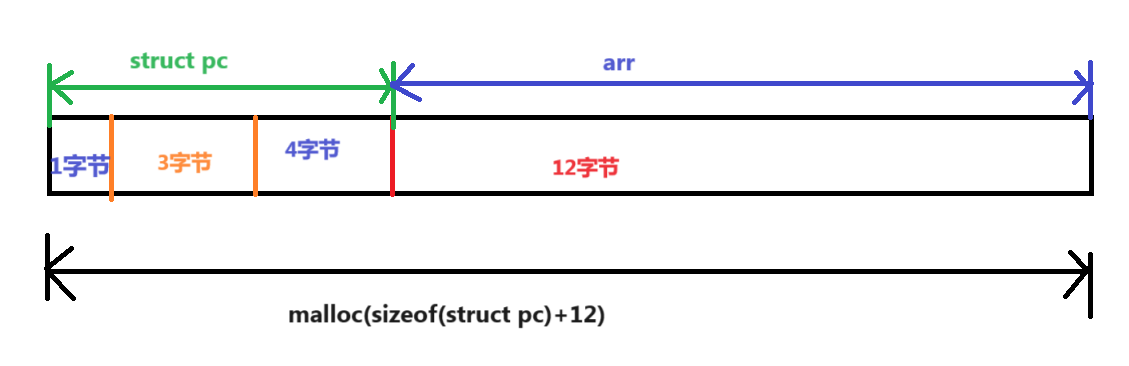
复星杏脉算法面经2024年5月
- 面试记录:3个部分1. 自己介绍 2. 问八股 3.代码题
- 先自我介绍
- 20分钟问问题
- 1. 梯度爆炸怎么解决,三个解决方案:梯度裁剪(Gradient Clipping)正则化(Regularization)调整激活函数
- 2. batch norm说一下 里面的缩放因子 为什么需要 shift
- 二分类任务的评价指标 仔细讲讲
- 如何缓解样本不均的二分类问题
- 其中Adan优化器比SGD优化器优点是什么,优化器的选择
- 有没有用过分布式训练dp和ddp,dp和ddp哪个更好
- 代码题15分钟但是很简单
- 解题思路一:
面试记录:3个部分1. 自己介绍 2. 问八股 3.代码题
1一小时
先自我介绍
再20分钟简历
然后问了其他自己做的实习论文
怎么做的 细细讲
20分钟问问题
1. 梯度爆炸怎么解决,三个解决方案:梯度裁剪(Gradient Clipping)正则化(Regularization)调整激活函数
梯度爆炸(Gradient Explosion)是指在训练深度神经网络时,梯度值在反向传播过程中变得非常大,导致模型参数更新过大,进而导致模型不稳定或无法收敛。以下是常用的三个解决梯度爆炸问题的方案:
- 梯度裁剪(Gradient Clipping):
梯度裁剪是直接限制梯度的大小,当梯度的范数超过预设的阈值时,将其缩放到该阈值范围内。这样可以防止梯度变得过大。
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
在上面的代码中,max_norm 参数设置了梯度的最大范数,当梯度的范数超过这个值时,会被裁剪到这个值。
- 正则化(Regularization):
正则化是一种在损失函数中添加额外项以防止过拟合的方法,常见的有 L1 和 L2 正则化。正则化项能够限制权重的大小,从而间接减小梯度的爆炸。
- L2 正则化(也称为权重衰减,Weight Decay):
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
在上面的代码中,weight_decay 参数即为 L2 正则化项的系数。
- 调整激活函数:
选择合适的激活函数可以帮助减小梯度爆炸的风险。某些激活函数如 ReLU 和 Leaky ReLU 相较于 sigmoid 和 tanh 更能减轻梯度爆炸问题,因为它们的梯度在正区间不会饱和。
- ReLU(Rectified Linear Unit):
import torch.nn.functional as F
def forward(self, x):
x = F.relu(self.fc1(x))
return x
- Leaky ReLU:
import torch.nn.functional as F
def forward(self, x):
x = F.leaky_relu(self.fc1(x), negative_slope=0.01)
return x
以上三种方法分别从梯度约束、模型正则化和激活函数选择三个不同角度来缓解梯度爆炸的问题,在实际应用中可以根据具体情况选择合适的方法或组合使用多种方法。
2. batch norm说一下 里面的缩放因子 为什么需要 shift

二分类任务的评价指标 仔细讲讲


如何缓解样本不均的二分类问题

其中Adan优化器比SGD优化器优点是什么,优化器的选择



Adam及其变种:结合动量和自适应学习率,快速稳定收敛,适用于大多数深度学习任务。
AdamW 是 Adam 优化器的改进版本,旨在解决 Adam 优化器在某些情况下会导致权重衰减(weight decay)效果不佳的问题。AdamW 是由 Ilya Loshchilov 和 Frank Hutter 提出的,并在他们的论文《Decoupled Weight Decay Regularization》中详细介绍。


AdamW 是一种改进的 Adam 优化器,通过将权重衰减与梯度更新分离,提供了更好的正则化效果和更快的收敛速度。它在许多深度学习任务中表现优异,是现代深度学习中常用的优化器之一。
有没有用过分布式训练dp和ddp,dp和ddp哪个更好

代码题15分钟但是很简单
Q1: Compression
e.g, input: aabbbdeffffww
output aa3bde4fww
连续大于等于三个相同的character用“数量+ character”表示,otherwise照常输出
解题思路一:
s = input()
result = ""
i = 0
while i < len(s) - 2:
c = s[i]
if c == s[i + 1] == s[i + 2]:
count = 3
while i + count < len(s) and s[i + count] == c:
count += 1
result += str(count)
result += c
i += count
else:
result += c
i += 1
if s[-1] != s[-3]:
result += s[-2]
result += s[-1]
print(result)
时间复杂度:O(n)
空间复杂度:O(1)



♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠