目录
工业界中的机器学习
之前的部分涵盖了因果推理的核心。那里的技术是众所周知和成熟的。他们经受住了时间的考验。第一部分建立了我们可以依赖的坚实基础。用更专业的术语来说,第一部分侧重于定义什么是因果推理,哪些偏差会阻止相关性成为因果关系,调整这些偏差的多种方法(回归、匹配和倾向得分)和规范识别策略(工具变量、双重差分 和 断点回归)。总之,第一部分重点介绍了我们用来确定平均干预效果 的标准技术。
当我们进入第二部分时,事情会变得有点不稳定。我们将介绍因果推理文献的最新发展、它与机器学习的关系以及行业中的应用。从这个意义上说,我们在学术严谨性与适用性和经验主义之间进行了权衡。第 II 部分中介绍的一些方法没有关于它们为什么起作用的可靠理论。尽管如此,当我们尝试它们时,它们似乎仍然有效。从这个意义上说,对于想要在日常工作中使用因果推理的行业从业者,而不是想要研究世界上基本因果关系的科学家,第二部分可能更有用。
第二部分的前几章将侧重于估计异质治疗效果。我们将从一个只关心平均治疗效果 的世界转移到一个我们想知道不同单位对治疗有何不同反应的世界
。这是个性化至关重要的世界。我们希望优先治疗那些治疗效果最有影响的人,我们不想治疗那些治疗对他们有害的人。从某种意义上说,我们也在从一个关于平均治疗效果的积极问题转向一个规范性问题:我们应该治疗谁?
这是大多数企业问自己的问题,尽管措辞略有不同:我应该给谁打折?我应该对贷款收取多少利率?我应该向该用户推荐什么项目?我应该向每位客户展示什么页面布局?这些都是治疗效果异质性问题,我们可以使用第二部分中提供的工具来回答。但在我们这样做之前,我只公平地介绍一下机器学习对行业的意义,因为这将成为我们稍后将用于因果推理的基本工具。
工业界中的机器学习
重点是谈谈我们在工业界中通常是如何使用机器学习的。如果您不熟悉机器学习,可以将本章视为机器学习速成课程。如果您以前从未使用过 ML,我强烈建议您至少学习基础知识,以充分利用即将发生的事情。但这并不意味着如果您已经精通机器学习,就应该跳过本章。我仍然认为你会从阅读中受益。与其他机器学习材料不同,这本书不会讨论决策树或神经网络等算法的来龙去脉。相反,它将专注于机器学习在现实世界中的应用。

我想首先说明的是,为什么我们要在因果推理书中谈论机器学习?简短的回答是因为我认为理解因果关系的最佳方法之一是将其与机器学习带来的预测模型方法进行对比。长答案是双重的。首先,如果你已经读到本书的这一点,那么你很有可能已经熟悉机器学习。其次,即使你不是,鉴于这些主题目前的流行,你可能已经对它们是什么有了一些了解。唯一的问题是,在机器学习大肆宣传的情况下,我可能不得不带你回到现实,并用非常实用的术语解释它的真正作用。最后,因果推理的最新发展大量使用机器学习算法,所以也有。
非常直接,机器学习是一种快速、自动和良好预测的方法。这不是全部,但它涵盖了其中的 90%。它是在有监督的机器学习领域取得了大多数很酷的进步,如计算机视觉、自动驾驶汽车、语言翻译和诊断。请注意,起初,这些看起来不像是预测任务。语言翻译是如何预测的?这就是机器学习的美妙之处。我们可以通过预测解决比最初显而易见的问题更多的问题。在语言翻译的情况下,您可以将其构建为一个预测问题,即您向机器展示一个句子,并且它必须用另一种语言预测同一个句子。请注意,我不是在预测或预测未来的意义上使用预测这个词。预测只是从一个定义的输入映射到一个最初未知但同样定义良好且可观察的输出。
机器学习真正做的是学习这个映射函数,即使它是一个非常复杂的映射函数。底线是,如果您可以将问题描述为从输入到输出的映射,那么机器学习可能是解决该问题的不错选择。至于自动驾驶汽车,你可以认为它不是一个,而是多个复杂的预测问题:从汽车前部的传感器预测车轮的正确角度,从汽车周围的摄像头预测刹车的压力,根据 gps 数据预测加速器中的压力。解决这些(以及更多)预测问题是制造自动驾驶汽车的原因。
考虑 ML 的一种更具技术性的方式是估计(可能非常复杂)期望函数:
其中 Y 是您想知道的(翻译句子,诊断),而 X 是您已经知道的(输入句子,X 射线图像)。机器学习只是一种估计条件期望函数的方法。
好的……您现在了解预测如何比我们最初想象的更强大。自动驾驶汽车和语言翻译很酷,但它们相距甚远,除非你在谷歌或优步这样的大型科技公司工作。所以,为了让事情更相关,让我们来谈谈几乎每个公司都有的问题:客户获取(即获得新客户)。
从客户获取的角度来看,您通常需要做的是弄清楚谁是有利可图的客户。在这个问题中,每个客户都有获取成本(可能是营销成本、入职成本、运输成本……),并有望为公司带来正现金流。例如,假设您是一家互联网提供商或一家天然气公司。您的典型客户可能有一个看起来像这样的现金流。
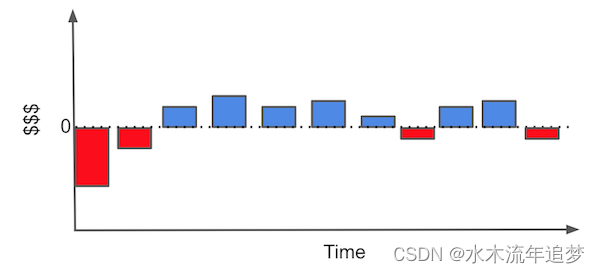
每个条形代表您与客户关系中的一个金钱事件。例如,要立即获得客户,您需要投资于营销。然后,在某人决定与您开展业务后,您可能会产生某种入职成本(您必须向客户解释如何使用您的产品)或安装成本。只有这样,客户才开始产生每月收入。在某些时候,客户可能需要一些帮助,而您将承担维护费用。最后,如果客户决定终止合同,您可能也会为此承担一些最终成本。
要查看这是否是一个有利可图的客户,我们可以在所谓的级联图中重新排列条形图。希望现金事件的总和最终高于零线。
相反,客户很可能会产生比收入更多的成本。如果他或她很少使用你的产品并且有很高的维护需求,当我们堆积现金事件时,它们最终可能会低于零线。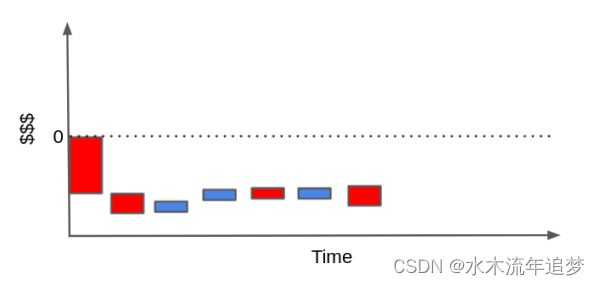
当然,这种现金流可能更简单或更复杂,具体取决于业务类型。你可以用利率做时间折扣之类的事情,然后为此疯狂,但我认为这里的重点是正确的。
但是你能做些什么呢?好吧,如果你有很多盈利和非盈利客户的例子,你可以训练一个机器学习模型来识别它们。这样,您就可以将营销策略集中在只针对有利可图的客户身上。或者,如果您的合同允许,您可以在客户产生更多成本之前终止与客户的关系。本质上,您在这里所做的是将业务问题构建为预测问题,以便您可以通过机器学习解决它:您想要预测或识别有利可图和无利可图的客户,以便您只与有利可图的客户互动。
import pandas as pd
import numpy as np
from sklearn import ensemble
from sklearn.model_selection import train_test_split
from sklearn.pipeline import Pipeline
from sklearn.metrics import r2_score
import seaborn as sns
from matplotlib import pyplot as plt
from matplotlib import style
style.use("ggplot")例如,假设您有 10000 个客户的 30 天交易数据。 您还需要购买 cacq 的成本。 如果您进行在线营销,这可能是您为他们提出的出价,也可能是运输成本或您必须与客户进行的任何培训,以便他们可以使用您的产品。 此外,为了简单起见(这是一门速成课程,而不是关于客户评估的一个学期),让我们假设您可以完全控制与您开展业务的客户。 换句话说,即使客户想与您做生意,您也有权拒绝客户。 如果是这种情况,您现在的任务就是事先确定谁将获利,因此您可以选择只与他们互动。
transactions = pd.read_csv("data/customer_transactions.csv")
print(transactions.shape)
transactions.head()
(10000, 32)
我们现在需要做的是根据这个交易数据来区分好客户和坏客户。为了简单起见,我只总结所有交易和CACQ。请记住,这会带来很多细微差别,例如区分被流失的客户和那些在一次购买和下一次购买之间处于休息状态的客户。
然后,我将把这个总和(我称之为net_value)与客户特定的功能结合起来。由于我的目标是在决定与他们互动之前确定哪个客户将有利可图,因此您只能在获取期之前使用数据。在我们的例子中,这些功能是年龄,地区和收入,所有这些都可以在另一个csv文件中找到。
profitable = (transactions[["customer_id"]]
.assign(net_value = transactions
.drop(columns="customer_id")
.sum(axis=1)))
customer_features = (pd.read_csv("data/customer_features.csv")
.merge(profitable, on="customer_id"))
customer_features.head()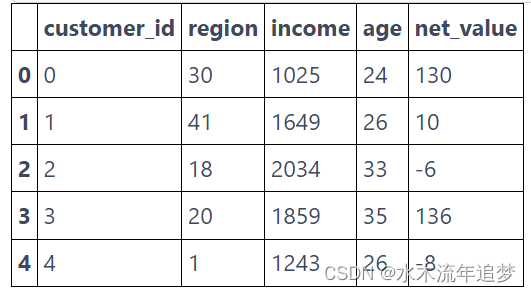
好!我们的任务正变得越来越不抽象。我们希望从非盈利客户中识别出有利可图的客户(net_value >0)。让我们尝试不同的东西,看看哪一个更好。但在此之前,我们需要快速了解一下机器学习(如果你知道ML是如何工作的,请随意跳过)

![[Vulnhub]Wintermute LFI+SMTP+Screen+Structv2-RCE+Lxc逃逸](https://img-blog.csdnimg.cn/img_convert/bf3d6720e0bea7eed12a223e4de60578.jpeg)