前言
自ChatGPT为代表的大语言模型(Large Language Model, LLM)出现以后,由于其惊人的类通用人工智能(AGI)的能力,掀起了新一轮[自然语言处理]领域的研究和应用的浪潮。尤其是以ChatGLM、LLaMA等平民玩家都能跑起来的较小规模的LLM开源之后,业界涌现了非常多基于LLM的二次微调或应用的案例。本项目旨在收集和梳理中文LLM相关的开源模型、应用、数据集及教程等资料,目前收录的资源已达100+个!
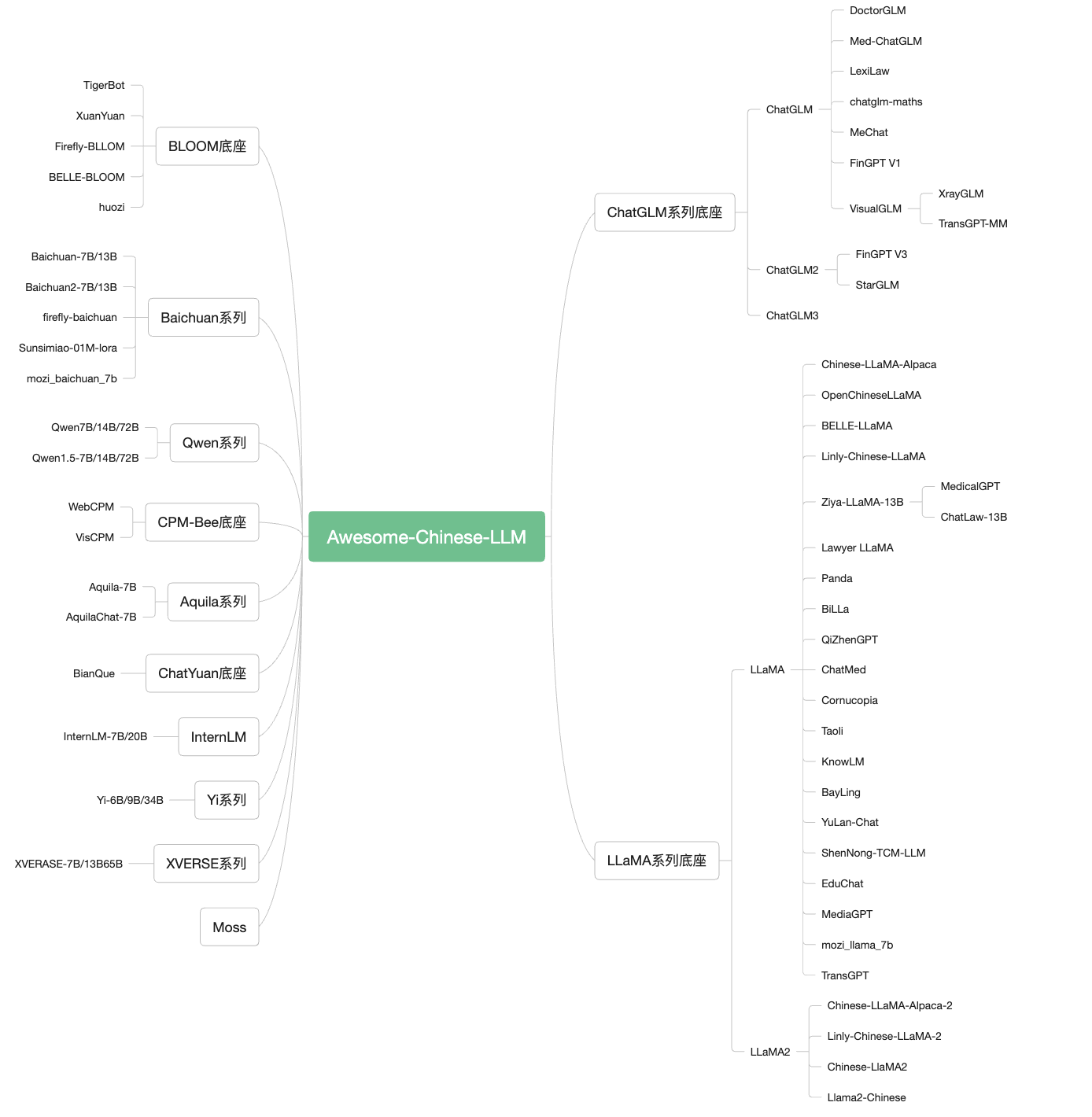
常见底座模型细节概览:
| 底座 | 包含模型 | 模型参数大小 | 训练token数 | 训练最大长度 | 是否可商用 |
|---|---|---|---|---|---|
| ChatGLM | ChatGLM/2/3 Base&Chat | 6B | 1T/1.4 | 2K/32K | 可商用 |
| LLaMA | LLaMA/2/3 Base&Chat | 7B/8B/13B/33B/70B | 1T/2T | 2k/4k | 部分可商用 |
| Baichuan | Baichuan/2 Base&Chat | 7B/13B | 1.2T/1.4T | 4k | 可商用 |
| Qwen | Qwen/1.5 Base&Chat | 7B/14B/72B/110B | 2.2T/3T | 8k/32k | 可商用 |
| BLOOM | BLOOM | 1B/7B/176B-MT | 1.5T | 2k | 可商用 |
| Aquila | Aquila/2 Base/Chat | 7B/34B | 2k | 可商用 | |
| InternLM | InternLM/2 Base/Chat/Code | 7B/20B | 200k | 可商用 | |
| Mixtral | Base&Chat | 8x7B | 32k | 可商用 | |
| Yi | Base&Chat | 6B/9B/34B | 3T | 200k | 可商用 |
| DeepSeek | Base&Chat | 1.3B/7B/33B/67B | 4k | 可商用 | |
| XVERSE | Base&Chat | 7B/13B/65B/A4.2B | 2.6T/3.2T | 8k/16k/256k | 可商用 |

一、大模型全套的学习路线
学习大型人工智能模型,如GPT-3、BERT或任何其他先进的神经网络模型,需要系统的方法和持续的努力。既然要系统的学习大模型,那么学习路线是必不可少的,下面的这份路线能帮助你快速梳理知识,形成自己的体系。
L1级别:AI大模型时代的华丽登场

L2级别:AI大模型API应用开发工程

L3级别:大模型应用架构进阶实践

L4级别:大模型微调与私有化部署

一般掌握到第四个级别,市场上大多数岗位都是可以胜任,但要还不是天花板,天花板级别要求更加严格,对于算法和实战是非常苛刻的。建议普通人掌握到L4级别即可。
以上的AI大模型学习路线,不知道为什么发出来就有点糊,高清版可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。