爬虫流程
1. 确定目标网址和所需内容
https://www.jiansheku.com/search/enterprise/
只是个学习案例,所以目标就有我自己来选择,企业名称,法定代表人,注册资本,成立日期

2. 对目标网站,进行分析
-
动态内容分析:
JS和Ajax请求:确定页面是否使用JavaScript动态加载内容,如果是,需要分析Ajax请求以获取数据的API。
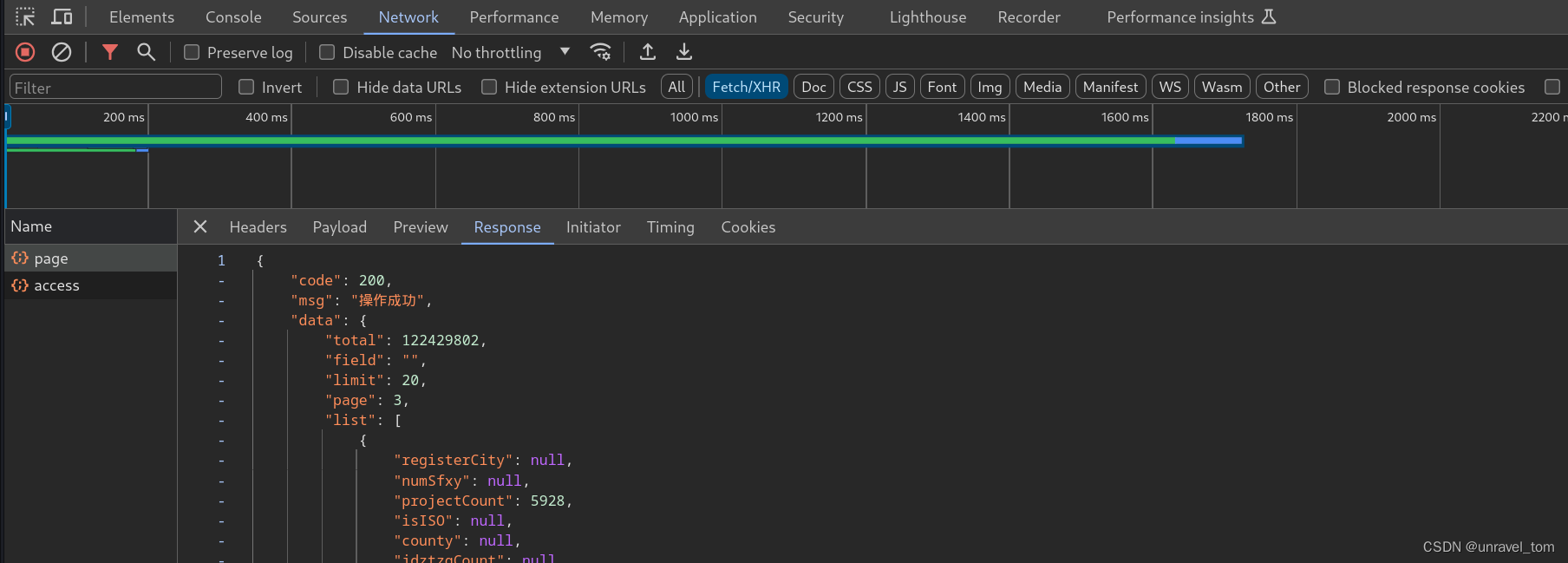 进行页面切换,抓去Ajax,发现page里面的response携带这我们所需要的数据
进行页面切换,抓去Ajax,发现page里面的response携带这我们所需要的数据找到动态变化值,一般在
headers,或者payload中,动态变化值,可能就是影响批量爬虫的关键
例中的payload是明文数据,headers中sign,timestamp是动态变化值
3 .找到加密的入口
靠经验,运气,猜测,分析代码,观察数据,调试代码,逆向分析,等等。
使用关键字搜索,断点,调用堆栈等方法。
这里我使用关键字搜索
使用正则表达式搜索缩小搜索范围,勾选“Use Regular Expression”或.*并输入正则表达式,如\bSign\b—\b确定搜索边界
像Math.sign这种是js的数学库文件,可以直接排除,就10几个,慢慢排查,使用断点调试
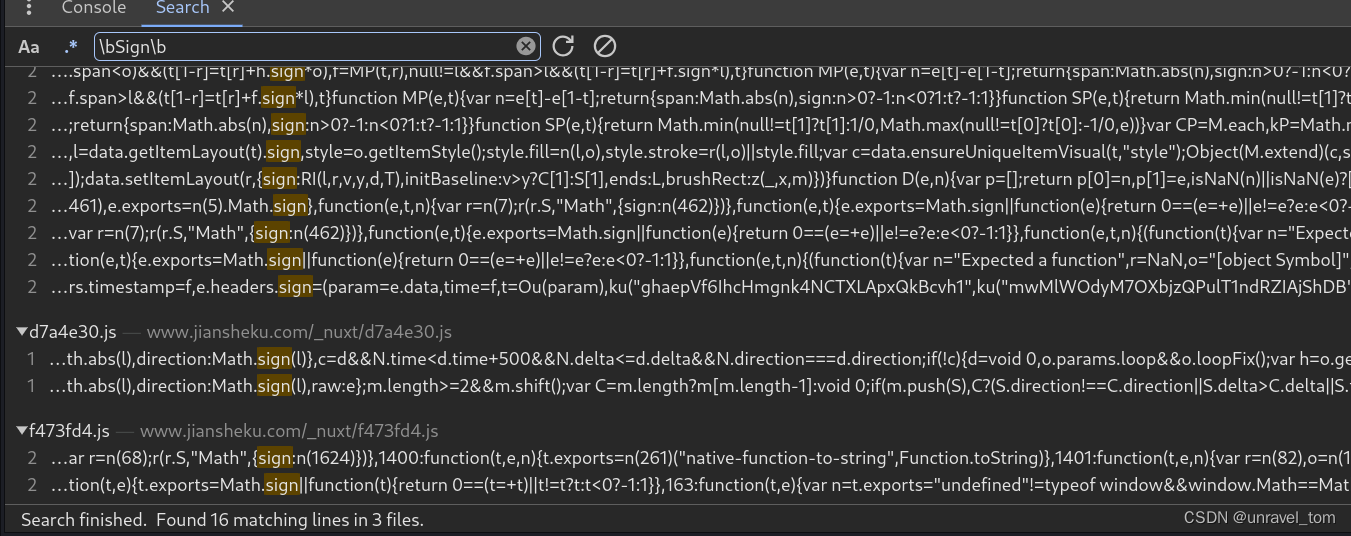
这里就是目标,注意这里使用了js的逗号表达式,想要查看结果悬浮,或者在控制台中查看,注意你要在断点的作用域内,函数是有生命周期的
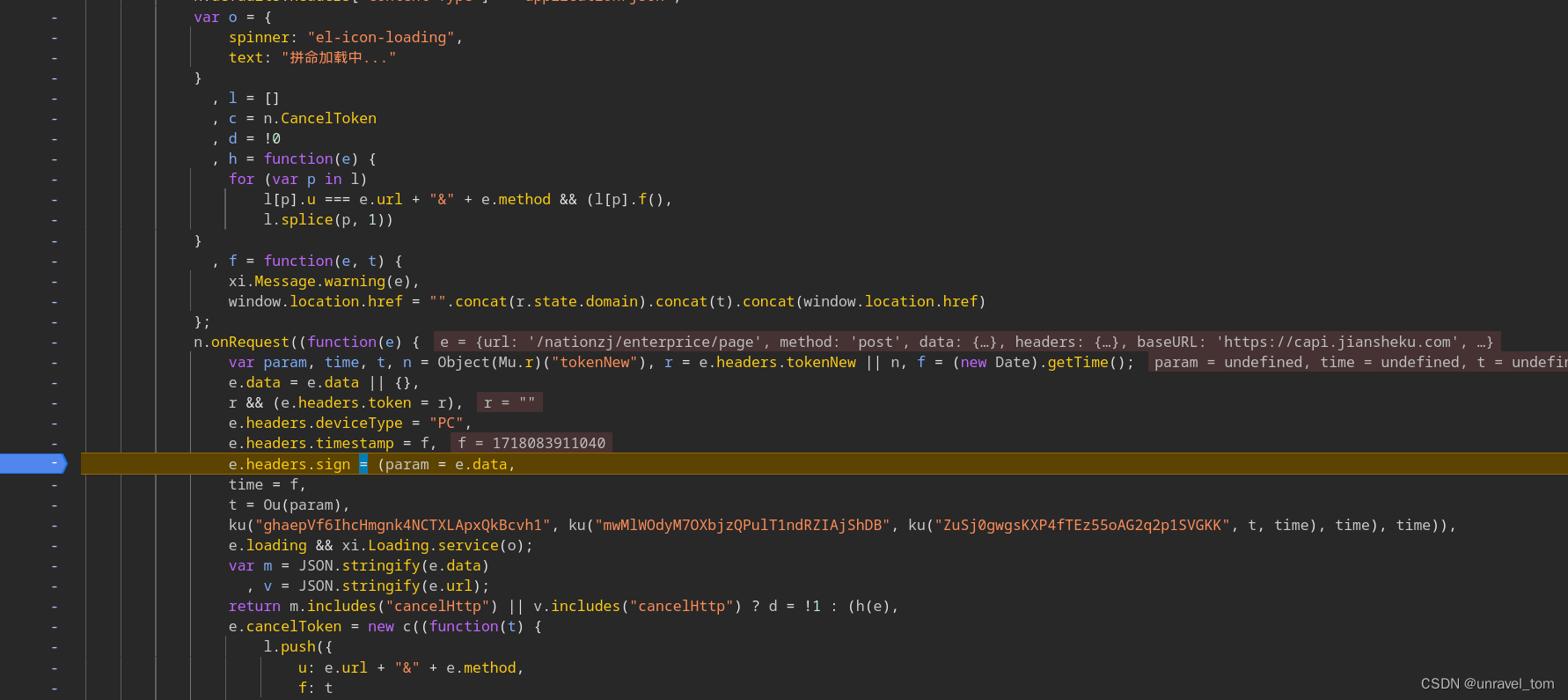
4. 扣js代码
复制js代码,模拟浏览器加密过程
这里我发现一个好用的小技巧,使用单步调试,从断点开始出发查看经过的函数基本都是我们所需的js代码,途中会跳转到其他的js文件(webpack)然后回来就可一看见MD5加密的算法了

5. 写代码
- 请求模拟
- 获取js逆向值
- py调用js
- 数据清洗
- 数据存储
- 处理反爬机制(ip封禁)
注意事项
- 下载packages的时候过慢,pip和node我都会给出镜像源
- 我使用的是Linux:
pip install PyExecJS2,Windows:pip install PyExecJS,不行就两个都试一遍 - google在浏览器开发者工具中不让粘贴,可在控制台输入
allow pasting - 本来打算以csv文件保存,但是爬取页数一多,就打不开csv文件,所以就保存为txt
- 最好不要使用异步模块,这个爬取的速度不会太慢,爬取的太快服务区可能不会响应
- 不要大量爬去,该网站会封IP(使用代理池就可以了)
packages
- pip
# 模拟浏览器发送请求
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
# 在py中调用js
pip install PyExecJS2 -i https://mirrors.aliyun.com/pypi/simple/
# 方便实时预览进度
pip install requests -i https://mirrors.aliyun.com/pypi/simple/
- npm
# 使用淘宝源
npm config set registry https://registry.npm.taobao.org
# 我遇到了证书过期(可能是我设置的是外国时区,使用的是国内的源),设置 npm 忽略 SSL 证书错误
npm config set strict-ssl false
npm install crypto-js
python code
import requests
import time
import execjs
import json
from tqdm import tqdm
def fetch_data(page, timer):
json_data = {
'eid': '',
'achievementQueryType': 'and',
'achievementQueryDto': [],
'personnelQueryDto': {
'queryType': 'and',
},
'aptitudeQueryDto': {
'queryType': 'and',
'nameStr': '',
'aptitudeQueryType': 'and',
'businessScopeQueryType': 'or',
'filePlaceType': '1',
'aptitudeDtoList': [
{
'codeStr': '',
'queryType': 'and',
'aptitudeType': 'qualification',
},
],
'aptitudeSource': 'new',
},
'page': {
'page': page,
'limit': 20,
'field': '',
'order': '',
},
}
get_sign = execjs.compile(open('jiansheku.js').read()).call('get_sign', json_data, timer)
cookies = {
'Hm_lvt_03b8714a30a2e110b8a13db120eb6774': '1718020163',
'Hm_lpvt_03b8714a30a2e110b8a13db120eb6774': '1718020163',
'HWWAFSESTIME': '1718020163509',
'HWWAFSESID': '228fb8efd82b43680e',
}
headers = {
'accept': 'application/json, text/plain, */*',
'accept-language': 'en-US,en;q=0.9',
'content-type': 'application/json;charset=UTF-8',
'devicetype': 'PC',
'origin': 'https://www.jiansheku.com',
'page': 'search-enterprise',
'priority': 'u=1, i',
'referer': 'https://www.jiansheku.com/',
'sec-ch-ua': '"Google Chrome";v="125", "Chromium";v="125", "Not.A/Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Linux"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'sign': get_sign,
'timestamp': str(timer),
'user-agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.0.0 Safari/537.36',
}
try:
response = requests.post('https://capi.jiansheku.com/nationzj/enterprice/page', cookies=cookies, headers=headers, json=json_data)
response.raise_for_status() # 检查请求是否成功
print(f"Page {page} fetched successfully")
print(response.text) # 打印响应内容以检查数据格式
return response.json()
except requests.RequestException as e:
print(f"Request failed for page {page}: {e}")
return None
def save_to_txt(all_records, filename='enterprise_data.txt'):
with open(filename, 'w', encoding='utf-8') as file:
headers = ['Name', 'Legal Person', 'Registered Capital', 'LiceValidity Date']
file.write('\t'.join(headers) + '\n')
for record in all_records:
line = f"{record['name']}\t{record['legalPerson']}\t{record['registeredCapital']}\t{record['liceValidityDate']}\n"
file.write(line)
print(f"数据已保存到 {filename} 文件中")
def main():
timer = time.time() * 1000
max_pages = 5 # 设置要遍历的最大页数
all_records = []
for page in tqdm(range(1, max_pages + 1)):
data = fetch_data(page, timer)
if data and 'data' in data and 'list' in data['data']:
records = [{
'name': item['name'],
'legalPerson': item.get('legalPerson', ''),
'registeredCapital': item.get('registeredCapital', ''),
'liceValidityDate': item.get('liceValidityDate', '')
} for item in data['data']['list']]
all_records.extend(records)
else:
print(f"No data found for page {page}")
if all_records:
# 将记录保存到txt文件
save_to_txt(all_records)
else:
print("No records to save.")
if __name__ == "__main__":
main()
js code
const Cryptojs = require("crypto-js")
ku = function(e, t, time) {
var n = t + e + time;
// 这里的MD5是加密算法,加密后的字符串就是签名
return n = Cryptojs.MD5(n).toString() // 经过单点调试,发现这里是加密算法构成的位置
}
Lu = function e(t) {
var n;
if (Array.isArray(t)) {
for (var r in n = new Array,
t) {
var o = t[r];
for (var i in o)
null == o[i] ? delete t[r][i] : Array.isArray(t[r][i]) && e(t[r][i])
}
return n = t,
JSON.stringify(n).replace(/^(\s|")+|(\s|")+$/g, "")
}
return n = t && t.constructor === Object ? JSON.stringify(t) : t
}
Tu = function(e) {
var t = new Array
, n = 0;
for (var i in e)
t[n] = i,
n++;
return t.sort()
}
Ou = function(e) {
var t = Tu(e)
, n = "";
for (var i in t) {
var r = Lu(e[t[i]]);
null != r && "" != r.toString() && (n += t[i] + "=" + r + "&")
}
return n
}
function get_sign(param, time) {
// param = {
// 'eid': '',
// 'achievementQueryType': 'and',
// 'achievementQueryDto': [],
// 'personnelQueryDto': {
// 'queryType': 'and',
// },
// 'aptitudeQueryDto': {
// 'queryType': 'and',
// 'nameStr': '',
// 'aptitudeQueryType': 'and',
// 'businessScopeQueryType': 'or',
// 'filePlaceType': '1',
// 'aptitudeDtoList': [
// {
// 'codeStr': '',
// 'queryType': 'and',
// 'aptitudeType': 'qualification',
// },
// ],
// 'aptitudeSource': 'new',
// },
// 'page': {
// 'page': 3,
// 'limit': 20,
// 'field': '',
// 'order': '',
// },
// };
// time = (new Date).getTime();
t = Ou(param);
return ku("ghaepVf6IhcHmgnk4NCTXLApxQkBcvh1", ku("mwMlWOdyM7OXbjzQPulT1ndRZIAjShDB", ku("ZuSj0gwgsKXP4fTEz55oAG2q2p1SVGKK", t, time), time), time);
}
// console.log(get_sign());