go的运行时调度框架简介
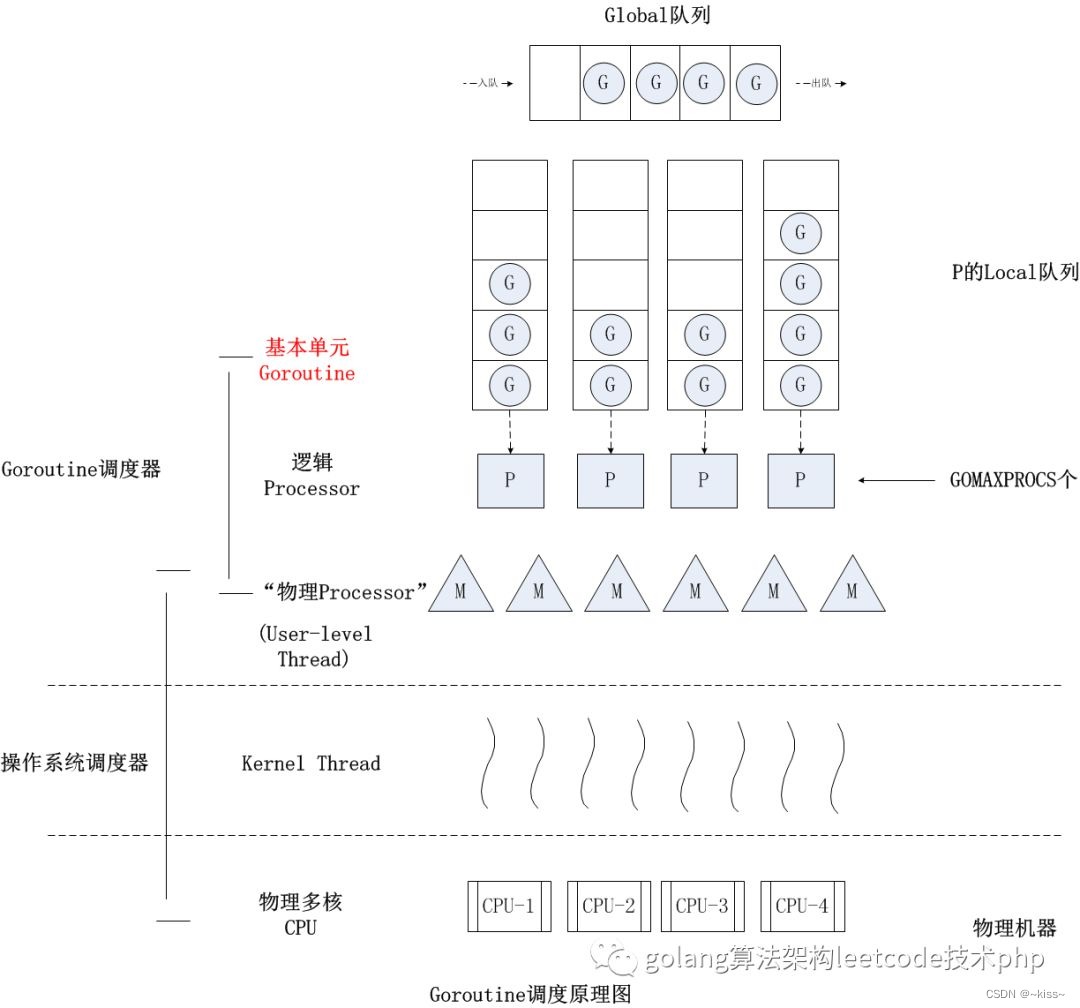
Go的运行时(runtime)中,由调度器管理:goroutine(G)、操作系统线程(M)和逻辑处理器(P)之间的关系
以实现高效的并发执行
当一个goroutine(G)发起一个系统调用(system call)并且需要等待其完成时,会导致该goroutine暂停执行
G的阻塞:
当一个goroutine执行系统调用并因此阻塞时(例如文件I/O、网络请求等),这个goroutine会进入阻塞状态
此时,它不会占用CPU资源,也不会继续执行
M与P的关系调整:
关键在于执行该goroutine的用户级线程(M)的行为
实际上,并不是M会被解绑P并一起进入sleep状态 。根据Go的调度策略,当M上的goroutine因为系统调用而阻塞时,调度器可能会采取以下行动之一:
(1) 如果可能,调度器会尝试将其他可运行的goroutine(即处于就绪状态的G)分配给这个M来执行,这样M不会空闲,继续利用CPU资源。这种情况下,M保持与P的绑定,只是切换了执行的goroutine。
(2) 如果没有其他goroutine可以调度(或者出于效率考虑,比如系统调用预计很快返回),M可能会选择进入休眠状态(但不直接与G一起sleep),这时它会释放对P的绑定,让P可以被其他M使用,以避免P资源闲置。M此时会进入一个等待状态,直到被唤醒(可能是由于系统调用完成/有新的任务需要处理)。
sysmon(监控线程)的作用:
sysmon是Go运行时中的一个特殊后台线程,负责监控和维护整个运行时的状态
包括发现并解决某些阻塞情况、管理空闲的M和P等
如果一个M因为等待系统调用长时间未被唤醒,sysmon可能会介入检查并采取措施
比如创建新的M来保证CPU的充分利用,但这并不意味着sysmon直接抢走P
当一个goroutine因系统调用而阻塞时,主要影响是该goroutine本身暂停执行
而执行它的M和关联的P则根据Go运行时的具体策略灵活调整,以优化整体的执行效率和资源利用率,而不是一起进入sleep状态
Go netpoll 核心
package main
import (
"fmt"
"net"
)
func main() {
listen, err := net.Listen("tcp", ":8888")
if err != nil {
fmt.Println("listen error: ", err)
return
}
for {
conn, err := listen.Accept()
if err != nil {
fmt.Println("accept error: ", err)
break
}
// start a new goroutine to handle the new connection
go HandleConn(conn)
}
}
func HandleConn(conn net.Conn) {
defer conn.Close()
packet := make([]byte, 1024)
for {
// 如果没有可读数据,也就是读 buffer 为空,则阻塞
_, _ = conn.Read(packet)
// 同理,不可写则阻塞
_, _ = conn.Write(packet)
}
}
Go netpoll 通过在底层对 epoll/kqueue/iocp 的封装(利用runtime 的 Go scheduler,让它来负责调度 goroutines)
从而实现了使用同步编程模式达到异步执行的效果,对于开发者来说 I/O 是否阻塞是无感知的。
所有的网络操作都以网络描述符 netFD 为中心实现。
netFD 与底层 PollDesc 结构绑定,当在一个 netFD 上读写遇到 EAGAIN 错误时,就将当前 goroutine 存储到这个 netFD 对应的 PollDesc 中,同时调用 gopark 把当前 goroutine 给 park 住,直到这个 netFD 上再次发生读写事件,才将此 goroutine 给 ready 激活重新运行。
显然,在底层通知 goroutine 再次发生读写等事件的方式就是 epoll/kqueue/iocp 等事件驱动机制。
Go netpoll 问题
没有任何一种设计和架构是完美的,goroutine-per-connection这种模式虽然简单高效,但是在某些极端的场景下也会暴露出问题:
goroutine 虽然非常轻量,它的自定义栈内存初始值仅为 2KB,后面按需扩容
海量连接的业务场景下,goroutine-per-connection,此时 goroutine 数量以及消耗的资源就会呈线性趋势暴涨
首先给 Go runtime scheduler 造成极大的压力和侵占系统资源,然后资源被侵占又反过来影响 runtime 的调度,导致性能大幅下降
Reactor 模式
在 Linux 平台下构建的高性能网络程序中,大都使用 Reactor 模式,比如 netty、libevent、libev、ACE,POE(Perl)、Twisted(Python)等
Reactor 模式本质上指的是使用I/O 多路复用(I/O multiplexing) + 非阻塞 I/O(non-blocking I/O)的模式
通常设置一个主线程负责做 event-loop 事件循环和 I/O 读写,通过 select/poll/epoll_wait 等系统调用监听 I/O 事件
业务逻辑提交给其他工作线程去做
『非阻塞 I/O』的核心思想是指避免阻塞在 read() 或者 write() 或者其他的 I/O 系统调用上
这样可以最大限度的复用 event-loop 线程,让一个线程能服务于多个 sockets
在 Reactor 模式中,I/O 线程只能阻塞在 I/O multiplexing 函数上(select/poll/epoll_wait)
Reactor 模式通常的工作流程如下:
(1) Server 端完成在bind&listen之后,将 listenfd 注册到 epollfd 中,最后进入 event-loop 事件循环。循环过程中会调用select/poll/epoll_wait阻塞等待,若有在 listenfd 上的新连接事件则解除阻塞返回,并调用socket.accept接收新连接 connfd,并将 connfd 加入到 epollfd 的 I/O 复用(监听)队列。
(2) 当 connfd 上发生可读/可写事件也会解除select/poll/epoll_wait的阻塞等待,然后进行 I/O 读写操作,这里读写 I/O 都是非阻塞 I/O,这样才不会阻塞 event-loop 的下一个循环。然而,这样容易割裂业务逻辑,不易理解和维护。
(3) 调用read读取数据之后进行解码并放入队列中,等待工作线程处理。
(4) 工作线程处理完数据之后,返回到 event-loop 线程,由这个线程负责调用write把数据写回 client。
(5) accept 连接以及 conn 上的读写操作若是在主线程完成,则要求是非阻塞 I/O
Reactor 模式一条最重要的原则就是:
I/O 操作不能阻塞 event-loop 事件循环。
实际上 event loop 可能也可以是多线程的,只是一个线程里只有一个 select/poll/epoll_wait
参考文档
https://cloud.tencent.com/developer/article/2064645


![[DDR4] DDR 简史](https://img-blog.csdnimg.cn/direct/8d31fad7a28745eb81e253606f226423.png#pic_center)