提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- IK分词器
- 1. IK分词器 下载
- https://github.com/infinilabs/analysis-ik/releases
- 2. 创建文件夹 analysis-ik
- 3.把zip包放至该目录下 解压
- 4. 删除zip包
- 5、重启Elasticsearch, 观察日志
- 使用kibana测试
- 1、细粒度的拆分
- 2、粗粒度的拆分
IK分词器
elasticsearch默认提供了standard分词器,但对中文的分词效果不尽人意
1. IK分词器 下载
- IK中文分词器-Github地址
https://github.com/infinilabs/analysis-ik/releases
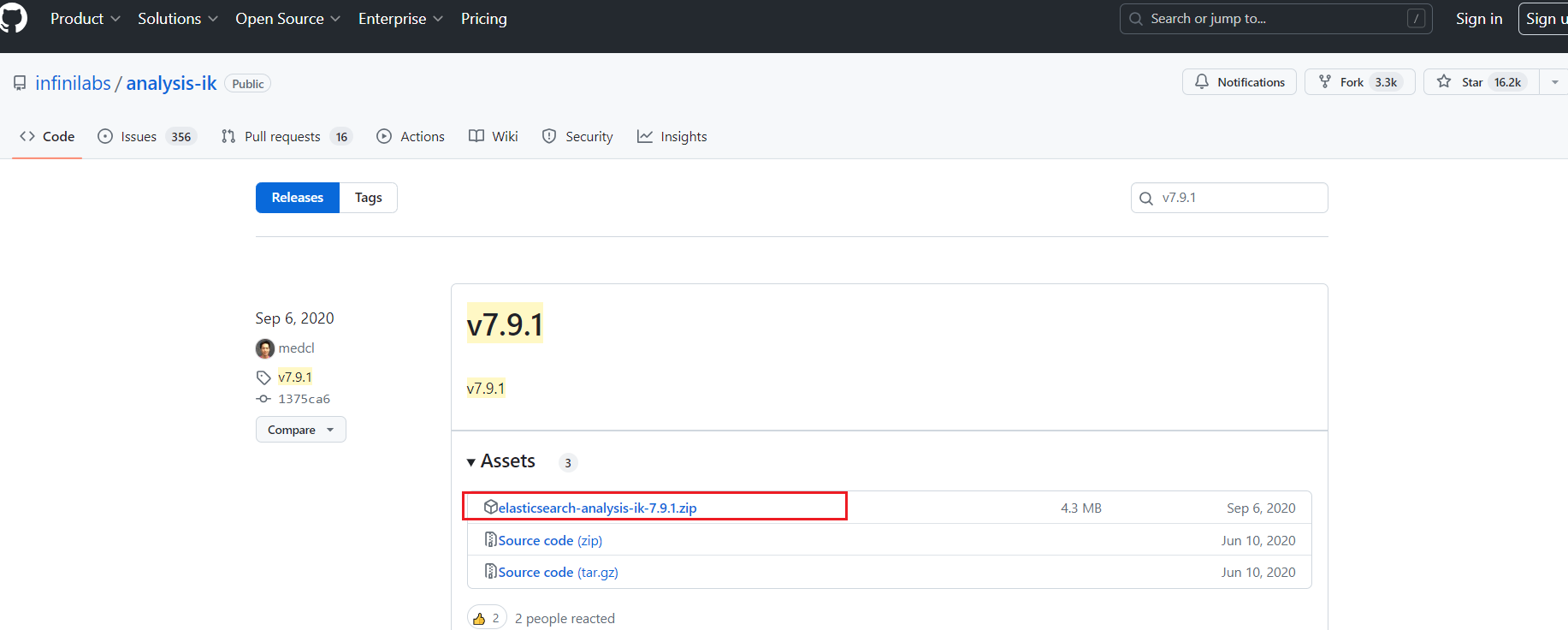
2. 创建文件夹 analysis-ik
创建文件夹 analysis-ik,在/data/es/elasticsearch-7.9.1/plugins/下
3.把zip包放至该目录下 解压
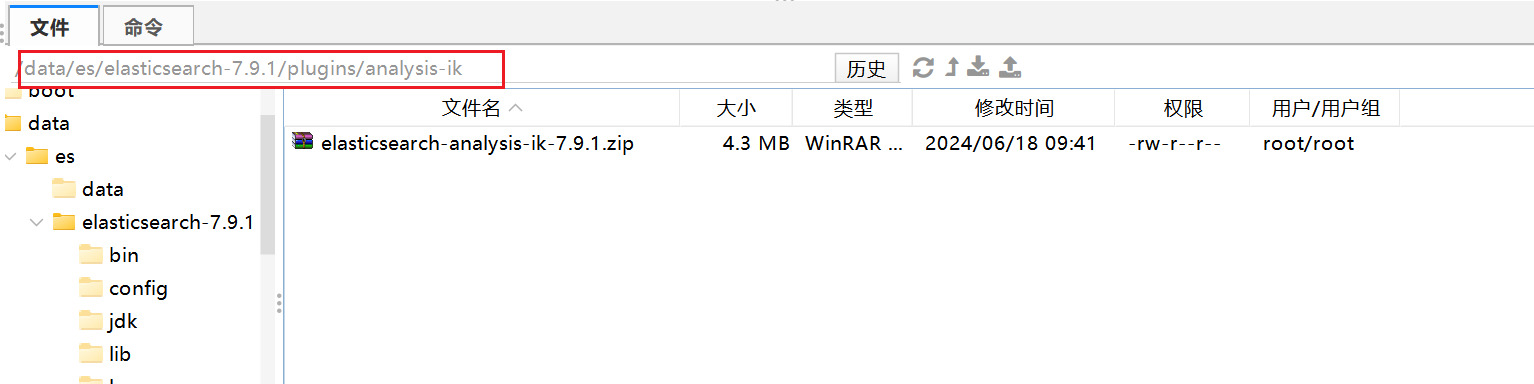
unzip elasticsearch-analysis-ik-7.9.1.zip
4. 删除zip包
rm -rf elasticsearch-analysis-ik-7.9.1.zip
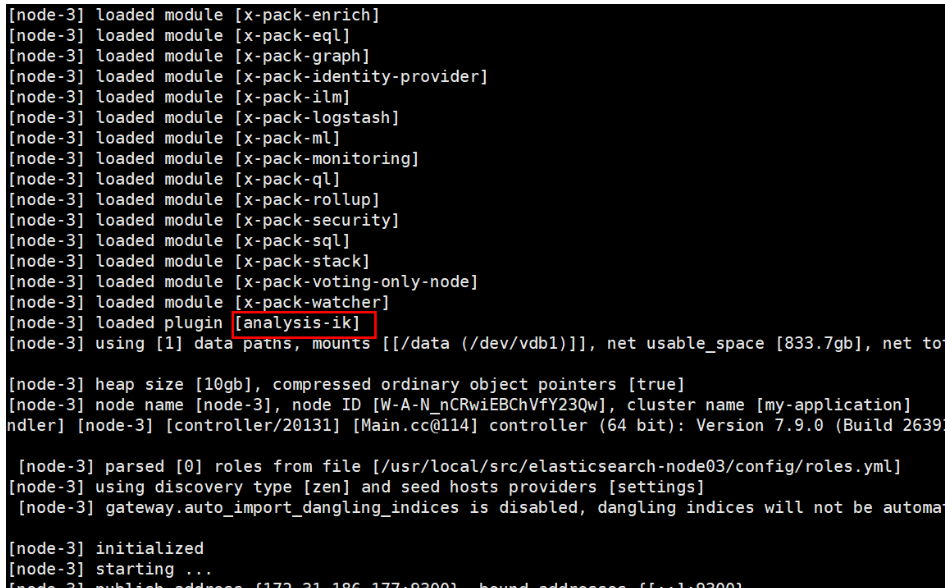
5、重启Elasticsearch, 观察日志

使用kibana测试
IK提供两种分词算法:ik_smart 和 ik_max_word
- ik_smart : 最粗粒度的拆分
- ik_max_word : 最细粒度的拆分
1、细粒度的拆分
POST _analyze
{
"analyzer": "ik_max_word",
"text": ["中华人民共和国万岁"]
}
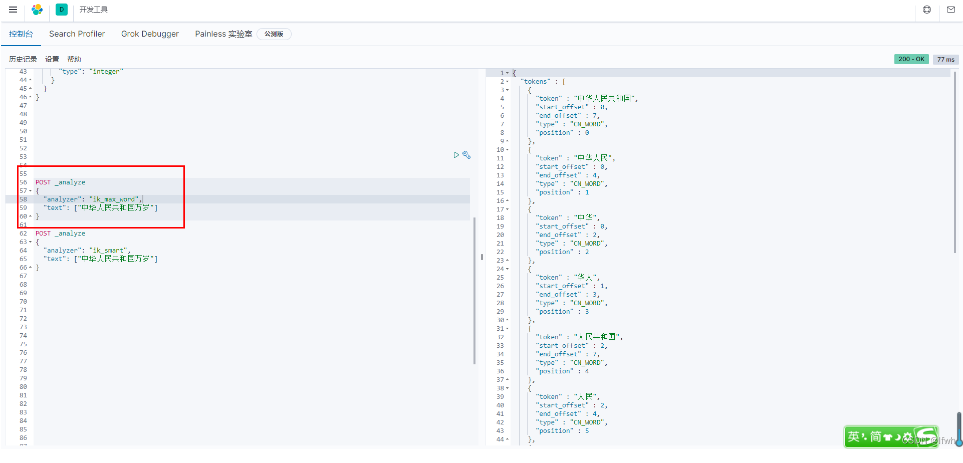
2、粗粒度的拆分
POST _analyze
{
"analyzer": "ik_smart",
"text": ["中华人民共和国万岁"]
}