文章目录
- 完整代码
- 一、上传资源
- 二、替换 MD 中的引用文件为在线链接
- 参考
完整代码
完整代码由两个文件组成,upload.py 和 main.py,放在同一目录下运行 main.py 就好!
# upload.py
import requests
class UploadPic:
def __init__(self, cookie):
self.cookie = cookie
# 解析
self.file_path = ''
self.img_type = ''
# 两个请求体
self.upload_data = {}
self.csdn_data = {}
self.output_url = ''
def _get_file(self, file_path):
with open(file_path, mode='rb') as f:
binary_data = f.read()
return binary_data
def _upload_request(self):
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookie': self.cookie,
'origin': 'https://editor.csdn.net',
'priority': 'u=1, i',
'referer': 'https://editor.csdn.net/',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
}
params = {
'type': 'blog',
'rtype': 'markdown',
'x-image-template': '',
'x-image-app': 'direct_blog',
'x-image-dir': 'direct',
'x-image-suffix': self.img_type,
}
url = 'https://imgservice.csdn.net/direct/v1.0/image/upload'
response = requests.get(url, params=params, headers=headers)
try:
self.upload_data = response.json()
except Exception as e:
return e
def _csdn_request(self):
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'https://editor.csdn.net',
'Referer': 'https://editor.csdn.net/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
files = {
'key': (None, self.upload_data['data']['filePath']),
'policy': (None, self.upload_data['data']['policy']),
'OSSAccessKeyId': (None, self.upload_data['data']['accessId']),
'success_action_status': (None, '200'),
'signature': (None, self.upload_data['data']['signature']),
'callback': (None, self.upload_data['data']['callbackUrl']),
'file': (f'image.{self.img_type}', self._get_file(self.file_path), f'image/{self.img_type}'),
}
url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/'
response = requests.post(url, headers=headers, files=files)
try:
self.csdn_data = response.json()
self.output_url = self.csdn_data['data']['imageUrl']
except Exception as e:
return e
def upload_image(self, file_path):
self.file_path = file_path
self.img_type = self.file_path.split('.')[-1]
exception_1 = self._upload_request()
assert exception_1 is None, exception_1
exception_2 = self._csdn_request()
assert exception_2 is None, exception_2
return self.output_url
if __name__ == '__main__':
cookie = '' # 输入你的cookie
upload = UploadPic(cookie)
output_url = upload.upload_image('') #输入你需要上传的文件位置
print(output_url)
# main.py
import os
import re
from pathlib import Path
from rich.progress import track
from upload import UploadPic
class CSDNTransform:
def __init__(self, upload:UploadPic, file_path, walk_path='C:/Users/Administrator/Documents/Obsidian Vault/'):
self.upload = upload
self.file_path = file_path
self.walk_path = walk_path
self.markdown_text = ''
self.image_lst = []
self.posterior_image_lst = []
self.image_2_url_dic = {}
def _get_markdown_text(self):
with open(self.file_path, mode='r', encoding='utf-8') as f:
markdown_text = f.read()
self.markdown_text = markdown_text
def _process_markdown_text(self):
image_lst = re.findall(r'(!\[\[.*]])', self.markdown_text)
posterior_image_lst = [item[3:-2] for item in image_lst]
self.image_lst = image_lst
self.posterior_image_lst = posterior_image_lst
def _get_target_image_path(self, target_path):
for root, floders, files in os.walk(self.walk_path):
for file in files:
if file == target_path:
return str(Path(root) / file)
def _get_the_url_of_image(self, image_path):
image_url = self.upload.upload_image(image_path)
return image_url
def get_the_urls(self):
self._get_markdown_text()
self._process_markdown_text()
not_exist_image_index = []
for ix, (origin_image, target_path) in track(enumerate(zip(self.image_lst, self.posterior_image_lst))):
image_path = self._get_target_image_path(target_path)
if image_path is not None:
image_url = self._get_the_url_of_image(image_path)
self.image_2_url_dic[origin_image] = image_url
else:
not_exist_image_index.append(ix)
# 清楚掉需要删除的index
num = 0
for ix in not_exist_image_index:
del self.image_lst[ix-num]
del self.posterior_image_lst[ix-num]
num += 1
def _the_transform_data_from(self, image_url):
data_form = f"""\n<div align=center><img src="{image_url}"></div>\n"""
return data_form
def _save_markdown_text(self, output_file='markdown_processed.txt'):
with open(output_file, mode='w', encoding='utf-8') as f:
f.write(self.markdown_text)
def get_transform(self):
self.get_the_urls()
# Judge the length
assert len(self.image_lst) == len(self.image_2_url_dic), f"上传成功{len(self.image_2_url_dic)}张图片,总共有{len(self.image_lst)}张图片"
for origin_image, image_url in self.image_2_url_dic.items():
self.markdown_text = self.markdown_text.replace(origin_image, self._the_transform_data_from(image_url))
self._save_markdown_text()
if __name__ == '__main__':
cookie = '' # 输入你的cookie
file_path = '' # 输入你要转换的markdown文件地址
upload = UploadPic(cookie)
transform = CSDNTransform(upload, file_path)
markdown_text = transform.get_transform()
# 修改后的 Markdown 在当前目录的 markdown_processed.txt 文件中
一、上传资源
首先我们解析 CSDN 上传请求,这里随便上传一张图片,观察请求;

请求由三部分组成,分别是:1. 获取存储位置和签名验证信息;2. 利用签名等验证信息上传文件;3. 获取文件信息并显示;
仔细观察两个请求,upload 请求是 GET ,csdn 请求是 POST,其结果很明显 csdn 请求是主体,仔细观察 csdn 的参数,可以所有参数都可以利用 upload 的返回结果得到;
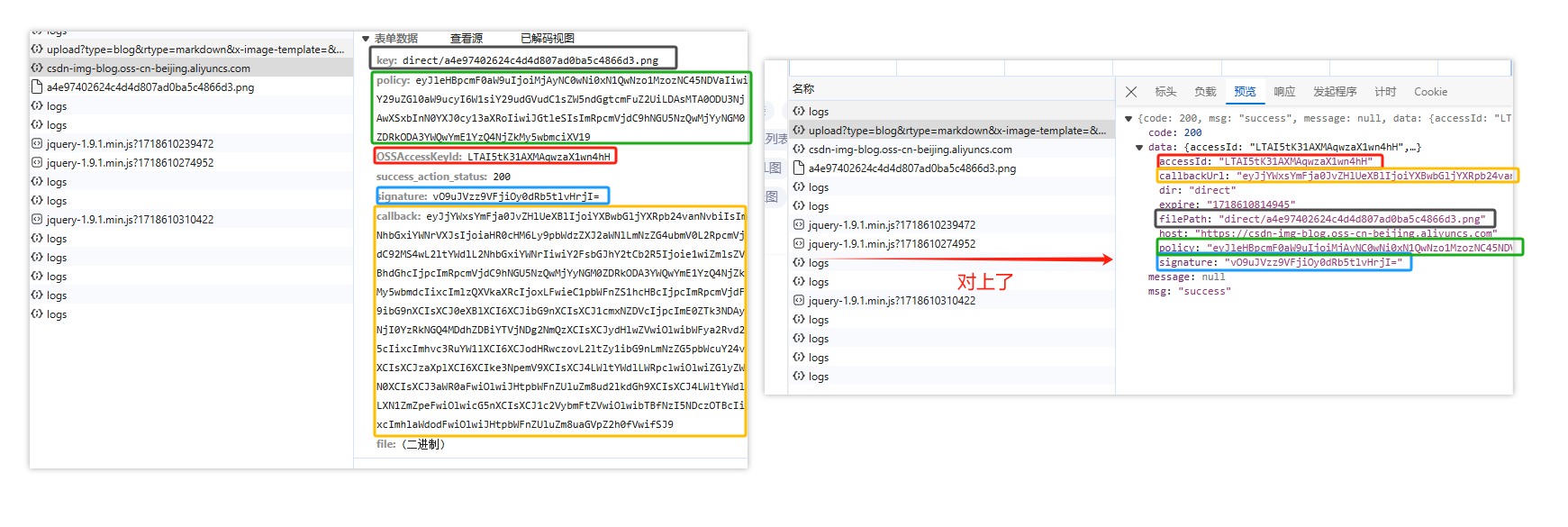
那么接下来我们开始构造 upload 请求
import requests
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookie': '', # 输入自己的cookies
'origin': 'https://editor.csdn.net',
'priority': 'u=1, i',
'referer': 'https://editor.csdn.net/',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
}
params = {
'type': 'blog',
'rtype': 'markdown',
'x-image-template': '',
'x-image-app': 'direct_blog',
'x-image-dir': 'direct',
'x-image-suffix': 'png',
}
url = 'https://imgservice.csdn.net/direct/v1.0/image/upload'
response = requests.get(url, params=params, headers=headers)
# 获得数据
upload_data = response.json()
得到 json 内容如下,通过比较该内容下 expire 和 time 库下的 time.time() * 1000,再根据英文名可以推断,expire 表示的是上传文件这一请求的失效时间,即 csdn 请求的最晚成功时间;
{'code': 200,
'data': {'accessId': 'LTAI5tK31AXMAqwzaX1wn4hH',
'callbackUrl': 'eyJjYWxsYmFja0JvZHlUeXBlIjoiYXBwbGljYXRpb24vanNvbiIsImNhbGxiYWNrVXJsIjoiaHR0cHM6Ly9pbWdzZXJ2aWNlLmNzZG4ubmV0L2RpcmVjdC92MS4wL2ltYWdlL2NhbGxiYWNrIiwiY2FsbGJhY2tCb2R5Ijoie1wiZmlsZVBhdGhcIjpcImRpcmVjdC9jN2VlYWNjZjU2ZDM0MzM3OWQ2Yjk4ZmYwNGYyZWFjNS5wbmdcIixcImlzQXVkaXRcIjoxLFwieC1pbWFnZS1hcHBcIjpcImRpcmVjdF9ibG9nXCIsXCJ0eXBlXCI6XCJibG9nXCIsXCJ1cmxNZDVcIjpcImM3ZWVhY2NmNTZkMzQzMzc5ZDZiOThmZjA0ZjJlYWM1XCIsXCJydHlwZVwiOlwibWFya2Rvd25cIixcImhvc3RuYW1lXCI6XCJodHRwczovL2ltZy1ibG9nLmNzZG5pbWcuY24vXCIsXCJzaXplXCI6XCIke3NpemV9XCIsXCJ4LWltYWdlLWRpclwiOlwiZGlyZWN0XCIsXCJ3aWR0aFwiOlwiJHtpbWFnZUluZm8ud2lkdGh9XCIsXCJ4LWltYWdlLXN1ZmZpeFwiOlwicG5nXCIsXCJ1c2VybmFtZVwiOlwibTBfNzI5NDczOTBcIixcImhlaWdodFwiOlwiJHtpbWFnZUluZm8uaGVpZ2h0fVwifSJ9',
'dir': 'direct',
'expire': '1718611892700',
'filePath': 'direct/c7eeaccf56d343379d6b98ff04f2eac5.png',
'host': 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com',
'policy': 'eyJleHBpcmF0aW9uIjoiMjAyNC0wNi0xN1QwODoxMTozMi43MDBaIiwiY29uZGl0aW9ucyI6W1siY29udGVudC1sZW5ndGgtcmFuZ2UiLDAsMTA0ODU3NjAwXSxbInN0YXJ0cy13aXRoIiwiJGtleSIsImRpcmVjdC9jN2VlYWNjZjU2ZDM0MzM3OWQ2Yjk4ZmYwNGYyZWFjNS5wbmciXV19',
'signature': '2hRKp5YO3epBJe5+Qt7Ngi7P/y4='},
'message': None,
'msg': 'success'}
下面利用 upload 得到的请求来构造 csdn 请求;
import requests
from requests_toolbelt.multipart.encoder import MultipartEncoder
def get_file(file_path):
"""获取文件的二进制数据"""
with open(file_path, mode='rb') as f:
binary_data = f.read()
return binary_data
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'https://editor.csdn.net',
'Referer': 'https://editor.csdn.net/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
success_action_status = '200'
# upload 请求中获取到的数据
key = upload_data['data']['filePath']
policy = upload_data['data']['policy']
OSSAccessKeyId = upload_data['data']['accessId']
signature = upload_data['data']['signature']
callback = upload_data['data']['callbackUrl']
# 上传的图片位置,
file = get_file('') # 输入需要上传文件的位置
files = {
'key': (None, key),
'policy': (None, policy),
'OSSAccessKeyId': (None, OSSAccessKeyId),
'success_action_status': (None, '200'),
'signature': (None, signature),
'callback': (None, callback),
'file': ('image.png', file, 'image/png'),
}
url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/'
response = requests.post(url, headers=headers, files=files)
print(response.text)
得到 Json 数据如下
{'code': 200,
'data': {'hostname': 'https://img-blog.csdnimg.cn/',
'imageUrl': 'https://img-blog.csdnimg.cn/direct/97c5610606c140afb474800403140ea3.png',
'width': '1138',
'targetObjectKey': 'direct/97c5610606c140afb474800403140ea3.png',
'x-image-suffix': 'png',
'height': '239'},
'msg': 'success'}
在其中 imageUrl 就表示上传的图片地址,同时,图片格式有许多种,面对不同的图片格式,在尝试观察后发现只需要修改 upload 请求中 parms 中的 x-image-suffix,csdn 请求中 files 中的 file;
整合得到完整上传类如下:
import requests
class UploadPic:
def __init__(self, cookie):
self.cookie = cookie
# 解析
self.file_path = ''
self.img_type = ''
# 两个请求体
self.upload_data = {}
self.csdn_data = {}
self.output_url = ''
def _get_file(self, file_path):
with open(file_path, mode='rb') as f:
binary_data = f.read()
return binary_data
def _upload_request(self):
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookie': self.cookie,
'origin': 'https://editor.csdn.net',
'priority': 'u=1, i',
'referer': 'https://editor.csdn.net/',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
}
params = {
'type': 'blog',
'rtype': 'markdown',
'x-image-template': '',
'x-image-app': 'direct_blog',
'x-image-dir': 'direct',
'x-image-suffix': self.img_type,
}
url = 'https://imgservice.csdn.net/direct/v1.0/image/upload'
response = requests.get(url, params=params, headers=headers)
try:
self.upload_data = response.json()
except Exception as e:
return e
def _csdn_request(self):
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'https://editor.csdn.net',
'Referer': 'https://editor.csdn.net/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
files = {
'key': (None, self.upload_data['data']['filePath']),
'policy': (None, self.upload_data['data']['policy']),
'OSSAccessKeyId': (None, self.upload_data['data']['accessId']),
'success_action_status': (None, '200'),
'signature': (None, self.upload_data['data']['signature']),
'callback': (None, self.upload_data['data']['callbackUrl']),
'file': (f'image.{self.img_type}', self._get_file(self.file_path), f'image/{self.img_type}'),
}
url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/'
response = requests.post(url, headers=headers, files=files)
try:
self.csdn_data = response.json()
self.output_url = self.csdn_data['data']['imageUrl']
except Exception as e:
return e
def upload_image(self, file_path):
self.file_path = file_path
self.img_type = self.file_path.split('.')[-1]
exception_1 = self._upload_request()
assert exception_1 is None, exception_1
exception_2 = self._csdn_request()
assert exception_2 is None, exception_2
return self.output_url
if __name__ == '__main__':
cookie = '' # 输入你的cookie
upload = UploadPic(cookie)
output_url = upload.upload_image('') #输入你需要上传的文件位置
print(output_url)
二、替换 MD 中的引用文件为在线链接
首先,肯定是整体替换而不是单个替换,因此我们的流程为:1. 上传所有文件,直到所有的文件都上传成功;2. 替换所有文件;
首先提取出 Markdown 中所有的图片信息,一般来说图片信息都在两个中括号之间 ![[ img_pic ]],使用 re 正则提取,代码如下;
import re
file_path = 'C:/Users/Administrator/Documents/Obsidian Vault/UE开发/My FirstGame Tutorial.md'
with open(file_path, mode='r', encoding='utf-8') as f:
markdown_text = f.read()
image_lst = re.findall(r'(!\[\[.*\]\])', markdown_text)
posterior_image_lst = [item[3:-2] for item in image_lst]
提取出所有的 img_pic 后,我们需要在根目录下寻找文件,一般来说在 Markdown 中文件名是不重复的;
import os
from pathlib import Path
def get_target_image_path(target_path):
walk_path = 'C:/Users/Administrator/Documents/Obsidian Vault/'
for root, floders, files in os.walk(walk_path):
for file in files:
if file == target_path:
return Path(root) / file
get_target_image_path(posterior_image_lst[0])
获取到了绝对位置后,我们可以将图片上传,在检查图片全部都上传完毕后,我们就可以替换 ![[ img_pic ]]
import os
import re
import requests
from pathlib import Path
from rich.progress import track
class UploadPic:
def __init__(self, cookie):
self.cookie = cookie
# 解析
self.file_path = ''
self.img_type = ''
# 两个请求体
self.upload_data = {}
self.csdn_data = {}
self.output_url = ''
def _get_file(self, file_path):
with open(file_path, mode='rb') as f:
binary_data = f.read()
return binary_data
def _upload_request(self):
headers = {
'accept': '*/*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'content-type': 'application/json',
'cookie': self.cookie,
'origin': 'https://editor.csdn.net',
'priority': 'u=1, i',
'referer': 'https://editor.csdn.net/',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
}
params = {
'type': 'blog',
'rtype': 'markdown',
'x-image-template': '',
'x-image-app': 'direct_blog',
'x-image-dir': 'direct',
'x-image-suffix': self.img_type,
}
url = 'https://imgservice.csdn.net/direct/v1.0/image/upload'
response = requests.get(url, params=params, headers=headers)
try:
self.upload_data = response.json()
except Exception as e:
return e
def _csdn_request(self):
headers = {
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'Connection': 'keep-alive',
'Origin': 'https://editor.csdn.net',
'Referer': 'https://editor.csdn.net/',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'cross-site',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0',
'sec-ch-ua': '"Not/A)Brand";v="8", "Chromium";v="126", "Microsoft Edge";v="126"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
files = {
'key': (None, self.upload_data['data']['filePath']),
'policy': (None, self.upload_data['data']['policy']),
'OSSAccessKeyId': (None, self.upload_data['data']['accessId']),
'success_action_status': (None, '200'),
'signature': (None, self.upload_data['data']['signature']),
'callback': (None, self.upload_data['data']['callbackUrl']),
'file': (f'image.{self.img_type}', self._get_file(self.file_path), f'image/{self.img_type}'),
}
url = 'https://csdn-img-blog.oss-cn-beijing.aliyuncs.com/'
response = requests.post(url, headers=headers, files=files)
try:
self.csdn_data = response.json()
self.output_url = self.csdn_data['data']['imageUrl']
except Exception as e:
return e
def upload_image(self, file_path):
self.file_path = file_path
self.img_type = self.file_path.split('.')[-1]
exception_1 = self._upload_request()
assert exception_1 is None, exception_1
exception_2 = self._csdn_request()
assert exception_2 is None, exception_2
return self.output_url
class CSDNTransform:
def __init__(self, upload:UploadPic, file_path, walk_path='C:/Users/Administrator/Documents/Obsidian Vault/'):
self.upload = upload
self.file_path = file_path
self.walk_path = walk_path
self.markdown_text = ''
self.image_lst = []
self.posterior_image_lst = []
self.image_2_url_dic = {}
def _get_markdown_text(self):
with open(self.file_path, mode='r', encoding='utf-8') as f:
markdown_text = f.read()
self.markdown_text = markdown_text
def _process_markdown_text(self):
image_lst = re.findall(r'(!\[\[.*]])', self.markdown_text)
posterior_image_lst = [item[3:-2] for item in image_lst]
self.image_lst = image_lst
self.posterior_image_lst = posterior_image_lst
def _get_target_image_path(self, target_path):
for root, floders, files in os.walk(self.walk_path):
for file in files:
if file == target_path:
return str(Path(root) / file)
def _get_the_url_of_image(self, image_path):
image_url = self.upload.upload_image(image_path)
return image_url
def get_the_urls(self):
self._get_markdown_text()
self._process_markdown_text()
not_exist_image_index = []
for ix, (origin_image, target_path) in track(enumerate(zip(self.image_lst, self.posterior_image_lst))):
image_path = self._get_target_image_path(target_path)
if image_path is not None:
image_url = self._get_the_url_of_image(image_path)
self.image_2_url_dic[origin_image] = image_url
else:
not_exist_image_index.append(ix)
# 清楚掉需要删除的index
num = 0
for ix in not_exist_image_index:
del self.image_lst[ix-num]
del self.posterior_image_lst[ix-num]
num += 1
def _the_transform_data_from(self, image_url):
data_form = f"""\n<div align=center><img src="{image_url}"></div>\n"""
return data_form
def _save_markdown_text(self, output_file='markdown_processed.txt'):
with open(output_file, mode='w', encoding='utf-8') as f:
f.write(self.markdown_text)
def get_transform(self):
self.get_the_urls()
# Judge the length
assert len(self.image_lst) == len(self.image_2_url_dic), f"上传成功{len(self.image_2_url_dic)}张图片,总共有{len(self.image_lst)}张图片"
for origin_image, image_url in self.image_2_url_dic.items():
self.markdown_text = self.markdown_text.replace(origin_image, self._the_transform_data_from(image_url))
self._save_markdown_text()
if __name__ == '__main__':
cookie = '' # 输入你的cookie
file_path = '' # 输入你要转换的markdown文件地址
upload = UploadPic(cookie)
transform = CSDNTransform(upload, file_path)
markdown_text = transform.get_transform()
# 修改后的 Markdown 在当前目录的 markdown_processed.txt 文件中
参考
requests库post请求参数data、json和files的使用_requests post data-CSDN博客
HTTP协议之multipart/form-data请求分析_http form-data请求-CSDN博客