背景
现在,我们已经完成了,数据集的清洗,标签的制作,也把VGG16的模型建立好了。那接下来,我们应该把数据,放到我们搭建的vgg16的模型里面,让模型针对这些猫和狗的图片,去进行训练,经过几个epoch后,我们希望可以得到,一个经过若干轮训练后,学习的比较好的w,这样,当我们给这个vgg16的模型,一张它从没有见过的图片时候,它可以准确的判断出,这是猫还是狗。
声明:整个数据和代码来自于b站,链接:使用pytorch框架手把手教你利用VGG16网络编写猫狗分类程序_哔哩哔哩_bilibili
我做了复现,并且记录了自己在做这个项目分类时候,一些所思所得。
开始训练,我们新建一个main.py程序,作为我们训练的主程序,我们会在main.py里面,导入数据,对数据进行一些分批次的处理(data loader),然后调用我们新建的vgg16模型,进行训练,得到训练好的权重文件。
训练
1、导包
import torch
import torch.nn as nn
from net import vgg16
from torch.utils.data import DataLoader#工具取黑盒子,用函数来提取数据集中的数据(小批次) from data import *
from module import * 是一种导入模块的方式,这里的 module 是你要导入的模块名称。这条语句的意思是,从名为 data 的模块中,导入所有的公开(非以下划线开头的)对象到当前命名空间。这意味着,data.py 文件中定义的所有函数、类和变量(只要它们没有被定义为私有的,即没有前缀下划线 _)都将可以在当前脚本中直接使用,无需通过模块名作为前缀。data是做了数据增强。
2、数据集处理
数据集处理这里,要做两个事情:
读取标签(索引)文件,让程序正确的指向存放的图片
对于所有的图片,猫和狗的,做训练集和验证集的划分
2.1 读取标签文件并且打乱
实际上,标签文件就是一个索引文件,里面有每张图片的类别和每张图片的储存位置,
annotation_path='cls_train_1.txt'#读取数据集生成的文件
with open(annotation_path,'r',encoding='utf-8') as f:
lines=f.readlines() #按照行来读取,意思是把标签文件一行一行拿出来并存到名为lines的列表里
np.random.seed(10101)#函数用于生成指定随机数
np.random.shuffle(lines)#把lines列表里的数据打乱
np.random.seed(None)
-
np.random.seed(10101): 设定NumPy随机数生成器的种子为10101。这使得每次执行时产生的随机序列相同,对于实验的可重复性很重要。 -
np.random.shuffle(lines): 使用设定好的随机种子打乱lines列表中的元素顺序,实现数据集的随机化处理,有助于模型训练时的泛化能力。 -
np.random.seed(None): 重置随机数生成器的种子为默认值,这意味着接下来的随机操作将不再受之前设定种子的影响,产生真正的随机结果。
2.2 训练集和验证集的划分
把打乱的标签文件分成训练集和验证集
num_val = int(len(lines)*0.2) #先计算有多少图片,然后,取20%作为验证集
num_train = len(lines)-num_val #剩下的做训练集
3、处理图片:进行数据增强
把训练集和验证集划分好了,之前已经设定了图像增强的data.py文件,现在就是,把每张图片进行数据增强
input_shape=[224,224] #导入图像大小 train_data=DataGenerator(lines[:num_train],input_shape,True) val_data=DataGenerator(lines[num_train:],input_shape,False) val_len=len(val_data) print(val_len)#返回测试集长度
- 1. `input_shape=[224,224]`: 定义了图像预处理时所需的输入尺寸,即所有的输入图像都将被重塑为224x224像素的大小。这是常见的用于许多卷积神经网络(如VGG, ResNet等)的输入尺寸。实际上,
input_shape=[224,224]这一行代码本身并不直接修改任何图像的尺寸。它只是定义了预期的输入尺寸,告诉后续处理流程(比如深度学习模型)你期望输入图像的尺寸是多少。为了将不同大小的照片统一修改为这个尺寸,需要在数据预处理阶段实现图像的缩放或重塑功能。图像尺寸调整主要发生在data.py的get_random_data方法内。 - 2. `train_data=DataGenerator(lines[:num_train], input_shape, True)`:
- - 这一行实例化了一个名为`DataGenerator`的类(假设它是自定义的或第三方库中的数据生成器类),用于生成训练数据。
- - `lines[:num_train]`表示使用之前划分的前80%数据行(训练集)。
- - `input_shape=[224,224]`作为参数传递,指示数据生成器如何重塑图像尺寸。
- - `True`参数可能意味着此数据生成器在提供数据时会应用数据增强技术,这对于提高模型的泛化能力非常有用,尤其是在训练集相对有限的情况下。
- 3. `val_data=DataGenerator(lines[num_train:], input_shape, False)`:
- - 同样实例化`DataGenerator`类,但这次是为验证集创建数据生成器。
- - `lines[num_train:]`使用剩余的20%数据行(验证集)。
- - `input_shape`同样设置为224x224。
- - `False`参数表明验证集的数据生成不会应用数据增强,因为验证阶段我们希望看到模型在未修改数据上的真实表现。
- 4. `val_len=len(val_data)`: 计算验证集数据生成器中包含的样本数量,并将其赋值给变量`val_len`。
- 5. `print(val_len)`: 打印出验证集的长度,即验证集包含的样本数量。这对于了解数据分布、监控模型训练进度等都是有用的信息。
4、加载数据:dataloader
gen_train=DataLoader(train_data,batch_size=4)#训练集batch_size读取小样本,规定每次取多少样本
gen_test=DataLoader(val_data,batch_size=4)#测试集读取小样本
5、加载模型:模型实例化
选择设备以及模型实例化,并把模型转移到指定设备
device=torch.device('cuda'if torch.cuda.is_available() else "cpu")#电脑主机的选择 net=vgg16(True, progress=True,num_classes=2)
net.to(device)
- net=vgg16(True, progress=True,num_classes=2),因为之前是这么定义vgg16模的的:
def vgg16(pretrained=False, progress=True,num_classes=2):所以这三个参数要传进去
True: 表示加载预训练权重,这会从指定的URL下载预训练的VGG16模型权重并加载到模型中,这对于迁移学习非常关键。progress=True: 当从网上下载模型权重时,显示下载进度条。num_classes=2: 指定模型的输出类别数为2,猫狗分类
6、设置优化器
lr=0.0001#定义学习率
optim=torch.optim.Adam(net.parameters(),lr=lr)#导入网络和学习率 sculer=torch.optim.lr_scheduler.StepLR(optim,step_size=1)#步长为1的读取
-
学习率定义 (
lr):lr=0.0001这行代码定义了模型训练过程中的学习率(learning rate)为0.0001。学习率是一个超参数,决定了模型参数在梯度下降过程中更新的幅度,较小的学习率可以使训练过程更为稳定,但可能需要更多的迭代次数来收敛;较大的学习率可能加速收敛过程,但也可能导致训练不稳定或无法收敛。
-
优化器定义 (
optim):optim=torch.optim.Adam(net.parameters(),lr=lr)这里使用了Adam优化器来更新模型参数。Adam是Adaptive Moment Estimation的简称,是一种常用的优化算法,结合了RMSProp和动量的思想,能够自动调整学习率。
net.parameters()用于获取模型的所有可学习参数,lr=lr则指定了之前定义的学习率。这行代码实例化了一个Adam优化器,它将用于模型训练过程中参数的更新。
学习率调度器定义 (sculer):sculer=torch.optim.lr_scheduler.StepLR(optim,step_size=1)#
这行代码创建了一个学习率调度器StepLR,它以固定步长(step_size)调整学习率。在这里,step_size=1意味着每经过一次(一个epoch或一个batch,取决于调度器如何被调用)学习率就会按照预定的规则进行调整。但是,仅凭这段代码,我们无法得知学习率具体是如何调整的(比如降低多少比例),因为这通常还需要设置gamma参数(默认为0.1,意味着每step_size次学习率乘以0.1)。如果希望在每个周期后调整学习率,可能需要额外指定gamma值或者检查默认设置是否符合需求。
为了明确学习率如何随着训练进行而调整,特别是使用StepLR调度器时,你应该显式地设置gamma参数。gamma值决定了每次调整时学习率的衰减比例。默认情况下,如果没有指定gamma,StepLR会使用0.1,意味着每step_size个周期后学习率会乘以0.1,即减少到原来的10%。如果你想调整学习率衰减的策略,可以按照以下方式修改代码:
# 设置gamma值,例如衰减为原来的0.5 gamma_value = 0.5 sculer = torch.optim.lr_scheduler.StepLR(optim, step_size=1, gamma=gamma_value)
7、设置损失函数
criterion = nn.CrossEntropyLoss()
8、训练
epochs=20#读取数据次数,每次读取顺序方式不同
for epoch in range(epochs):
total_train=0 #定义总损失
for data in gen_train:
img,label=data
with torch.no_grad():
img =img.to(device)
label=label.to(device)
optim.zero_grad()
output=net(img)
train_loss=criterion(output,label).to(device)
train_loss.backward()#反向传播
optim.step()#优化器更新
total_train+=train_loss #损失相加
sculer.step()
total_test=0#总损失
total_accuracy=0#总精度
for data in gen_test:
img,label =data #图片转数据
with torch.no_grad():
img=img.to(device)
label=label.to(device)
optim.zero_grad()#梯度清零
out=net(img)#投入网络
test_loss=criterion(out,label).to(device)
total_test+=test_loss#测试损失,无反向传播
accuracy=((out.argmax(1)==label).sum()).clone().detach().cpu().numpy()#正确预测的总和比测试集的长度,即预测正确的精度
total_accuracy+=accuracy
【生成器的理解】
class DataGenerator(data.Dataset):
def __init__(self,annotation_lines,inpt_shape,random=True):
self.annotation_lines=annotation_lines
self.input_shape=inpt_shape
self.random=random
def __len__(self):
return len(self.annotation_lines)
def __getitem__(self, index):
annotation_path=self.annotation_lines[index].split(';')[1].split()[0]
image=Image.open(annotation_path)
image=self.get_random_data(image,self.input_shape,random=self.random)
image=np.transpose(preprocess_input(np.array(image).astype(np.float32)),[2,0,1])
y=int(self.annotation_lines[index].split(';')[0])
return image,y
在data.py中,`DataGenerator` 类被设计为生成器,它在每次迭代时不仅提供图像数据 (`img`) 还有对应的标签 (`label`)。当您看到 `data` 里面包含 `img` 和 `label`,这是因为在定义 `DataGenerator` 的 `__getitem__` 方法时,就已经指定了返回图像及其对应的标签。这里是关键部分的逻辑解释:
- 在 `DataGenerator` 类中,通过 `__getitem__` 方法定义了如何根据索引 `index` 获取单个样本。此方法内部,您首先使用索引从预先设定好的路径列表和标签列表中获取对应的图像路径和标签,然后对图像进行预处理(虽然具体的预处理函数 `preprocess_image` 没有展示,但假设它会读取图像文件并调整至所需尺寸等),最后返回这对数据(图像和标签)。
- 当使用 PyTorch 的 `DataLoader` 对象包装这个自定义的 `DataGenerator` 时,`DataLoader` 会在每个训练或验证周期内依次调用 `DataGenerator` 的 `__getitem__` 方法来获取数据。由于在 `DataGenerator` 中实现了返回 `(img, label)` 对,因此每次迭代时 `DataLoader` 返回的 `data` 实际上是一个包含图像张量和标签张量的元组。
所以,在训练循环中,这一行代码 `img, label = data` 实际上是对从 `DataLoader` 中取出的一个批次数据的解包操作,其中 `img` 是一个形状为 `[batch_size, channels, height, width]` 的四维张量,包含了批量的图像数据;而 `label` 则是一个形状为 `[batch_size]` 的一维张量,包含了这些图像对应的类别标签。这样,就可以直接使用这些数据进行模型的前向传播、计算损失、反向传播等训练步骤了。
【训练集和测试集的理解】
在深度学习中,训练集主要用于调整模型的权重参数。这一过程包括前向传播(forward pass)和反向传播(backward pass)两个主要步骤:
- 前向传播:模型接收输入数据,通过一系列的计算(如线性变换、激活函数等),产生预测输出。
- 反向传播:计算预测输出与实际标签之间的损失(loss),然后沿着网络的结构反向传播这个损失,以此来量化每个参数对损失的贡献程度。基于这些信息,算法(如梯度下降)会更新模型的参数,以期望在下一次预测时减小损失,即更准确地预测。
而对于测试集:
- 主要目的是评估模型在未见过的数据上的表现能力,即泛化能力。
- 测试集不参与模型参数的学习过程,因此只进行前向传播来获取预测结果,计算准确率、查准率、查全率等评价指标。
- 不执行反向传播和参数更新,因为测试集是用来模拟模型部署后遇到新数据时的表现,不应影响模型的训练过程。
总结来说,训练集用于教导模型如何预测,涉及参数调整;而测试集用来检验模型学得的知识,不改变模型参数。
【预测准确度的计算】
accuracy=((out.argmax(1)==label).sum()).clone().detach().cpu().numpy()
1. **`(out.argmax(1) == label)`**:
- `out` 是模型对于一批输入数据的预测输出,通常是一个二维张量,其中每一行对应一个样本的预测概率分布。
比如:
- `.argmax(1)` 操作沿着第1维度(行)找到概率最大的索引,即预测的类别。对于每个样本,这给出了模型认为最可能的类别。
- `label` 是这批数据的真实标签,也是一个张量,其中每个元素代表一个样本的真实类别。
- 这部分比较了模型的预测类别(`out.argmax(1)`)与真实类别(`label`),生成一个布尔张量,其中`True`表示预测正确,`False`表示预测错误。
2. **`.sum()`**:
- 上述布尔张量中,`True`值被视为1,`False`值被视为0。因此,`.sum()`操作计算了预测正确的样本数。
3. **`.clone().detach().cpu().numpy()`**:
- `.clone()` 创建了一个张量的副本,这在某些情况下是必要的,以避免修改原始张量。
- `.detach()` 用于从计算图中分离张量,这意味着对分离后的张量进行的操作不会记录到计算历史中,也不会占用额外的图形计算内存。这对于计算指标(如准确率)很有用,因为我们不需要对其进行反向传播。
- `.cpu()` 将张量从GPU(如果之前在GPU上)移动到CPU内存中,因为`.numpy()`方法只能在CPU张量上调用。
- `.numpy()` 最终将PyTorch张量转换为NumPy数组,便于进行进一步的数值处理或打印。
综上所述,这段代码计算了模型在某一批数据上的预测准确率,即预测正确的样本数占总样本数的比例。通过一系列操作,它确保了计算的正确性、高效性和兼容性。但请注意,为了得到整体的测试集精度,通常需要在整个测试集上累积这个准确率,并除以总的测试样本数。
【out.argmax(1) 的理解】
执行.argmax(1)操作时,对于每个样本,会得到预测概率最高的类别索引。
out.argmax(1) 是一个在深度学习和机器学习领域常用的张量操作,尤其是在处理分类问题时。这里假设out是一个二维张量(tensor),它通常代表了一组数据样本通过神经网络模型得到的预测概率分布。每个样本对应一行,每列对应一个类别,元素值表示该样本属于对应类别的概率。
具体来说:
.argmax(dim)是一个PyTorch中的函数,它作用于一个张量,返回沿着某一维度(dim)上的最大值的索引。索引是从0开始的整数。- 当你写
out.argmax(1)时,你是在要求沿着张量的第二个维度(索引为1的维度,通常代表类别)找到每一行(每个样本)的最大值所在的索引。这个索引实际上就是模型对于每个样本预测的类别标签,因为它指向了概率最高的那个类别的列。 -
在二分类问题中,场景会稍微简化一些,因为模型通常只需要预测两个类别,比如0(负类)和1(正类)。`out`张量对于每个样本仍然会给出两个类别的概率分布,但总和为1。例如:
```
out = [[0.3, 0.7], # 预测样本1为负类的概率为0.3,为正类的概率为0.7
[0.1, 0.9], # 预测样本2为负类的概率为0.1,为正类的概率为0.9
[0.6, 0.4]] # 预测样本3为负类的概率为0.6,为正类的概率为0.4
```这里的每一行第一个元素代表预测为类别0(通常视为负类)的概率,第二个元素代表预测为类别1(通常视为正类)的概率。
应用`.argmax(1)`操作后,我们得到每个样本预测的类别:
```
predicted_classes = out.argmax(1)
predicted_classes = [1, 1, 0] # 样本1和2被预测为类别1(正类),样本3被预测为类别0(负类)
```假设我们的`label`(真实类别)为:
```
label = [1, 1, 1] # 所有三个样本的真实类别均为正类(1)
```现在,我们比较预测类别与真实类别:
```
correct_predictions = (predicted_classes == label)
correct_predictions = [True, True, False] # 样本1和2预测正确,样本3预测错误
```这说明,在这个二分类问题的例子中,前两个样本的预测是正确的(`True`),而第三个样本的预测是错误的(`False`)。
9、保存模型
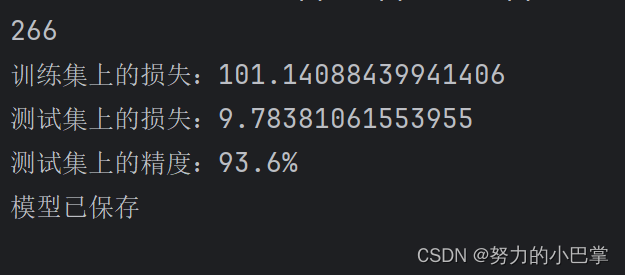
print("训练集上的损失:{}".format(total_train))
print("测试集上的损失:{}".format(total_test))
print("测试集上的精度:{:.1%}".format(total_accuracy/val_len))#百分数精度,正确预测的总和比测试集的长度
torch.save(net.state_dict(),"DogandCat{}.pth".format(epoch+1))
print("模型已保存")
完整代码
import numpy as np
import os
import torch
import torch.nn as nn
from net import vgg16
from torch.utils.data import DataLoader#工具取黑盒子,用函数来提取数据集中的数据(小批次)
from data import *
'''数据集'''
annotation_path='cls_train_1.txt'#读取数据集生成的文件
with open(annotation_path,'r',encoding='utf-8') as f:
lines=f.readlines()
np.random.seed(10101)#函数用于生成指定随机数
np.random.shuffle(lines)#数据打乱
np.random.seed(None)
num_val=int(len(lines)*0.2)#十分之一数据用来测试
num_train=len(lines)-num_val
#输入图像大小
input_shape=[224,224] #导入图像大小
train_data=DataGenerator(lines[:num_train],input_shape,True)
val_data=DataGenerator(lines[num_train:],input_shape,False)
val_len=len(val_data)
print(val_len)#返回测试集长度
# 取黑盒子工具
"""加载数据"""
gen_train=DataLoader(train_data,batch_size=4)#训练集batch_size读取小样本,规定每次取多少样本
gen_test=DataLoader(val_data,batch_size=4)#测试集读取小样本
'''构建网络'''
device=torch.device('cuda'if torch.cuda.is_available() else "cpu")#电脑主机的选择
net=vgg16(True, progress=True,num_classes=2)#定于分类的类别
net.to(device)
'''选择优化器和学习率的调整方法'''
lr=0.0001#定义学习率
optim=torch.optim.Adam(net.parameters(),lr=lr)#导入网络和学习率
sculer=torch.optim.lr_scheduler.StepLR(optim,step_size=1)#步长为1的读取
# 定义损失函数
criterion = nn.CrossEntropyLoss()
'''训练'''
epochs=20#读取数据次数,每次读取顺序方式不同
for epoch in range(epochs):
total_train=0 #定义总损失
for data in gen_train:
img,label=data
with torch.no_grad():
img =img.to(device)
label=label.to(device)
optim.zero_grad()
output=net(img)
train_loss=criterion(output,label).to(device)
train_loss.backward()#反向传播
optim.step()#优化器更新
total_train+=train_loss #损失相加
sculer.step()
total_test=0#总损失
total_accuracy=0#总精度
for data in gen_test:
img,label = data #图片转数据
with torch.no_grad():
img=img.to(device)
label=label.to(device)
optim.zero_grad()#梯度清零
out=net(img)#投入网络
test_loss=criterion(out,label).to(device)
total_test+=test_loss #测试损失,无反向传播
accuracy=((out.argmax(1)==label).sum()).clone().detach().cpu().numpy()#正确预测的总和比测试集的长度,即预测正确的精度
total_accuracy+=accuracy
print("训练集上的损失:{}".format(total_train))
print("测试集上的损失:{}".format(total_test))
print("测试集上的精度:{:.1%}".format(total_accuracy/val_len))#百分数精度,正确预测的总和比测试集的长度
torch.save(net.state_dict(),"DogandCat{}.pth".format(epoch+1))
print("模型已保存")
结果:






![【2024最新华为OD-C/D卷试题汇总】[支持在线评测] 部门项目任务分配(100分) - 三语言AC题解(Python/Java/Cpp)](https://img-blog.csdnimg.cn/direct/2404e031ec004407b0e0c8239e8fc605.png)