Hi,大家好。我是茶桁。
前段时间我介绍过一款文字生视频的 AI 工具:SadTalker, 当时咱们是作为 Stable Diffusion 的插件来安装的。
那基于 Stable Diffusion 呢,咱们今天就来聊聊新开源的 Stable Diffusion 3。
在文字生成图片这个领域,一直是有三个主要的竞争者,Midjourney, DELL-3, 还有就是 Stable Diffusion。前不久,Stable Diffusion 开源了 SD3,使用过后,效果直逼 Midjourney,而在社区内的出图效果来看,可以替代 Midjourney 作为主力出图工具了。这可真是能省下不少钱,毕竟那可都是真金白银。
好,那到底如何去安装 Stable Diffusion 3 呢?这次咱们不使用 Stable Diffusion WebUI,来看另外一款 UI 工具: ComlyUI。
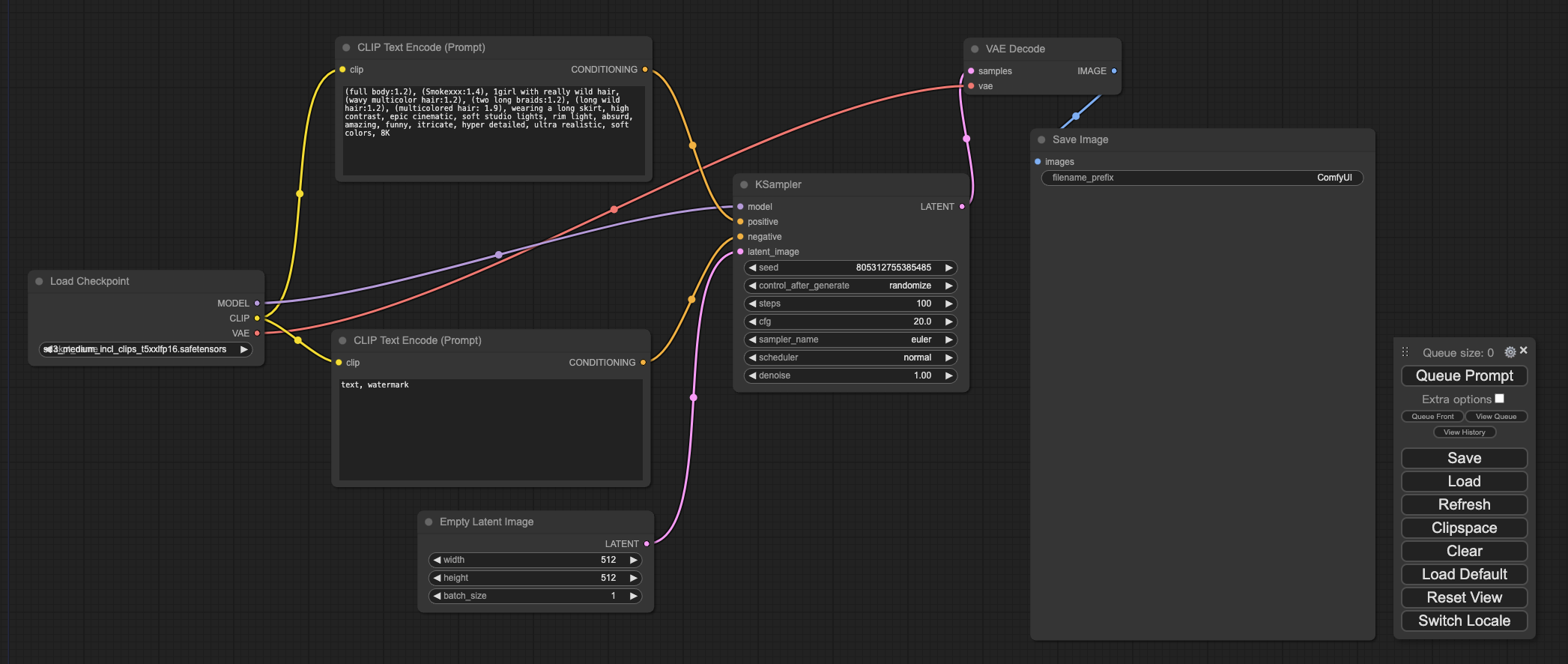
这款应用的风格是类似于 Blender,在相关节点之间进行连线来完成通路。
具体安装嘛,首先,我们需要下载开源的 Stable Diffusion 3 大模型:https://huggingface.co/stabilityai/stable-diffusion-3-medium/tree/main
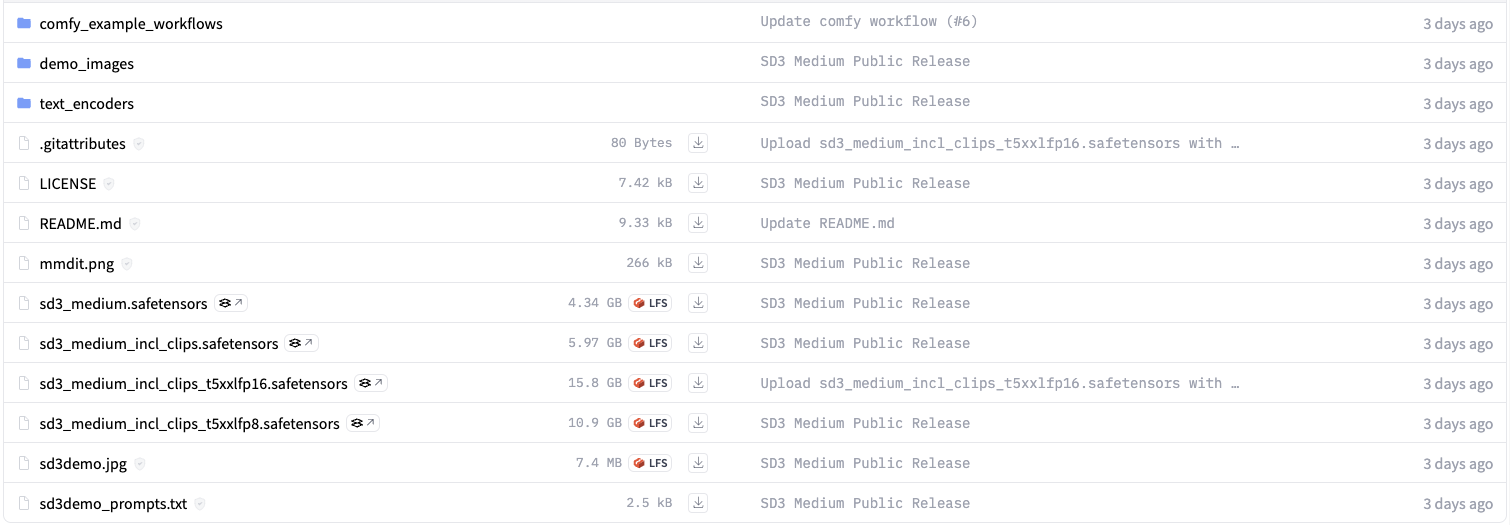
如何你和我一样是 M1 芯片,建议你选择 sd3_medium_incl_clips_t5xxlfp8.safetensors,总体上来说,这个模型比 fp16 要快上不少,生图的质量也算有所保障。
下载好之后,接下来我们去下载 ComlyUI: https://github.com/comfyanonymous/ComfyUI?tab=readme-ov-file
直接git clone,克隆到本地后进入ComfyUI目录。打开目录,将我们刚才下载的模型拷贝到/ComlyUI/models/checkpoints/中。
然后执行python main.py,如果之前你已经根据我的教程完成过 SD 的环境设置,那么基本上,这次直接就会启动了,地址为: http://127.0.0.1:8188。
基本上,到这里我们就完成了,不过如果你对语言有要求(障碍),那咱们还可以下载一个语言包,反正我是需要语言包的:https://github.com/AIGODLIKE/AIGODLIKE-ComfyUI-Translation,一样,先执行git clone 将其克隆到本地,然后将其放入目录 /ComfyUI/custom_nodes/,再到界面里去设置一下就可以了。
好了,至此安装结束了,咱们可以自己尝试一下生成图了。至于如何选择模型,如何设置大小和图片数量,以及其他设置,自己摸索一下就能明白。实在还需要一个小指导的,可以关注我视频号去看看我最新一期的视频。
下课…