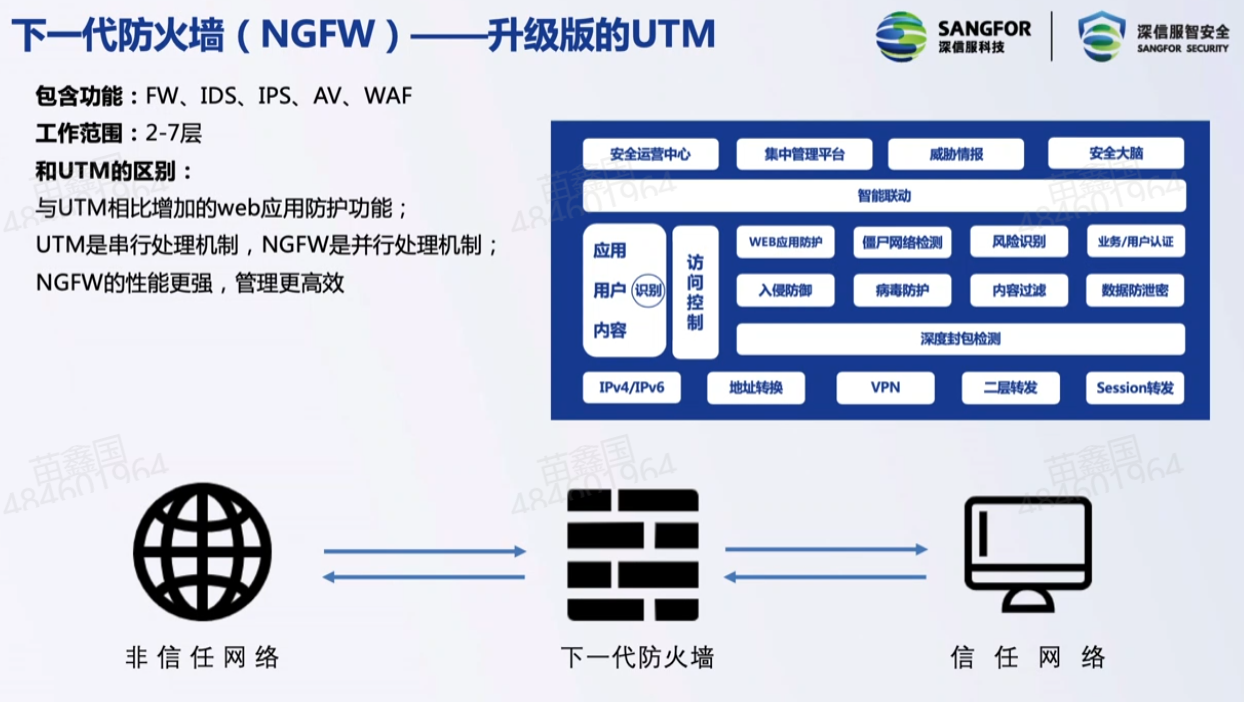
【摘要】文本到SQL旨在将自然语言问题转换为可执行的SQL语句,这对用户提问理解、数据库模式理解和SQL生成都是一个长期存在的挑战。传统的文本到SQL系统包括人工工程和深度神经网络。随后,预训练语言模型(PLMs)被开发并用于文本到SQL任务,取得了可喜的成绩。随着现代数据库变得更加复杂,相应的用户问题也更具挑战性,理解能力有限的PLMs可能会导致SQL生成不正确。这需要更复杂和定制的优化方法,反过来又限制了PLM系统的应用。最近,随着模型规模的不断增大,大语言模型(LLMs)在自然语言理解方面表现出显著的能力。因此,基于LLM的实现可以为文本到SQL研究带来独特的机遇、挑战和解决方案。在这篇综述中,我们全面回顾了基于LLM的文本到SQL。具体来说,我们提出了当前挑战和文本到SQL演进过程的简要概述。然后,我们详细介绍了为评估文本到SQL系统而设计的数据集和指标。之后,我们系统分析了基于LLM的文本到SQL的最新进展。最后,我们讨论了该领域仍面临的挑战,并对未来的方向提出了期望。
原文:Next-Generation Database Interfaces: A Survey of LLM-based Text-to-SQL
地址:https://arxiv.org/abs/2406.08426
代码:未知
出版:未知
机构: 暨南大学, 香港理工大学
1 研究问题
本文研究的核心问题是: 全面回顾基于大语言模型的文本到SQL任务的最新进展、面临的挑战以及未来的发展方向。
::: block-1
假设一个电商网站希望为其非技术用户提供一种自然语言查询报表数据的功能。用户可以用自然语言提问如"上个月销量最高的十款商品是什么?"系统需要能将这个问题转换成对应的SQL语句去查询后台的销售数据库。这里涉及了对自然语言问题的理解、数据库模式的理解以及正确SQL的生成。传统方法往往需要大量人工设计的规则和特征工程,而最新的基于大语言模型的方法有望简化这一过程,但仍面临诸多挑战有待进一步研究。
:::
本文研究问题的特点和现有方法面临的挑战主要体现在以下几个方面:
- 自然语言问题往往包含复杂的语言结构,如嵌套从句、共指和省略等,很难准确映射到SQL查询上。此外,自然语言本身就存在歧义,一个问题可能有多种解读。消除歧义需要深入的语言理解能力以及融入上下文和领域知识。
- 要生成正确的SQL查询,文本到SQL系统需要全面理解数据库模式,包括表名、列名以及表之间的关系。但不同领域的数据库模式差异很大。如何以一种能被文本到SQL模型有效利用的方式来表示和编码数据库模式信息是一个挑战。
- 一些SQL查询涉及罕见或复杂的操作,如嵌套子查询、外连接和窗口函数等。这些操作在训练数据中出现频率低,给文本到SQL模型的准确生成带来挑战。
- 文本到SQL模型往往难以跨不同数据库模式和领域泛化。在一个特定领域上训练的模型,由于词汇、模式结构和问题模式的差异,可能很难在另一个领域的问题上表现良好。如何开发能够以最少的微调或特定领域训练数据,就能有效适应新领域的模型,是一个持续的挑战。
针对这些挑战,本文全面回顾了将大语言模型应用于文本到SQL任务的最新进展:
::: block-1
与预训练语言模型相比,大语言模型具有更强大的语义解析能力,这得益于其在更大规模语料上的训练。最新的研究聚焦于如何进一步增强大语言模型在文本到SQL任务中的表现,主要探索了以下几个方向:
一是优化输入到大语言模型的提示,引导其更好地理解用户意图。这包括精心设计少样本示例、融入外部知识、对输入进行归纳和分解等。
二是改进大语言模型生成SQL的推理过程。研究者尝试了思维链、最小到最大prompting等策略,将复杂问题分解成步骤化的子问题,减少信息丢失,同时引入一致性检验避免逻辑谬误。
三是利用数据库反馈来提炼SQL。通过将生成的SQL在实际数据库中执行,获得准确性反馈,并将其再输入给语言模型修正SQL,形成闭环学习。
此外,本文还梳理了文本到SQL常用的评测数据集、指标体系以及不同研究范式,为后续研究提供参考。尽管基于大语言模型的方法取得了显著进展,但在鲁棒性、计算效率等方面依然面临诸多挑战,需要学界进一步攻关。
:::
2 方法综述

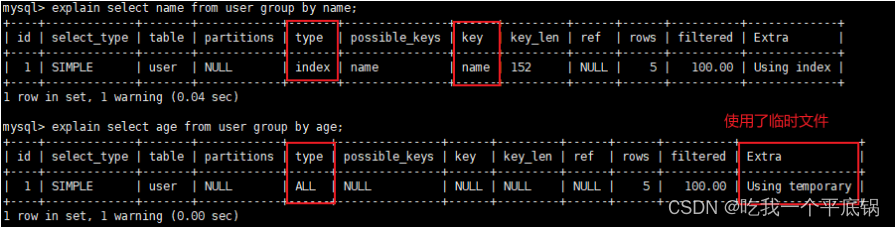
2.1 基于上下文学习的Text-to-SQL方法

基于上下文学习(In-context Learning)的Text-to-SQL方法利用大语言模型强大的少样本学习能力,通过设计提示(prompt)使模型直接生成SQL,而无需微调模型参数。本文将这类方法进一步细分为以下5类:
2.1.1 平凡提示
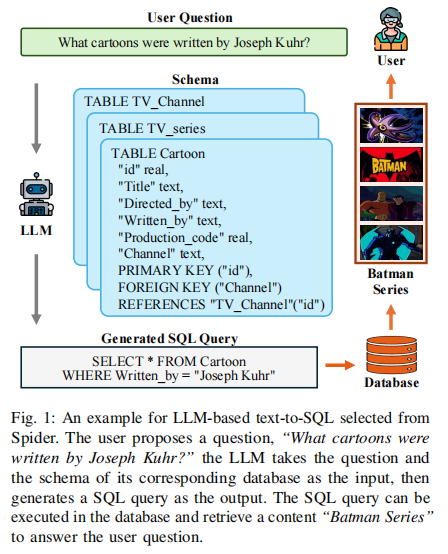
平凡提示是指直接使用问题和数据库schema作为提示,让语言模型直接生成SQL。举个例子,对于问题"What cartoons were written by Joseph Kuhr?",平凡的零样本提示可以是:
问题:What cartoons were written by Joseph Kuhr?
数据库Schema:
TABLE Cartoon
"id" real,
"Title" text,
"Directed_by" text,
"Written_by" text,
"Production_code" real,
"Channel" text,
PRIMARY KEY ("id"),
FOREIGN KEY ("Channel")
REFERENCES "TV_Channel"("id")
SQL:
语言模型会直接根据这个提示生成对应的SQL。平凡的少样本提示则是在此基础上添加一些示例,如:
问题1:What is the name of cartoon with id 2?
SQL1:SELECT Title FROM Cartoon WHERE id = 2
问题2:What cartoons were written by Joseph Kuhr?
数据库Schema:
TABLE Cartoon
"id" real,
"Title" text,
"Directed_by" text,
"Written_by" text,
"Production_code" real,
"Channel" text,
PRIMARY KEY ("id"),
FOREIGN KEY ("Channel")
REFERENCES "TV_Channel"("id")
SQL2:
2.1.2 分解
分解方法通过将Text-to-SQL任务分解为多个子任务或步骤,降低任务复杂度。这就好比将一个复杂的数学题分解为多个简单的小问题。具体来说,分解方法可以分为子任务分解和子问题分解。子任务分解会将Text-to-SQL分解为模式连接(schema linking)、分类、SQL生成等子任务。而子问题分解则是将用户问题分解为多个子问题,然后分别生成对应的SQL子句再组合。举个例子,DIN-SQL就是一个多步骤的分解方法,包括模式连接、分类与问题分解、SQL生成和自我纠错4个步骤。
2.1.3 提示优化
提示优化旨在构造更高质量的少样本示例,从而提升模型性能。其关键在于示例的选择策略。直觉上,选择与当前问题更相似或更有代表性的示例作为提示,可以让模型更好地理解任务。常见的优化方法包括:基于相似度的采样、模式增强、外部知识等。以DAIL-SQL为例,其先对问题中的领域特定词进行掩码,然后基于嵌入式欧氏距离对候选示例进行排序,同时还考虑了候选SQL的相似度,最终选择兼顾问题和SQL相似度的高质量示例。
2.1.4 推理增强
大语言模型具有一定的推理能力,推理增强方法旨在进一步提升模型在Text-to-SQL任务中的推理和逻辑能力。代表性的方法包括思维链(Chain-of-Thoughts)和最小优先(Least-to-Most)提示等。具体来说,思维链提示引导模型进行逐步推理,将推理过程外显化。而最小优先提示则是先将问题分解为子问题,然后逐步求解。ACT-SQL在思维链提示的基础上,提出了一种自动构造思维链的方法,通过将问题切片与SQL中出现的列进行匹配,形成推理步骤。
2.1.5 执行细化
执行细化方法利用SQL执行反馈来提升模型生成的准确性。其基本思路是:先让模型生成候选SQL,然后在数据库中执行,根据执行结果(如报错信息)来提示模型纠错和细化生成的SQL。这种方法让模型充分利用了数据库反馈的信号。以DIN-SQL为例,其自我纠错模块就是让模型根据数据库反馈迭代优化生成的SQL。类似地,SQL-CRAFT引入了交互式纠错机制,通过自动化控制避免过度纠错或纠错不足的问题。
2.2 基于微调的Text-to-SQL方法
与基于上下文学习的方法不同,基于微调的方法通过在Text-to-SQL数据集上微调预训练语言模型的参数,让模型习得从自然语言问题生成SQL的能力。根据微调框架的不同,可以分为以下4类:
2.2.1 增强架构
增强架构方法对语言模型的架构进行了调整和优化,以提升Text-to-SQL任务的性能。常见的优化包括引入编码器-解码器结构、图神经网络等。以CL-LMs为例,其提出了一种压缩优化的语言模型变体,在不影响性能的情况下大幅提升了SQL生成速度。
2.2.2 数据增强
数据增强通过构造更多的训练数据,来提升模型的微调效果。这些数据既可以通过人工标注,也可以通过半自动化方式生成。DAIL-SQL利用其少样本采样策略,将采样得到的高质量示例也用于微调阶段的训练,最终提升了开源模型的性能。Symbol-LLM则是先将数据转化为抽象的符号形式,然后在符号层面进行数据增强。
2.2.3 预训练
针对Text-to-SQL任务的预训练方法旨在让模型更好地习得从自然语言到SQL的映射关系。相比通用的语言模型预训练,这类方法会在预训练阶段加入更多SQL相关的数据和任务。如CodeS模型的预训练过程分为3个阶段,其数据集既包括通用的语料,也包括SQL和代码相关的语料,从而让模型更好地适配Text-to-SQL任务。
2.2.4 分解
与上下文学习范式下的分解类似,基于微调的分解方法也是将Text-to-SQL任务拆解为多个步骤或子任务。区别在于,这里每个子任务都需要对应的训练数据对模型进行微调,而不是直接用提示生成。DTS-SQL就是一个典型的两阶段微调方法,先在模式连接数据上微调模型,然后再在Text-to-SQL数据上微调得到最终的SQL生成模型。
综上,本文系统全面地介绍了基于大语言模型的Text-to-SQL方法。这些方法充分利用了大语言模型强大的自然语言理解和生成能力,并针对Text-to-SQL任务的特点进行了优化,为构建自然语言数据库接口提供了新的思路。未来进一步提升性能的关键在于优化提示、增强推理、引入更多结构信息等,也需要在更真实的场景中评估模型的鲁棒性和实用性。
3 实验梳理
3.1 实验场景介绍
本文是一篇关于大语言模型(LLM)在text-to-SQL任务中应用的综述,没有进行具体的实验。文章主要对现有数据集、评估指标以及方法进行了梳理和总结。
3.2 实验设置
- Datasets:文章介绍了多个主流的text-to-SQL数据集,包括Spider、WikiSQL、CoSQL等,并总结了它们的规模、特点等统计信息(见表I)。
- Evaluation Metrics:介绍了常用的text-to-SQL任务评估指标,分为基于SQL内容匹配的指标(如Exact Matching)和基于执行结果的指标(如Execution Accuracy)。
- Methods:将现有工作分为in-context learning(提示工程)和fine-tuning两大范式,并在此基础上对各类方法进行了分类总结。
3.3 实验结果
3.3.1 实验一、主流text-to-SQL数据集统计分析
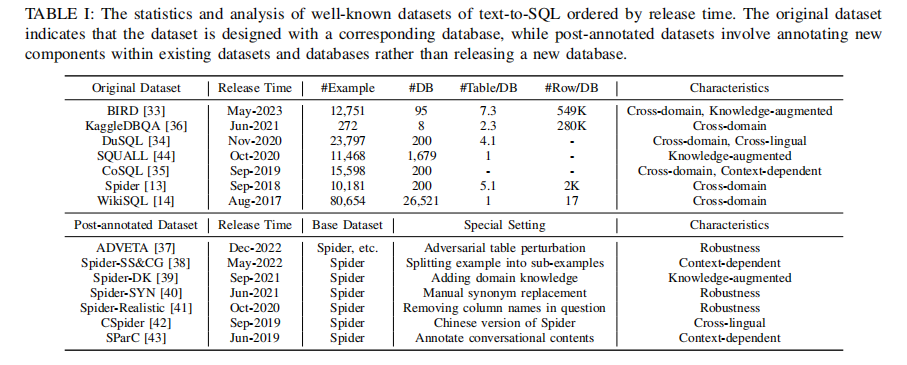
目的:分析现有text-to-SQL数据集的规模、领域、特点等
涉及图表:表I
实验细节概述:将数据集分为原始数据集和二次标注数据集两类,并从领域、语言、鲁棒性等维度进行了特点总结
结果:目前已有Spider、WikiSQL等多个跨领域大规模数据集,但在知识融合、多语言、鲁棒性等方面仍有待进一步扩展
3.3.2 实验二、in-context learning范式下方法总结
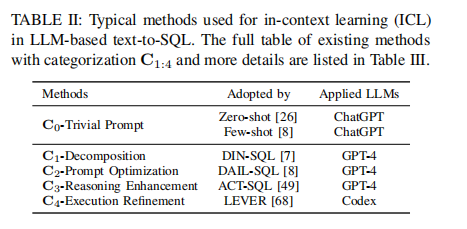
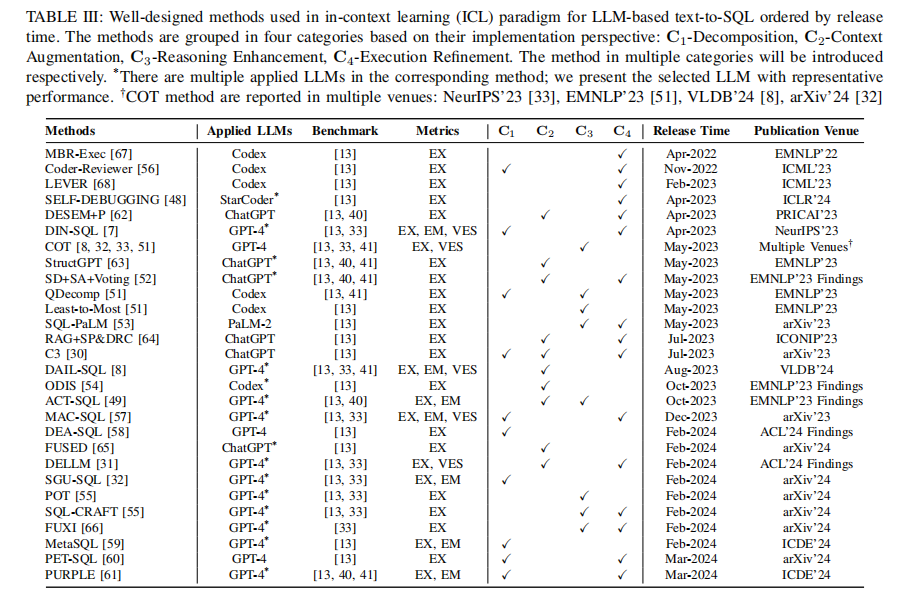
目的:梳理目前将LLM用于text-to-SQL任务的主要方法(提示工程范式)
涉及图表:表II、表III
实验细节概述:将现有工作分为trivial prompt、decomposition、prompt optimization、reasoning enhancement、execution refinement五类
结果:提示工程是当前主流做法,通过对prompt进行优化可以进一步提升LLM在text-to-SQL任务上的表现,但推理能力和执行反馈的融合仍是难点
3.3.3 实验三、fine-tuning范式下方法总结
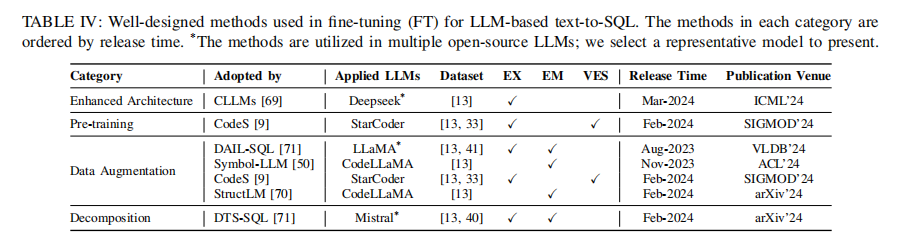
目的:梳理目前通过fine-tuning将LLM应用于text-to-SQL任务的主要方法
涉及图表:表IV
实验细节概述:包括对模型架构的改进、数据增强、任务分解等方法
结果:fine-tuning开源LLM在text-to-SQL任务上的效果普遍不如提示工程范式,提高训练效率是关键
4 总结后记
本论文针对自然语言问题转化为结构化SQL查询(Text-to-SQL)的任务,系统梳理了基于大语言模型(LLM)的Text-to-SQL方法。论文首先介绍了Text-to-SQL的研究背景、面临的挑战以及技术路线的演进过程,然后详细总结了Text-to-SQL的常用数据集、评估指标以及基于LLM的具体方法。其中,方法部分分为in-context learning和fine-tuning两大类范式,每一类又细分多个具体技术角度。最后,论文展望了未来研究方向,包括真实场景的鲁棒性、计算效率、数据隐私、可解释性等。