location: Beijing
1. why is GPU
CPU的存储单元和计算单元的互通过慢直接促进了GPU的发展
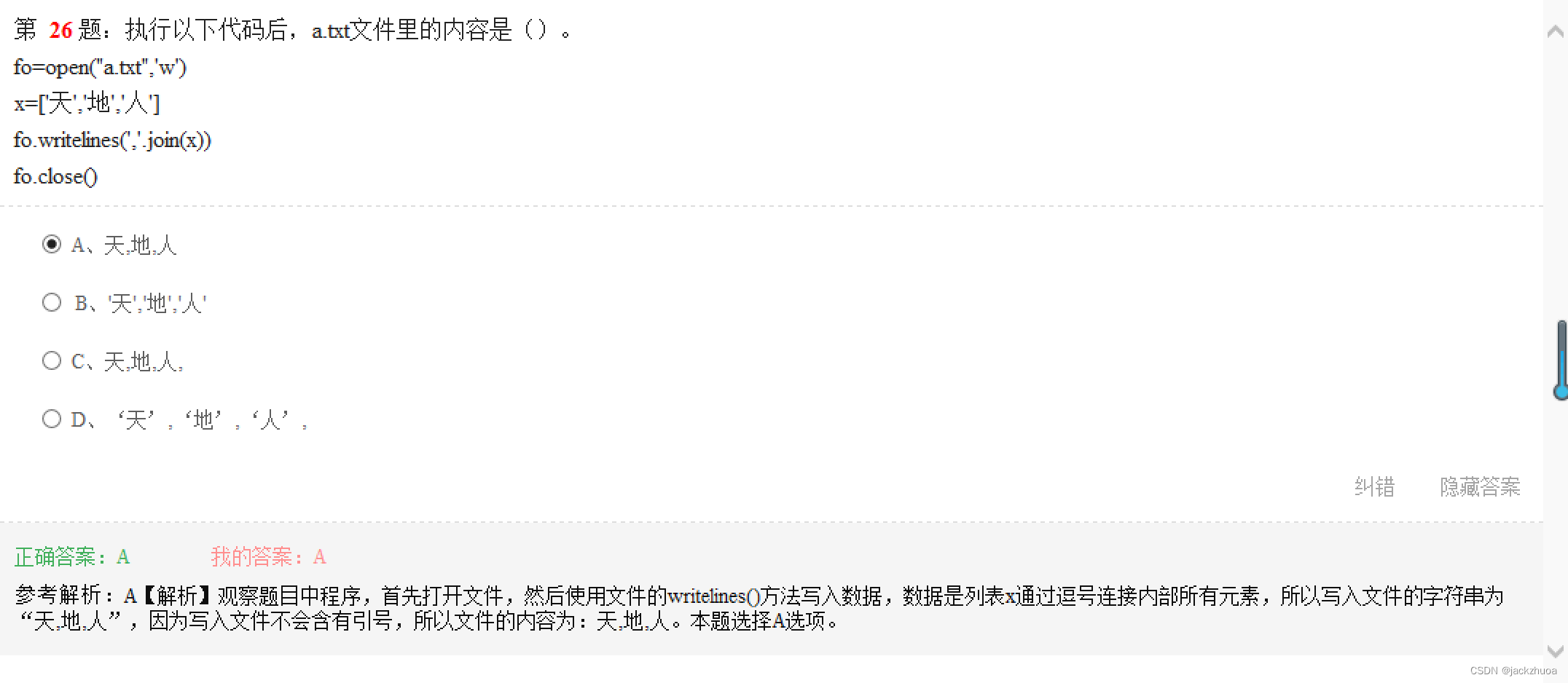
先介绍一个概念:FLOPS(Floating Point Operations Per Second,浮点运算每秒)是一个衡量其执行浮点运算的能力,可以作为计算机性能的指标。所以人们买计算机是往往关心一下计算机有多少FLOPS
然而,计算机性能可能是过剩的?下图是CPU与DRAM的关系

DRAM每秒把200GB的数据,也就是把25,000,000,000个FP64类型的浮点数传输给CPU;CPU每秒可以计算2,000,000,000,000个FP64类型的浮点数。可以看出,CPU可处理数据的能力是DRAM传输能力的80倍(这种比值有个专业术语:计算强度),除非我们的程序对每个数据都做80次运算,否则CPU的算力总是过剩的
所以从这里可以看出,大部分时间,计算机运行程序的速度并不取决于CPU的计算能力,而是DRAM与CPU传输数据的时间延迟(latency)
以一段测试程序daxpy函数为例:
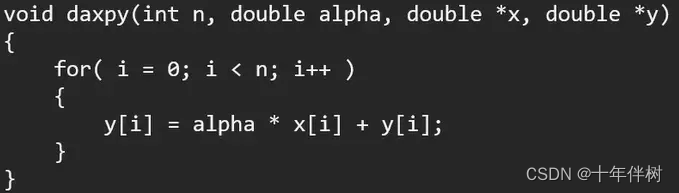
这里我们默认alpha存在CPU的缓存中,数组x和y存在DRAM中。当程序执行时,我们用甘特图看看程序的执行:

可以看出,在程序运行的过程中,CPU花了大量的时间在等待DRAM把数据传过来,这段等待时间大概是占整个程序执行时间的99%以上
至于为什么这么慢,我们可以理解为光速太慢,CPU尺寸太大,传输线太长……anyway,这里不在追究,不过值得一提的是,NVIDIA、Intel、AMD都无法解决这个物理问题
这个问题没办法解决了吗?或许我们可以另辟蹊径,既然这种latency无法避免,那我们就想办法“掩盖”这个latecy
如果总线在89ns内可以传输11659bytes数据,通过daxpy函数可以看到这个函数89ns内只要了16bytes的数据,所以为了让总线忙起来,我们只需要让daxpy函数一次要11659/16=729次数据就能让总线满负荷
比如下面一段程序一定程度上让总线忙一点
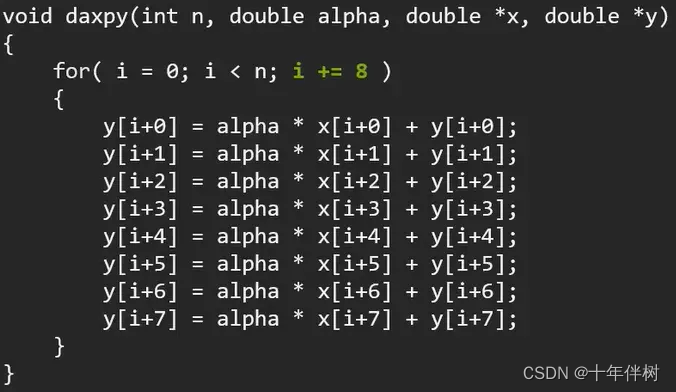
通过这种一次加载大量数据,让CPU和DRAM之间的传输线忙起来,这从一定程度上“减少”了后面加载的数据的延迟,使程序快速运行 ,理论上来讲,即使这是单线程的程序,我的循环中迭代729次也是没问题的
这里需要指出一个点:并行性指的是计算机同时处理多个任务的能力,在硬件限制下每个线程同时处理一个操作,但硬件可以处理很多线程;并发性指计算机有处理多个任务的能力,不讲究同时。
这样通过多线程的模式,也可以掩盖latency的的事实。

从这里可以看出NVIDIA的优势,通过对一批数据进行221184种不同的操作(线程),来掩盖latency的不足,GPU就是为少量数据进行大量任务而设计的,与此相比,CPU期望通过一个线程解决所有问题。
因此,解决latency的问题变为:创造足够多的线程。
2. What is GPU
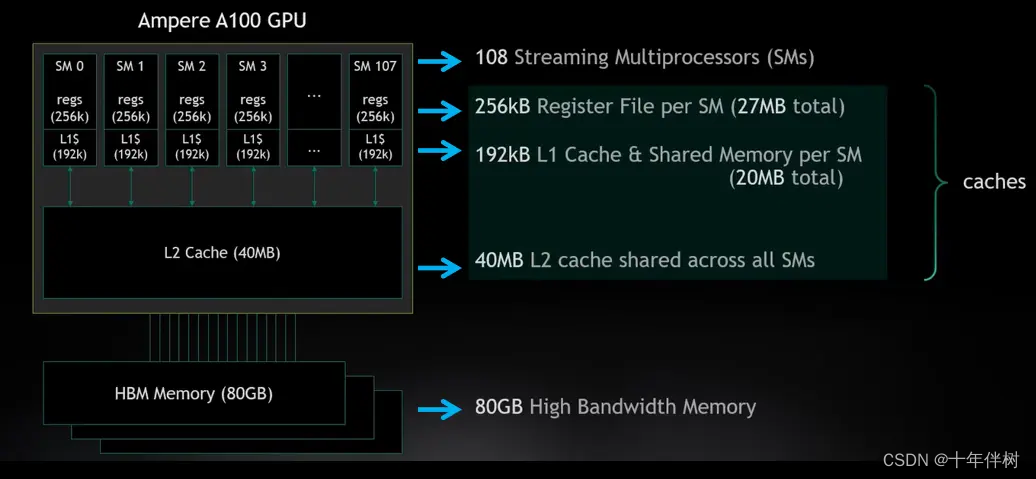
其中,我们希望离SM较近的寄存器能够尽可能的填满,因为每向较远的缓存访问数据,latency都会灾难性的上升。每一个SM都是一个基础处理单元,下图使SM的示意图
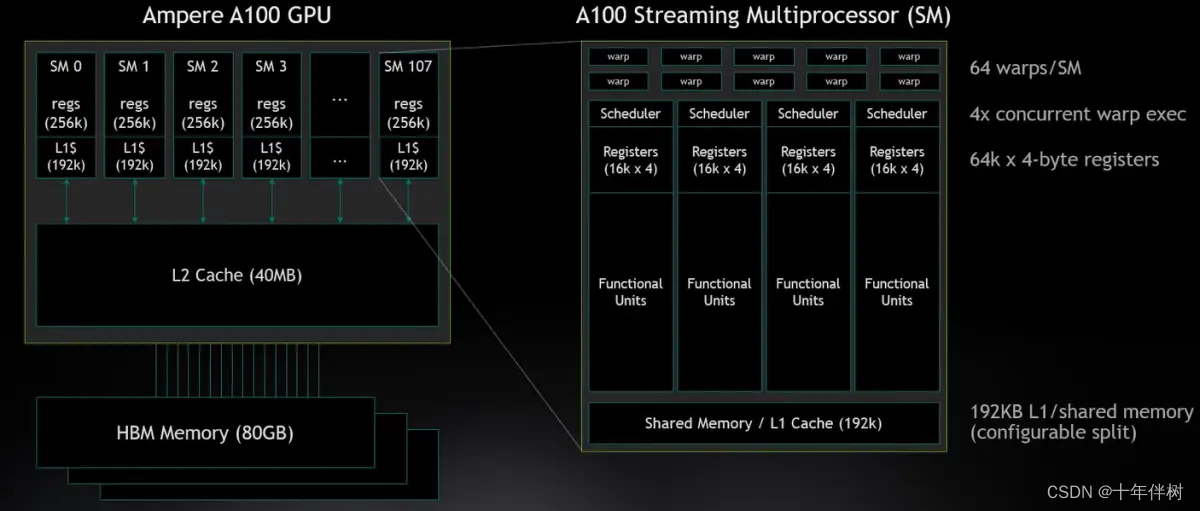
warp使GPU的基本调度单元,每个warp由32个线程组成,作用是将大量线程分组并同时执行,以实现并行计算和隐藏内存访问延迟,Warp中的32个线程将同时执行相同的指令,但操作不同的数据,但如果遇到条件分支语句(如if语句),不同线程可能会选择不同的执行路径。在这种情况下,Warp会以SIMD方式执行分支,即每个线程都会执行分支中的指令,但只有满足条件的线程会更新结果。
如果是单线程,那所有任务都要排队执行,而且最慢的任务可能卡着其他任务执行;但如果是多线程,所有任务都可以同时进入运算,这样就会更快,对延迟的处理更好。
但事实上,各线程之间很少能够独立的进行,因为很多算法或多或少需要一些邻居的数据,比如卷积操作,傅里叶变换。
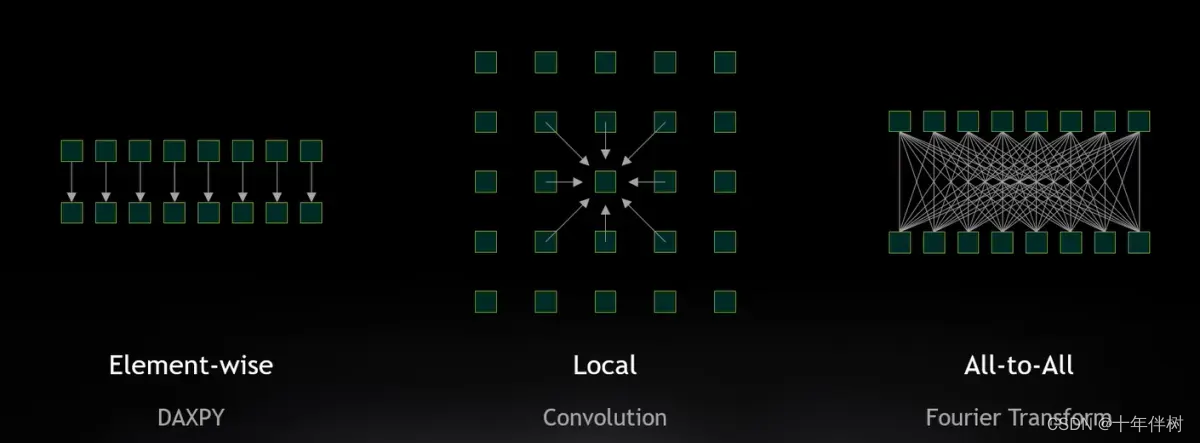
线程之间相互影响
3. How is GPU

比如我让AI去识别一只猫,首先先把照片切块,所有这些块相对独立的操作,GPU通过超量分配(oversubscribed)加载这些块,希望GPU的内存能够满载。然后每个块由若干线程同时操作,这些线程可以共享这个块的数据。
GPU的超量分配(Oversubscription)是指在GPU加速计算环境中,分配给应用程序或作业的资源超出了物理GPU硬件的实际容量,以覆盖latency。
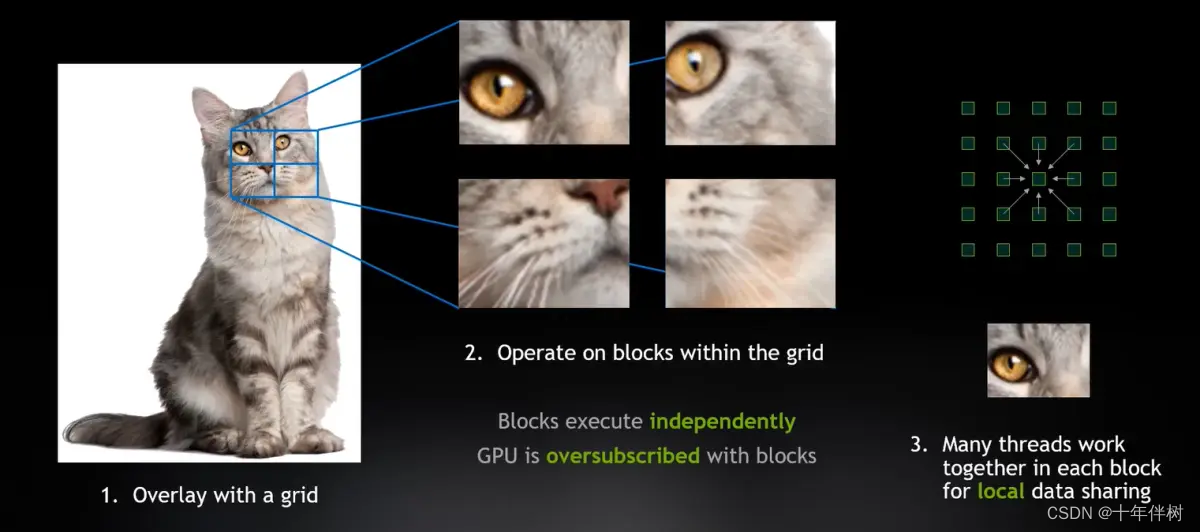
像这样,一个大的任务被分解成若干线程块,每个块相对独立,每个块都有同时进行的并行线程,这些并行的线程共享这个块的数据,当然特定块中的线程可以有所交叉。

不同类型问题类型的计算强度如下图,intensity Scales=compute Scales/data Scales
可以理解为,对于Element-wise问题,每增加到N个线程,多加载到N个数据,多N组运算;对local问题,每增加N到个线程,多加载NN个数据,多NN数量级次的运算,在卷积中再多的数据也没办法与算术强度相抗衡;但是对于All-to-All问题,每增加到N个线程,多加载N个数据,多了N*N次运算,算术强度就会增加N。

事实上,矩阵的乘法就是All-to-All问题,对于矩阵乘法,NN的矩阵相乘,有N行乘N列,再进行N次相加,所以compute Scales为O(NNN) ,访问内存的数量级是O(NN) ,因此算术强度是O(N) 。
下图的蓝线是矩阵计算的计算强度随矩阵规模增加的曲线,橘线是GPU的计算强度曲线,假设交点是50,计算机运算FP32的最佳位置也就是这个点。对于白线,100是双精度浮点数的最佳计算点。随着矩阵的增大,运算量变得更大,也就不太需要这么多的数据,所以内存也就变得更闲了。GPU中存在一些tensor cores,就是算力更强,这个点也就会上移一些。当内存用完,也就不需要增加算力了。
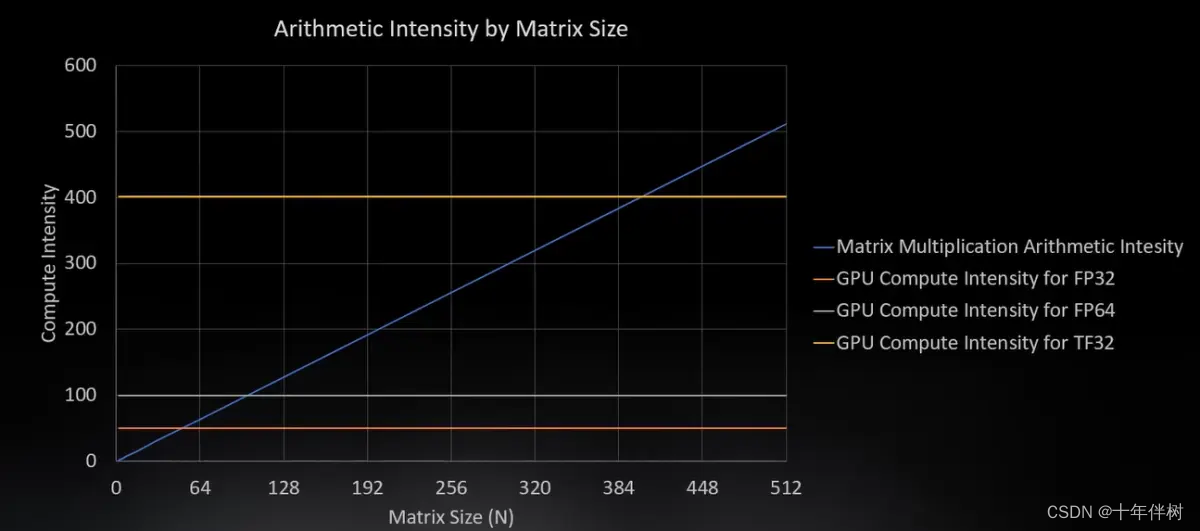
于是对应于GPU的内部结构,也就有了下图
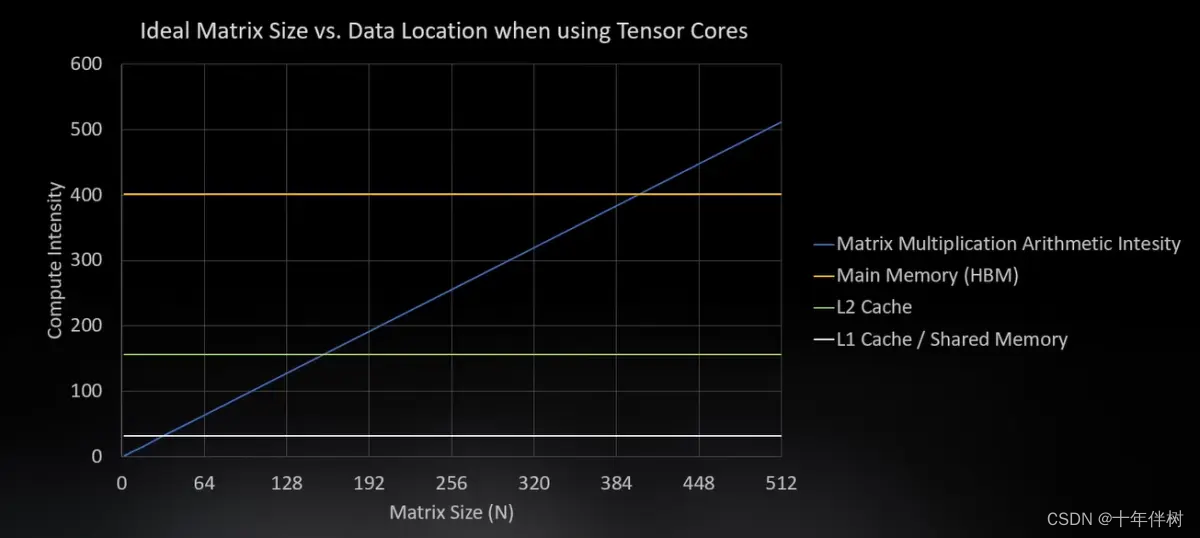
当数据存在L1,可以计算32*32,当数据存在L2可以计算大一些,当数据存在HBM,就会达到400。计算小矩阵更高效。
reference
[1] NVIDIA 2021 GPU工作原理