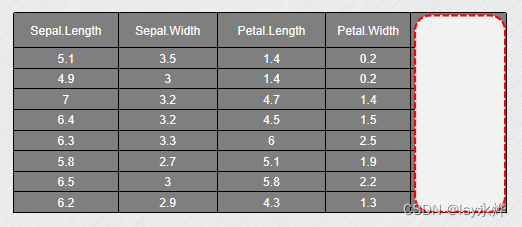
大数据技术与实践期末复习
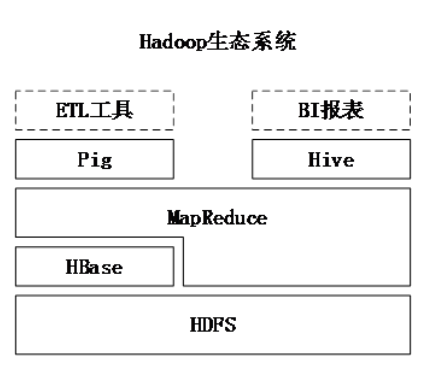
生态系统
每一张图片都值得思考,理清楚到底是什么!
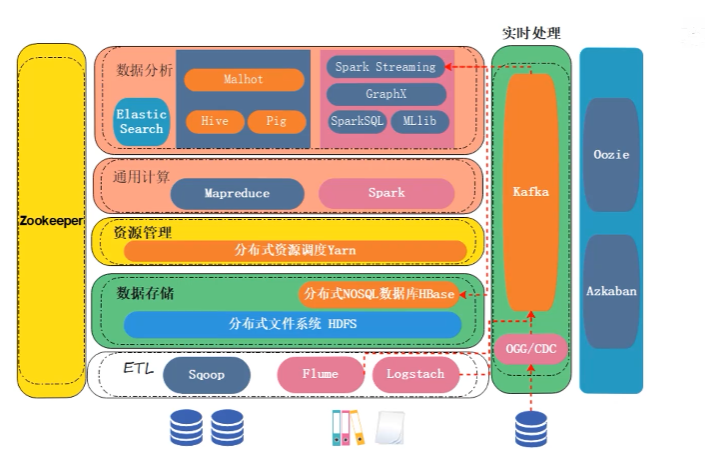
1.结构化数据(数据库里面的):Sqoop(效率比较慢/隔一段时间抽取一次)
2.半结构化或者非结构化数据:Flume/Logstach(实时/消息队列(Kafaka))
3.Hbase(解决了小文件问题)基于HDFS
4.存储之后进行计算,使用mapReduce(慢一些)/Spark
5.Yarn相当于管理HDFS中节点的资源(CPU等等)
6.Hive/Pig将SQL转换成底层的mapReduce(通用计算)
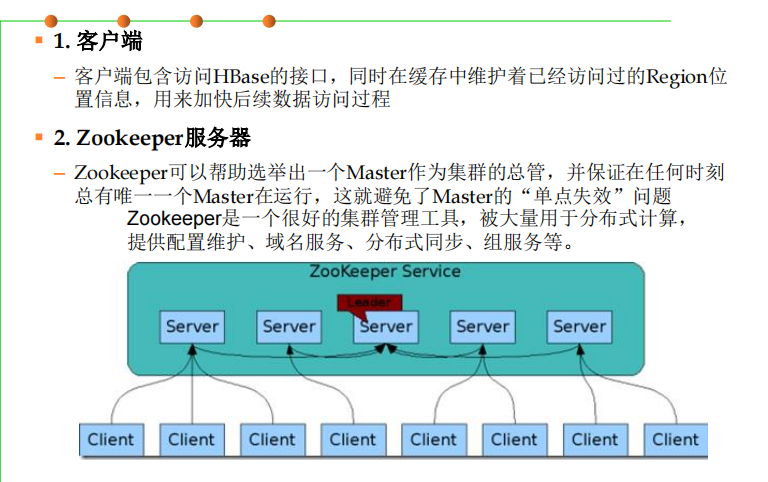
7.Zookeeper(分布式的协调服务),可以来协调HDFS中的节点
8.Oozie和Azkaban是任务调度组件,调度计算任务(优先级)
大数据技术概述
大数据与其他新技术之间的关系
HDFS
分布式文件系统
分布式文件系统把文件分布存储到多个计算机节点上,成千上万的计算机节点构成计算机集群。
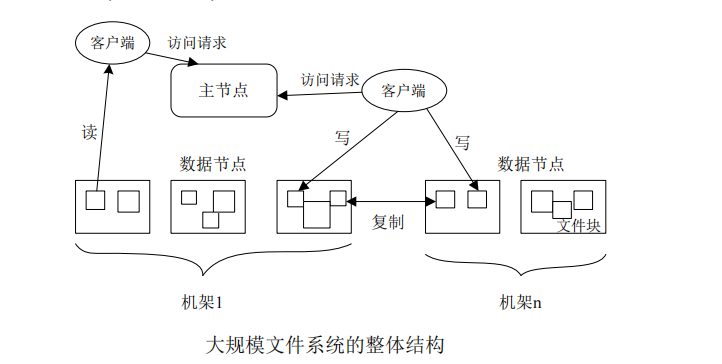
HDFS简介

HDFS采用抽象的块概念带来的好处:
1.支持大规模文件存储(文件块存储)
2.简化系统设计
3.适合数据备份
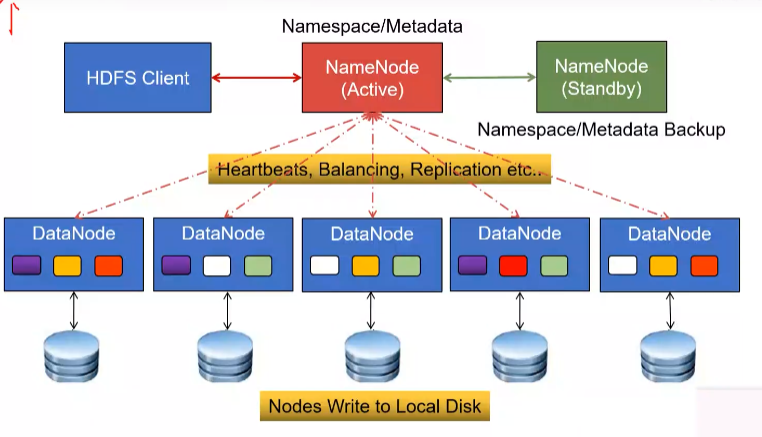
NameNode和DataNode
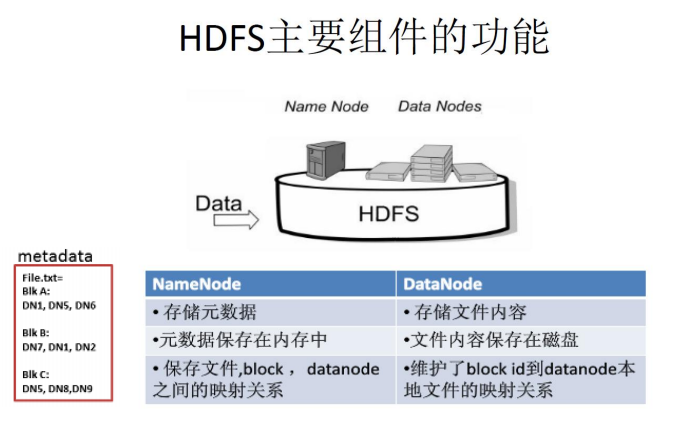
HDFS相关概念
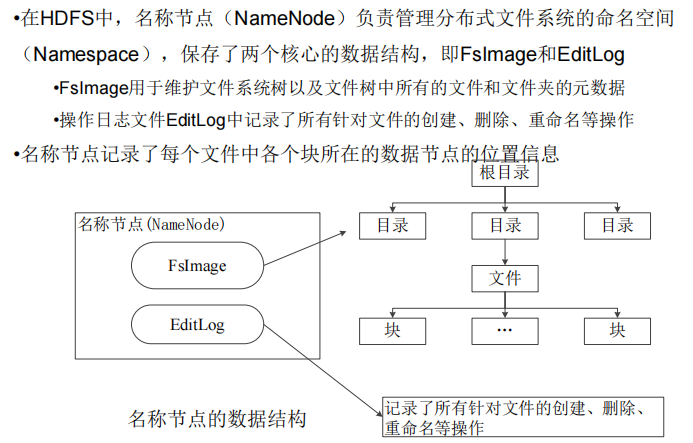
EditLog里面存储的相当于内存中的元数据存储到磁盘中,修改的日志
◼ 数据节点是分布式文件系统HDFS的工作节点,负责数据的存储和读取,会根据客户端或者是名称节点的调度来进行数据的存储和检索,并且向名称节点定期发送自己所存储的块的列表。
◼ 每个数据节点中的数据会被保存在各自节点的本地Linux文件系统中。
HDFS体系结构
通信协议
◼ HDFS是一个部署在集群上的分布式文件系统,因此,很多数据需要通过网络进行传输。
◼ 所有的HDFS通信协议都是构建在TCP/IP协议基础之上的。
◼ 客户端通过一个可配置的端口向名称节点主动发起TCP连接,并使用客户端协议与名称节点进行交互。
◼ 名称节点和数据节点之间则使用数据节点协议进行交互。
◼ 客户端与数据节点的交互是通过RPC(Remote Procedure Call)来实现的。在设计上,名称节点不会主动发起RPC,而是响应来自客户端和数据节点的RPC请求。
只设置一个NameNode节点的局限性:
1.命名空间的限制
2.性能的瓶颈
3.隔离问题
4.集群的可用性
HDFS存储原理
冗余数据保存
(1)加快数据传输速度
(2)容易检查数据错误
(3)保证数据可靠性
数据存取策略
调度管理
数据错误与恢复
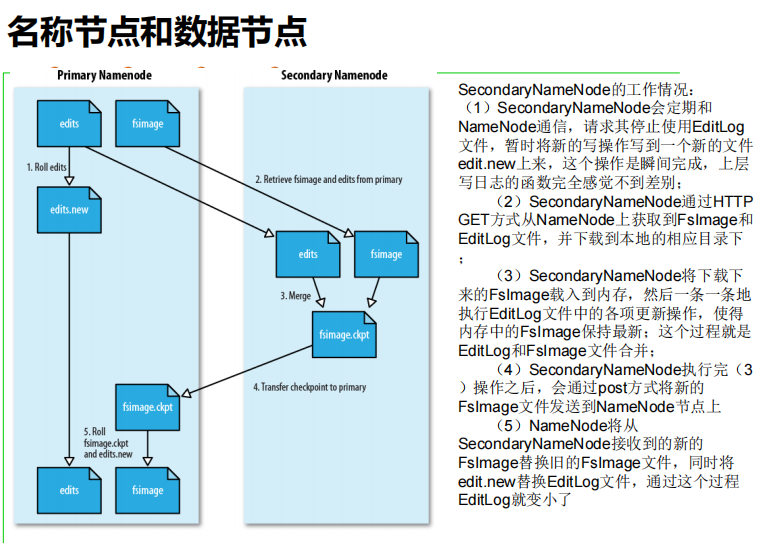
1.namenode出错(secondaryNameNode备份最重要的两个数据结构–>FsImage和EditLog)
2.datanode出错 – dataNode每隔一个时间段(3s)向nameNode上报信息(存储的内容,健康状态(负载状态))
3.数据出错:md5和sha1校验,客户端进行判断,定期检查和复制
文件上传之前要先切块(128M),然后存到dataNode(还要备份),保持每个3份
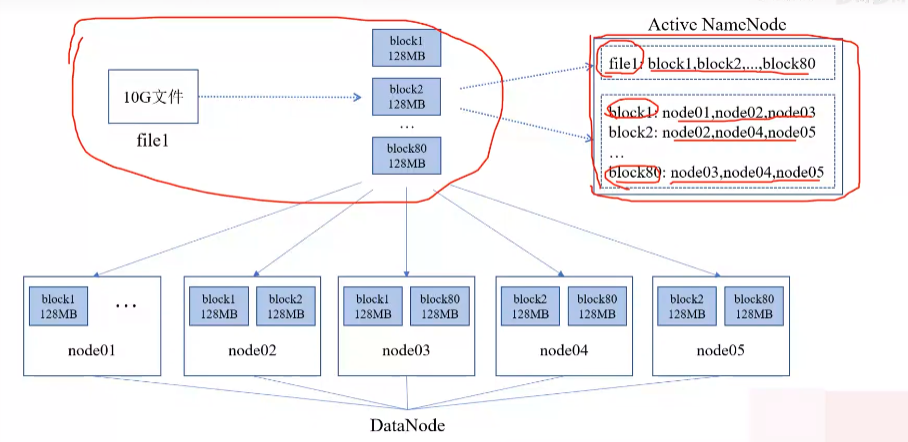
dataNode每隔一个时间段(3s)向nameNode上报信息(存储的内容,健康状态(负载状态))
HDFS数据读写过程
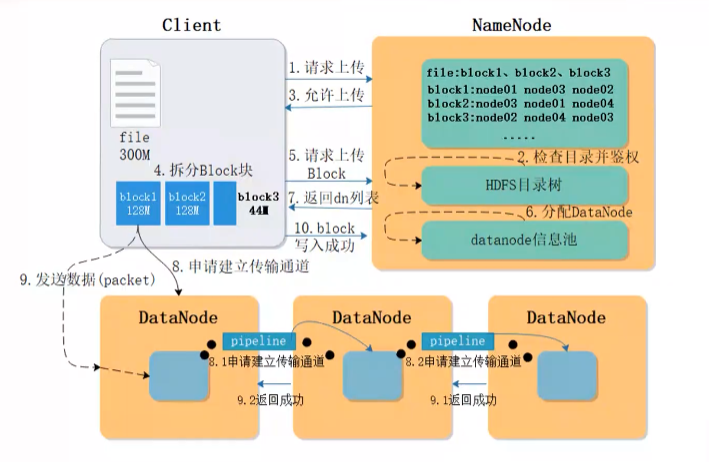
HDFS写操作:
`import java.io.BufferedReader;
import java.io.InputStreamReader;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.FSDataInputStream;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”,“hdfs://localhost:9000”);
conf.set(“fs.hdfs.impl”,“org.apache.hadoop.hdfs.DistributedFileSystem”);
FileSystem fs = FileSystem.get(conf);
Path file = new Path(“test”);
FSDataInputStream getIt = fs.open(file);
BufferedReader d = new BufferedReader(new
InputStreamReader(getIt));
String content = d.readLine(); //读取文件一行
System.out.println(content);
d.close(); //关闭文件
fs.close(); //关闭hdfs
} catch (Exception e) {
e.printStackTrace();
}
}`
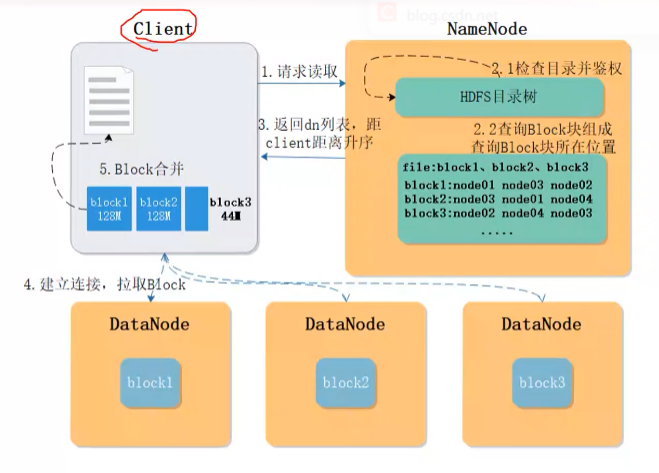
读操作:
`import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.Path;
public class Chapter3 {
public static void main(String[] args) {
try {
Configuration conf = new Configuration();
conf.set(“fs.defaultFS”,“hdfs://localhost:9000”);
conf.set(“fs.hdfs.impl”,“org.apache.hadoop.hdfs.DistributedFileSystem”);
FileSystem fs = FileSystem.get(conf);
byte[] buff = “Hello world”.getBytes(); // 要写入的内容
String filename = “test”; //要写入的文件名
FSDataOutputStream os = fs.create(new Path(filename));
os.write(buff,0,buff.length);
System.out.println(“Create:”+ filename);
os.close();
fs.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}`
进入到安全模式,就只能读取了
HBase
概述
HBase是一个高可靠、高性能、面向列、可伸缩的分布式数据库。
HBase和传统的关系数据库的区别:
1.数据类型:将数据存储为未经解释的字符串。
2.数据操作:避免了复杂的表和表之间的关系。
3.存储模式:关系数据库是基于行模式存储的。HBase是基于列存
储的,每个列族都由几个文件保存,不同列族的文件是分离的。
4.数据索引(只有行键索引)
5.数据维护(保留旧版本)
6.可伸缩性(减少硬件数量来实现性能的伸缩)
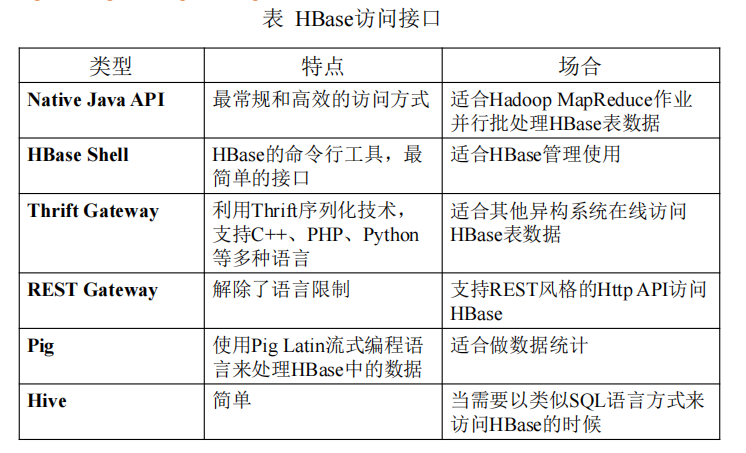
HBase访问接口
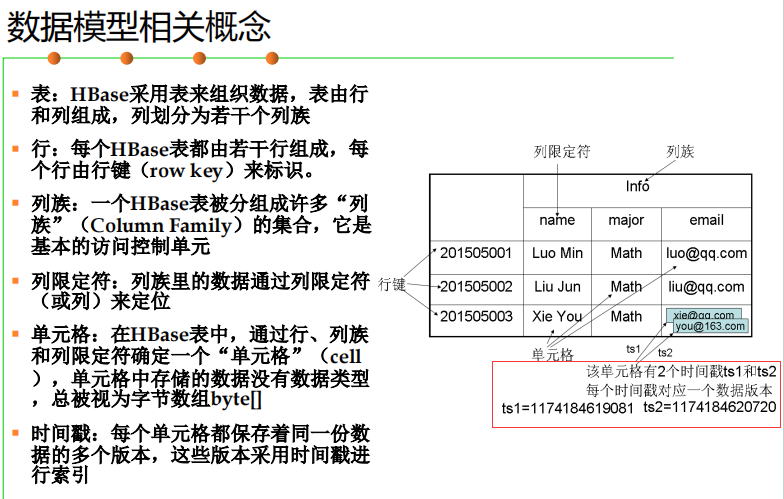
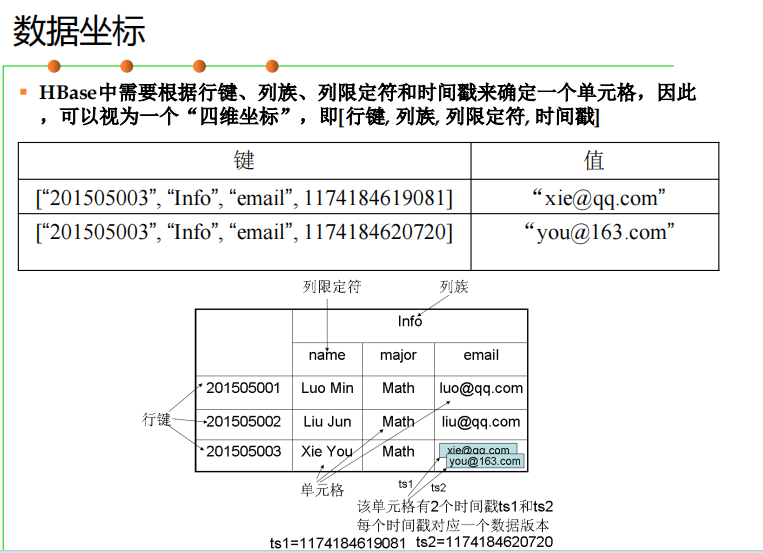
HBase数据模型
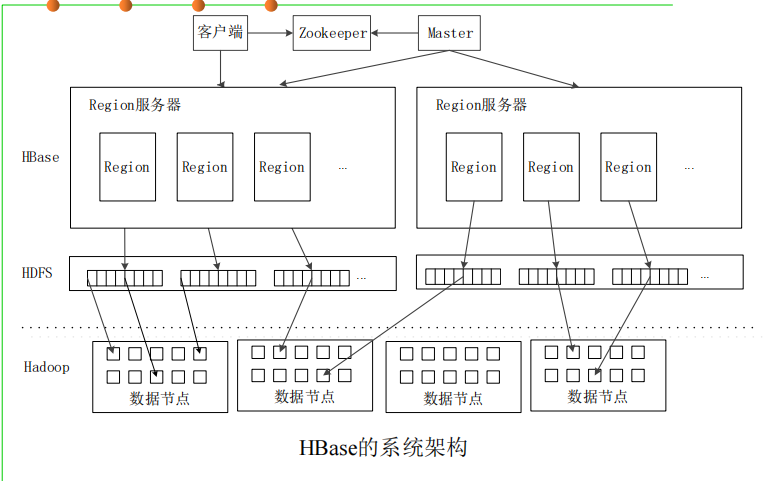
HBase的实现原理
HBase的实现包括三个主要的功能组件:
– (1)库函数:链接到每个客户端
– (2)一个Master主服务器
– (3)许多个Region服务器
▪ 主服务器Master负责管理和维护HBase表的分区信息,维护Region服 务器列表,分配Region,负载均衡
▪ Region服务器负责存储和维护分配给自己的Region,处理来自客户端 的读写请求
▪ 客户端并不是直接从Master主服务器上读取数据,而是在获得Region 的存储位置信息后,直接从Region服务器上读取数据
▪ 客户端并不依赖Master,而是通过Zookeeper来获得Region位置信息 ,大多数客户端甚至从来不和Master通信,这种设计方式使得Master 负载很小
HBase运行机制

HBase应用方案
HBase实际应用中的性能优化方法
行键 InMemory Max Version Time To Live
HBase性能监视
•Master-status(自带)
•Ganglia
•OpenTSDB
•Ambar
在HBase之上构建SQL引擎
NoSQL区别于关系型数据库的一点就是NoSQL不使用SQL作为查询语言,
至于为何在NoSQL数据存储HBase上提供SQL接口,有如下原因:
1.易使用。使用诸如SQL这样易于理解的语言,使人们能够更加轻
松地使用HBase。
2.减少编码。使用诸如SQL这样更高层次的语言来编写,减少了编
写的代码量。
方案:
1.Hive整合HBase
2.Phoenix
构建HBase二级索引
HBase只有一个针对行健的索引
访问HBase表中的行,只有三种方式:
•通过单个行健访问
•通过一个行健的区间来访问
•全表扫描
使用其他产品为HBase行健提供索引功能:
•Hindex二级索引
•HBase+Redis
•HBase+solr
MapReduce
概述

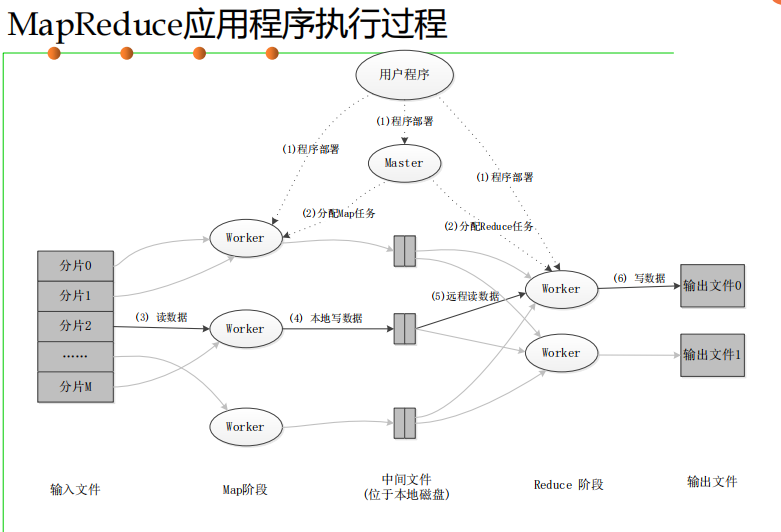
MapReduce体系结构
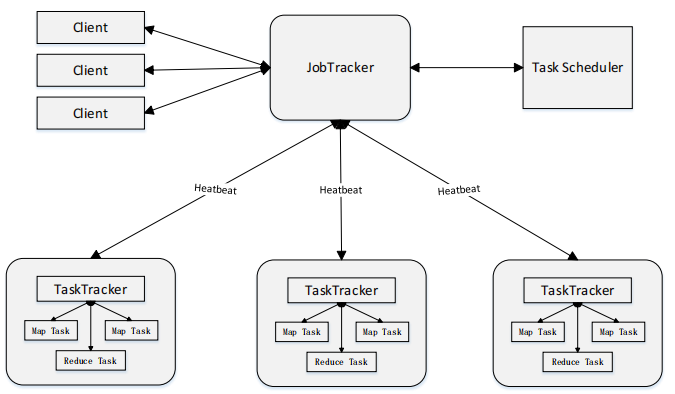
MapReduce体系结构主要由四个部分组成,分别是:Client、JobTracker、TaskTracker以及Task。
MapReduce工作流程
shuffle过程对hash取模
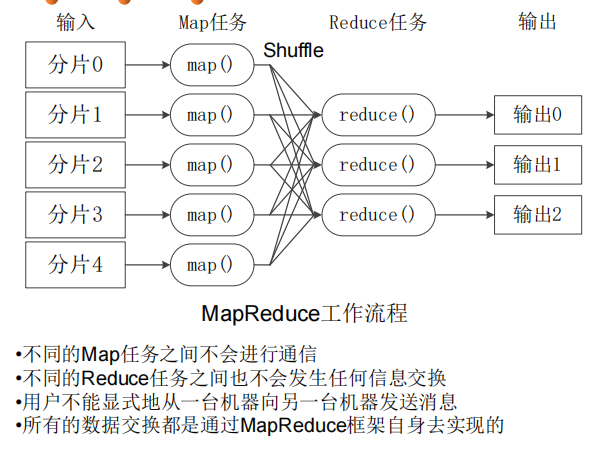
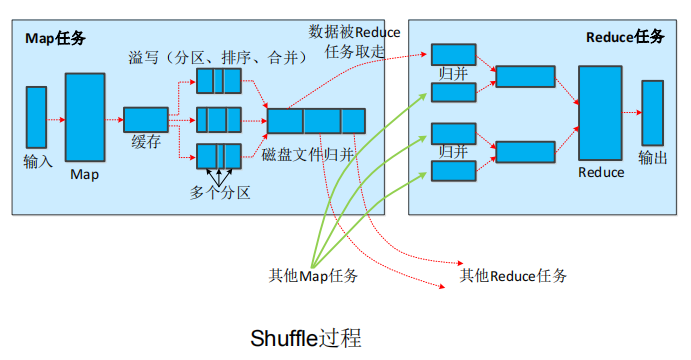
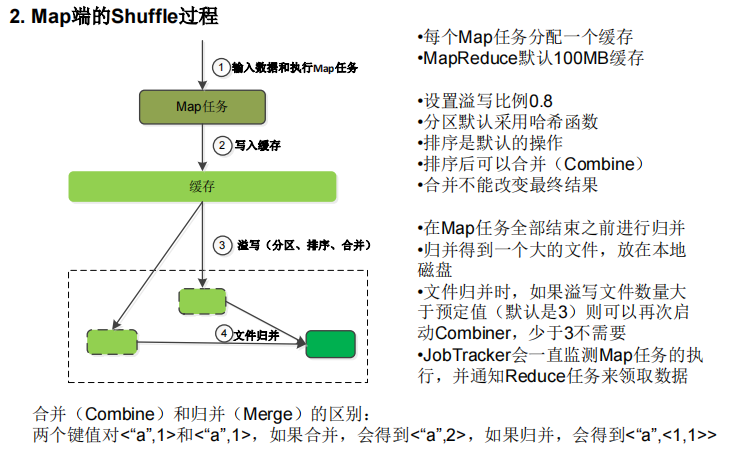
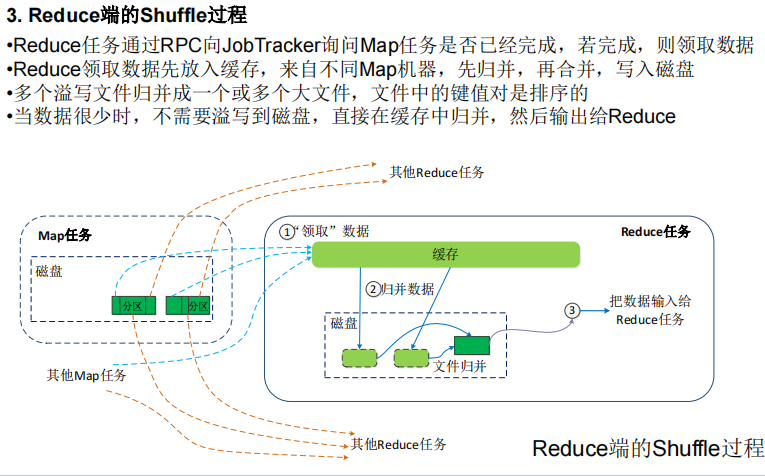
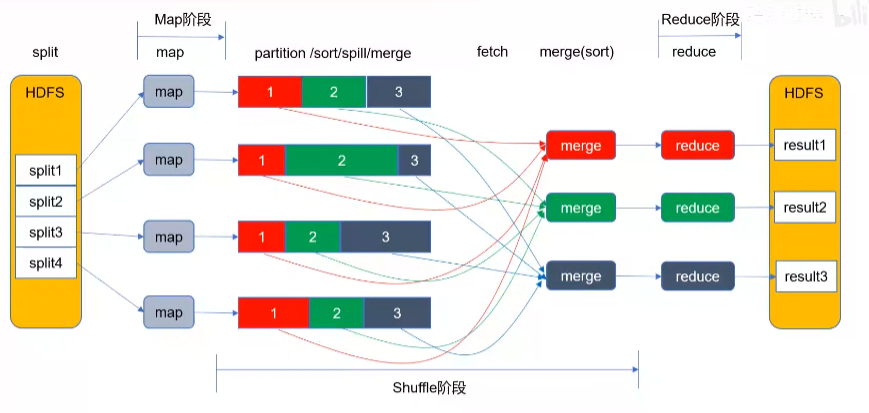
四个阶段:split,map,shuffle,reduce
shuffle阶段会在内存与磁盘之间多次读取数据
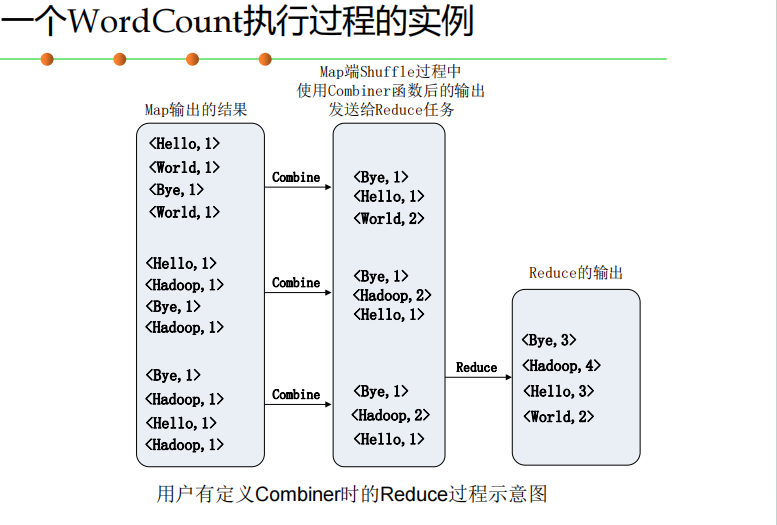
实例分析:WordCount ⭐⭐
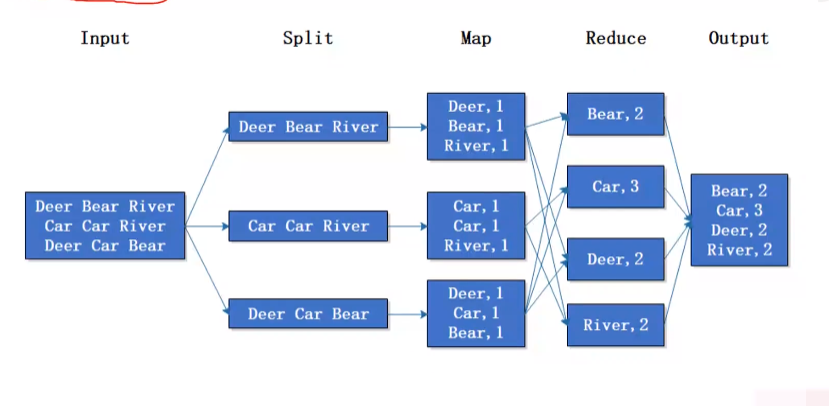
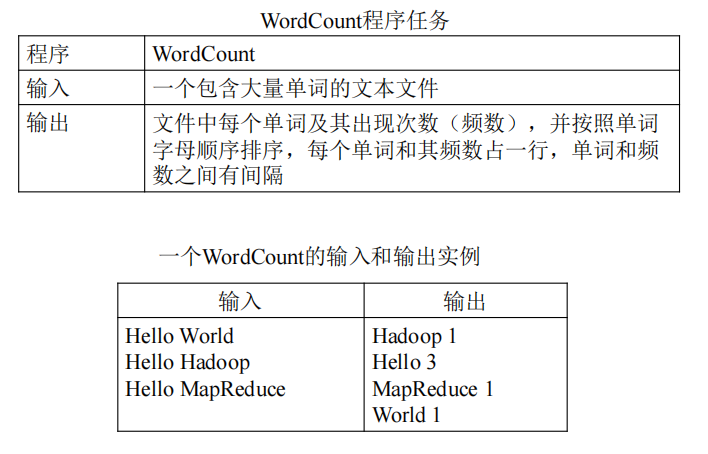

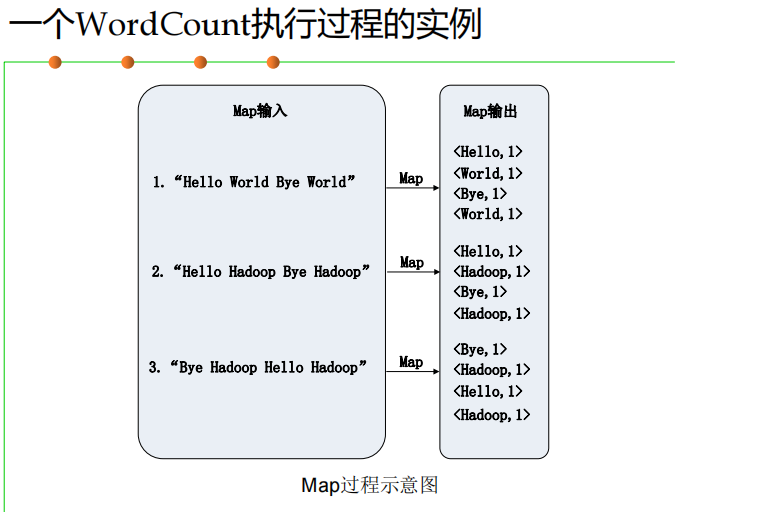
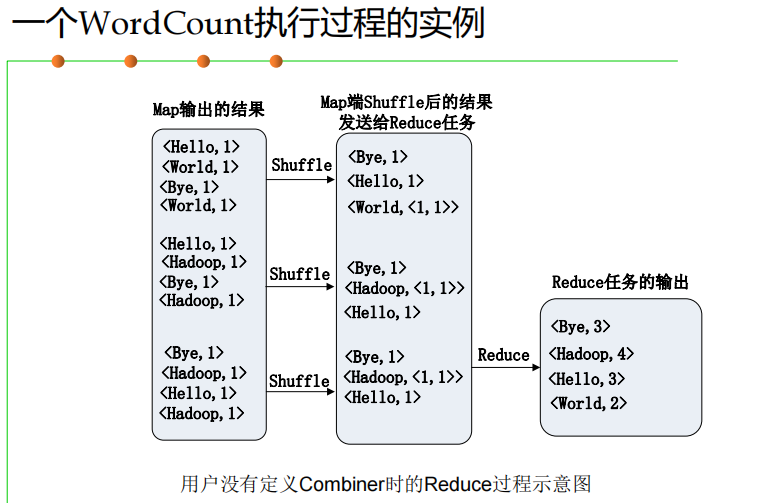
MapReduce的具体应用
MapReduce可以很好地应用于各种计算问题
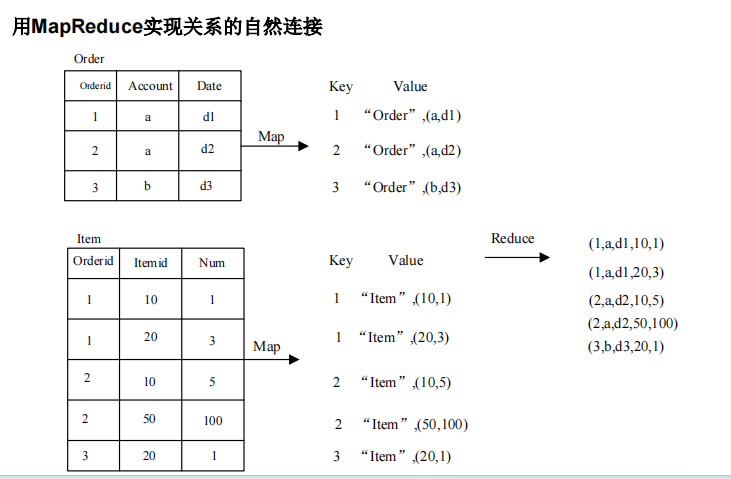
▪ 关系代数运算(选择、投影、并、交、差、连接)
▪ 分组与聚合运算
▪ 矩阵向量乘法
▪ 矩阵乘法
Hive
Hive是一个构建于Hadoop顶层的数据仓库工具。
概述


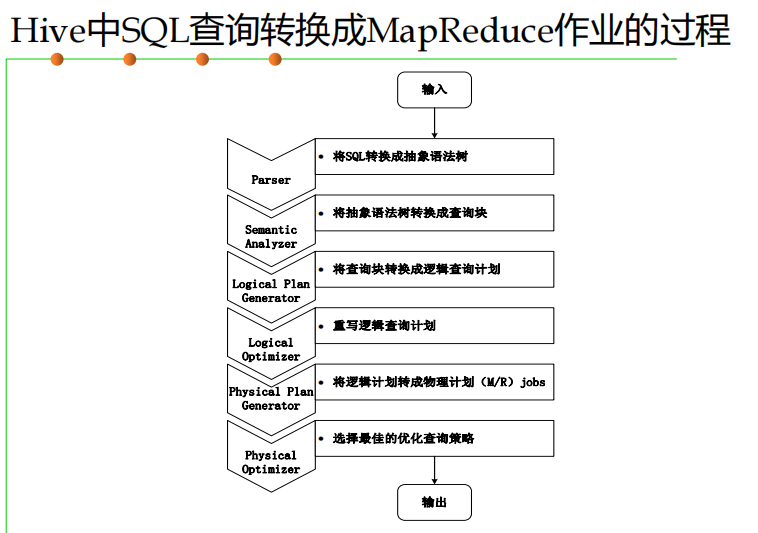
Hive系统架构

Hive的应用
Impala
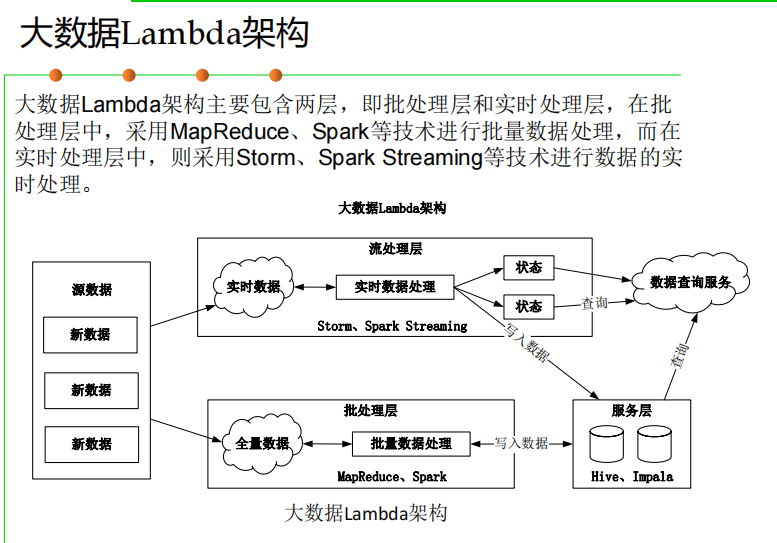
批处理层和实时处理层
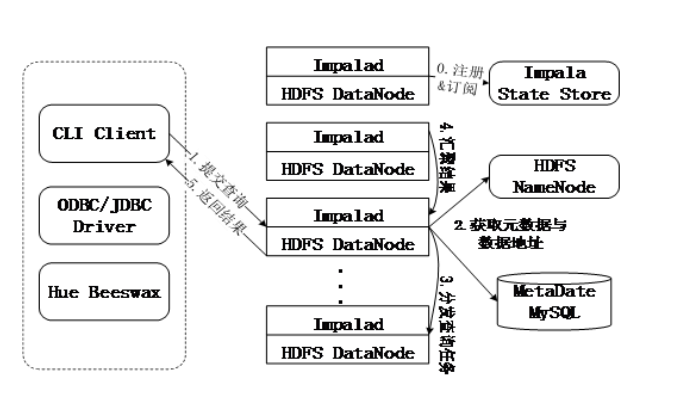
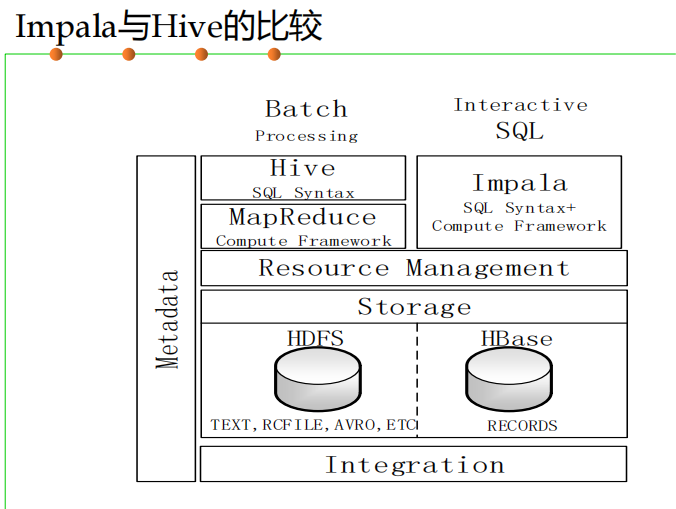
Hive编程实践
Hive有三种运行模式,单机模式、伪分布式模式、分布式模式。


Spark
Spark概述
Spark具有如下几个主要特点:
•运行速度快:使用DAG执行引擎以支持循环数据流与内存计算
•容易使用:支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程
•通用性:Spark提供了完整而强大的技术栈,包括SQL查询、流式计算、机器学习和图算法组件
•运行模式多样:可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源


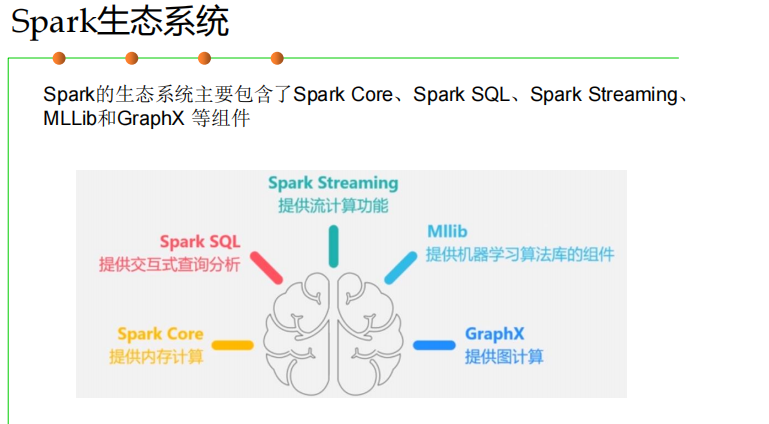
Spark生态系统
Spark运行架构
RDD是只读的
RDD操作 Transformation和Action
RDD之间的依赖关系 宽依赖(走shuffle)窄依赖(一对一)
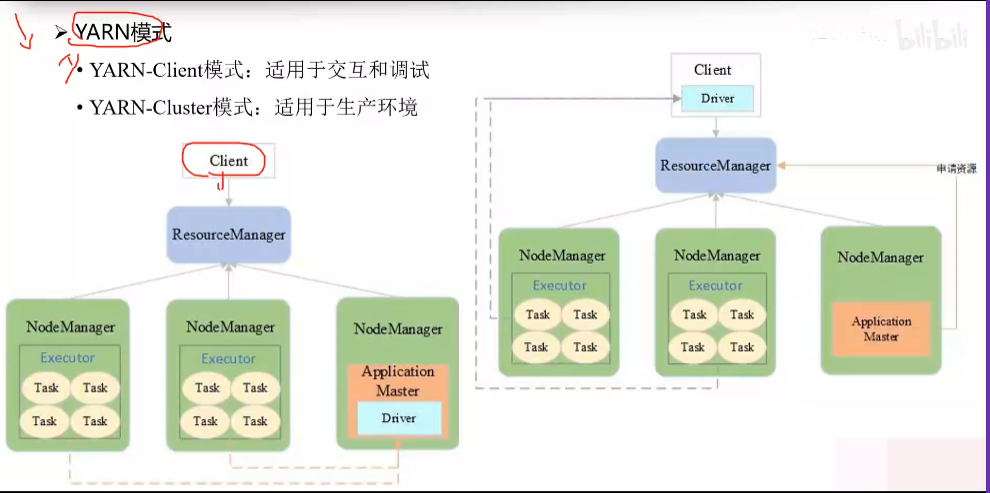
在yarn ,作业管理节点叫做application master
申请的资源叫做container
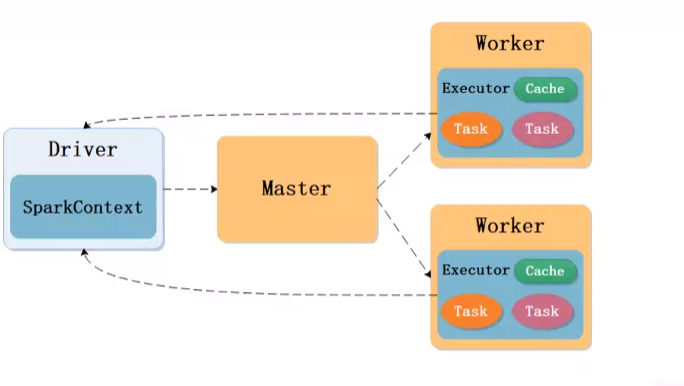
在spark,作业管理节点叫做Driver
申请的资源叫做executor(可以运行多个task)
Spark SQL
Spark的部署和应用方式
Spark编程实践
Flink
Flink简介
主要特性:批流一体化、精密的状态管理、事件时间支持、精确一次的状态一致性保障
为什么选择Flink
流处理架构
Flink具有以下优势:
(1)同时支持高吞吐、低延迟、高性能
(2)同时支持流处理和批处理
(3)高度灵活的流式窗口
(4)支持有状态计算
(5)具有良好的容错性
(6)具有独立的内存管理
(7)支持迭代和增量迭代
Flink应用场景
事件驱动型应用
数据分析应用
数据流水线应用
Flink技术栈
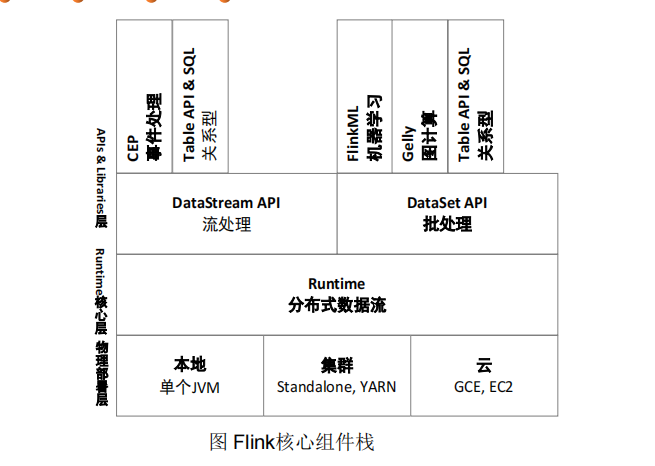
Flink体系架构
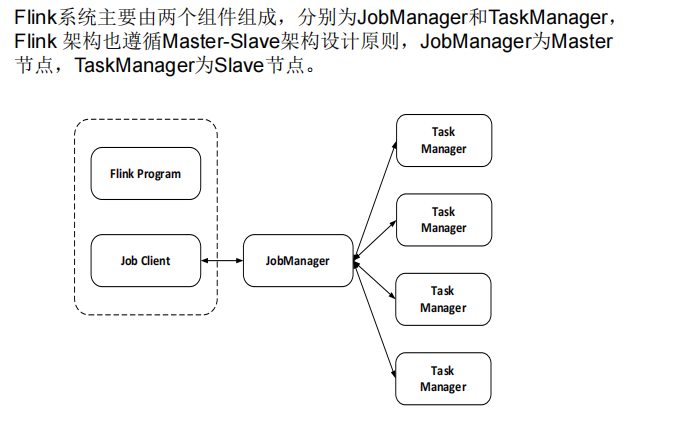
Flink编程模型

Flink编程实践
理解数据
大数据技术综合应用
数据量大
数据类型多
处理速度快
价值密度低