为什么要使用线程池?
- 降低资源的消耗,降低线程创建和销毁的资源消耗;
- 降低响应速度:线程的创建时间为T1,执行时间T2,销毁时间T3,免去T1和T3的时间;
- 提高线程的可管理性
线程池的核心思想:线程复用,同一个线程可以被重复停用,来处理多个任务。
实现流程
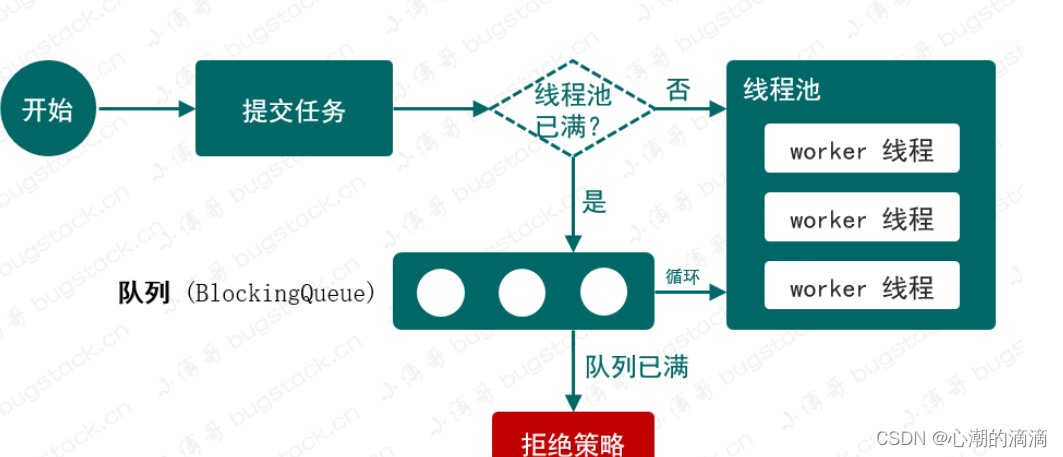
这个手写线程池的实现也非常简单,只会体现出核心流程:包括:
- 有n个一直在运行的线程,相当于我们创建线程池时允许的线程池大小;
- 把线程提交给线程池运行;
- 如果运行线程池已满,则把线程放入队列中;
- 最后当有空闲时,则获取队列中线程进行运行。
代码实现
阻塞队列的实现
- 阻塞队列主要存放任务,有容量限制
- 阻塞队列提供添加和删除任务的API,如果超过容量,阻塞不能添加任务,如果没有任务,阻塞无法获取任务
public class BlockingQueue<T> {
private Logger logger = LoggerFactory.getLogger(BlockingQueue.class);
// 容量
private Integer capacity;
// 双端任务队列容器
private Deque<T> deque = new ArrayDeque<>();
// 重入锁
private ReentrantLock lock = new ReentrantLock();
// 生产者条件变量
private Condition fullWaitSet = lock.newCondition();
// 生产者条件变量
private Condition emptyWaitSet = lock.newCondition();
public BlockingQueue(int capacity) {
this.capacity = capacity;
}
// 尝试添加任务
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
// 如果队列超过容量
if (deque.size() > capacity) {
logger.debug("task too much, do reject");
rejectPolicy.reject(this, task);
} else {
deque.offer(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
// 阻塞的方式添加任务
public void put(T task) {
lock.lock();
try {
// 通过while的方式
while (deque.size() >= capacity) {
logger.debug("wait to add queue");
try {
fullWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
deque.offer(task);
logger.debug("task add successfully");
emptyWaitSet.signal();
} finally {
lock.unlock();
}
}
// 阻塞获取任务
public T take() {
lock.lock();
try {
// 通过while的方式
while (deque.isEmpty()) {
try {
logger.debug("wait to take task");
emptyWaitSet.await();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
fullWaitSet.signal();
T task = deque.poll();
logger.debug("take task successfully");
// 从队列中获取元素
return task;
} finally {
lock.unlock();
}
}
}
- put()方法是向阻塞队列中添加任务
- take()方法是向阻塞队列中获取任务
线程池消费端实现
- 定义执行器接口
public interface Executor {
// 提交任务执行
void execute(Runnable task);
}
- 定义线程池类实现该接口
public class ThreadPool implements Executor {
private Logger logger = LoggerFactory.getLogger(ThreadPool.class);
// 任务队列
private BlockingQueue<Runnable> taskQueue;
// 核心工作线程数
private int coreSize;
// 工作线程集合
private final Set<Worker> workers = new HashSet<>();
// 拒绝策略
private RejectPolicy rejectPolicy;
public ThreadPool(int coreSize, int capacity, RejectPolicy rejectPolicy) {
this.coreSize = coreSize;
this.taskQueue = new BlockingQueue<>(capacity);
this.rejectPolicy = rejectPolicy;
}
// 提交任务执行
@Override
public void execute(Runnable task) {
synchronized (workers) {
// 如果工作线程数小于阈值,直接开始任务执行
if (workers.size() < coreSize) {
Worker worker = new Worker(task);
workers.add(worker);
worker.start();
} else {
// 如果超过了阈值,加入到队列中
// taskQueue.put(task);
// 调用tryPut的方式
taskQueue.tryPut(rejectPolicy, task);
}
}
}
// 工作线程,对执行的任务做了一层包装经验
class Worker extends Thread {
private Runnable task;
public Worker(Runnable task) {
this.task = task;
}
@Override
public void run() {
// 如果任务不为空,或者可以从队列中获取任务
while (Objects.nonNull(task) || Objects.nonNull(task = taskQueue.take())) {
try {
task.run();
} catch (Exception e) {
e.printStackTrace();
} finally {
// 执行完后,设置任务为空
task = null;
}
}
// 移除工作线程
synchronized (workers) {
logger.debug("remove worker successfully");
workers.remove(this);
}
}
}
}
- Worker类是工作线程类,包装了执行任务,里面实现了从队列获取任务,然后执行任务
- execute()方法的实现中,如果工作线程数量小于阈值的话,直接创建新的工作线程,否则将任务添加到队列中
获取任务超时设计
目前从队列中获取任务是永久阻塞等待的,可以改成阻塞一段时间没有获取任务,丢弃的策略
public class TimeoutBlockingQueue<T> {
private Logger logger = LoggerFactory.getLogger(TimeoutBlockingQueue.class);
// 容量
private int capacity;
// 双端任务队列容器
private Deque<T> deque = new ArrayDeque<>();
// 重入锁
private ReentrantLock lock = new ReentrantLock();
// 生产者条件变量
private Condition fullWaitSet = lock.newCondition();
// 生产者条件变量
private Condition emptyWaitSet = lock.newCondition();
public TimeoutBlockingQueue(int capacity) {
this.capacity = capacity;
}
// 带超时时间的获取
public T poll(long timeout, TimeUnit unit) {
lock.lock();
try {
// 将timeout统一转换为纳秒
long nanos = unit.toNanos(timeout);
while (deque.isEmpty()) {
try {
if (nanos <= 0) {
return null;
}
// 返回的是剩余的等待时间,更改nanos的值,使虚假唤醒的时候可以继续等待
nanos = emptyWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
fullWaitSet.signal();
return deque.getFirst();
} finally {
lock.unlock();
}
}
// 带超时时间的增加
public boolean offer(T task, long timeout, TimeUnit unit) {
lock.lock();
try {
// 将timeout统一转换为纳秒
long nanos = unit.toNanos(timeout);
while (deque.size() == capacity) {
try {
if (nanos <= 0) {
return false;
}
// 更新剩余需要等待的时间
nanos = fullWaitSet.awaitNanos(nanos);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
logger.debug("加入任务队列 {}", task);
deque.addLast(task);
emptyWaitSet.signal();
return true;
} finally {
lock.unlock();
}
}
}
拒绝策略设计
目前的实现还是有个漏洞,无法自定义任务超出出阈值的一个拒绝策略,我们可以通过函数式编程+策略模式去实现
- 定义策略模式的函数式接口
@FunctionalInterface
public interface RejectPolicy<T> {
// 拒绝策略的接口
void reject(BlockingQueue<T> queue, T task);
}
- 添加函数式接口的调用入口
我们可以在阻塞队列添加任务新加一个api,添加任务如果超过容量,调用函数式接口
// 尝试添加任务
public void tryPut(RejectPolicy<T> rejectPolicy, T task) {
lock.lock();
try {
// 如果队列超过容量
if (deque.size() > capacity) {
logger.debug("task too much, do reject");
rejectPolicy.reject(this, task);
} else {
deque.offer(task);
emptyWaitSet.signal();
}
} finally {
lock.unlock();
}
}
- 演示
public class TestThreadPool1 {
private static Logger LOGGER = LoggerFactory.getLogger(TestThreadPool1.class);
public static void main(String[] args) throws InterruptedException {
Executor executor = new ThreadPool(2, 4, new RejectPolicy() {
@Override
public void reject(BlockingQueue queue, Object task) {
LOGGER.error("task too much");
}
});
// 提交任务
for (int i = 0; i < 6; i++) {
final int j = i;
executor.execute(() -> {
try {
Thread.sleep(10);
LOGGER.info("run task {}", j);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
Thread.sleep(10);
}
Thread.sleep(10000);
}
}