【x264】滤波模块的简单分析
- 1. 滤波模块概述
- 1.1 自适应边界
- 1.2 自适应样点级滤波器
- 1.3 滤波过程
- 2. 函数入口(fdec_filter_row)
- 2.1 去块滤波(x264_frame_deblock_row)
- 2.1.1 强滤波函数(deblock_edge_intra)
- 2.1.2 普通滤波函数(deblock_edge)
- 3.小结
参数分析:
【x264】x264编码器参数配置
流程分析:
【x264】x264编码主流程简单分析
【x264】编码核心函数(x264_encoder_encode)的简单分析
【x264】分析模块(analyse)的简单分析—帧内预测
【x264】分析模块(analyse)的简单分析—帧间预测
【x264】码率控制模块的简单分析—宏块级码控工具Mbtree和AQ
【x264】码率控制模块的简单分析—帧级码控策略
【x264】码率控制模块的简单分析—编码主流程
【x264】lookahead模块的简单分析
【x264】变换量化模块的简单分析
【x264】熵编码模块的简单分析
1. 滤波模块概述
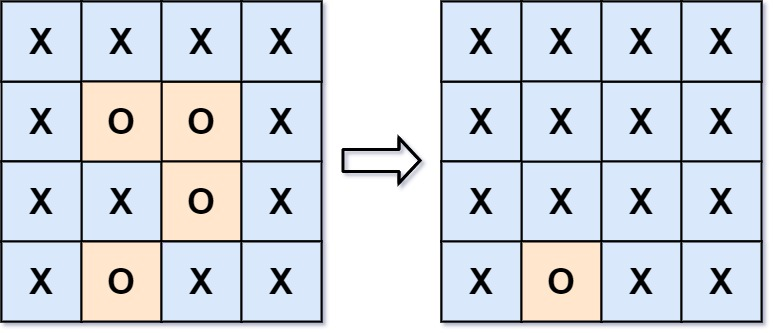
滤波模块存在的意义是,由于编解码过程中的变换量化过程带来的误差,重建帧和原始帧往往有一定的差异程度,这种差异程度在mb的边界部分较为突出,具体表现为两个mb之间的边界模糊、不连续,此时需要进行滤波来去除这种边界模糊的不利影响。由于滤波模块存在位置在编解码的环路之中,同时去除的是相邻块之间的模糊,所以滤波模块又称之为环路去块滤波(In-loop deblock filter)或环路滤波。下图中,左侧图片没有使用滤波,右侧图片使用了滤波。明显看出没有使用滤波之前,块之间有明显的不连续情况,而使用了之后明显平滑许多

1.1 自适应边界
边界强度(Border Strength,BS)决定去方块滤波器选择的滤波参数,控制去方块效应的程度。对所有4x4亮度块间的边界,边界强度参数值在0~4之间,它与边界的性质有关。滤波器强度参数与编码模式的关系为
| 图像块模式与条件 | Bs |
|---|---|
| 边界两边一个图像块为帧内预测并且边界为宏块边界 | 4 |
| 边界两边一个图像块为帧内预测 | 3 |
| 边界两边一个图像块对残差编码 | 2 |
| 边界两边图像块运动矢量差不小于1个亮度图像点距离 | 1 |
| 其他 | 0 |
在实际的滤波算法中,Bs决定对边界的滤波强度,包括对两个主要滤波模式的选择。当其值为4时表示要用特定最强的滤波模式,而其值为0表示不需要对边界进行滤波。当其值为1~3时,为标准的滤波模式,Bs值影响滤波器对样点的最大修正程度。Bs值下降趋势说明最强的方块效应主要来自于帧内预测模式及对预测残差编码,而在较小程度上与图像的运动补偿有关。此外,色度块边界滤波的Bs值不会单独计算,而是从相应亮度边界的Bs值复制而来。
1.2 自适应样点级滤波器
在去块滤波中,需要区分图像中的真实边界和由DCT变换系数量化而造成的假边界。为了保持图像的逼真度,应该尽量在滤波假边界以不致被看出的同时保持图像真实边界不被滤波。为了区分,需要分析边界两边的样点值。现在假设相邻4x4块中一条直线上的样点为p3, p2, p1, p0, q0, q1, q2, q3,实际的图像边界在p0和q0之间,只有满足如下条件时才会进行滤波:
∣
p
0
−
q
0
∣
<
α
(
I
n
d
e
x
A
)
∣
p
1
−
p
0
∣
<
β
(
I
n
d
e
x
B
)
∣
q
1
−
q
0
∣
<
β
(
I
n
d
e
x
B
)
|p_0 - q_0| < \alpha (Index_A) \\ |p_1 - p_0| < \beta (Index_B) \\ |q_1 - q_0| < \beta (Index_B)
∣p0−q0∣<α(IndexA)∣p1−p0∣<β(IndexB)∣q1−q0∣<β(IndexB)
其中,
α
\alpha
α和
β
\beta
β根据查表获取,查找索引值计算方式为
I
n
d
e
x
i
=
{
0
,
Q
P
+
O
f
f
s
e
t
i
≤
0
Q
P
+
O
f
f
s
e
t
i
,
0
<
Q
P
+
O
f
f
s
e
t
i
<
51
51
,
Q
P
+
O
f
f
s
e
t
i
≥
51
Index_i=\left\{ \begin{matrix} 0, QP+Offset_i \leq 0\\ QP+Offset_i, 0 < QP+Offset_i < 51 \\ 51, QP+Offset_i \geq 51 \end{matrix} \right.
Indexi=⎩
⎨
⎧0,QP+Offseti≤0QP+Offseti,0<QP+Offseti<5151,QP+Offseti≥51
其中,
i
=
A
或
B
i=A或B
i=A或B
1.3 滤波过程
滤波是基于宏块的,先对垂直边界进行水平滤波,再对水平边界进行垂直滤波。滤波顺序如下所示,首先滤波宏块最左侧的边界(0号边界),后续依次滤波1,2,3号边界,随后滤波宏块最上方的边界(4号边界),随后依次滤波5,6,7号边界
/*
* 滤波顺序如下所示(大方框代表16x16块)
*
* +--4-+--4-+--4-+--4-+
* 0 1 2 3 |
* +--5-+--5-+--5-+--5-+
* 0 1 2 3 |
* +--6-+--6-+--6-+--6-+
* 0 1 2 3 |
* +--7-+--7-+--7-+--7-+
* 0 1 2 3 |
* +----+----+----+----+
*
*/
(1)如果Bs从1到3,滤波的过程可以描述为
p
0
’
=
p
0
+
(
(
(
q
0
−
p
0
)
<
<
2
)
+
(
p
1
−
q
1
)
+
4
)
>
>
3
p
1
’
=
(
p
2
+
(
(
p
0
+
q
0
+
1
)
>
>
1
)
–
2
p
1
)
>
>
1
p0’ = p0 + (((q0 - p0 ) << 2) + (p1 - q1) + 4) >> 3 \\ p1’ = ( p2 + ( ( p0 + q0 + 1 ) >> 1) – 2p1 ) >> 1
p0’=p0+(((q0−p0)<<2)+(p1−q1)+4)>>3p1’=(p2+((p0+q0+1)>>1)–2p1)>>1
(2)如果Bs为4,滤波的过程可以描述为
p
0
’
=
(
p
2
+
2
∗
p
1
+
2
∗
p
0
+
2
∗
q
0
+
q
1
+
4
)
>
>
3
p
1
’
=
(
p
2
+
p
1
+
p
0
+
q
0
+
2
)
>
>
2
p
2
’
=
(
2
∗
p
3
+
3
∗
p
2
+
p
1
+
p
0
+
q
0
+
4
)
>
>
3
p0’ = ( p2 + 2*p1 + 2*p0 + 2*q0 + q1 + 4 ) >> 3 \\ p1’ = ( p2 + p1 + p0 + q0 + 2 ) >> 2 \\ p2’ = ( 2*p3 + 3*p2 + p1 + p0 + q0 + 4 ) >> 3
p0’=(p2+2∗p1+2∗p0+2∗q0+q1+4)>>3p1’=(p2+p1+p0+q0+2)>>2p2’=(2∗p3+3∗p2+p1+p0+q0+4)>>3
2. 函数入口(fdec_filter_row)
滤波模块的入口为fdec_filter_row,定义在encoder\encoder.c中,主要的工作流程为:
- 进行去块滤波(x264_frame_deblock_row)
- 半像素内插(x264_frame_filter)
- 计算质量
(1)计算psnr(x264_pixel_ssd_wxh)
(2)计算ssim(x264_pixel_ssim_wxh)
static void fdec_filter_row( x264_t *h, int mb_y, int pass )
{
/* mb_y is the mb to be encoded next, not the mb to be filtered here */
int b_hpel = h->fdec->b_kept_as_ref;
int b_deblock = h->sh.i_disable_deblocking_filter_idc != 1;
int b_end = mb_y == h->i_threadslice_end;
int b_measure_quality = 1;
int min_y = mb_y - (1 << SLICE_MBAFF);
int b_start = min_y == h->i_threadslice_start;
/* Even in interlaced mode, deblocking never modifies more than 4 pixels
* above each MB, as bS=4 doesn't happen for the top of interlaced mbpairs. */
int minpix_y = min_y*16 - 4 * !b_start;
int maxpix_y = mb_y*16 - 4 * !b_end;
b_deblock &= b_hpel || h->param.b_full_recon || h->param.psz_dump_yuv;
// slice级的线程使用
if( h->param.b_sliced_threads )
{
switch( pass )
{
/* During encode: only do deblock if asked for */
default:
case 0:
b_deblock &= h->param.b_full_recon;
b_hpel = 0;
break;
/* During post-encode pass: do deblock if not done yet, do hpel for all
* rows except those between slices. */
case 1:
b_deblock &= !h->param.b_full_recon;
b_hpel &= !(b_start && min_y > 0);
b_measure_quality = 0;
break;
/* Final pass: do the rows between slices in sequence. */
case 2:
b_deblock = 0;
b_measure_quality = 0;
break;
}
}
if( mb_y & SLICE_MBAFF )
return;
if( min_y < h->i_threadslice_start )
return;
// ----- 1.进行deblock处理 ----- //
if( b_deblock )
for( int y = min_y; y < mb_y; y += (1 << SLICE_MBAFF) )
x264_frame_deblock_row( h, y ); // 按照行处理
/* FIXME: Prediction requires different borders for interlaced/progressive mc,
* but the actual image data is equivalent. For now, maintain this
* consistency by copying deblocked pixels between planes. */
// 交错/渐进式mc的预测需要不同的边界,但实际图像数据是等效的
// 现在,通过在平面之间复制去块像素来保持这种一致性
if( PARAM_INTERLACED && (!h->param.b_sliced_threads || pass == 1) )
for( int p = 0; p < h->fdec->i_plane; p++ )
for( int i = minpix_y>>(CHROMA_V_SHIFT && p); i < maxpix_y>>(CHROMA_V_SHIFT && p); i++ )
memcpy( h->fdec->plane_fld[p] + i*h->fdec->i_stride[p],
h->fdec->plane[p] + i*h->fdec->i_stride[p],
h->mb.i_mb_width*16*SIZEOF_PIXEL );
if( h->fdec->b_kept_as_ref && (!h->param.b_sliced_threads || pass == 1) )
x264_frame_expand_border( h, h->fdec, min_y );
// ----- 2.半像素内插 ----- //
if( b_hpel )
{
int end = mb_y == h->mb.i_mb_height;
/* Can't do hpel until the previous slice is done encoding. */
if( h->param.analyse.i_subpel_refine )
{
x264_frame_filter( h, h->fdec, min_y, end ); // 半像素内插入口
x264_frame_expand_border_filtered( h, h->fdec, min_y, end );
}
}
if( SLICE_MBAFF && pass == 0 )
for( int i = 0; i < 3; i++ )
{
XCHG( pixel *, h->intra_border_backup[0][i], h->intra_border_backup[3][i] );
XCHG( pixel *, h->intra_border_backup[1][i], h->intra_border_backup[4][i] );
}
if( h->i_thread_frames > 1 && h->fdec->b_kept_as_ref )
x264_frame_cond_broadcast( h->fdec, mb_y*16 + (b_end ? 10000 : -(X264_THREAD_HEIGHT << SLICE_MBAFF)) );
// ----- 3.计算质量 ----- //
if( b_measure_quality )
{
maxpix_y = X264_MIN( maxpix_y, h->param.i_height );
if( h->param.analyse.b_psnr ) // 计算psnr
{
for( int p = 0; p < (CHROMA444 ? 3 : 1); p++ )
h->stat.frame.i_ssd[p] += x264_pixel_ssd_wxh( &h->pixf,
h->fdec->plane[p] + minpix_y * h->fdec->i_stride[p], h->fdec->i_stride[p],
h->fenc->plane[p] + minpix_y * h->fenc->i_stride[p], h->fenc->i_stride[p],
h->param.i_width, maxpix_y-minpix_y );
if( !CHROMA444 )
{
uint64_t ssd_u, ssd_v;
int v_shift = CHROMA_V_SHIFT;
x264_pixel_ssd_nv12( &h->pixf,
h->fdec->plane[1] + (minpix_y>>v_shift) * h->fdec->i_stride[1], h->fdec->i_stride[1],
h->fenc->plane[1] + (minpix_y>>v_shift) * h->fenc->i_stride[1], h->fenc->i_stride[1],
h->param.i_width>>1, (maxpix_y-minpix_y)>>v_shift, &ssd_u, &ssd_v );
h->stat.frame.i_ssd[1] += ssd_u;
h->stat.frame.i_ssd[2] += ssd_v;
}
}
if( h->param.analyse.b_ssim ) // 计算ssim
{
int ssim_cnt;
x264_emms();
/* offset by 2 pixels to avoid alignment of ssim blocks with dct blocks,
* and overlap by 4 */
minpix_y += b_start ? 2 : -6;
h->stat.frame.f_ssim +=
x264_pixel_ssim_wxh( &h->pixf,
h->fdec->plane[0] + 2+minpix_y*h->fdec->i_stride[0], h->fdec->i_stride[0],
h->fenc->plane[0] + 2+minpix_y*h->fenc->i_stride[0], h->fenc->i_stride[0],
h->param.i_width-2, maxpix_y-minpix_y, h->scratch_buffer, &ssim_cnt );
h->stat.frame.i_ssim_cnt += ssim_cnt;
}
}
}
2.1 去块滤波(x264_frame_deblock_row)
函数的主要功能是执行具体的边界滤波,主要的工作流程为:
- 定义FILTER宏,会决定滤波的强弱、滤波的方向和滤波的边界
- 逐次滤波每条边界
(1)FILTER( _intra, 0, 0, qp_left, qpc_left ); // 第0条边界, 强滤波,水平滤波器(垂直边界)
或 FILTER( , 0, 0, qp_left, qpc_left ); // 0, 普通滤波,水平滤波器(垂直边界)
(2)FILTER( , 0, 1, qp, qpc ); // 第1条边界//普通滤波,水平滤波器(垂直边界)
(3)FILTER( , 0, 2, qp, qpc ); // 第2条边界
(4)FILTER( , 0, 3, qp, qpc ); // 第3条边界
(5)FILTER( _intra, 1, 0, qp_top, qpc_top ); // 第4条边界,普通滤波,垂直滤波器(水平边界)
(6)FILTER( , 1, 1, qp, qpc );// 第5条边界,普通滤波,垂直滤波器(水平边界)
(7)FILTER( , 1, 2, qp, qpc );// 第6条边界
(8)FILTER( , 1, 3, qp, qpc );// 第7条边界
边界和编号对应的关系是
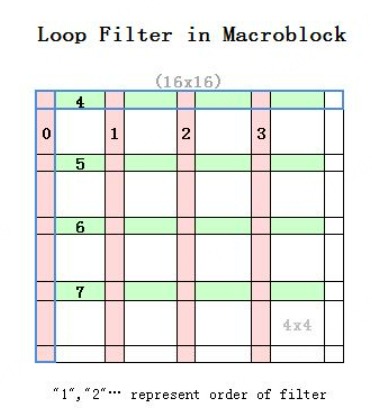
此外,边界滤波会根据具体情况使用deblock_edge_intra或者是deblock_edge函数之一
void x264_frame_deblock_row( x264_t *h, int mb_y )
{
int b_interlaced = SLICE_MBAFF;
int a = h->sh.i_alpha_c0_offset - QP_BD_OFFSET;
int b = h->sh.i_beta_offset - QP_BD_OFFSET;
int qp_thresh = 15 - X264_MIN( a, b ) - X264_MAX( 0, h->pps->i_chroma_qp_index_offset );
int stridey = h->fdec->i_stride[0];
int strideuv = h->fdec->i_stride[1];
int chroma_format = CHROMA_FORMAT;
int chroma444 = CHROMA444;
int chroma_height = 16 >> CHROMA_V_SHIFT;
intptr_t uvdiff = chroma444 ? h->fdec->plane[2] - h->fdec->plane[1] : 1;
for( int mb_x = 0; mb_x < h->mb.i_mb_width; mb_x += (~b_interlaced | mb_y)&1, mb_y ^= b_interlaced )
{
// 获取fdec信息
x264_prefetch_fenc( h, h->fdec, mb_x, mb_y );
// 从cache中获取相邻已进行deblock的块
macroblock_cache_load_neighbours_deblock( h, mb_x, mb_y );
int mb_xy = h->mb.i_mb_xy;
int transform_8x8 = h->mb.mb_transform_size[mb_xy];
int intra_cur = IS_INTRA( h->mb.type[mb_xy] );
uint8_t (*bs)[8][4] = h->deblock_strength[mb_y&1][h->param.b_sliced_threads?mb_xy:mb_x];
pixel *pixy = h->fdec->plane[0] + 16*mb_y*stridey + 16*mb_x;
pixel *pixuv = CHROMA_FORMAT ? h->fdec->plane[1] + chroma_height*mb_y*strideuv + 16*mb_x : NULL;
if( mb_y & MB_INTERLACED )
{
pixy -= 15*stridey;
if( CHROMA_FORMAT )
pixuv -= (chroma_height-1)*strideuv;
}
int stride2y = stridey << MB_INTERLACED;
int stride2uv = strideuv << MB_INTERLACED;
int qp = h->mb.qp[mb_xy];
int qpc = h->chroma_qp_table[qp];
int first_edge_only = (h->mb.partition[mb_xy] == D_16x16 && !h->mb.cbp[mb_xy] && !intra_cur) || qp <= qp_thresh;
/*
* 滤波顺序如下所示(大方框代表16x16块)
*
* +--4-+--4-+--4-+--4-+
* 0 1 2 3 |
* +--5-+--5-+--5-+--5-+
* 0 1 2 3 |
* +--6-+--6-+--6-+--6-+
* 0 1 2 3 |
* +--7-+--7-+--7-+--7-+
* 0 1 2 3 |
* +----+----+----+----+
*
*/
// ## 表示连接符
// 当intra有效时,deblock_edge##intra -> deblock_edge_intra()
// 当intra 为空时,deblock_edge##intra -> deblock_edge()
// dir为滤波的方向,dir=0表示水平滤波器(处理的是垂直边界),dir=1表示垂直滤波器(处理的是水平边界)
#define FILTER( intra, dir, edge, qp, chroma_qp )\
do\
{\
if( !(edge & 1) || !transform_8x8 )\
{\
deblock_edge##intra( h, pixy + 4*edge*(dir?stride2y:1),\
stride2y, bs[dir][edge], qp, a, b, 0,\
h->loopf.deblock_luma##intra[dir] );\
if( chroma_format == CHROMA_444 )\
{\
deblock_edge##intra( h, pixuv + 4*edge*(dir?stride2uv:1),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 0,\
h->loopf.deblock_luma##intra[dir] );\
deblock_edge##intra( h, pixuv + uvdiff + 4*edge*(dir?stride2uv:1),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 0,\
h->loopf.deblock_luma##intra[dir] );\
}\
else if( chroma_format == CHROMA_420 && !(edge & 1) )\
{\
deblock_edge##intra( h, pixuv + edge*(dir?2*stride2uv:4),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 1,\
h->loopf.deblock_chroma##intra[dir] );\
}\
}\
if( chroma_format == CHROMA_422 && (dir || !(edge & 1)) )\
{\
deblock_edge##intra( h, pixuv + edge*(dir?4*stride2uv:4),\
stride2uv, bs[dir][edge], chroma_qp, a, b, 1,\
h->loopf.deblock_chroma##intra[dir] );\
}\
} while( 0 )
// 如果左侧的mb存在
if( h->mb.i_neighbour & MB_LEFT )
{
// 如果是隔行处理
if( b_interlaced && h->mb.field[h->mb.i_mb_left_xy[0]] != MB_INTERLACED )
{
int luma_qp[2];
int chroma_qp[2];
int left_qp[2];
x264_deblock_inter_t luma_deblock = h->loopf.deblock_luma_mbaff;
x264_deblock_inter_t chroma_deblock = h->loopf.deblock_chroma_mbaff;
x264_deblock_intra_t luma_intra_deblock = h->loopf.deblock_luma_intra_mbaff;
x264_deblock_intra_t chroma_intra_deblock = h->loopf.deblock_chroma_intra_mbaff;
int c = chroma444 ? 0 : 1;
left_qp[0] = h->mb.qp[h->mb.i_mb_left_xy[0]];
luma_qp[0] = (qp + left_qp[0] + 1) >> 1;
chroma_qp[0] = (qpc + h->chroma_qp_table[left_qp[0]] + 1) >> 1;
if( intra_cur || IS_INTRA( h->mb.type[h->mb.i_mb_left_xy[0]] ) )
{
deblock_edge_intra( h, pixy, 2*stridey, bs[0][0], luma_qp[0], a, b, 0, luma_intra_deblock );
if( chroma_format )
{
deblock_edge_intra( h, pixuv, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_intra_deblock );
if( chroma444 )
deblock_edge_intra( h, pixuv + uvdiff, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_intra_deblock );
}
}
else
{
deblock_edge( h, pixy, 2*stridey, bs[0][0], luma_qp[0], a, b, 0, luma_deblock );
if( chroma_format )
{
deblock_edge( h, pixuv, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_deblock );
if( chroma444 )
deblock_edge( h, pixuv + uvdiff, 2*strideuv, bs[0][0], chroma_qp[0], a, b, c, chroma_deblock );
}
}
int offy = MB_INTERLACED ? 4 : 0;
int offuv = MB_INTERLACED ? 4-CHROMA_V_SHIFT : 0;
left_qp[1] = h->mb.qp[h->mb.i_mb_left_xy[1]];
luma_qp[1] = (qp + left_qp[1] + 1) >> 1;
chroma_qp[1] = (qpc + h->chroma_qp_table[left_qp[1]] + 1) >> 1;
if( intra_cur || IS_INTRA( h->mb.type[h->mb.i_mb_left_xy[1]] ) )
{
deblock_edge_intra( h, pixy + (stridey<<offy), 2*stridey, bs[0][4], luma_qp[1], a, b, 0, luma_intra_deblock );
if( chroma_format )
{
deblock_edge_intra( h, pixuv + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_intra_deblock );
if( chroma444 )
deblock_edge_intra( h, pixuv + uvdiff + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_intra_deblock );
}
}
else
{
deblock_edge( h, pixy + (stridey<<offy), 2*stridey, bs[0][4], luma_qp[1], a, b, 0, luma_deblock );
if( chroma_format )
{
deblock_edge( h, pixuv + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_deblock );
if( chroma444 )
deblock_edge( h, pixuv + uvdiff + (strideuv<<offuv), 2*strideuv, bs[0][4], chroma_qp[1], a, b, c, chroma_deblock );
}
}
}
else
{ // 非隔行处理
int qpl = h->mb.qp[h->mb.i_mb_xy-1];
int qp_left = (qp + qpl + 1) >> 1;
int qpc_left = (qpc + h->chroma_qp_table[qpl] + 1) >> 1;
int intra_left = IS_INTRA( h->mb.type[h->mb.i_mb_xy-1] );
int intra_deblock = intra_cur || intra_left;
/* Any MB that was coded, or that analysis decided to skip, has quality commensurate with its QP.
* But if deblocking affects neighboring MBs that were force-skipped, blur might accumulate there.
* So reset their effective QP to max, to indicate that lack of guarantee. */
// 任何被编码的MB,或者分析决定跳过的MB,都具有与其QP相称的质量
// 但是,如果块化影响了被强制跳过的相邻mb,则模糊可能会在那里积聚
// 所以将他们的有效QP重置为最大值,以表明缺乏保证。
if( h->fdec->mb_info && M32( bs[0][0] ) )
{
#define RESET_EFFECTIVE_QP(xy) h->fdec->effective_qp[xy] |= 0xff * !!(h->fdec->mb_info[xy] & X264_MBINFO_CONSTANT);
RESET_EFFECTIVE_QP(mb_xy);
RESET_EFFECTIVE_QP(h->mb.i_mb_left_xy[0]);
}
if( intra_deblock )
FILTER( _intra, 0, 0, qp_left, qpc_left ); // 0, 强滤波,水平滤波器(垂直边界)
else
FILTER( , 0, 0, qp_left, qpc_left ); // 0, 普通滤波,水平滤波器(垂直边界)
}
}
if( !first_edge_only )
{
// 水平滤波器(垂直边界)
FILTER( , 0, 1, qp, qpc ); // 1
FILTER( , 0, 2, qp, qpc ); // 2
FILTER( , 0, 3, qp, qpc ); // 3
}
// 如果上方的mb存在
if( h->mb.i_neighbour & MB_TOP )
{
if( b_interlaced && !(mb_y&1) && !MB_INTERLACED && h->mb.field[h->mb.i_mb_top_xy] )
{
int mbn_xy = mb_xy - 2 * h->mb.i_mb_stride;
for( int j = 0; j < 2; j++, mbn_xy += h->mb.i_mb_stride )
{
int qpt = h->mb.qp[mbn_xy];
int qp_top = (qp + qpt + 1) >> 1;
int qpc_top = (qpc + h->chroma_qp_table[qpt] + 1) >> 1;
int intra_top = IS_INTRA( h->mb.type[mbn_xy] );
if( intra_cur || intra_top )
M32( bs[1][4*j] ) = 0x03030303;
// deblock the first horizontal edge of the even rows, then the first horizontal edge of the odd rows
deblock_edge( h, pixy + j*stridey, 2* stridey, bs[1][4*j], qp_top, a, b, 0, h->loopf.deblock_luma[1] );
if( chroma444 )
{
deblock_edge( h, pixuv + j*strideuv, 2*strideuv, bs[1][4*j], qpc_top, a, b, 0, h->loopf.deblock_luma[1] );
deblock_edge( h, pixuv + uvdiff + j*strideuv, 2*strideuv, bs[1][4*j], qpc_top, a, b, 0, h->loopf.deblock_luma[1] );
}
else if( chroma_format )
deblock_edge( h, pixuv + j*strideuv, 2*strideuv, bs[1][4*j], qpc_top, a, b, 1, h->loopf.deblock_chroma[1] );
}
}
else
{
int qpt = h->mb.qp[h->mb.i_mb_top_xy];
int qp_top = (qp + qpt + 1) >> 1;
int qpc_top = (qpc + h->chroma_qp_table[qpt] + 1) >> 1;
int intra_top = IS_INTRA( h->mb.type[h->mb.i_mb_top_xy] );
int intra_deblock = intra_cur || intra_top;
/* This edge has been modified, reset effective qp to max. */
// 如果edge已经被更新,重置有效的qp为最大值
if( h->fdec->mb_info && M32( bs[1][0] ) )
{
RESET_EFFECTIVE_QP(mb_xy);
RESET_EFFECTIVE_QP(h->mb.i_mb_top_xy);
}
if( (!b_interlaced || (!MB_INTERLACED && !h->mb.field[h->mb.i_mb_top_xy])) && intra_deblock )
{
FILTER( _intra, 1, 0, qp_top, qpc_top ); // 4 普通滤波,垂直滤波器(水平边界)
}
else
{
if( intra_deblock )
M32( bs[1][0] ) = 0x03030303;
FILTER( , 1, 0, qp_top, qpc_top ); // 4 普通滤波,垂直滤波器(水平边界)
}
}
}
if( !first_edge_only )
{ // 垂直滤波器(水平边界)
FILTER( , 1, 1, qp, qpc ); // 5
FILTER( , 1, 2, qp, qpc ); // 6
FILTER( , 1, 3, qp, qpc ); // 7
}
#undef FILTER
}
}
2.1.1 强滤波函数(deblock_edge_intra)
强滤波函数会根据alpha和beta来进行滤波调整,alphae和beta与qp有对应关系。在标准当中,强滤波使用的情况是Bs=4
static ALWAYS_INLINE void deblock_edge_intra( x264_t *h, pixel *pix, intptr_t i_stride, uint8_t bS[4], int i_qp,
int a, int b, int b_chroma, x264_deblock_intra_t pf_intra )
{
int index_a = i_qp + a;
int index_b = i_qp + b;
int alpha = alpha_table(index_a) << (BIT_DEPTH-8);
int beta = beta_table(index_b) << (BIT_DEPTH-8);
//根据QP,通过查表的方法获得是否滤波的门限值alpha和beta
//alpha为边界两边2点的门限值
//beta为边界一边最靠近边界的2点的门限值
//总体说来,QP越大,alpha和beta越大,越有可能滤波
// alpha或beta有一个为0时,不进行滤波
if( !alpha || !beta )
return;
// 具体进行滤波的入口,pf_intra通常使用汇编函数来加速处理,极少会使用c语言函数来处理
pf_intra( pix, i_stride, alpha, beta );
}
2.1.2 普通滤波函数(deblock_edge)
普通滤波函数除了会计算alpha和beta之外,还会根据查找表来计算tc,再进行具体的滤波。在标准中,普通滤波分为3种情况,Bs=1,2或3
static ALWAYS_INLINE void deblock_edge( x264_t *h, pixel *pix, intptr_t i_stride, uint8_t bS[4], int i_qp,
int a, int b, int b_chroma, x264_deblock_inter_t pf_inter )
{
int index_a = i_qp + a;
int index_b = i_qp + b;
int alpha = alpha_table(index_a) << (BIT_DEPTH-8);
int beta = beta_table(index_b) << (BIT_DEPTH-8);
int8_t tc[4];
if( !M32(bS) || !alpha || !beta )
return;
tc[0] = (tc0_table(index_a)[bS[0]] * (1 << (BIT_DEPTH-8))) + b_chroma;
tc[1] = (tc0_table(index_a)[bS[1]] * (1 << (BIT_DEPTH-8))) + b_chroma;
tc[2] = (tc0_table(index_a)[bS[2]] * (1 << (BIT_DEPTH-8))) + b_chroma;
tc[3] = (tc0_table(index_a)[bS[3]] * (1 << (BIT_DEPTH-8))) + b_chroma;
pf_inter( pix, i_stride, alpha, beta, tc );
}
3.小结
滤波模块旨在解决重建后相邻mb之间块效应的问题,由于处于编解码环路之中,所以又称为环路滤波。另外,由于解决的问题是块效应问题,所以又成为去块滤波。滤波模块需要考虑的问题包括:(1)是否要进行滤波,这是根据相邻像素的具体数值进行判断的;(2)使用何种强度进行滤波,这是根据相邻块编码模式决定的。在具体的实现上,x264编码器通常会使用汇编函数进行优化处理,但也有c函数的支持
CSDN : https://blog.csdn.net/weixin_42877471
Github : https://github.com/DoFulangChen