ELK日志分析
一、ELK概述
1、ELK简介
ELK平台是一套完整的日志集中处理解决方案,将ElasticSearch、Logstash和Kiabana三个开源工具配合使用,完成更强大的用户对日志的查询、排序、统计需求。
一个完整的集中式日志系统,需要包含以下几个主要特点:
- 收集-能够采集多种来源的日志数据
- 传输-能够稳定的把日志数据传输到中央系统
- 存储-如何存储日志数据
- 分析-可以支持 UI 分析
- 警告-能够提供错误报告,监控机制
tip:
linux时间同步
安装工具
yum -y install ntp ntpdate
同步网络时间
ntpdate cn.pool.ntp.org
2、ELK组成
(1)ElasticSearch
• 是基于Lucene(一个全文检索引擎的架构)开发的分布式存储检索引擎,用来存储各类日志
• Elasticsearch是用Java开发的,可通过RESTful Web接口,让用户可以通过浏览器与Elasticsearch通信
• Elasticsearch是个分布式搜索和分析引擎,优点是能对大容量的数据进行接近实时的存储、搜索和分析操作
• Elasticsearch可以划分为三种:主节点、数据节点和客户端节点
1、master主节点:
elasticsearch.yml:
node.master:true
node.data:false
主要功能:维护元数据,管理集群节点状态;不负责数据写入和查询
配置要点:内存可以相对小一些,但是机器一定要稳定,最好是独占的机器
2、data数据节点
elasticsearch.yml:
node.master:false
node.data:true
主要功能:负责数据的写入与查询,压力大
配置要点:大内存,最好是独占的机器
3、client客户端节点
elasticsearch.yml:
node.master:true
node.data:true
主要功能:综合上述三个节点的功能。
配置要点:大内存,最好是独占的机器。
特别说明:不建议这种配置,节点容易挂掉
4、一般配置主节点3台服务器,数据节点与客户端节点配置比例一般在3:1左右,根据实际情况调节
(2)Logstash
• 作为数据收集引擎。它支持动态的从各种数据源搜集数据,并对数据进行过滤、分析、丰富、统一格式等操作,然后存储到用户指定的位置,一般会发送给Elasticsearch
• Logstash由JRuby语言编写,运行在Java虚拟机(JVM)上,是一款强大的数据处理工具,可以实现数据传输、格式处理、格式化输出。Logstash具有强大的插件功能,常用于日志处理
(3)Kibana
是基于Node.js开发的展示工具,可以为Logstash和ElasticSearch提供图形化的日志分析Web界面展示,可以汇总、分析和搜索重要数据日志
(4)Filebeat
轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat就能快速收集数据,并发送给logstash进行解析,或是直接发给Elasticsearch存储,性能上相比运行于JVM上的loqstash优势明显,是对它的替代

3、为什么要使用ELK
(1)日志主要包括-系统日志,应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及。错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
(2)往往单台机器的日志我们使用grep、awk等工具就能基本实现简单析,但是当日志被分散的储存不同的设备上。如果你管理数十上百台服务器,你还在使用依次登录每台机器的传统方法查阅日志。这样感觉很繁琐和效率低下。
(3)当务之急我们使用集中化的日志管理,例如∶开源的syslog,将所有服务器上的日志收集汇总。集中化管理日志后,日志的统计和检索又成为一件比较麻烦的事情,一般我们使用grep、awk和wc等Linux命令能实现检索和统计,但是对于要求更高的查询、排序和统计等要求和庞大的机器数量依然使用这样的方法难免有点力不从心。
(4)一般大型系统是一个分布式部署的架构,不同的服务模块部署在不同的服务器上,问题出现时,大部分情况需要根据问题暴露的关键信息,定位到具体的服务器和服务模块,构建一套集中式日志系统,可以提高定位问题的效率。
4.ELK的主要特点
存储:面向文档+JSON
(1)面向文档
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储,还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。这种理解数据的方式与以往完全不同,这也是Elasticsearch能够执行复杂的全文搜索的原因之一。
(2)JSON
ELasticsearch使用Javascript对象符号(JavaScript Object Notation),也就是JSON,作为文档序列化格式。JSON现在已经被大多语言所支持,而且已经成为NoSQL领域的标准格式。它简洁、简单且容易阅读。尽管原始的user对象很复杂,但它的结构和对象的含义已经被完整的体现在JSON中了,在Elasticsearch中将对象转化为JSON并做索引要比在表结构中做相同的事情简单的多。传统数据库有表名.字段.,属性 然后对应下面行为数据,但是在es中不区分,统一将一行数据转换为json格式进行存储,所以es中存储非格式化的方式。
以下是一个表示嵌套JSON的示例:
{
"person": {
"name": "John",
"age": 30,
"address": {
"street": "123 Main St",
"city": "New York",
"state": "NY",
"zipcode": "10001"
},
"phone_numbers": [
{
"type": "home",
"number": "555-1234"
},
{
"type": "work",
"number": "555-5678"
}
]
}
}
在上面的示例中,“person"是一个对象,它包含了"name”、“age”、"address"和"phone_numbers"四个属性。其中,“address"是一个对象,它包含了"street”、“city”、"state"和"zipcode"四个属性。"phone_numbers"是一个数组,它包含了两个元素,每个元素是一个对象,包含了"type"和"number"两个属性。
检索:倒排+乐观锁(了解)
(1)倒排
倒排是一种索引方法,用来存储在全文检索下某个单词在一个/组文档中的存储位置,也常被称为反向索引、置入档案或反向档案。也是ES为何具有高检索性能的原因。
- 一般的正向索引
一般的正向索引要搜索某个单词,是遍历文档,检查文档中是否有这个单词。
文档1>>[单词1,单词2]
文档2>>[单词1,单词2,单词3]
- 倒排索引
而倒排索引是建立一个映射关系,确定单词属于哪几个文档
单词1>>[文档1,文档2]
单词2>>[文档1,文档2,文档3]
ES中采用的就是倒排索引结构。
(2)冲突处理和修改操作
ES采用乐观锁处理冲突,乐观锁概念参考Elasticsearch-并发冲突处理机制,因此在执行一些操作时可能要进行多次操作才可以完成,并且ES的修改操作有以下方面有几个特性
修改:
- 文档不能被修改,只能被替换
删除:
-
文档删除操作只是标记为”已删除“,并没有真正释放内存
-
尽管不能再对旧版本的文档进行访问,但它并不会立即消失
-
当继续索引更多的数据,Elasticsearch 会在后台清理这些已删除文档
-
删除索引会直接释放内存
分析:监控+预警+可视化
ELK将所有节点上的日志统一收集,传输,存储,管理,访问,分析,警告,可视化。
它提供了大量应用于监控的可视化界面,例如Uptime、Metric、Machine Learning、DashBoard、Stack Monitoring,都是我们将系统/服务器/应用的数据传入ES后,就可以利用Kibana的模板来展示相关内容。
对于各种常见的采集器采集到的数据,官方提供了一系列对应的模板,但是我们也可以针对自己的数据自定义,来按需求展示想要的信息。
关于各个板块的具体展示内容和查看方式,在后文具体提到,见三、Beats和四、Kibana+插件。
支持集群
集群真正的扩容能力是来自于水平扩容–为集群添加更多的节点,并且将负载压力和稳定性分散到这些节点中。
(1)ES集群特点
一个集群拥有相同的cluster.name 配置的节点组成, 它们共同承担数据和负载的压力
主节点负责管理集群的变更例如增加、删除索引,或者增加、删除节点等。 而主节点并不需要涉及到文档级别的变更和搜索等操作
(2)分片的特点
Elasticsearch 是利用分片将数据分发到集群内各处
分片是数据的容器,文档保存在分片内
分片又被分配到集群内的各个节点里
当集群规模变动,ES会自动在各个节点中迁移分片。使得数据仍然均匀分布在集群中
副分片是主分片的一个拷贝,作为硬件故障时的备份。并提供返回文档读操作
在创建索引时,确定主分片数,但是副分片可以在后面进行更改
5.ELK工作原理
- 在所有需要收集日志的服务器上部署Logstash;或者先将日志进行集中化管理在日志服务器上,在日志服务器上部署 Logstash。
- Logstash 收集日志,将日志格式化并输出到 Elasticsearch 群集中。
- Elasticsearch 对格式化后的数据进行索引和存储。
- Kibana 从 ES 群集中查询数据生成图表,并进行前端数据的展示。
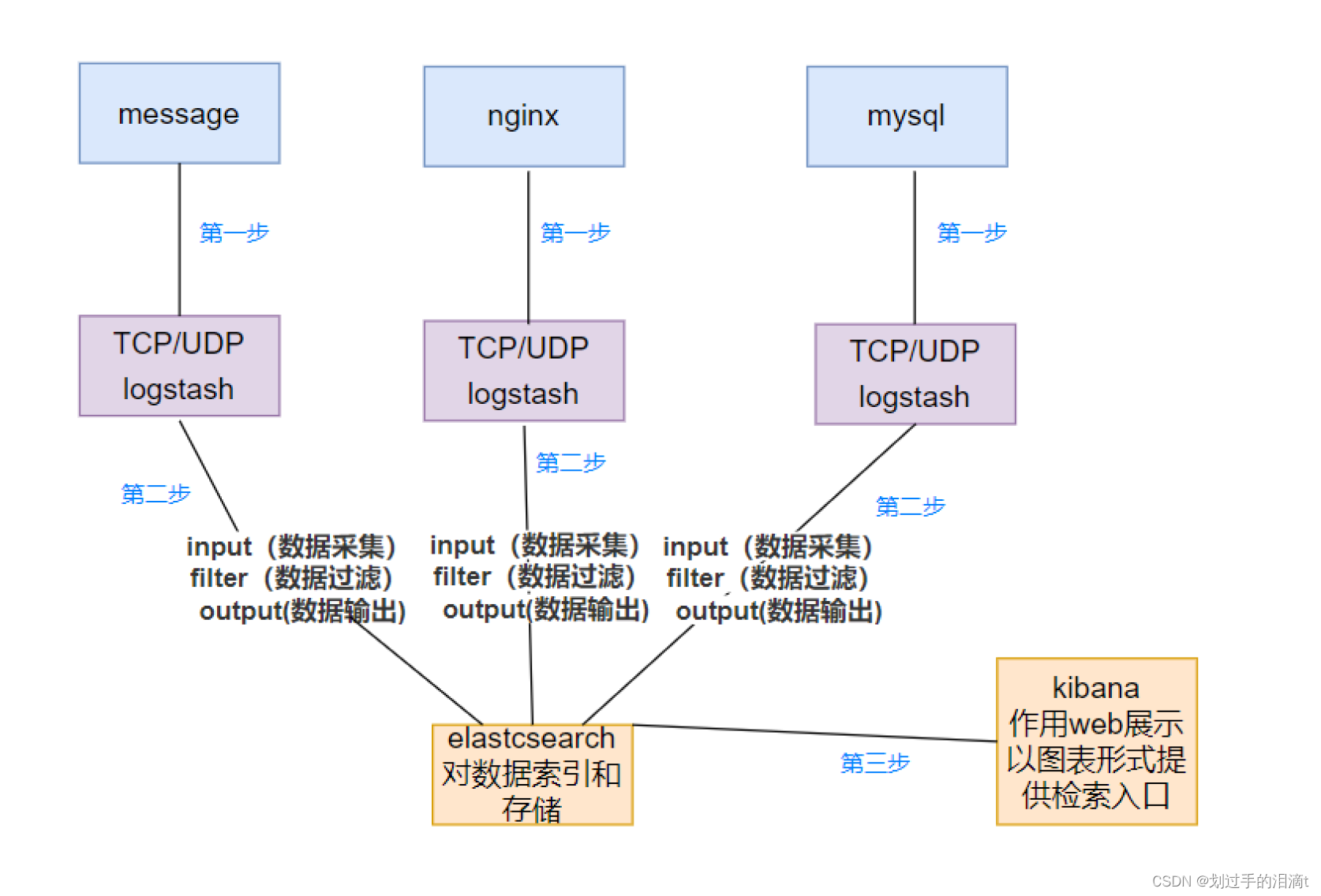
总结:logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana对日志进行可视化处理
ElasticSearch工作原理
ElasticSearch(简称ES)是一个基于Lucene构建的开源、分布式、RESTful的全文本搜索引擎。
不过,ElasticSearch却也不仅只是一个全文本搜索引擎,它还是一个分布式实时文档存储,其中每个field均是被索引的数据且可被搜索;也是一个带实时分析功能的分布式搜索引擎,并且能够扩展至数以百计的服务器存储及处理PB级的数据。
如前所述,ElasticSearch在底层利用Lucene完成其索引功能,因此其许多基本概念源于Lucene。
说说ES的基本概念。
索引(Index)
ES将数据存储于一个或多个索引中,索引是具有类似特性的文档的集合。类比传统的关系型数据库领域来说,索引相当于SQL中的一个数据库,或者一个数据存储方案(schema)。
索引由其名称(必须为全小写字符)进行标识,并通过引用此名称完成文档的创建、搜索、更新及删除操作。一个ES集群中可以按需创建任意数目的索引。
类型(Type)
类型是索引内部的逻辑分区(category/partition),然而其意义完全取决于用户需求。因此,一个索引内部可定义一个或多个类型(type)。一般来说,类型就是为那些拥有相同的域的文档做的预定义。
例如,在索引中,可以定义一个用于存储用户数据的类型,一个存储日志数据的类型,以及一个存储评论数据的类型。类比传统的关系型数据库领域来说,类型相当于“表”。
文档(Document)
文档是Lucene索引和搜索的原子单位,它是包含了一个或多个域的容器,基于JSON格式进行表示。
文档由一个或多个域组成,每个域拥有一个名字及一个或多个值,有多个值的域通常称为“多值域”。每个文档可以存储不同的域集,但同一类型下的文档至应该有某种程度上的相似之处。
映射(Mapping)
ES中,所有的文档在存储之前都要首先进行分析。用户可根据需要定义如何将文本分割成token、哪些token应该被过滤掉,以及哪些文本需要进行额外处理等等。
另外,ES还提供了额外功能,例如将域中的内容按需排序。事实上,ES也能自动根据其值确定域的类型。
接下去再说说ES Cluster相关的一些概念。
集群(Cluster)
ES集群是一个或多个节点的集合,它们共同存储了整个数据集,并提供了联合索引以及可跨所有节点的搜索能力。
多节点组成的集群拥有冗余能力,它可以在一个或几个节点出现故障时保证服务的整体可用性。
集群靠其独有的名称进行标识,默认名称为“elasticsearch”。节点靠其集群名称来决定加入哪个ES集群,一个节点只能属一个集群。
如果不考虑冗余能力等特性,仅有一个节点的ES集群一样可以实现所有的存储及搜索功能。
节点(Node)
运行了单个实例的ES主机称为节点,它是集群的一个成员,可以存储数据、参与集群索引及搜索操作。
类似于集群,节点靠其名称进行标识,默认为启动时自动生成的随机Marvel字符名称。
用户可以按需要自定义任何希望使用的名称,但出于管理的目的,此名称应该尽可能有较好的识别性。
节点通过为其配置的ES集群名称确定其所要加入的集群。
分片(Shard)和副本(Replica)
ES的“分片(shard)”机制可将一个索引内部的数据分布地存储于多个节点,它通过将一个索引切分为多个底层物理的Lucene索引完成索引数据的分割存储功能,这每一个物理的Lucene索引称为一个分片(shard)。
每个分片其内部都是一个全功能且独立的索引,因此可由集群中的任何主机存储。创建索引时,用户可指定其分片的数量,默认数量为5个。
Shard有两种类型:primary和replica,即主shard及副本shard。
-
Primary shard用于文档存储,每个新的索引会自动创建5个Primary shard,当然此数量可在索引创建之前通过配置自行定义,不过,一旦创建完成,其Primary shard的数量将不可更改。
-
Replica shard是Primary Shard的副本,用于冗余数据及提高搜索性能。
每个Primary shard默认配置了一个Replica shard,但也可以配置多个,且其数量可动态更改。ES会根据需要自动增加或减少这些Replica shard的数量。
ES集群可由多个节点组成,各Shard分布式地存储于这些节点上。
ES可自动在节点间按需要移动shard,例如增加节点或节点故障时。简而言之,分片实现了集群的分布式存储,而副本实现了其分布式处理及冗余功能。
下面说说ES系统及插件。
ES依赖于JDK,使用Oracke JDK或OpenJDK均可。
JDK在不同平台的安装方式各异,具体方法这里不再介绍。ES的安装也非常容易,通常只需要简单修改其配置文件中的集群名称,并启动服务即可,这里不再赘述。
ElasticSearch在设计上支持插件式体系结构,用户可根据需要通过插件来增强ElasticSearch的功能。
目前,常用的通过插件扩展的功能包括添加自定义映射类型、自定义分析器、本地脚本、自定义发现方式等等。
安装及移除插件
插件的安装有两种方式:直接将插件放置于plugins目录中,或通过plugin脚本进行安装。
Marvel、BigDesk及Head这三个是较为常用的插件。
ElasticSearch提供了易用但功能强大的RESTful API以用于与集群进行交互,这些API大体可分为如下四类:
(1) 检查集群、节点、索引等健康与否,以及获取其相关状态与统计信息;
(2) 管理集群、节点、索引数据及元数据;
(3) 执行CRUD操作及搜索操作;
(4) 执行高级搜索操作,例如paging、filtering、scripting、faceting、aggregations及其它操作;
Logstash原理
Logstash的理念很简单,它只做3件事情:Collect:数据输入(收集);Enrich:数据加工,如过滤,改写等;Transport:数据输出(被其他模块进行调用)
Logstash 配置文件基本由三部分组成:Input、Output、Filter Plugin
- Input:获取日志,表示从数据源采集数据,常见的数据源如Kafka、日志文件等
- Output:输出日志,表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch
- Filter Plugin:过滤日志、格式处理,表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
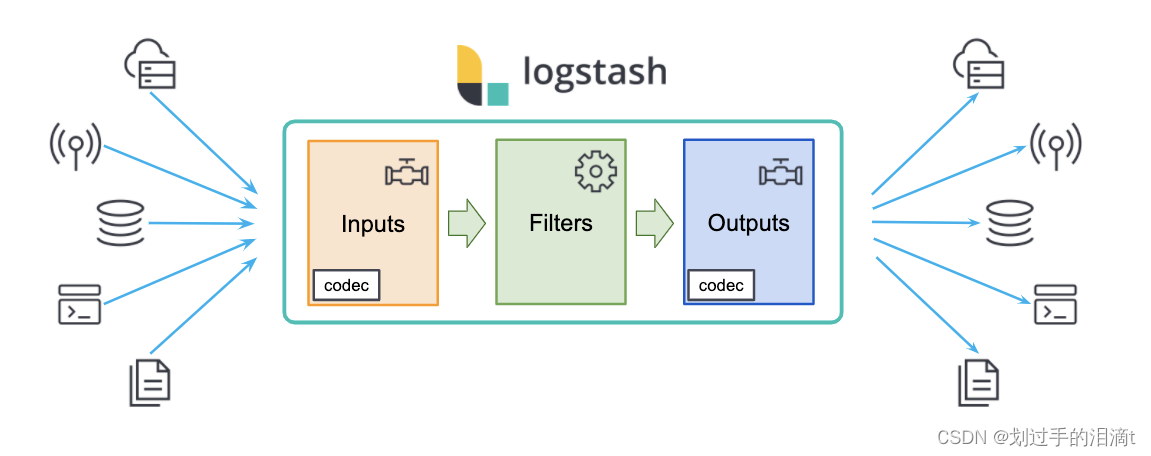
Logstash主要组件
(1)Shipper(日志收集者):日志收集负责监控本地日志文件的变化,及时把日志文件的最新内容收
集起来。通常,远程代理端(agent)只需要运行这个组件即可。
(2)Indexer(日志存储者):日志存储负责接受日志并写入到本地文件。
(3)Broker(日志Hub):日志hub负责链接多个shipper和对应数目的indexer。
(4)Search and Storage:允许对事件进行搜索和存储。
(5)Web Interface:基于web的展示界面。
以上组件在Logstash架构中可以独立部署,因此提供了很好的集群扩展性
LogStash主机分类
- 代理主机(agent host):作为事件的传递者(shipper),将各种日志数据发送至中心主机;只需运行Logstash代理( agent)程序;
- 中心主机(central host):可运行包括中间转发器(Broker)、索引器(Indexer)、搜索和存储器(Searchandstorage)
- web界面端(web Interface):在内的各个组件,以实现对日志数据的接收,处理和存储
其它组件
Filebeat:轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装 Filebeat,并指定目录与日志格式,Filebeat 就能快速收集数据,并发送给 logstash 进行解析,或是直接发给 Elasticsearch存储,性能上相比运行于 JVM 上的 logstash 优势明显,是对它的替代。常应用于 EFLK 架构当中。
filebeat 结合 logstash 带来好处:
(1)通过 Logstash 具有基于磁盘的自适应缓冲系统,该系统将吸收传入的吞吐量,从而减轻Elasticsearch 持续写入数据的压力
(2)从其他数据源(例如数据库,S3对象存储或消息传递队列)中提取
(3)将数据发送到多个目的地,例如S3,HDFS(Hadoop分布式文件系统)或写入文件
(4)使用条件数据流逻辑组成更复杂的处理管道
缓存/消息队列(redis、kafka、RabbitMQ等):可以对高并发日志数据进行流量削峰和缓冲,这样的缓冲可以一定程度的保护数据不丢失,还可以对整个架构进行应用解耦。
Fluentd:是一个流行的开源数据收集器。由于 logstash 太重量级的缺点,Logstash 性能低、资源消耗比较多等问题,随后就有 Fluentd 的出现。
相比较 logstash,Fluentd 更易用、资源消耗更少、性能更高,在数据处理上更高效可靠,受到企业迎,成为 logstash 的一种替代方案,常应用于 EFK 架构当中。在 Kubernetes 集群中也常使用 EFK 作为日志数据收集的方案。
在 Kubernetes 集群中一般是通过 DaemonSet 来运行 Fluentd,以便它在每个 Kubernetes 工作节点上都可以运行一个 Pod。
它通过获取容器日志文件、过滤和转换日志数据,然后将数据传递到Elasticsearch 集群,在该集群中对其进行索引和存储。
Kibana(展示)
(1)一个针对Elasticsearch的开源分析及可视化平台;
(2)搜索、查看存储在Elasticsearch索引中的数据;
(3)通过各种图标进行高级数据分析及展示;
(4)让海量数据更容易理解;
(5)操作简单,基于浏览器地用户界面就可以快速创建仪表板(dashboard)实时显示Elasticsearch查询动态;
(6)设置安装Kibana非常简单,无需编写代码,几分钟内就可以完成Kibana安装并启动Elasticsearch监测。
Kibana主要功能
Kibana 通常与 Elasticsearch 一起部署,Kibana 是 Elasticsearch 的一个功能强大的数据可视化Dashboard,Kibana 提供图形化的 web 界面来浏览 Elasticsearch 日志数据,可以用来汇总、分析和搜索重要数据。
(1)Elasticsearch无缝之集成。Kibana架构为Elasticsearch定制,可以将任何结构化和非结构化数据加入Elasticsearch索引。Kibana还充分利用了Elasticsearch强大的搜索和分析功能。
(2)整合数据:Kibana能够更好地处理海量数据,并据此创建柱形图、折线图、散点图、直方图、饼图和地图。
(3)复杂数据分析:Kibana提升了Elasticsearch分析能力,能够更加智能地分析数据,执行数学转换并且根据要求对数据切割分块。
(4)让更多团队成员受益:强大的数据库可视化接口让各业务岗位都能够从数据集合受益。
(5)接口灵活,分享更容易:使用Kibana可以更加方便地创建、保存、分享数据,并将可视化数据快速交流。
(6)配置简单:Kibana的配置和启用非常简单,用户体验非常友好。Kibana自带Web服务器,可以快速启动运行。
(7)可视化多数据源:Kibana可以非常方便地把来自Logstash、ES-Hadoop、Beats或第三方技术的数据整合到Elasticsearch,支持的第三方技术包括Apache Flume、Fluentd等。
(8)简单数据导出:Kibana可以方便地导出感兴趣的数据,与其它数据集合并融合后快速建模分析,发现新结果。
二、ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
准备
Node1节点(2C/4G):node1/192.168.99.111 Elasticsearch
Node2节点(2C/4G):node2/192.168.99.122 Elasticsearch Elasticsearch-head
Apache节点:apache 192.168.99.143 Logstash Apache Kibana
Filebeat节点:192.168.99.161
所有节点,关闭系统防火墙和安全机制
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
更改主机名
Node1节点:hostnamectl set-hostname n1
Node2节点:hostnamectl set-hostname n2
#查看Java环境,如果没有安装,yum -y install java
java -version

部署 Elasticsearch 软件
安装elasticsearch—rpm包
cd /opt
rpm -ivh elasticsearch-5.5.0.rpm
加载系统服务
systemctl daemon-reload
systemctl enable elasticsearch.service
修改elasticsearch主配置文件
cp /etc/elasticsearch/elasticsearch.yml /etc/elasticsearch/elasticsearch.yml.bak
# 修改时属性名和属性值之间需要有空格间隔
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 主机名 n1、n2
discovery.zen.ping.unicast.hosts: ["n1", "n2"]
#查看主配置文件
grep -v "^#" /etc/elasticsearch/elasticsearch.yml
创建数据存放路径并授权
mkdir -p /data/elk_data
chown elasticsearch:elasticsearch /data/elk_data/
启动elasticsearch是否成功开启
systemctl restart elasticsearch.service
netstat -antp | grep 9200

查看节点信息
浏览器访问 ,查看节点 Node1、Node2 的信息
http://192.168.99.111:9200
http://192.168.99.122:9200
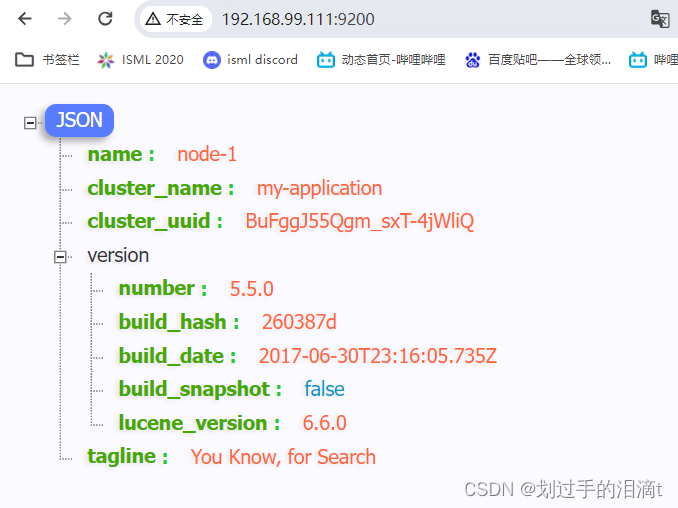
浏览器访问
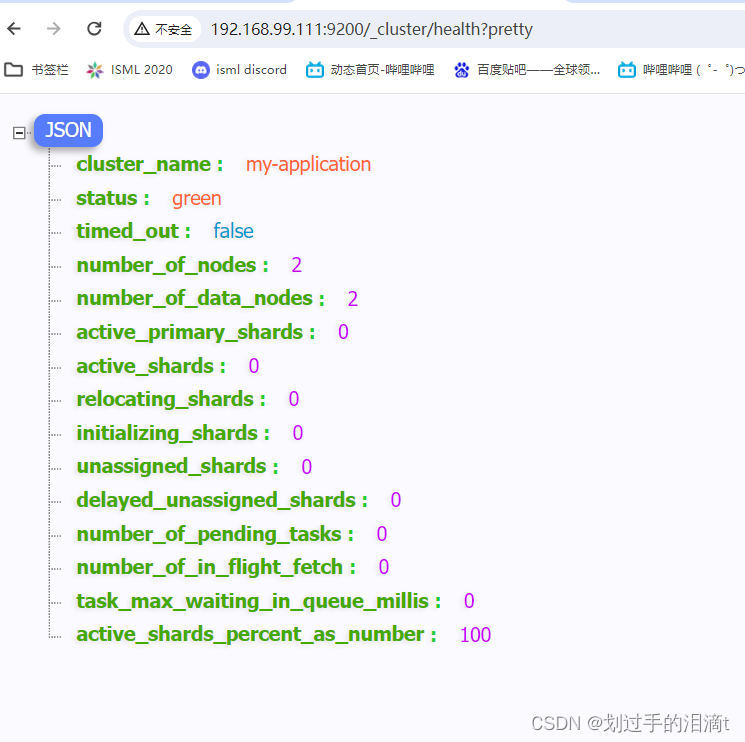
http://192.168.99.111:9200/_cluster/health?pretty
http://192.168.99.122:9200/_cluster/health?pretty
查看群集的健康情况,
可以看到 status 值为 green(绿色), 表示节点健康运行。
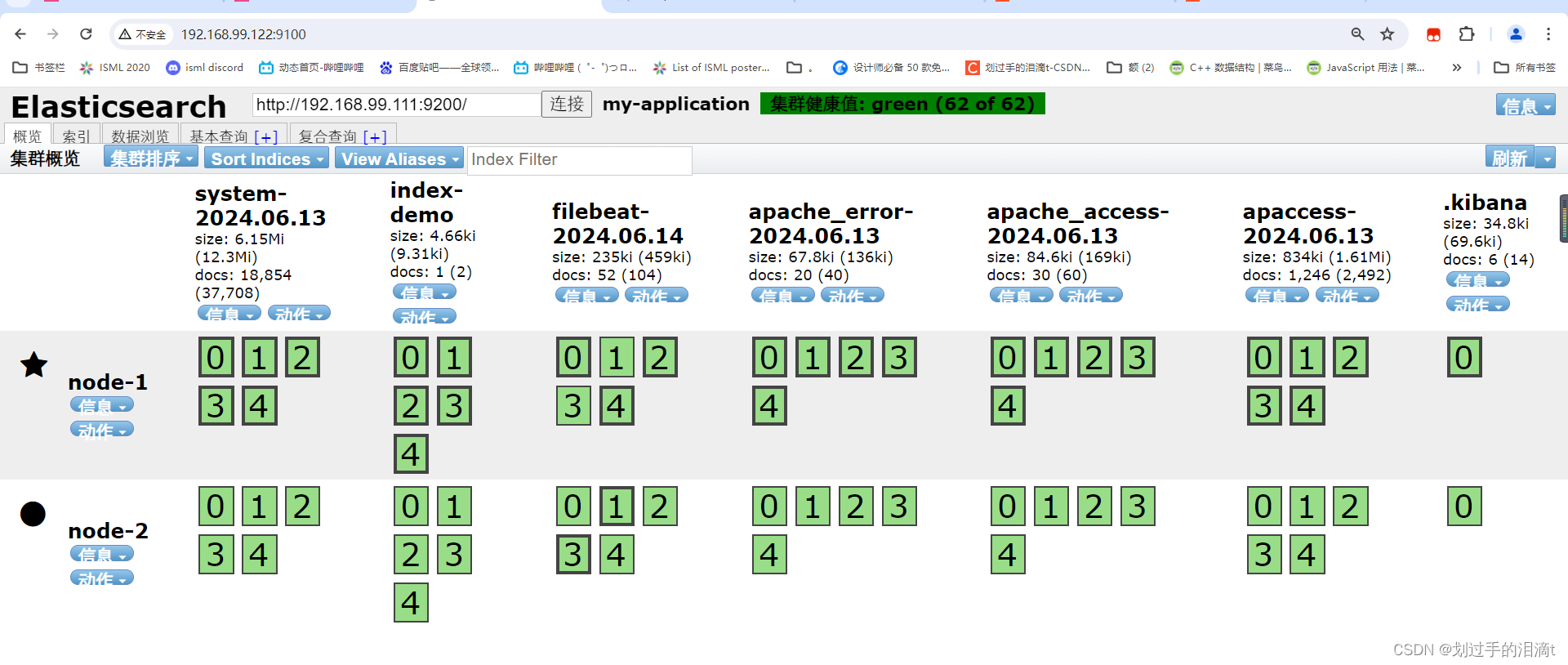
安装 Elasticsearch-head 插件
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
选择一台es设备安装
编译安装 node
上传软件包 node-v8.2.1.tar.gz 到/opt
yum install gcc gcc-c++ make -y
cd /opt
tar zxf node-v8.2.1.tar.gz
cd node-v8.2.1/
./configure
make -j4 && make install
安装 phantomjs
#上传软件包 phantomjs-2.1.1-linux-x86_64.tar.bz2 到
yum install -y bzip2
cd /opt
tar jxf phantomjs-2.1.1-linux-x86_64.tar.bz2 -C /usr/local/src/
cd /usr/local/src/phantomjs-2.1.1-linux-x86_64/bin
cp phantomjs /usr/local/bin
安装 Elasticsearch-head 数据可视化工具
#上传软件包 elasticsearch-head.tar.gz 到/opt
cd /opt
tar zxf elasticsearch-head.tar.gz -C /usr/local/src/
cd /usr/local/src/elasticsearch-head/
npm install
修改 Elasticsearch 主配置文件(这边展示node1的,node2与之相同)
vim /etc/elasticsearch/elasticsearch.yml
......
--末尾添加以下内容--
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有
systemctl restart elasticsearch
启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
cd /usr/local/src/elasticsearch-head/
npm run start &
> elasticsearch-head@0.0.0 start /usr/local/src/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100
elasticsearch-head #监听的端口是 9100
netstat -natp |grep 9100
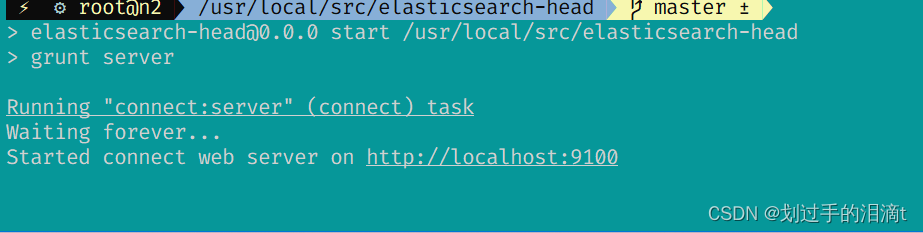

浏览器访问192.168.99.122:9100
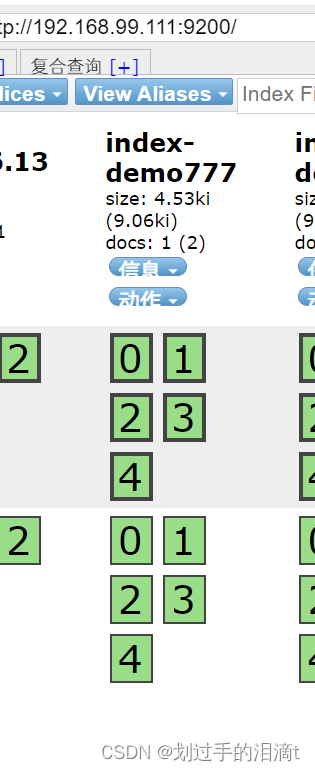
插入索引
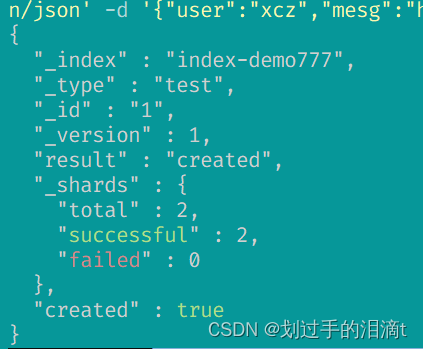
curl -X PUT 'localhost:9200/index-demo777/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"xcz","mesg":"hello world"}'
ELK Logstash 部署(在 Apache 节点上操作)
安装Logstash
(1)#修改主机名
hostnamectl set-hostname apache
su
(2)#安装httpd并启动
yum -y install httpd
systemctl start httpd
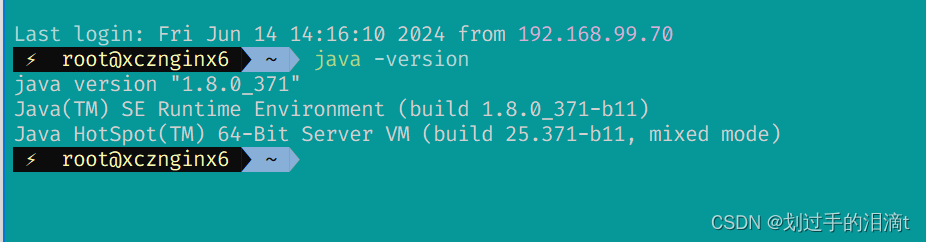
(3)#安装java环境
yum -y install java
java -version
(4)#安装logstash
cd /opt
rpm -ivh logstash-5.5.1.rpm
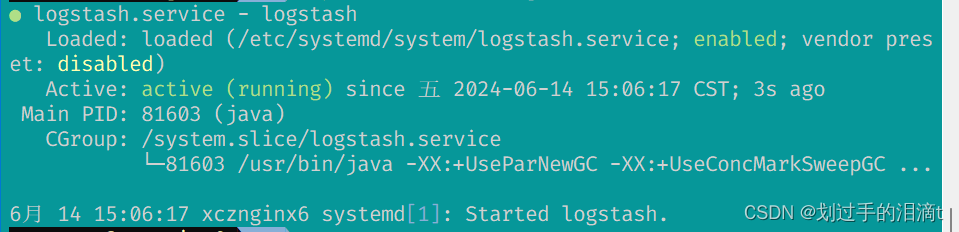
systemctl start logstash.service
systemctl enable logstash.service
cd /usr/share/logstash/
ls
ln -s /usr/share/logstash/bin/logstash /usr/local/bin/
测试 Logstash(Apache)与elasticsearch(node)功能是否正常,做对接
Logstash这个命令测试
字段描述解释:
● -f 通过这个选项可以指定logstash的配置文件,根据配置文件配置logstash
● -e 后面跟着字符串 该字符串可以被当做logstash的配置(如果是“空”则默认使用stdin做为输入、stdout作为输出)
● -t 测试配置文件是否正确,然后退出
logstash -f 配置文件名字 去连接elasticsearch
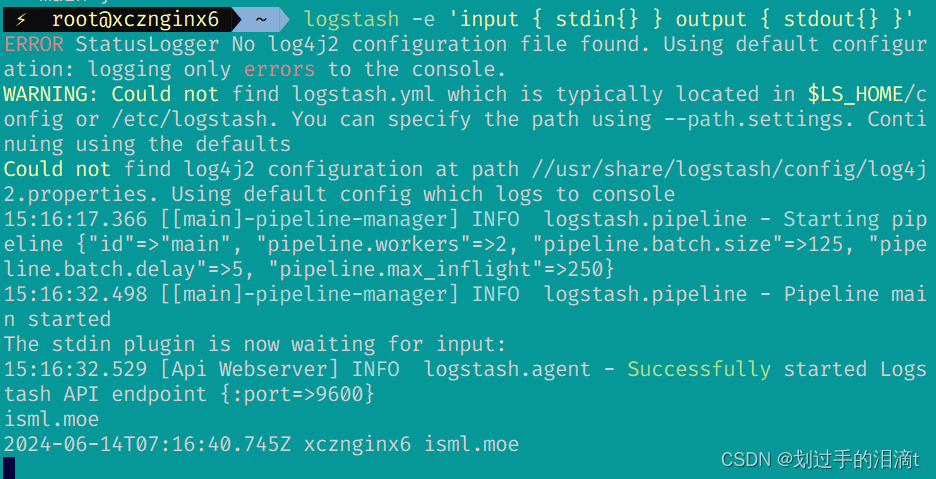
(1)#输入采用标准输入 输出采用标准输出---登录192.168.99.111 在Apache服务器上
logstash -e 'input { stdin{ } } output { stdout{ } }'
2、#使用 rubydebug 输出详细格式显示,codec 为一种编解码器
logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
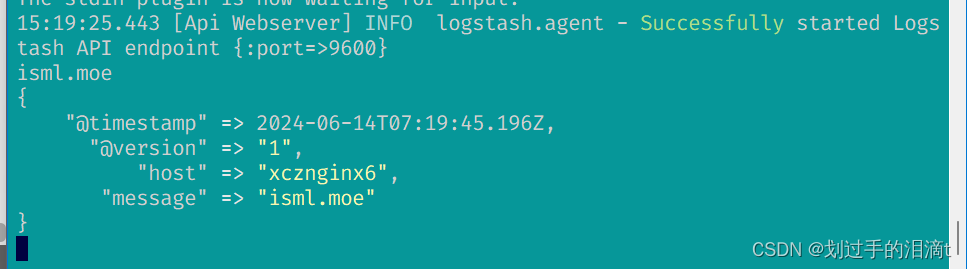
3、#使用 Logstash 将信息写入 Elasticsearch 中
logstash -e 'input { stdin{} } output { elasticsearch { hosts=>["192.168.99.111:9200"] } }'
# 输入 输出 对接
......
isml.moe
#键入内容(标准输入)
www.bilibili.com
#键入内容(标准输入)
www.bing.cn
#键入内容(标准输入)
//结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.99.111:9100/ 查看索引信息和数据浏览。

定义 logstash配置文件
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
**input**:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
**filter**:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
**output**:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
#格式如下:
input {...}
filter {...}
output {...}
#在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/httpd/access.log" type =>"apache"}
}
例如:
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages" #指定要收集的日志的位置
type =>"system" #自定义日志类型标识
start_position =>"beginning" #表示从开始处收集
}
}
output {
elasticsearch { #输出到 elasticsearch
hosts => ["192.168.99.111:9200"] #指定 elasticsearch 服务器的地址和端口
index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式
}
}
systemctl restart logstash
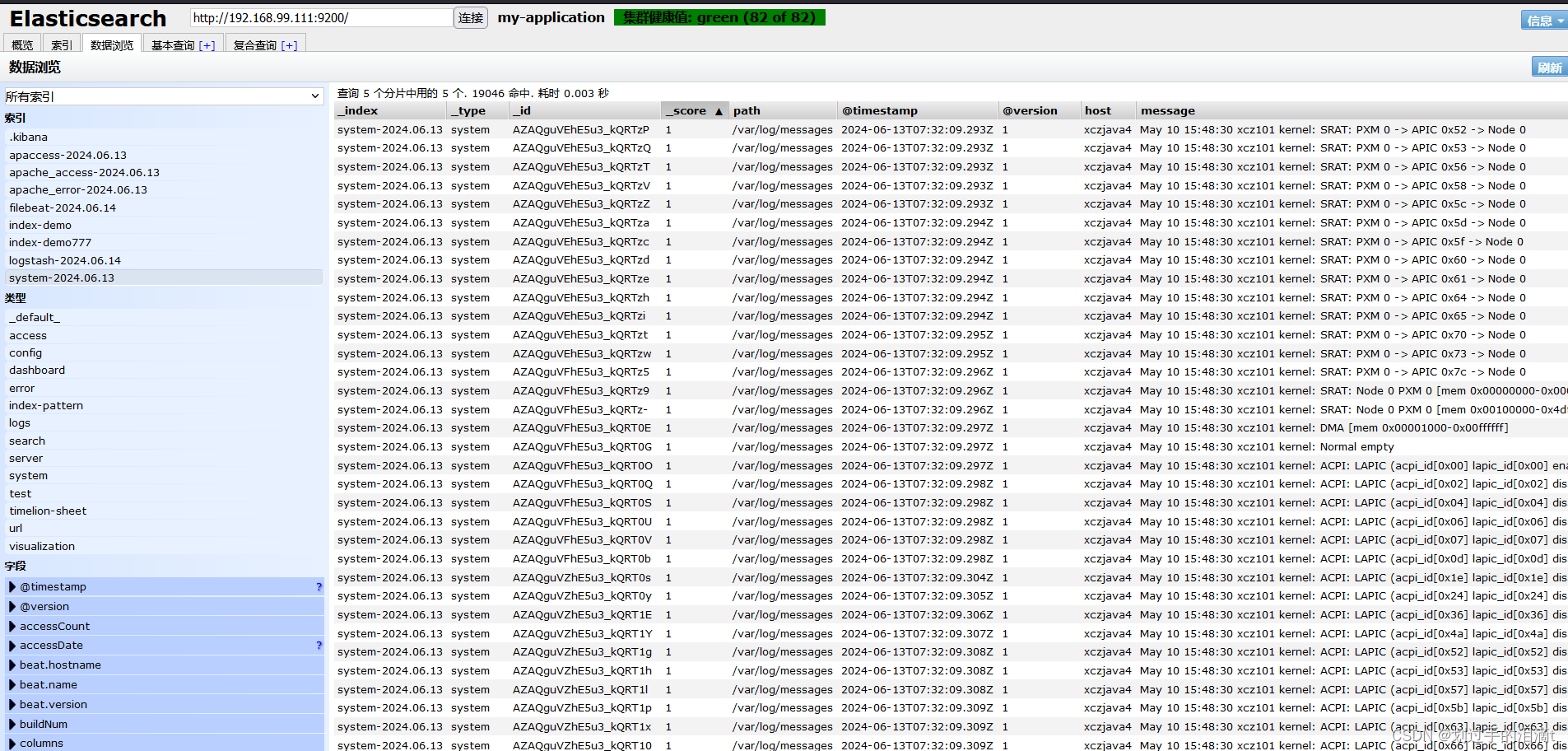
浏览器访问 http://192.168.99.122:9100/ 查看索引信息
修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch中。
(1)给日志目录可读权限
chmod +r /var/log/messages
#让 Logstash 可以读取日志
(2)修改 Logstash 配置文件
vim /etc/logstash/conf.d/system.conf
input {
file{
path =>"/var/log/messages"
type =>"system"
start_position =>"beginning"
}
}
output {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index =>"system-%{+YYYY.MM.dd}"
}
}
systemctl restart logstash
ELK Kibana 部署(192.168.99.143)
安装 Kibana
#上传软件包 kibana-5.5.1-x86_64.rpm 到/opt目录
cd /opt
rpm -ivh kibana-5.5.1-x86_64.rpm
设置 Kibana 的主配置文件
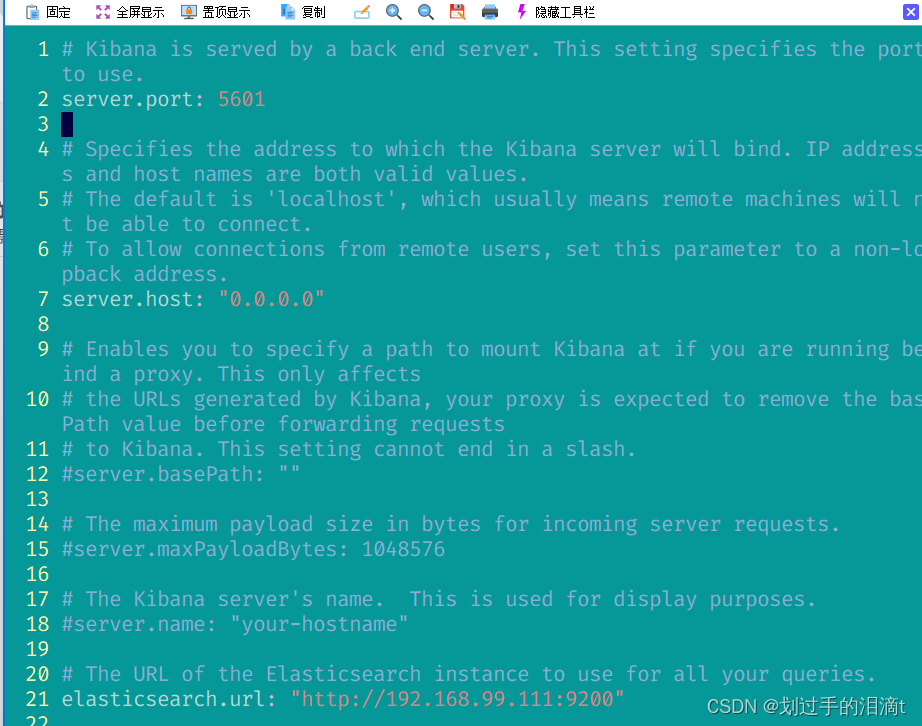
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.99.111:9200"
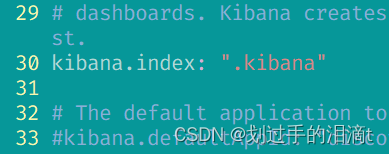
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
启动 Kibana 服务
systemctl start kibana.service
systemctl enable kibana.service
netstat -natp | grep 5601

浏览器访问:http://192.168.99.143:5601/
第一次登录需要添加一个 Elasticsearch 索引:
Index name or pattern
//输入:system-* #在索引名中输入之前配置的 Output 前缀“system”
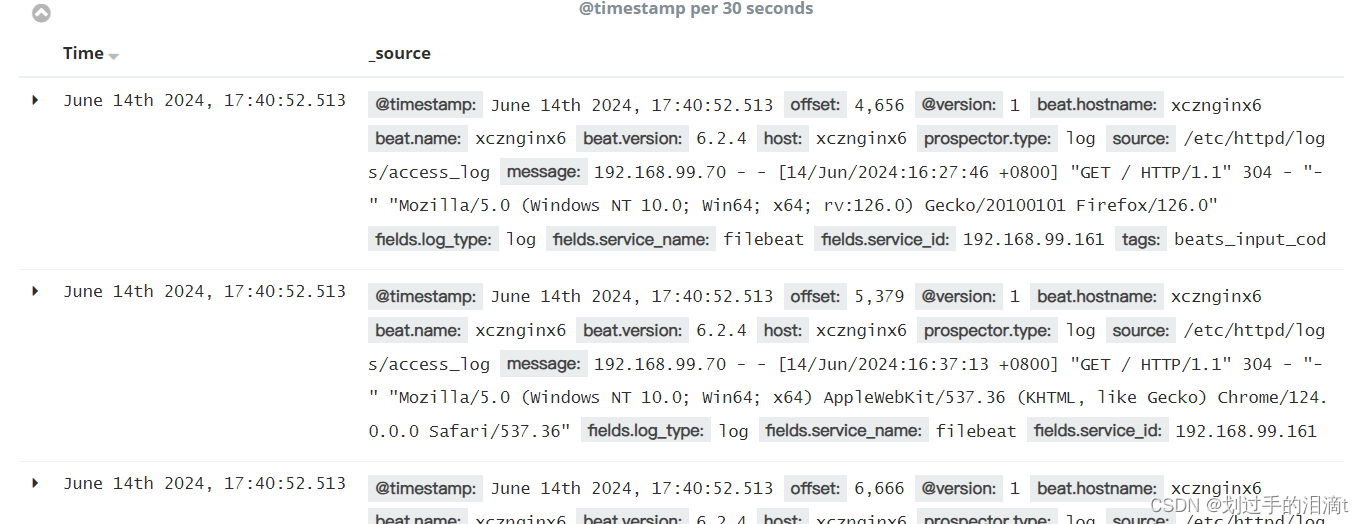
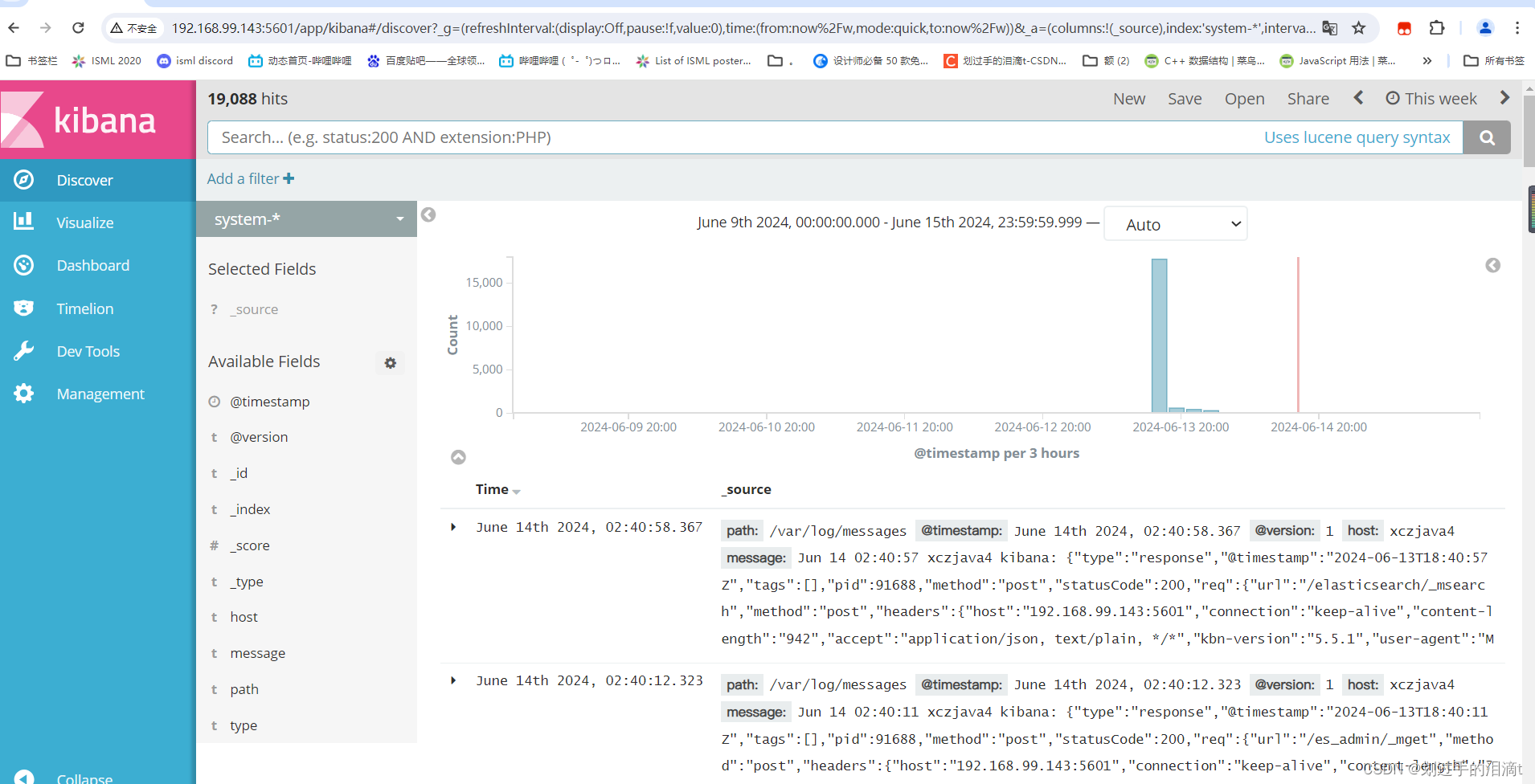
单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果

将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示
vim /etc/logstash/conf.d/apache_log.conf
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f apache_log.conf --path.data /var/lib/logstash/data_instance3
浏览器访问 http://192.168.99.122:9100 查看索引是否创建
浏览器访问 http://192.168.99.143:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 apache_access-*,并单击“Create”按钮。在用相同的方法添加 apache_error-*索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access-* 、apache_error-* 索引, 可以查看相应的图表及日志信息。


将 nginx 服务器的日志添加到 Elasticsearch 并通过 Kibana 显示
chmod +r /var/log/nginx
vim /etc/logstash/conf.d/nginx_log.conf
input {
file{
path => "/var/log/nginx/access.log"
type => "access"
start_position => "beginning"
}
file{
path => "/var/log/nginx/error.log-%{+YYYY.MM.dd}"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "nginx_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "nginx_error-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f nginx_log.conf --path.data /var/lib/logstash/data_instance_nginx
浏览器访问 http://192.168.99.122:9100 查看索引是否创建
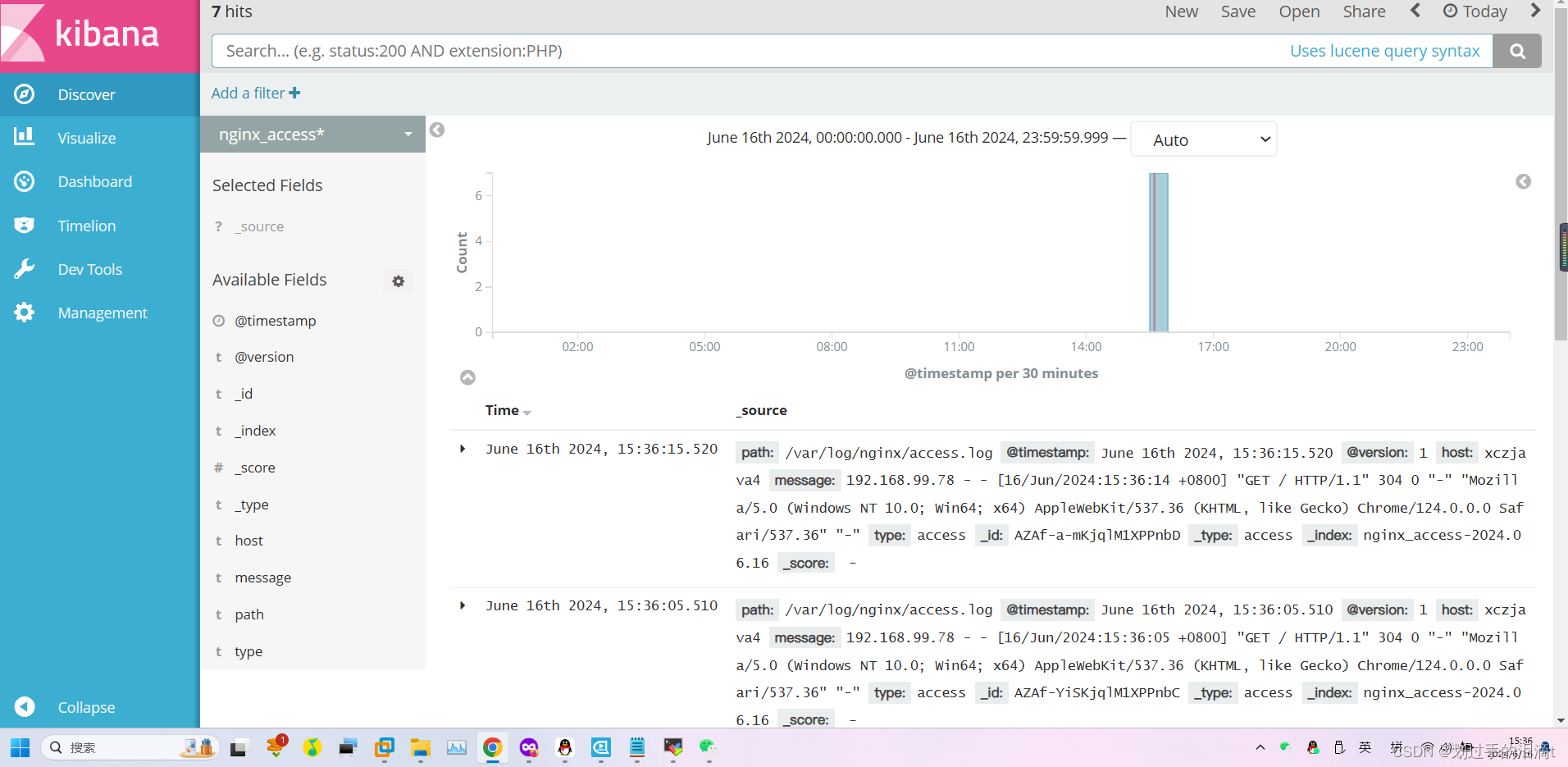
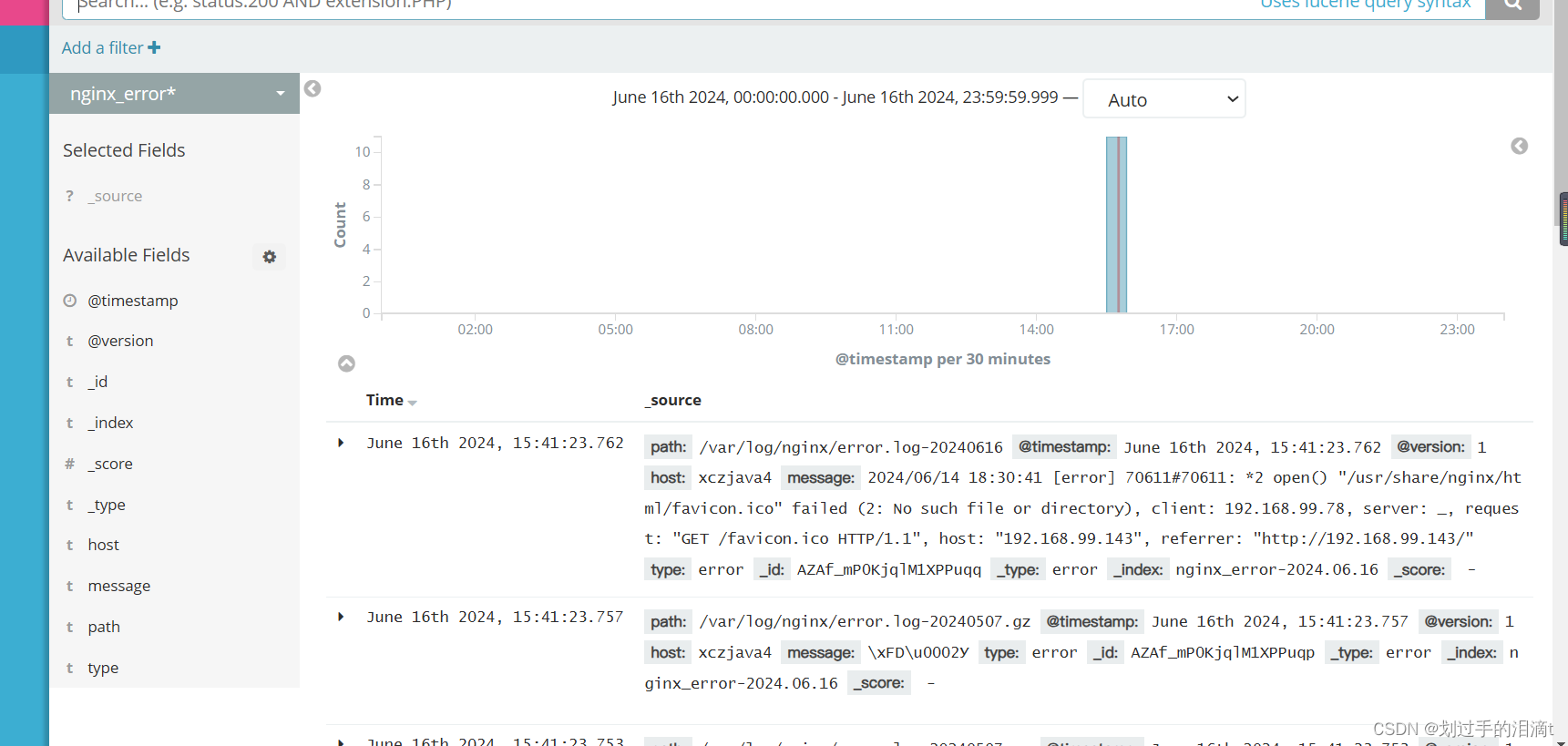
浏览器访问 http://192.168.99.143:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 nginx_access-,并单击“Create”按钮。在用相同的方法添加 nginx_error-索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 nginx_access- 、 nginx_error- 索引, 可以查看相应的图表及日志信息。
将 tomcat 服务器的日志添加到 Elasticsearch 并通过 Kibana 显示
在测试前不要忘了修改tomcat日志格式,使其支持JSON格式
Tomcat安装完成后,我们打开Tomcat的配置文件,/usr/local/tomcat/conf/server.xml,找到日志配置部分,将其pattern修改为如下内容:
{clientip:%h,ClientUser:%l,authenticated:%u,AccessTime:%t,method:%r,status:%s,SendBytes:%b,Query?string:%q,partner:%{Referer}i,AgentVersion:%{User-Agent}i}
chmod +r /usr/local/tomcat/apache-tomcat-9.0.78/logs/
vim /etc/logstash/conf.d/tomcat_log.conf
input {
file{
path => "/usr/local/tomcat/apache-tomcat-9.0.78/logs/catalina.2024-06-16.log"
type => "catalina"
start_position => "beginning"
}
file{
path => "/usr/local/tomcat/apache-tomcat-9.0.78/logs/host-manager.2024-06-16.log"
type => "host-manager"
start_position => "beginning"
}
file{
path => "/usr/local/tomcat/apache-tomcat-9.0.78/logs/localhost.2024-06-16.log"
type => "localhost"
start_position => "beginning"
}
file{
path => "/usr/local/tomcat/apache-tomcat-9.0.78/logs/maneger.2024-06-16.log"
type => "manager"
start_position => "beginning"
}
}
output {
if [type] == "catalina" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "tomcat_catalina-%{+YYYY.MM.dd}"
}
}
if [type] == "host-manage" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "tomcat_host-manage-%{+YYYY.MM.dd}"
}
}
if [type] == "localhost" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "tomcat_localhost-%{+YYYY.MM.dd}"
}
}
if [type] == "manager" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "tomcat_manager-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d/
/usr/share/logstash/bin/logstash -f tomcat_log.conf --path.data /var/lib/logstash/data_instance_tomcat
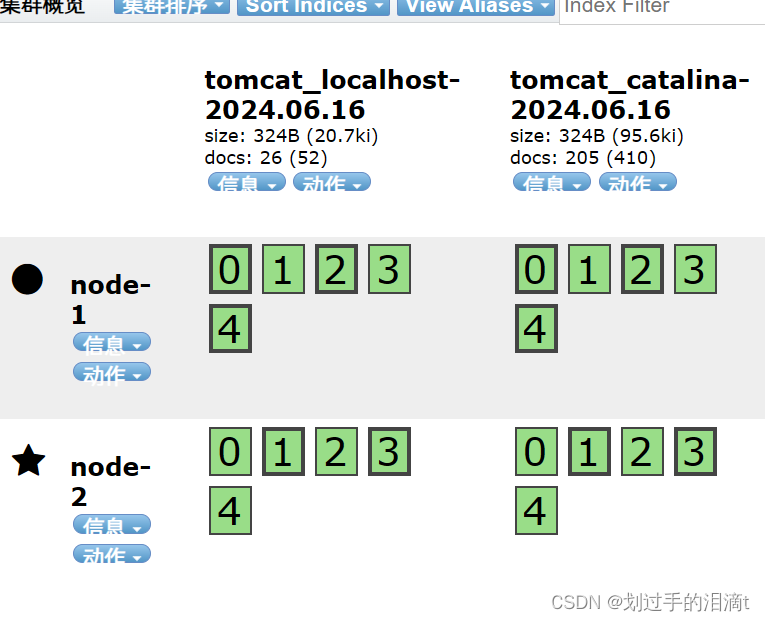
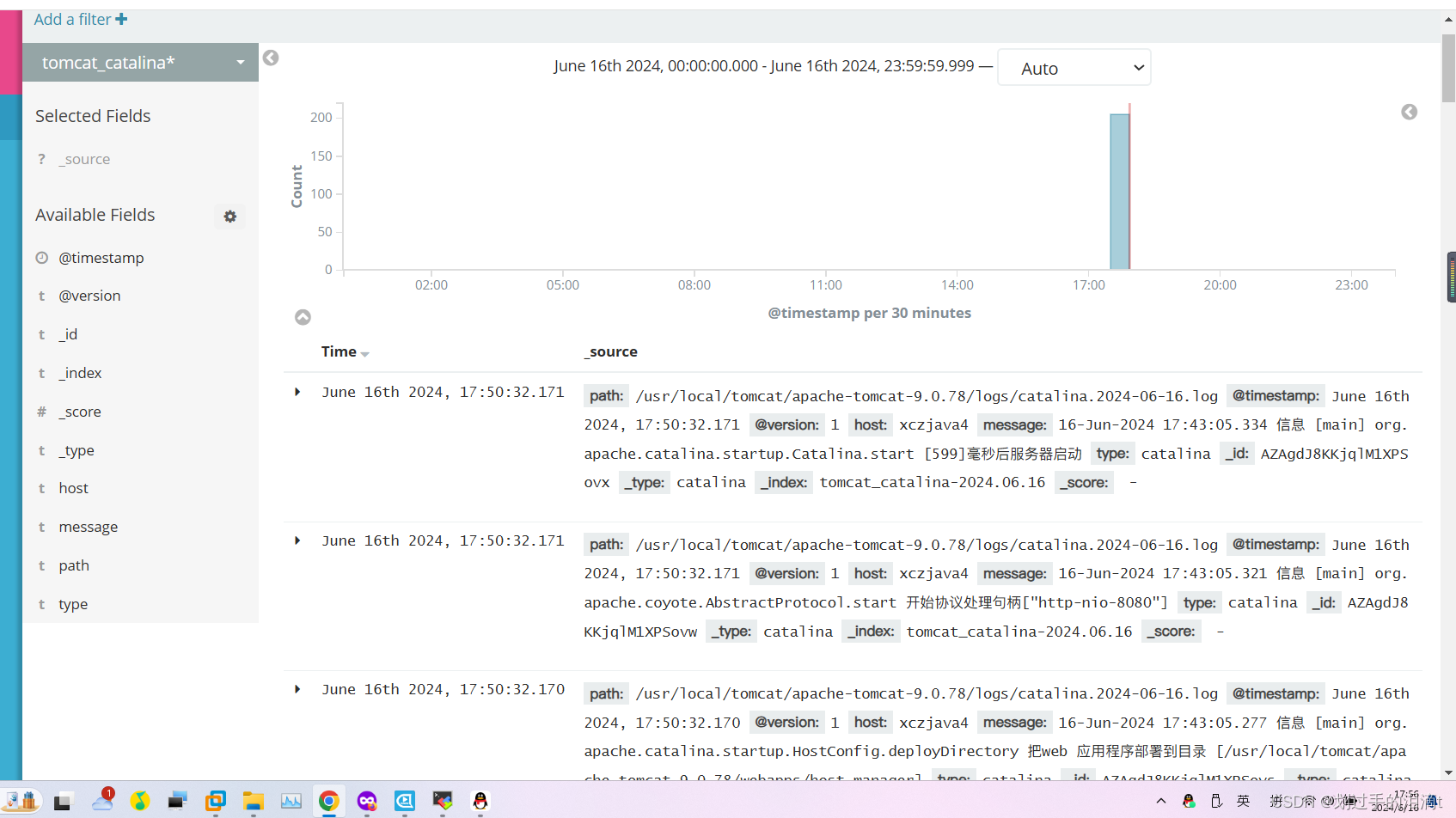
或者
input {
file{
path => "/usr/local/tomcat/apache-tomcat-9.0.78/logs/*.log"
type => "tomcat"
start_position => "beginning"
}
}
output {
if [type] == "tomcat" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "tomcat2-%{+YYYY.MM.dd}"
}
}
}
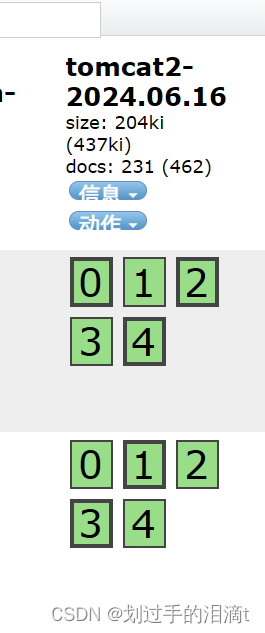
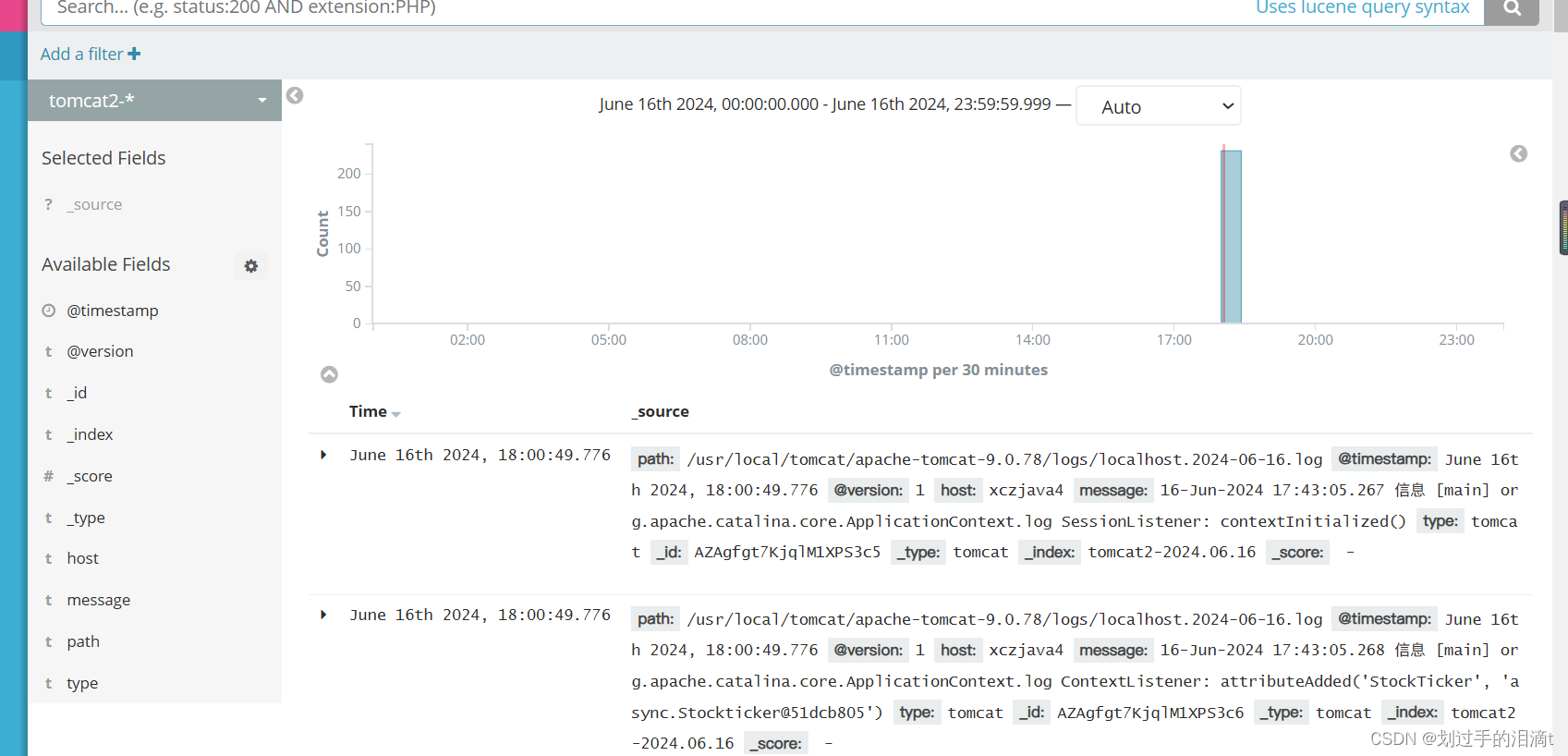
将 MySQL 服务器的日志添加到 Elasticsearch 并通过 Kibana 显示
安装mysql
wget https://repo.mysql.com//mysql57-community-release-el7-11.noarch.rpm --no-check-certificate
rpm -ivh mysql57-community-release-el7-11.noarch.rpm
cd /etc/yum.repos.d/
sed -i 's/gpgcheck=1/gpgcheck=0/' mysql-community.repo
yum -y install mysql-server
systemctl start mysqld.service
systemctl enable mysqld.service
grep "password" /var/log/mysqld.log
grep "password" /var/log/mysqld.log | awk '{print $NF}'
my.cnf
log-error=mysql_error.log
slow_query_log=ON
slow_query_log_file=mysql_slow_query.log
long_query_time=2
chmod +r /var/log/mysqld.log
chmod +r /var/lib/mysql
vim /etc/logstash/conf.d/mysql_log.conf
input {
file{
path => "/var/log/mysqld.log"
type => "mysqld"
start_position => "beginning"
}
file{
path => "/var/lib/mysql/mysql_error.log"
type => "mysql_error"
start_position => "beginning"
}
file{
path => "/var/lib/mysql/mysql_slow_query.log"
type => "mysql_slow_query"
start_position => "beginning"
}
}
output {
if [type] == "mysqld" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "mysqld-%{+YYYY.MM.dd}"
}
}
if [type] == "mysql_error" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "mysql_error-%{+YYYY.MM.dd}"
}
}
if [type] == "mysql_slow_query" {
elasticsearch {
hosts => ["192.168.99.111:9200"]
index => "mysql_slow_query-%{+YYYY.MM.dd}"
}
}
}
cd /etc/logstash/conf.d
/usr/share/logstash/bin/logstash -f mysql_log.conf --path.data /var/lib/logstash/data_instance_mysql

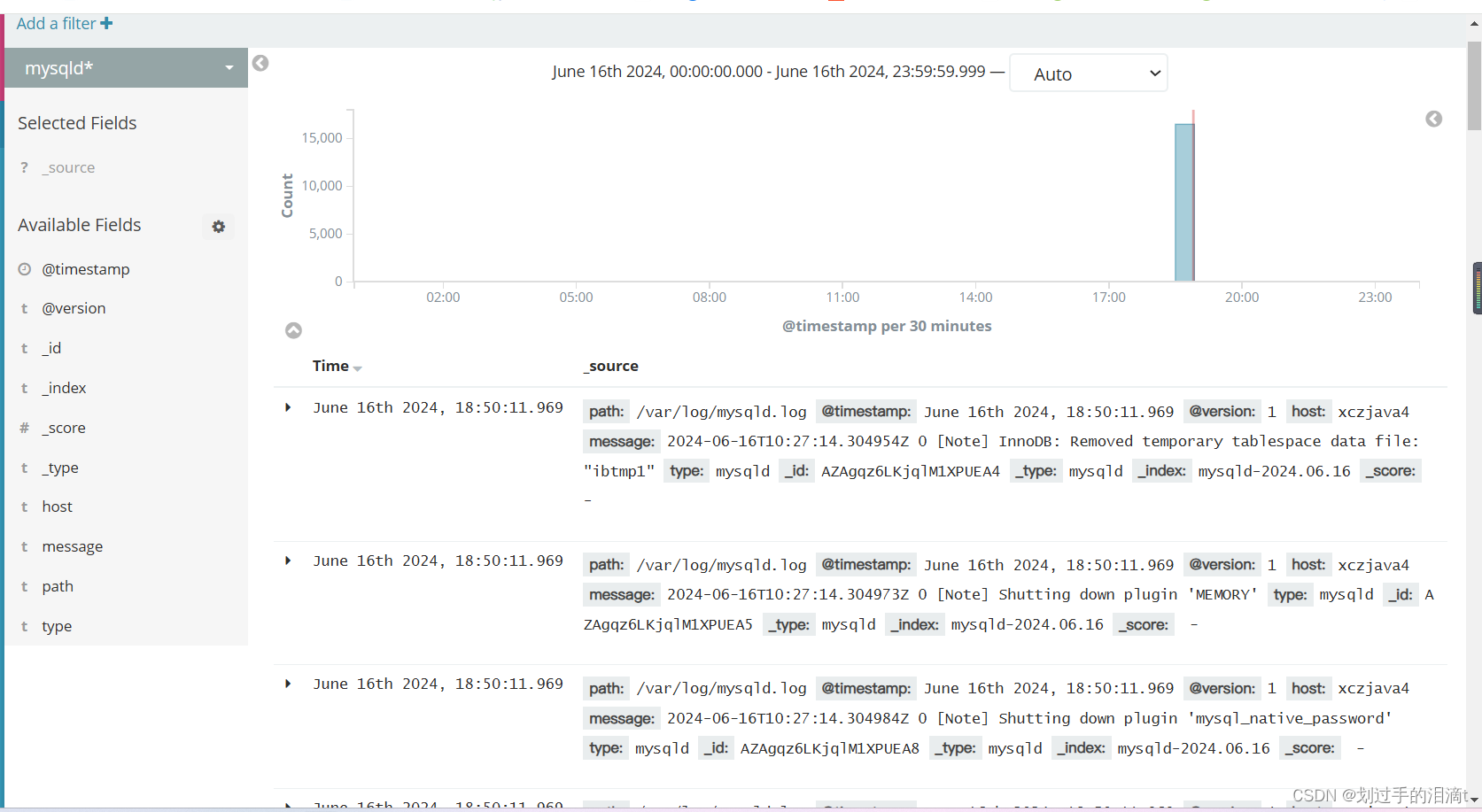
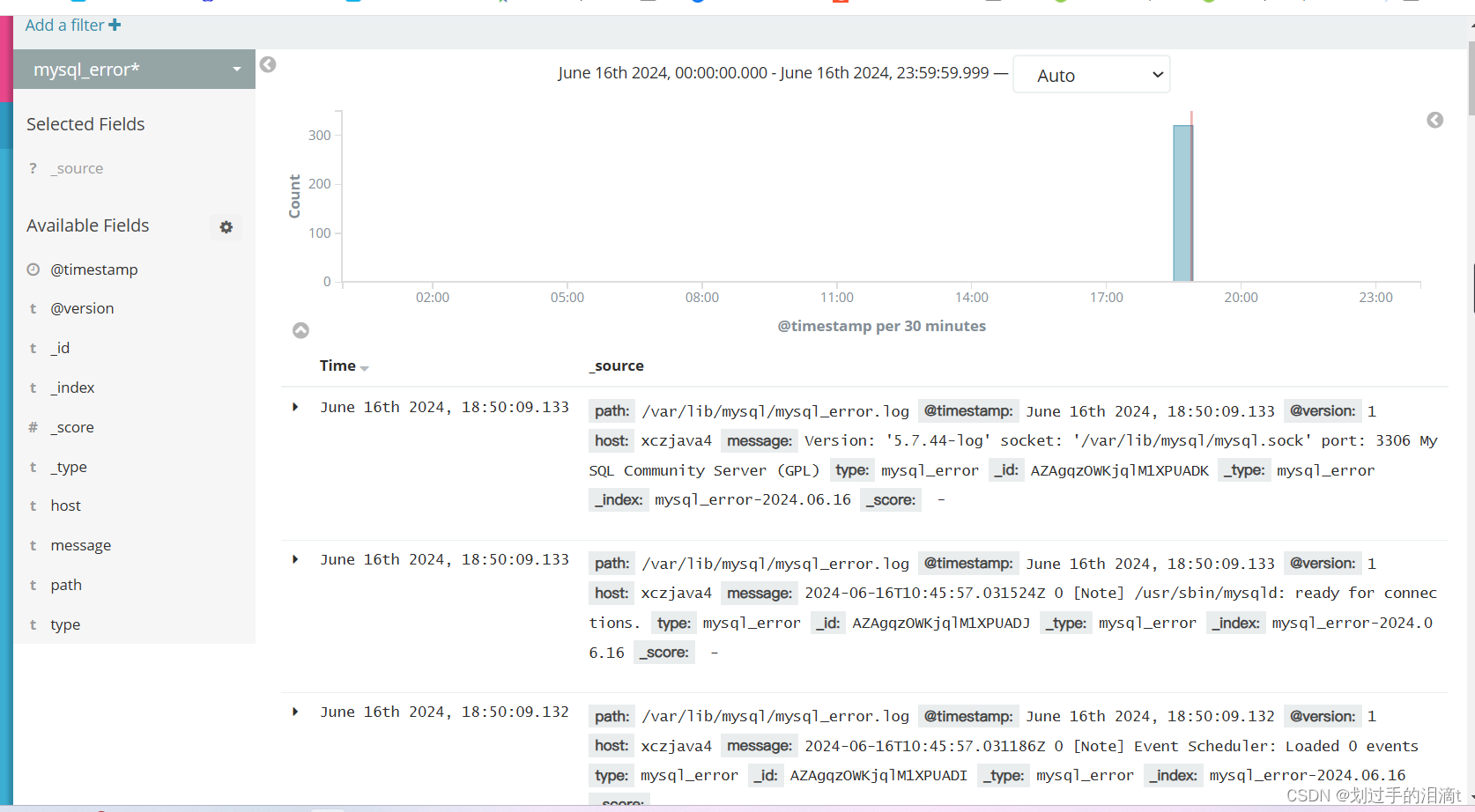
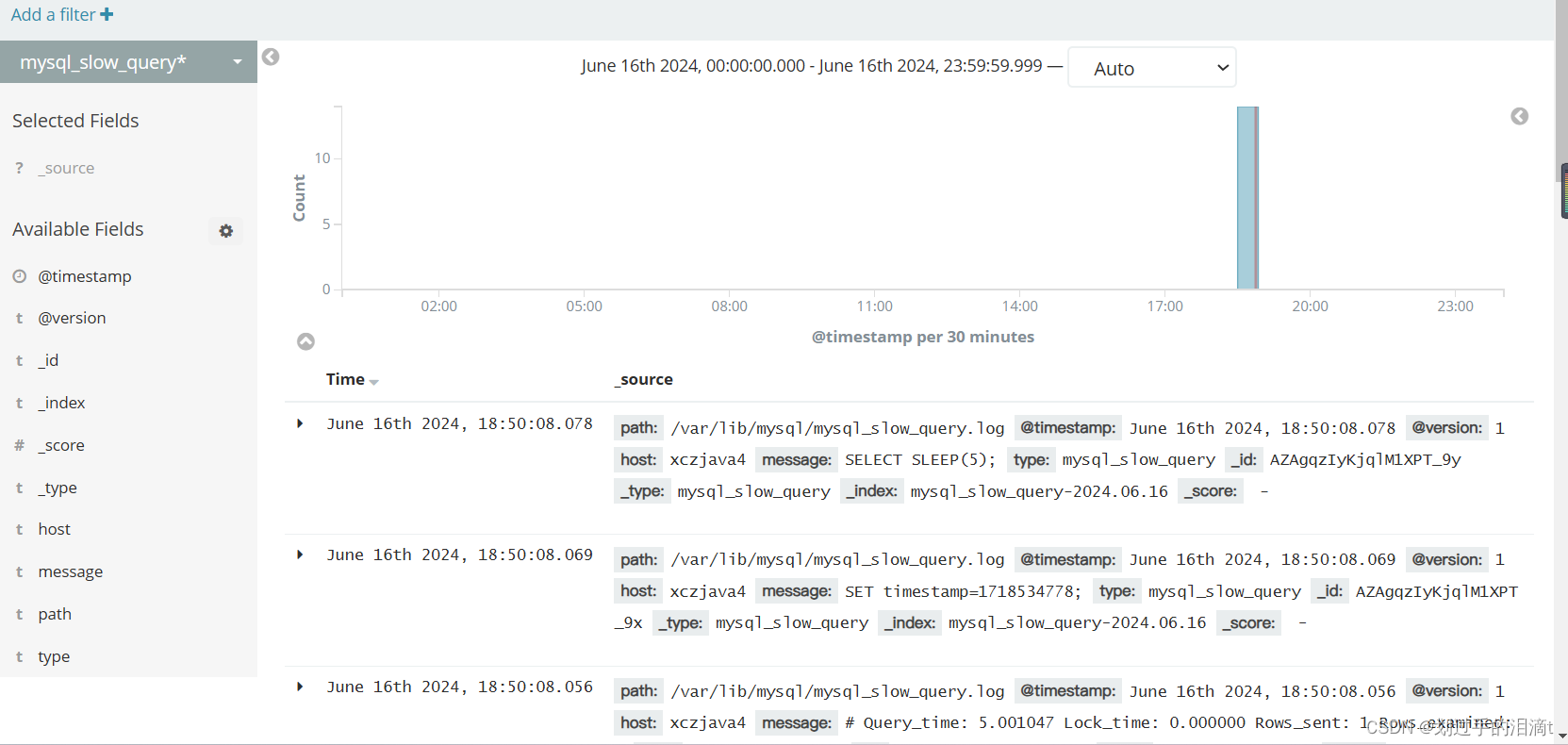
Filebeat+ELK 部署
Node1节点(2C/4G):node1/192.168.99.111 Elasticsearch
Node2节点(2C/4G):node2/192.168.99.122 Elasticsearch Elasticsearch-head
Apache节点:apache 192.168.99.143 Logstash Apache Kibana
Filebeat节点:192.168.99.161 Filebeat
安装Filebeat
#上传软件包 filebeat-6.2.4-linux-x86_64.tar.gz 到/opt目录
tar zxvf filebeat-6.2.4-linux-x86_64.tar.gz
mv filebeat-6.2.4-linux-x86_64/ /usr/local/filebeat
设置 filebeat 的主配置文件
cd /usr/local/filebeat
vim filebeat.yml
filebeat.prospectors:
- type: log # 指定 log 类型,从日志文件中读取消息
enabled: true # 启用日志采集配置
paths: # 日志文件所在的路径
- /etc/httpd/logs/*log
fields: # 可以使用 fields 配置选项设置一些参数字段添加到 output 中
service_name: filebeat
log_type: log
service_id: 192.168.99.161
--------------Elasticsearch output-------------------
(全部注释掉)
----------------Logstash output---------------------
output.logstash:
hosts: ["192.168.99.143:5044"] #指定 logstash 的 IP 和端口
filebeat.inputs 指明了这里是输入配置模块
type 指明采集的数据类型是日志文件
enabled 指明启用日志采集配置
paths 指明日志文件所在的路径
#启动 filebeat
./filebeat -e -c filebeat.yml
在 Logstash 组件所在节点(143)上新建一个 Logstash 配置文件
cd /etc/logstash/conf.d
vim logstash.conf
input {
beats {
port => "5044"
}
}
output {
elasticsearch {
hosts => ["192.168.99.122:9200"]
index => "%{[fields][service_name]}-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
#启动 logstash
logstash -f logstash.conf
#运行多个 Logstash 实例,每个实例必须拥有自己独立的数据目录。可以在 logstash.yml 文件中或通过命令行参数指定不同的数据目录。
logstash -f logstash.conf --path.data /var/lib/logstash/data_instance4
浏览器访问 http://192.168.99.143:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引“filebeat-*”,单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。