1.ANR
Application Not Responding,即应用程序未响应。Android系统要求一些事件在一定时间范围内完成,如果超过预定时间未得到有效响应或响应时间过长,就会造成ANR。
Android中有4种ANR发生场景:
①点击事件(按键和触摸事件):点击事件在5s内未被处理就会产生ANR,日志描述为Input event dispatching timed out。
②服务Service: 前台Service20s内、后台Service 200s内未完成启动就会产生ANR,日志描述为Timeout executing service。
③广播BroadcastReceiver:前台广播10s内、后台广播60s内,如果onReceive()在规定时间内没处理完就会产生ANR,日志描述为Timeout of broadcast Broadcast Record。
注意,前台广播的ANR时间是10s内onReceive()没有执行完就提示,这是在没有点击触摸事件导致ANR的前提下才是10s,否则会先触发点击事件的ANR,onReceive()有可能执行不到10s就发生 ANR,所以不要在onReceive()处理耗时操作。
④内容提供者ContentProvider:publish在10s内没处理完就会产生ANR,日志描述为Timeout publishing content providers。
ANR产生需要同时满足三个条件:
①主线程:只有应用程序的主线程响应超时才会产生ANR;
②超时时间:产生ANR的上下文不同,超时时间也会不同,但只要在这个时间上限内没有响应就会ANR;
③输入事件/特定操作:输入事件指按键、触屏等设备输入事件,特定操作指BroadcastReceiver和Service的生命周期中的各个函数,产生ANR的上下文不同,导致ANR的原因也会不同。
在实际项目中,大多数ANR都是点击触摸事件超时导致,超时的原因主要有以下三个:
①数据导致的ANR:频繁GC导致线程暂停,处理事件时间被拉长;
②线程阻塞或死锁导致ANR;
③Binder导致ANR:Binder通信数据量过大;
所以想要知道ANR的原因,就必须清楚它的原理,且知道有多少情况会导致出现事件被拉长的问题。
注:为了避免ANR,耗时操作要放在子线程中,防止耗时操作阻塞主线程。为了降低因网络访问导致的ANR,在Android4.0之后强制规定访问网络必须在子线程,否则将会抛出NetworkOnMainThreadException。
2.ANR触发原理
触发ANR的过程可分为三个步骤: 埋炸弹、拆炸弹、引爆炸弹。埋炸弹可以理解为发送了一个延迟触发的消息(炸弹);拆炸弹可以理解为将这个延迟消息(炸弹)取消了,也就不会触发了;引爆炸弹可以理解为延迟时间已达,开始处理延迟消息(炸弹引爆了)。
其实说到本质上,系统内部对于ANR的触发流程很简单,ANR也是建立在主线程Looper机制上的,就是先发送一个延时消息,然后在特定位置移除这个消息,如果消息没有被移除则证明整个流程出现问题,就会执行ANR处理。
以Service触发ANR为例看一下触发流程。
先附上一张service启动流程图:
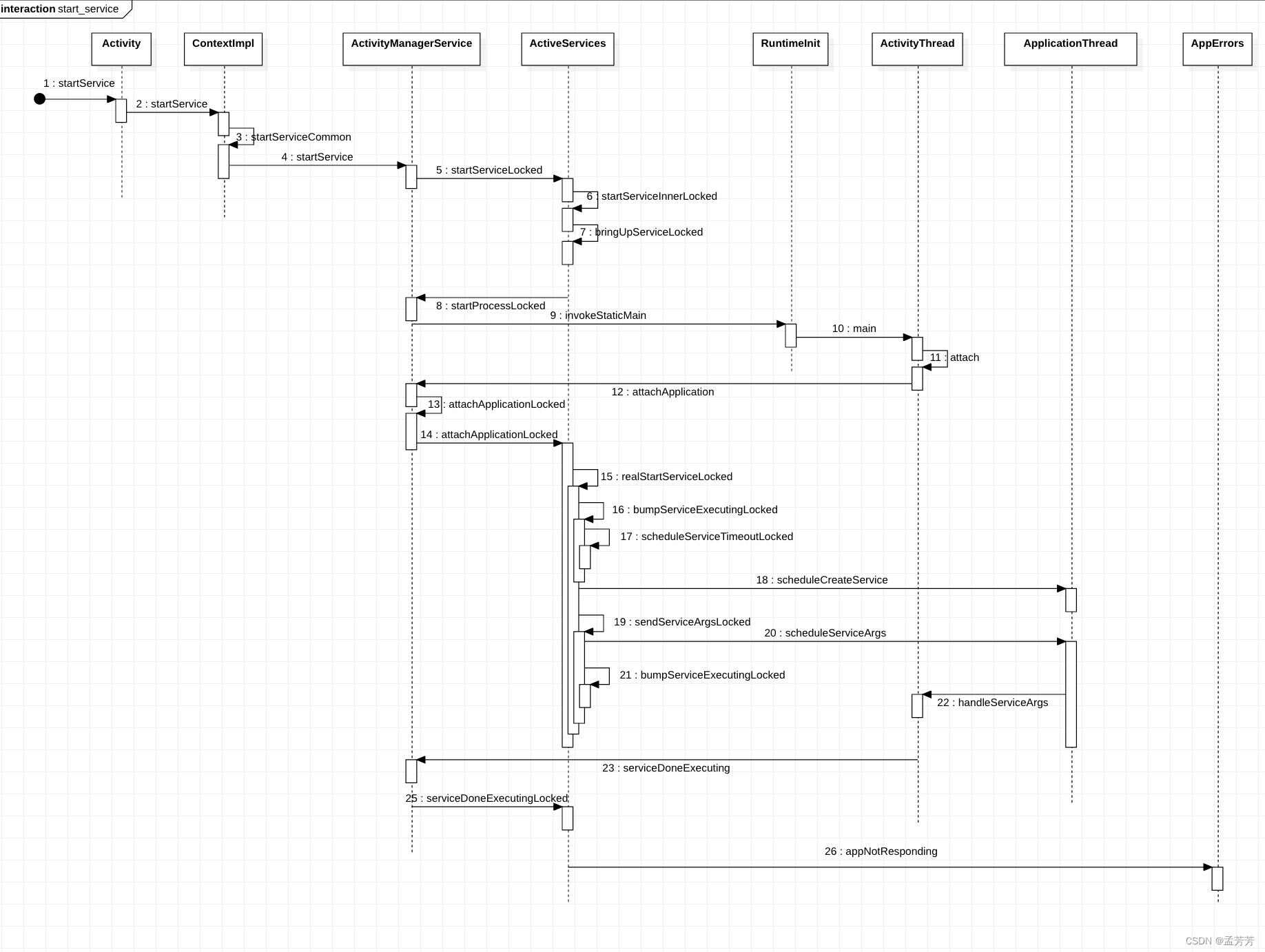
Service Timeout是位于ActivityManager线程中的AMS.MainHandler收到SERVICE_TIMEOUT_MSG消息时触发。
Service有两类:前台服务超时为SERVICE_TIMEOUT = 20s;后台服务超时为SERVICE_BACKGROUND_TIMEOUT = 200s。
由变量ProcessRecord.execServicesFg来决定是否前台启动。
1)第一步:埋炸弹
在Service进程attach到system_server进程的过程中会调用realStartServiceLocked()方法来埋下炸弹。
ActiveServices.java:
private final void realStartServiceLocked( ServiceRecord r, ProcessRecord app, boolean execInFg) {
...
bumpServiceExecutingLocked(r, execInFg, "create"); //发送delay消息
...
//最终执行服务的onCreate()方法
app.thread.scheduleCreateService(r, r.serviceInfo, mAm.compatibilityInfoForPackageLocked(r.serviceInfo.applicationInfo), app.repProcState);
}
private final void bumpServiceExecutingLocked( ServiceRecord r, boolean fg, String why) {
...
scheduleServiceTimeoutLocked(r.app);
}
void scheduleServiceTimeoutLocked( ProcessRecord proc) {
long now = SystemClock.uptimeMillis();
Message msg = mAm.mHandler.obtainMessage(ActivityManagerService.SERVICE_TIMEOUT_MSG);
msg.obj = proc;
//当超时后仍没有remove该SERVICE_TIMEOUT_MSG消息,则执行service Timeout流程
mAm.mHandler.sendMessageAtTime(msg, proc.execServicesFg ? (now+SERVICE_TIMEOUT) : (now+ SERVICE_BACKGROUND_TIMEOUT));
}
在ActiveServices类中的realStartServiceLocked方法中启动service时,发送了一个延时的关于超时的消息,这里又对service进行了前后台的区分:
static final int SERVICE_TIMEOUT = 20*1000;
static final int SERVICE_BACKGROUND_TIMEOUT = SERVICE_TIMEOUT * 10;
2)第二步:拆炸弹
ActiveServices.realStartServiceLocked()调用的过程会埋下一颗炸弹,超时没有启动完成则会爆炸。那什么时候会拆除这颗炸弹的引线呢?
经过Binder等层层调用会进入目标进程的主线程handleCreateService()方法:
ActivityThread java:
private void handleCreateService( CreateServiceData data) {
...
java.lang.ClassLoader cl = packageInfo.getClassLoader();
Service service = (Service) cl.loadClass(data.info.name).newInstance();
...
ContextImpl context = ContextImpl.createAppContext(this, packageInfo); //创建ContextImpl对象
context.setOuterContext(service);
Application app = packageInfo.makeApplication(false, mInstrumentation);//创建Application对象
service.attach(context, this, data.info.name, data.token, app, ActivityManagerNative.getDefault());
service.onCreate(); //调用服务onCreate()方法
ActivityManagerNative.getDefault().serviceDo neExecuting(data.token, SERVICE_DONE_EXECUTING_ANON, 0, 0);
}
在这个过程中会创建目标服务对象,并回调 onCreate()方法,onCreate()成功后就会调用到system_server来执行serviceDoneExecuting()方法:
ActiveServices.java:
private void serviceDoneExecutingLocked( ServiceRecord r, boolean inDestroying, boolean finishing) {
...
if (r.executeNesting <= 0) {
if (r.app != null) {
r.app.execServicesFg = false;
r.app.executingServices.remove(r);
if (r.app.executingServices.size() == 0) {
//当前服务所在进程中没有正在执行的service
mAm.mHandler.removeMessages( ActivityManagerService.SERVICE_TIMEOUT_MSG, r.app);
...
}
...
}
该方法会在service启动完成后移除服务超时消息 SERVICE_TIMEOUT_MSG,时间是20s。
3)第三步:引爆炸弹
如果在炸弹倒计时结束之前成功拆卸炸弹就没有爆炸的机会,否则在一些极端情况下无法即时拆除炸弹,就会导致炸弹爆炸,其结果就是App发生ANR。
在system_server进程中有一个Handler线程,当倒计时结束便会向该Handler线程发送一条信息SERVICE_TIMEOUT_MSG:
ActivityManagerService.java:
final class MainHandler extends Handler {
public MainHandler(Looper looper) {
super(looper, null, true);
}
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case SERVICE_TIMEOUT_MSG:
mServices.serviceTimeout( (ProcessRecord)msg.obj);
break;
}
}
当延时时间到了之后,就会对消息进行处理,下面看具体处理逻辑:
void serviceTimeout(ProcessRecord proc) {
String anrMessage = null;
synchronized(mAm) {
final long now = SystemClock.uptimeMillis();
final long maxTime = now -(proc.execServicesFg ? SERVICE_TIMEOUT : SERVICE_BACKGROUND_TIMEOUT);
ServiceRecord timeout = null;
long nextTime = 0;
for (int i=proc.executingServices.size()-1; i>=0; i--) {
ServiceRecord sr = proc.executingServices.valueAt(i); //从进程里获取正在运行的service
if (sr.executingStart < maxTime) {
timeout = sr;
break;
}
if (sr.executingStart > nextTime) {
nextTime = sr.executingStart;
}
}
if (timeout != null && mAm.mLruProcesses.contains(proc)) {
Slog.w(TAG, "Timeout executing service: " + timeout);
StringWriter sw = new StringWriter();
PrintWriter pw = new FastPrintWriter(sw, false, 1024);
pw.println(timeout);
timeout.dump(pw, " ");
pw.close();
mLastAnrDump = sw.toString();
mAm.mHandler.removeCallbacks( mLastAnrDumpClearer);
mAm.mHandler.postDelayed( mLastAnrDumpClearer, LAST_ANR_LIFETIME_DURATION_MSECS);
anrMessage = "executing service " + timeout.shortName;
}
}
if (anrMessage != null) {
mAm.appNotResponding(proc, null, null, false, anrMessage); //当存在timeout的service,则执行appNotResponding
}
}
其中anrMessage的内容为:executing service [发送超时serviceRecord信息]。
3.分析ANR日志
发生ANR时系统会在/data/anr/目录下额外生成一份traces.txt日志,通过它可以了解发生ANR时的基本信息和堆栈信息。
traces.txt日志信息如下(以主线程为例):
//main标识主线程,Native是线程状态,再下面是堆栈信息
"main" prio=5 tid=1 Native
| group="main" sCount=1 dsCount=0 obj=0x73cff4c0 self=0xafa84400
| sysTid=5790 nice=0 cgrp=top-app sched=1073741825/1 handle=0xb2717534
| state=S schedstat=( 3240607247 80660807 2053 ) utm=283 stm=41 core=1 HZ=100
| stack=0xbe7c1000-0xbe7c3000 stackSize=8MB
| held mutexes=
kernel: (couldn't read /proc/self/task/5790/stack)
……
main:标识是主线程。在traces.txt中如果是子线程会命名为 “thread-x” 的格式,x表示线程id,逐步递增。
prio:线程优先级,默认是5。
tid:不是线程的id,是线程唯一标识id。
group:线程组名称。
sCount:该线程被挂起的次数。
dsCount:线程被调试器挂起的次数。
obj:对象地址。
self:该线程native的地址。
sysTid:线程号(主线程的线程号和进程号相同)
nice:线程的调度优先级。
sched:分别标志了线程的调度策略和优先级。
cgrp:调度归属组。
handle:线程处理函数的地址。
state:调度状态。
schedstat:从/proc/[pid]/task/[tid]/schedstat读出,三个值分别表示线程在cpu上执行的时间、线程的等待时间和线程执行的时间片长度,不支持这项信息的三个值都是0。
utm:线程用户态下使用的时间值(单位是 jiffies)
stm:内核态下的调度时间值。
core:最后执行这个线程的cpu核的序号
其中,线程状态又可以分为几种情况:
①UNDEFINED = -1
②ZOMBIE = 0:TERMINATED,表示线程已经终止。
③RUNNING = 1:RUNNABLE or running now,表示正常运行
④TIMED_WAIT = 2:TIMED_WAITING Object.wait(), 表示等待,一般是调用 Object.wait(2000)
⑤MONITOR = 3:BLOCKED on a monitor, 表示synchronized
⑥WAIT = 4:WAITING in Object.wait(),表示调用Object.wait()或LockSupport.park()等待。
⑦INITIALIZING = 5:allocated, not yet running,表示已经初始化线程,但是还没有进行start。
⑧STARTING = 6:started, not yet on thread list,表示已经start但是没有run。
⑨NATIVE = 7:off in a JNI native method,表示native线程出问题,有三种常见情况:
1)项目自己有JNI开发线程
2)有IO操作(IO的本质是调用Linux内核的函数)
3)AQS锁住了
⑩VMWAIT = 8:waiting on a VM resource,表示没有时间片
⑩SUSPENDED = 9:suspended,usually by GC or debugger,被GC挂起的(该情况发生的可能性不高)
⑩Blocked:表示死锁(查看CPU usage会发现几乎都是 0%,这也是死锁的体现)
其中线程状态和堆栈信息是最关键的,它能够帮助快速定位到具体位置(堆栈信息有我们应用的函数调用的话)。
4.ANR日志分析思路
ANR日志分析思路可以分为四个步骤:
①ANR日志准备(traces.txt + mainlog)
②在traces.txt中找到ANR信息(发生ANR时间节点、主线程状态、事故点、ANR类型)
③在mainlog日志中分析发生ANR时的CPU状态
④在traces.txt中分析发生ANR时的GC情况(分析内存)
下面分别详细看一下:
第一步:ANR日志准备(traces.txt + mainlog)
发生ANR时系统会收集ANR相关的信息,包括:
①发生ANR时会收集trace信息,能找到各个线程的执行情况和GC信息,trace文件保存在/data/anr/traces.txt。
②在mainlog日志中有ANR相关的信息和发生ANR时的CPU使用情况
也就是说分析ANR问题至少需要两份文件:/data/anr/traces.txt 和mainlog日志。如果有eventlog能更快的定位到ANR的类型,当然traces.txt和mainlog也能分析得到。
其中,traces.txt文件通过命令adb pull /data/anr/ 获取。mainlog日志需要在程序运行时就时刻记录 adb logcat -v time -b main > mainlog.log。
第二步:在traces.txt找到ANR信息
在traces.txt文件中主要找四个信息:发生ANR的时间节点、主线程状态(在文件中搜索 main)、ANR类型、事故点(堆栈信息中找到我们应用中的函数)。
分析发生ANR时进程中各个线程的堆栈,一般有几种情况:
①主线程状态是Runnable或Native,堆栈信息中有我们应用中的函数,则很有可能就是执行该函数时候发生了超时。
②主线程状态是Block,非常明显的线程被锁,这时候可以看是被哪个线程锁了,可以考虑优化代码,如果是死锁问题,就更需要及时解决了。
③由于抓trace的时刻很有可能耗时操作已经执行完了(ANR -> 耗时操作执行完毕 -> 系统抓 trace),这时候的trace就没有什么用了(在堆栈信息找不到我们应用的函数调用)。
举个例子:
/data/anr/traces.txt文件如下:
// 发生 ANR 时的时间节点
----- pid 5790 at 2022-05-23 10:21:32 -----
// 主线程状态
"main" prio=5 tid=1 Waiting
// 事故点(不一定能找到我们应用的调用函数,因为抓trace的时候耗时操作可能已经执行完了,例如下面的堆栈)
at android.os.BinderProxy.transactNative(Native method)
at android.os.BinderProxy.transact(Binder.java:930)
at android.view.IWindowSession$Stub$Proxy.remove(IWindowSession.java:924)
……
从上面的堆栈中不能分析到ANR类型,所以可以再借助eventlog或mainlog日志找到,可以在mainlog日志里搜索关键词ANR in:
mainlog.log文件(对应的 adb logcat -v time -b main > mainlog.log)如下:
05-23 10:21:38.029 2003 2016 E ActivityManager: ANR in com.example.demo (com.example.demo/.ui.login.LoginActivity)
05-23 10:21:38.029 2003 2016 E ActivityManager: PID: 5790
05-23 10:21:38.029 2003 2016 E ActivityManager: PSS: 42718 kB
05-23 10:21:38.029 2003 2016 E ActivityManager: Reason: Input dispatching timed out (Waiting to send key event because the focused window has not finished processing all of the input events that were previously delivered to it. Outbound queue length: 0. Wait queue length: 1.)
在eventlog日志里搜索关键词am_anr:
05-23 10:20:29.166 2003 2016 I am_anr : [0,3392,com.example.demo,955792964,Input dispatching timed out (Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)]
第三步:在mainlog日志中分析发生ANR时的CPU状态
在mainlog日志中根据ANR时间节点并搜索关键词CPU usage查看发生ANR前后CPU的使用情况,从CPU usage信息中大概可以分析:
①如果某些进程的CPU占用百分比较高,几乎占用了所有CPU资源,而发生ANR的进程(一般说的是我们的app进程)CPU占用为0%或非常低,则认为CPU资源被占用,app进程没有被分配足够的资源,从而发生了ANR。这种情况多数可以认为是系统状态的问题,并不是由应用造成的(也就是其他进程CPU使用率非常高自己低,就是系统资源分配不足导致)。
②如果发生ANR的进程(一般说的是我们的app进程)CPU占用较高,比如到了80%或90%以上,则可以怀疑应用内一些代码不合理消耗掉了CPU资源,可能出现了死循环或后台有许多线程执行任务等原因,这时就要结合traces.txt和ANR前后的mainlog日志进一步分析(简单理解就是IO非常频繁,要么死循环了,要么上锁了)。
③如果CPU总用量不高,该进程和其他进程的占用过高,这有一定概率是由于某些主线程的操作耗时过长,或者是由于主进程被锁造成的。
发生死锁时的CPU状态如下:

第四步:在traces.txt中分析发生ANR时的GC情况(分析内存)
当上面分析了CPU状态后发现是非CPU问题时,就需要从内存GC分析了,因为GC会触发STW(Stop The World)导致线程执行时间被拉长。
// 这里只截取了一部分GC信息,如果还有其他信息,还需要分析如GC回收率等,下面的GC信息是正常的
Total time waiting for GC to complete: 64.298ms
Total GC count: 30
Total GC time: 4.961s
Total blocking GC count: 1
Total blocking GC time: 149.286ms
综上,其实ANR问题主要就是两类问题:CPU问题和GC问题。所以定位ANR总的来说就是:
①判定是否为CPU问题:常见的是在主线程事件发生。
②如果非CPU问题,再去定位GC问题。GC问题直接去看traces.txt上面的GC信息。常规GC导致的问题,就是有频繁的对象创建。常规少量数据不会出现这个问题,但是数据量异常将会引发连锁反应,ANR是结果的体现,具体体现是卡顿和内存泄漏。
5.ANR案例分析
1)案例一:
日志文件:eventlog、traces.txt、mainlog。
①查看eventlog日志搜索关键词am_anr,找到出现ANR的时间节点、进程pid、ANR类型。
07-20 15:36:36.472 1000 1520 1597 I am_anr :[0, 1480,com.xxxx.mobile,952680005,Input dispatching timed out(AppWindowToken{da8f666 token=Token{5501f51 ActivityRecord{15c5c78 u0 com.xxxx.mobile/.ui.MainActivity t3862}}}, Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)]
从log可以看出,应用com.xxxx.mobile在07-20 15:36:36.472发生了KeyDispatchTimeout类型的ANR,它的进程号是1480。
把关键信息梳理一下:
ANR时间节点:07-20 15:36:36.472
进程pid:1480
进程名:com.xxxx.mobile
ANR类型:KeyDispatchTimeout
②查看mainlog日志,分析发生ANR之前做了什么事情。
发生KeyDispatchTimeout的ANR是因为input事件在5s内没有处理完成。那在时间07-20 15:36:36.472的前5s也就是15:36:30~15:36:31时间段左右程序到底做了什么事情?既然已经知道 pid,从mainlog再搜索下pid=1480的日志找到该进程所运行的轨迹:
07-20 15:36:29.749 10102 1480 1737 D mobile-Application:[Thread:17329] receive an intent from server, action=com.ttt.push.RECEIVE_MESSAGE
07-20 15:36:30.136 10102 1480 1737 D mobile-Application:receiving an empty message, drop
07-20 15:36:35.791 10102 1480 1766 I Adreno :QUALCOMM build :9c9b012, I92eb381bc9
07-20 15:36:35.791 10102 1480 1766 I Adreno :Build Date :12/31/17
从这里可以知道,在时间07-20 15:36:29.749程序收到了一个action消息:
07-20 15:36:29.749 10102 1480 1737 D mobile-Application:[Thread:17329] receive an intent from server, action=com.ttt.push.RECEIVE_MESSAGE
应用com.xxxx.mobile收到了一个推送消息com.ttt.push.RECEIVE_MESSAGE导致了阻塞。
现在再串联一下目前所获取到的信息:在时间 07-20 15:36:29.749应用com.xxxx.mobile收到了一个推送消息action=com.ttt.push.RECEIVE_MESSAGE发生阻塞,5s后发生了KeyDispachTimeout的ANR。
③查看mainlog日志分析CPU状态
虽然知道了从什么时候开始ANR的,但是具体原因还没有找到,是不是当时CPU很紧张、各路app在抢占资源?所以从mainlog继续分析CPU信息。搜索关键词ANR in:
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: ANR in com.xxxx.mobile(com.xxxx.mobile/.ui.MainActivity)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: PID: 1480
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Reason: Input dispatching timed out(AppWindowToken{da8f666 token=Token{5501f51 ActivityRecord{15c5c78 u0 com.xxxx.mobile/.ui.MainActivity t3862}}}, Waiting because no window has focus but there is a focused application that may eventually add a window when it finishes starting up.)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Load: 0.0 / 0.0 / 0.0
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: CPU usage from 20ms to 20286ms later(2018-07-20 15:36:36.120 to 2018-07-20 15:36:56.426)
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 42% 6774/pressure: 41% user + 1.4% kernal / faults: 168 minor
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 34% 142/kswapd0: 0% user + 34% kernal
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 31% 1520/system_server: 13% user + 18% kernal / faults: 58724 minor 1585 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 13% 29901/com.ss.android.article.news: 7.7% user + 6% kernal / faults: 48999 minor 1540 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 11% 1480/com.xxxx.mobile: 5.2% user + 6.3% kernal / faults: 76401 minor 2422 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 8.2% 21000/kworker/u16:12: 0% user + 8.2% kernal
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 0.8% 724/mtd: 0% user + 0.8% kernal / faults: 1561 minor 9 major
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 8% 29704/kworker/u16:8: 0% user + 8% kernal
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.9% 24391/kworker/u16:18: 0% user + 7.9% kernal
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.1% 30656/kworker/u16:14: 0% user + 7.1% kernal
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 7.1% 9998/kworker/u16:4: 0% user + 7.1% kernal
上面的日志将CPU状态写的很清楚,这里再将需要分析的列出来:
// 进程名
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: ANR in com.xxxx.mobile(com.xxxx.mobile/.ui.MainActivity)
// 进程 pid
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: PID: 1480
// Load表明是1min/5min/15min CPU的负载
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: Load: 0.0 / 0.0 / 0.0
// com.xxxx.mobile 的CPU使用率是11%,用户态使用率5.2%,内核态使用率6.3%
07-20 15:36:58.711 1000 1520 1597 E ActivityManager: 11% 1480/com.xxxx.mobile: 5.2% user + 6.3% kernal / faults: 76401 minor 2422 major
com.xxxx.mobile占用了11%的CPU,其实这并不算多,现在的手机基本都是多核CPU,假如你的CPU是4核,那么上限是400%,以此类推。
④查看traces.txt日志分析具体发生ANR的位置
当app不响应、响应慢了或者WatchDog的监视没有得到回应时,系统会dump出一个traces.txt文件存放在/data/anr/traces.txt,通过traces.txt文件,可以拿到线程名、堆栈信息、线程当前状态、binder call等信息。通过命令adb pull /data/anr/获取。
Cmd line:com.xxxx.mobile
"main" prio=5 tid=1 Runnable
| group="main" sCount=0 dsCount=0 obj=0x73bcc7d0 self=0x7f20814c00
| sysTid=20176 nice=-10 cgrp=default sched=0/0 handle=0x7f251349b0
| state=R schedstat=( 0 0 0 ) utm=12 stm=3 core=5 HZ=100
| stack=0x7fdb75e000-0x7fdb760000 stackSize=8MB
| held mutexes="mutator lock"(shared held)
at ttt.push.InterceptorProxy.addMiuiApplication(InterceptorProxy.java:77)
at ttt.push.InterceptorProxy.create(InterceptorProxy.java:59)
at android.app.Activity.onCreate(Activity.java:1041)
at miui.app.Activity.onCreate(SourceFile:47)
at com.xxxx.mobile.ui.b.onCreate(SourceFile:172)
at com.xxxx.mobile.ui.MainActivity.onCreate(SourceFile:68)
at android.app.Activity.performCreate(Activity.java:7050)
……
从堆栈信息中能够看到有我们应用的代码:
at ttt.push.InterceptorProxy.addMiuiApplication(InterceptorProxy.java:77)
找到了具体代码的位置并修复。
2)案例二
①查看traces.txt日志找到发生ANR的时间节点、主线程状态、ANR类型、事故点。
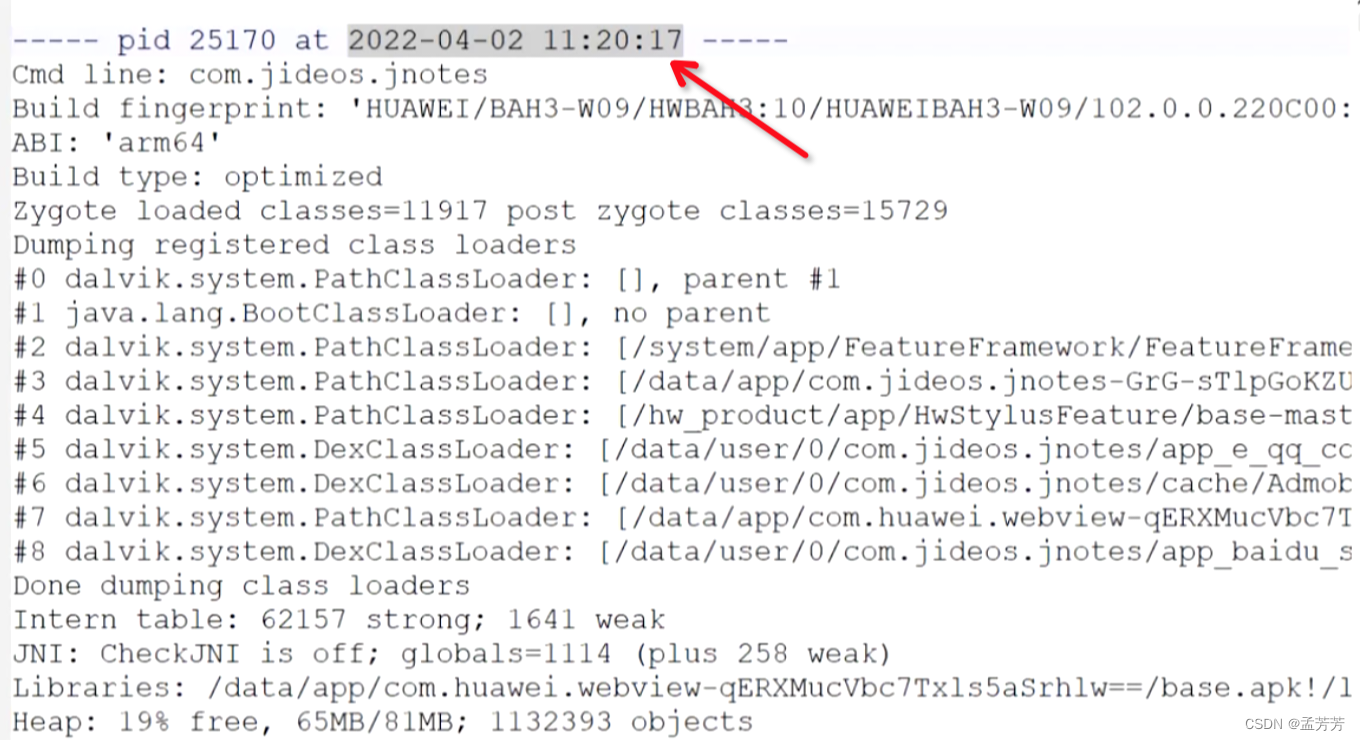
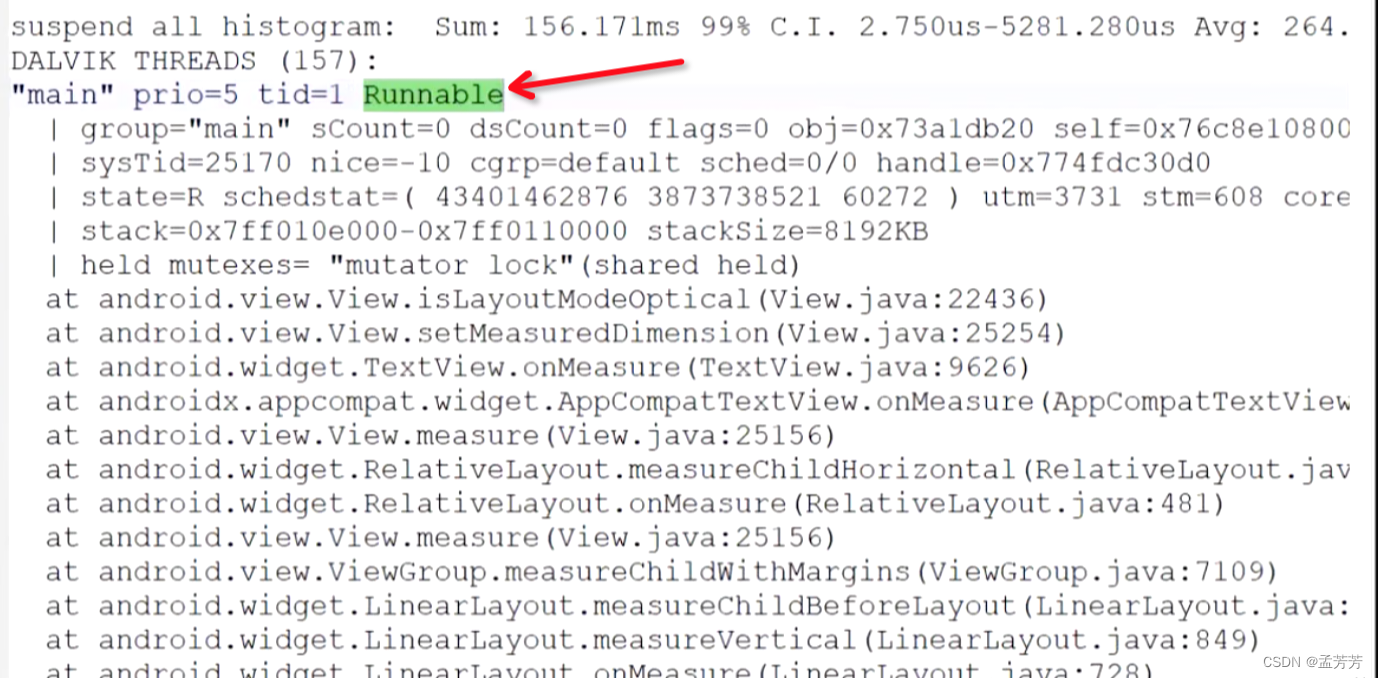
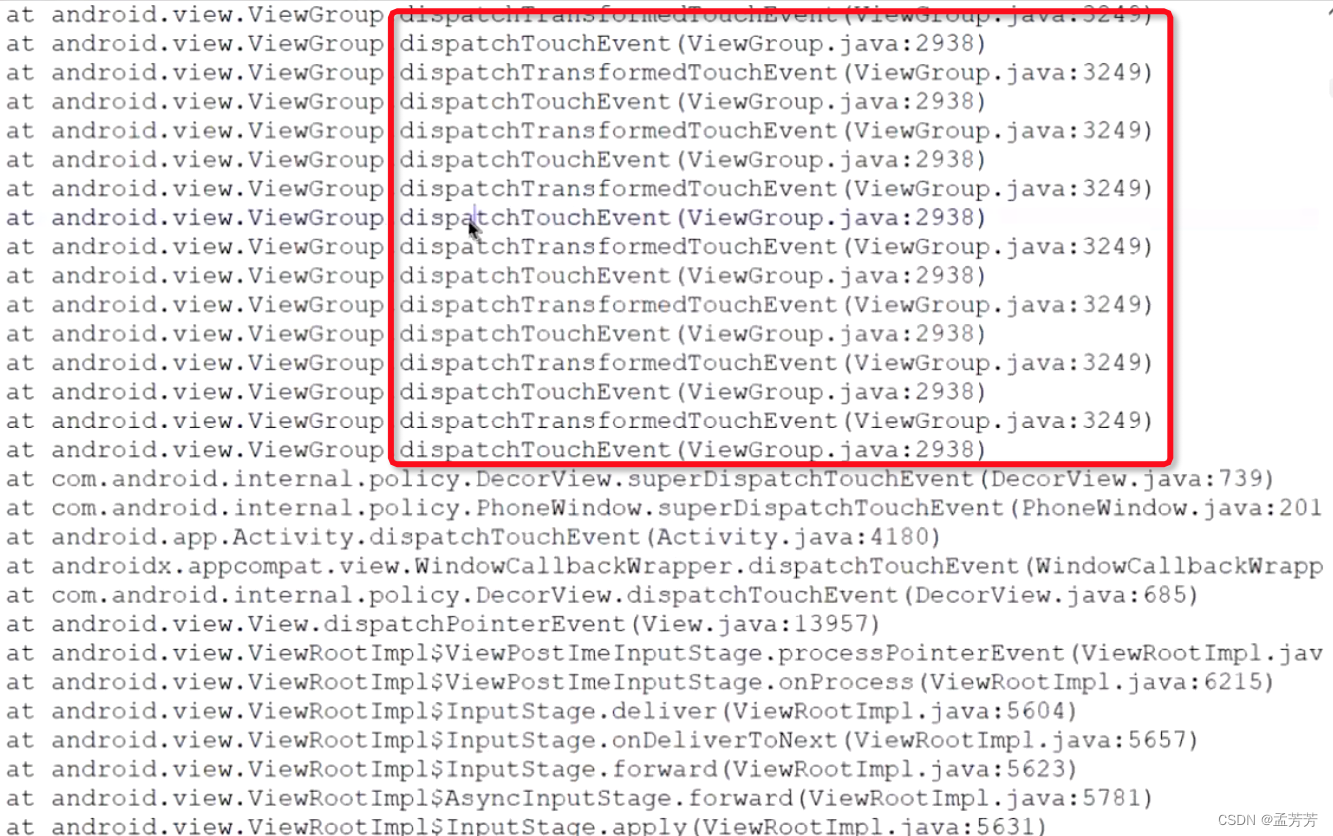
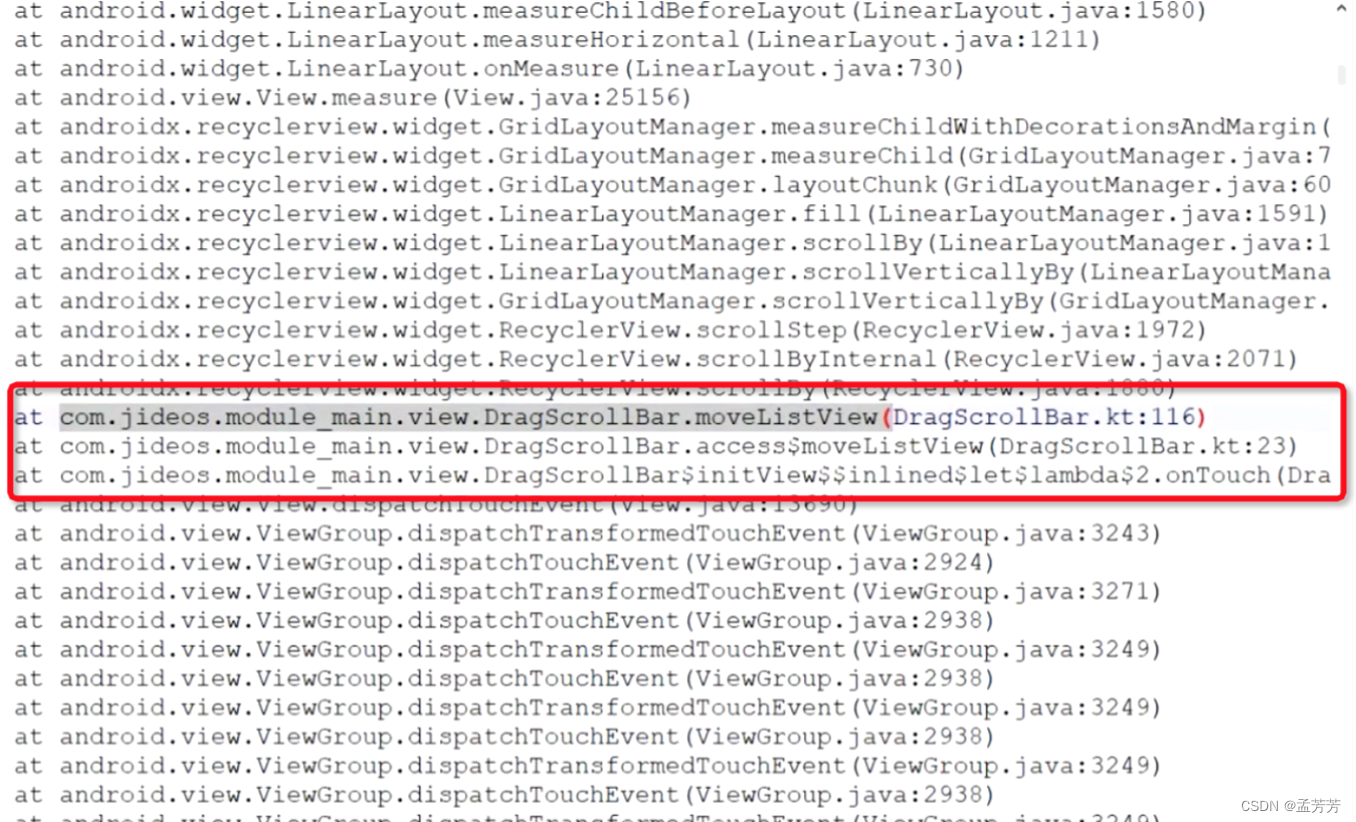
根据上面的信息梳理下信息:
ANR时间节点:2022-04-02 11:20:17
主线程状态:Runnable
ANR类型:堆栈信息是dispatchTouchEvent,大致判断是事件导致
事故点:com.jideos.module_main.view.DragScrollBar.moveListView()
②查看mainlog日志分析CPU状态
搜索关键词 ANR in:
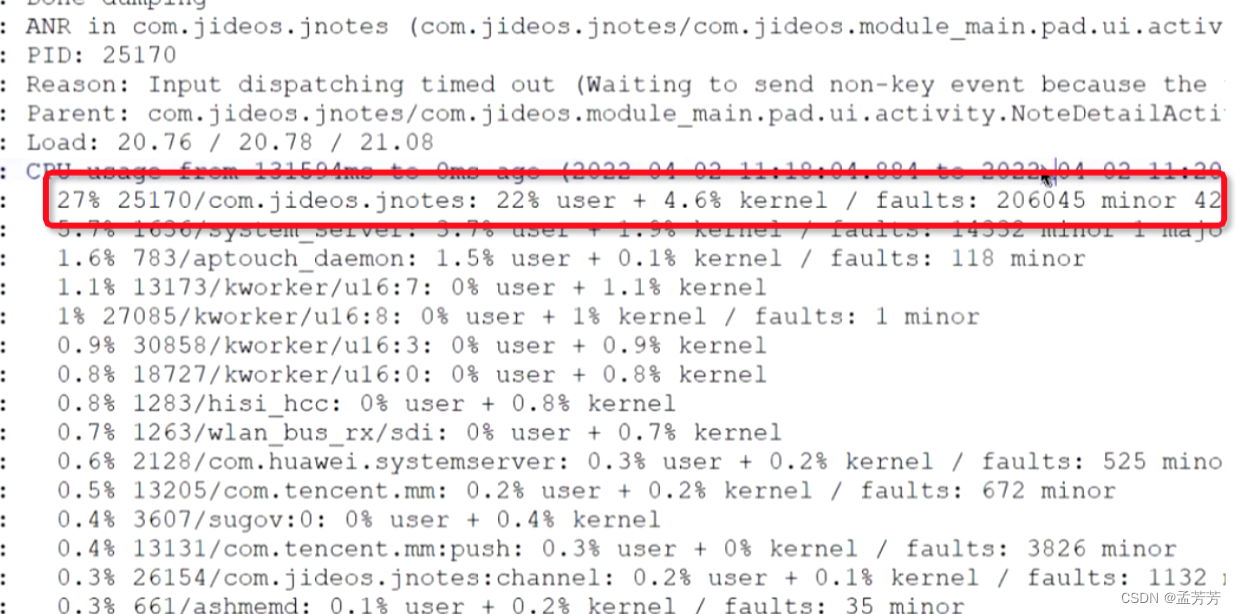
CPU状态该进程总共占27%,其中用户态占用22%,内核态占用4.6%(内核态能说明是否是IO过多)。
如果CPU占用40%左右就要考虑CPU消耗过高了。
根据上面的分析,CPU状态整体是正常的,排除掉IO、死锁导致的问题。
③查看traces.txt日志分析GC(是否是内存问题)
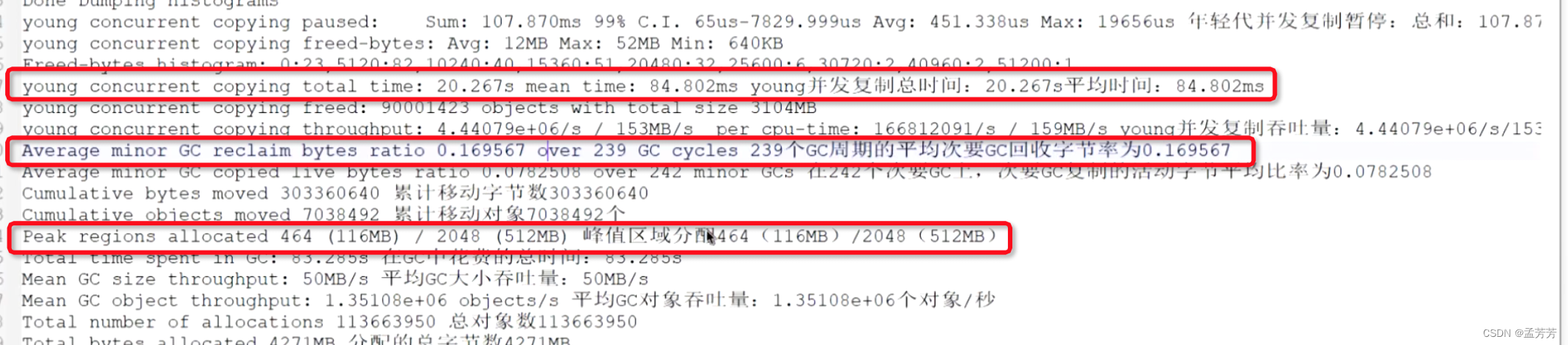

320个GC循环中的平均主GC回收字节率 0.0731004
323个主要GC上的平均主要GC复制活动字节比 0.862705
年轻代并发复制总时间20.267s,平均时间 84.802ms
239个周期的平均次要GC回收字节率0.169567(按次算)
峰值区域分配464(116MB)/ 2048(512MB),将近满值
总GC次数559次(也就是 559 次 STW)
总GC时间83.285s
总GC阻塞次数279次
总GC阻塞时间52.749s
根据上面的信息基本可以判定GC是不正常的,对象的回收率不高,而且GC次数过多,GC时间很长,应用程序在非常频繁的GC,内存不足才会频繁的GC,所以可以断定是有大对象创建或内存泄漏了导致的内存不足,频繁GC触发 STW(Stop The World)拉长了线程执行时间导致ANR。
④结合项目代码和分析到的原因定位修复ANR
6.难定位的ANR问题
①主线程被其他线程lock导致死锁

②主线程做耗时操作,比如数据库读写

③binder数据量过大

④binder通信失败

7.解决ANR问题
①将所有耗时操作如访问网络、socket通信、查询大量SQL语句、复杂逻辑计算等都放在子线程中,然后通过handler.sendMessage、runOnUIThread等方式更新UI。无论如何都要确保用户界面的流畅度,如果耗时操作需要让用户等待,可以在界面上显示进度条。
②将IO操作放在异步线程。在一些同步的操作主线程有可能被锁,需要等待其他线程释放响应锁才能继续执行,这样会有一定的ANR风险,对于这种情况有时也可以用异步线程来执行相应的逻辑,另外,要避免死锁的发生。
③使用Thread或HandlerThread时,调用 Process.setThreadPriority(Process.THREAD_PRIORITY_BACKGROUND)设置优先级,否则仍然会降低程序响应,因为默认Thread优先级和主线程相同。
④使用Handler处理工作线程结果,而不是使用Thread.wait()或Thread.sleep()来阻塞主线程。
⑤Activity的onCreate()和onResume()回调中避免耗时代码。
⑥BroadcastReceiver中onReceive()代码要尽量减少耗时,建议使用IntentService处理。
⑦各个组件的生命周期函数都不应该有太耗时的操作,即使对于后台Service或ContentProvider来讲,虽然应用在后台运行时生命周期函数不会有用户输入引起无响应的ANR,但其执行时间过长也会引起Service或ContentProvider的ANR。
以上的常规解决方案实际上只有一个核心,就是降低线程阻塞时间,将耗时操作放到子线程处理。

![[LeetCode 1664]生成平衡数组的方案数](https://img-blog.csdnimg.cn/58251bb734ed4c27b316ff9824bfaaff.png)



![[acwing周赛复盘] 第 88 场周赛20230128](https://img-blog.csdnimg.cn/ace0c1290b404900a0d57adf8381cba4.png)