目录
DSL相关联的基本概念
ElasticSearch的字段类型
ElasticSearch的查询类型
DSL语法
query
普通查询
布尔查询
字符串构建查询
_source
from和size
sort
关于sort和查询的相关性评分
关于sort的性能
DSL相关联的基本概念
Es的DSL并不是独立的知识点,是需要和Es的存储类型和查询类型相关联,所以在进行DSL语法的解析之前,需要先硬性理解或者说记录这两个内容
ElasticSearch的字段类型
es中的文档是以Json的格式存在,像关系型数据库一样,在使用时需要通过Mapping进行内容的预定义(虽然Es本身可以根据插入的数据进行自动的类型识别,但是最好还是在写入数据之前进行数据建模为好,毕竟自动识别是存在误差的),而Mapping定义中除了定义索引相关的信息外,最重要的就是索引内存储文档的各个字段类型(像关系型数据库中定义表结构时,需要指名每个 cloum的字段类型是varchar还是date)。
例如一个student索引,我们存储的内容包括,学号、姓名、年龄、性别、年级、宣言,那么一个学生的信息在es中的文档应该是:
{
"stu_no":"sadfas213213312",
"name":"张三",
"level":"3"
"age":9,
"sex":"男",
"desc":"阳光向上,积极进取"
}这么一种Json结构,在进行Es存储以及后续的检索时,各个字段的数据类型和性能以及查询语句的写法都息息相关,例如年纪,使用中可能需要经常被聚合统计,设置为keyword会更好,desc这种可能需要被快速查询,就需要用到可分析类型(text)……
Es的常用的存储类型有:
| 字段类型 | 使用场景 | 是否分词 | 是否纳入倒排索引 | 其他 |
| Text | 适用于需要进行全文搜索的字段,可存放内容性质、描述性质的数据,如文章内容 | 是 | 是 | 唯一的可分析字段,Es会对该类型的字段内容进行分析、分词,并把词项纳入倒排索引中 |
| keyword | 类似于varchar,用于存放简短的字符串性质内容,例如状态码、姓名、账号等 | 否 | 是 | keyword不进行分词,但是内容会整个被倒排索引纳入作为一个词项,适用于精确匹配、聚合 |
| Integer, Short, Long, Byte | 数值类型,用于存储整数 | 否 | 否 | 注:对于数字类型的字段,Elasticsearch 会为它们构建一个数值索引(Numeric Index),这种索引允许高效的数值范围查询和排序操作。数值索引不包含文本分析和分词,因此它们不适合用于搜索包含文本的查询。 |
| Double, Float, Half_Float | 数值类型,用于存放浮点数 | 否 | 否 | |
| Date | 存储日期和时间 | 否 | 否 | 1. 日期字段存储为时间戳,查询时和数值类型一样使用数值索引来优化查询 2.在聚合和排序时,通过DocValues、fielddata来提高性能 3.针对日期类型,在查询、聚合时,Es都提供方便的计算和处理 |
| Boolean | 存放布尔值 | 否 | 否 | |
| Object | 存储复杂数据结构,例如嵌套JSON | 否 | 否 | Object类型虽然不会被纳入倒排索引,但是内容中可以包含倒排索引的字段 |
| Nested | 存储嵌套对象数组 | 否 | 否 | 慎用,对于此类型在查询、聚合时都较为麻烦 |
| Ip | 专门用于存储 IP 地址 | 否 | 否 | 使用该类型,Es可以提供一些针对Ip的操作和运算较为方便 |
ElasticSearch的查询类型
Es中的查询类型又叫查询句柄,如果类比SQL语法,这里的查询类型就类似于SQL中WHERE部分的内容,例如= 、< 、>、LIKE、NOT之类。
Es的查询类型较多,在这里就放一些常用的,对于特殊需求的,可以查阅详细官方文档。
| 查询类型 | 使用场景 | 适用字段类型 | 缓存情况 |
| Match Query | 用于全文搜索,可以进行分词和分析,类似于 SQL 中的 LIKE 查询。 | Text | 使用queryCache,但由于全文搜索的复杂性,缓存效果可能不如 Term Query。 |
| Prefix Query | 用于查找以特定前缀开头的词项 | Keyword、Text(不进行分词的情况下) | 使用queryCache,尤其是当字段是 Keyword 类型时效果更佳 |
| Multi-Match Query | 允许在多个字段上执行全文搜索 | Text | 使用queryCache,但可能因跨多个字段而降低缓存效率 |
| Term Query | 用于查找与指定词项(term)完全匹配的文档 | Keyword、Boolean、Integer、Short、Long、Byte、Double、Float、Date、IP | 通常使用普通的queryCache,如果字段是 Keyword 或 Date 类型,并且查询是精确匹配,也可能使用字段数据缓存(fielddata cache) |
| Range Query | 用于查找在指定数值或日期范围内的文档 | Integer、Short、Long、Byte、Double、Float、Date | 不使用查询缓存 |
| Wildcard Query | 支持使用通配符(如 | Keyword、Text | 通常不使用查询缓存,因为通配符查询可能涉及大量文档 |
| Fuzzy Query | 允许进行模糊搜索,可以容忍一定数量的拼写错误 | Keyword、Text | 不使用查询缓存 |
| Bool Query | 允许组合多个查询条件,使用 AND、OR 和 NOT 逻辑 | 因为其内部可以嵌套其他查询类型,所以适配所有字段类型 | 使用QueryCache,但缓存效率取决于子查询的复杂性和可缓存性 |
| Nested Query | 用于在嵌套对象中执行查询 | Nested | 不使用查询缓存 |
| Script Query | 允许使用脚本语言(如 Painless)执行自定义查询 | 根据脚本内容决定适配的字段类型 | 不使用查询缓存 |
关于缓存内容可以参考上一篇文章,详细的查询类型使用方法会在下文中提及
DSL语法
先看一下DSL的语法,DSL常用的有查询、返回内容、排序、条数、以及聚合
{
"query":{}, // 查询
"_source":[], //返回内容
"sort":[], //排序
"from":0, // 起始位置
"size":10, // 返回条数
}以常用的SQL进行对照理解大约是这样的:
| DSL | SQL | 解释 |
|---|---|---|
| query | SELECT name,age FROM student WHERE home = '饭都花园' ORDER BY stu_no DESC LIMIT 0, 10 | 相当于SQL中的WHERE起手,此次内容为查询的条件 |
| _source | SELECT name,age FROM student WHERE home = '饭都花园' ORDER BY stu_no DESC LIMIT 0, 10 | 相当于SQL中SELECT关键字后指定此次查询需要的字段,DSL中通过_source来指定一次查询中需要返回json文档中的哪些字段的内容 |
| from、size | SELECT name,age FROM student WHERE home = '饭都花园' ORDER BY stu_no DESC LIMIT 0, 10 | 相当于SQL中的返回条数limit,指定多少条数据开始,返回多少个数据 |
| sort | SELECT name,age FROM student WHERE home = '饭都花园' ORDER BY stu_no DESC LIMIT 0, 10 | 相当于SQL中的ORDER BY排序字段,即查询出的数据是以JSON文档中哪个字段以何种方式排序 |
| aggs | SELECT stu_id FROM student WHERE home = '饭都花园' GROUP BY stu_id | 相当于SQL中的Group BY操作,即对某个字段内容进行聚合 |
query
其中query关键字是查询中最核心的部分,它是上文中提到的查询类型的集中区,不论是查询功能方面,还是查询性能方面,query的操作性是最多的;从查询类型上来看query又可以分为普通查询、过滤查询、布尔查询、字符串构建查询:
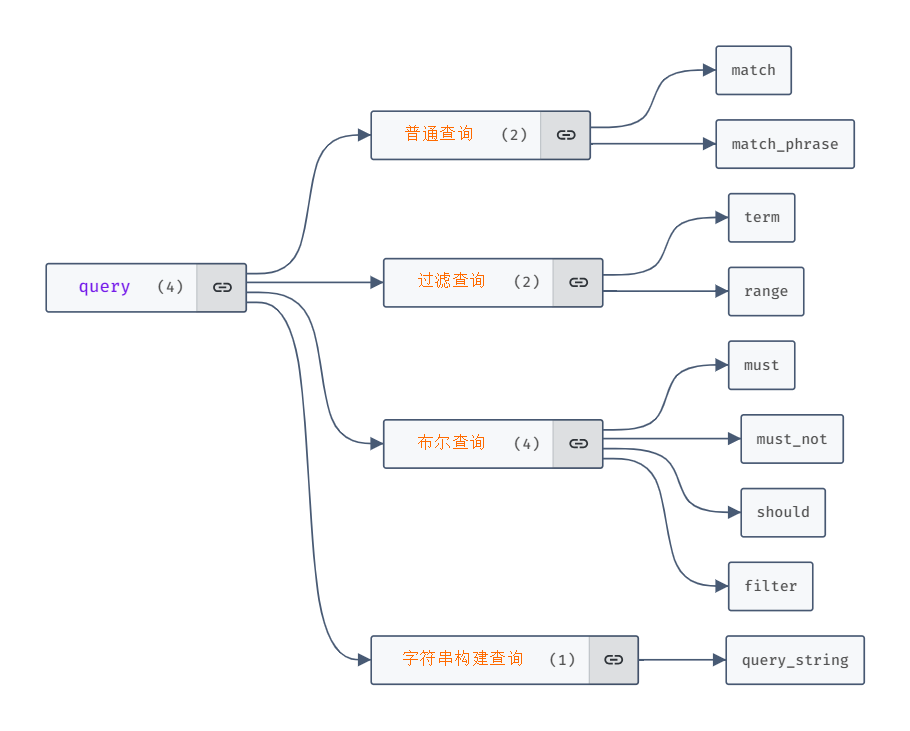
普通查询
普通查询一般使用match查询类型,是最常见的查询语句,只针对类型为text的字段才生效,此查询为全文检索;全文检索会影响返回结果的相关性得分,这意味着Elasticsearch会计算每个匹配文档的相关性,并按照得分排序返回结果。
//一个普通的全文查询
{ "query": { "match": { "context": "this is a boy" } } }
// 包含顺序的词短语搜索
{ "query": { "match_phrase": { "context": "搜索引擎" } } }过滤查询其实也可以算在简单查询里,即都是通过query下一层直接使用查询句柄(查询类型),不同的是使用的查询类型,过滤查询一般使用的查询句柄为 term、range这种查询类型
//等于逻辑筛选 name = 张三
{ "query": { "term": { "name": "张三" } } }
//范围筛选 , age >= 10 ,age =< 20
{ "query": { "range": { "age": { "gte": 10,"lte":20 } } } }使用term、range这种查询句柄相较于match、match_phrase来说,不会影响相关性得分,过滤查询的结果不会根据相关性进行排序,它们只是简单地确定文档是否应该被包含在结果集中,减少了排序步骤,性能上会好一些。
布尔查询
布尔查询就是在query关键字下使用布尔查询类型来进行查询,相比于简单查询,仅能使用一种逻辑查询,布尔查询可以理解为复杂查询,即可以使用逻辑关系组合条件,布尔查询包含四个逻辑组,must(且)、must_not(非)、should(或)、filter(且),组成方式是在query下存放逻辑组,逻辑组中放查询句柄:
| 关键字 | 含义 | 用法 |
|---|---|---|
| must | ”是“条件组,参数类型为[] | 数组内可配多个查询句柄,各查询句柄之间为且的关系 |
| must_not | ”否“条件组,参数类型为[] | 数组内可配多个查询句柄,每个查询句柄为逻辑取反 |
| should | ”或“条件组 ,参数类型为[] | 数组内可配多个查询句柄,各查询句柄之间为或的关系 |
| filter | 筛选器,参数类型为[] | 数组内可配多个查询句柄,查询句柄的关系也为且关系,且使用filter的可以忽略相关性得分,考虑性能可使用filter替代must |
{
"query":{
"bool":{
"must":[], //且
"should":[], // 或
"must_not":[] // 非
}
}
}例如以下几个例子
# 查询 性别是女的或者 年龄大于30岁且教授语文的老师
SELECT * FROM tb_teach WHERE sex = 1 OR ( age > 30 AND role = '语文' )对应使用Es的布尔查询则是:
{
"query":{
"bool":{
"should":[ //对应SQL中最高层的 OR 逻辑
{
"term":{ "sex":1}
},
{
"bool":{ // 对应 SQL中二层里的AND逻辑
"must":[
{"range": { "age":{ "gt":30 } } }, //age > 30
{"term":{ "role":"语文" } // role = 语文
]// end must
}
}
] // end should
}
}
}#查询不教语文,且年龄在20-30之间的老师
SELECT * FROM tb_teach WHERE role != '语文' AND age BETWEEN 20 AND 30
#对应的DSL:
{
"query":{
"bool":{
"must":[ //对应SQL中最高层的 AND 逻辑
{
"bool":{ "must_not":[{"term":{ "role":"语文"}}] }
},
{
"range":{
"age":{
"gte":20,
"lte":30
}
}
}
]
}
}
}#查询名字为张三且年龄为12岁,或者部门不在人事部且年龄在10到20岁之间的人
SELECT
*
FROM
USER
WHERE
(name = "张三" AND age = 12) OR (dept != "人事部" AND age >= 10 AND age<=20 )
#对应的DSL
{
"query":{
"bool":{
"should":[ //对标SQL 中 的 OR
{
"bool":{
"flter":[ //对标SQL 中 OR左侧()中的AND
{
"term":{
"name":"张三"
}
},
{
"term":{
"age":12
}
}
]
}
}, // ↑ 为OR左侧的() 中的条件
{
"bool":{
"must_not":[ // 对标dept != "人事部"
{
"term":{
"dept":"人事部"
}
}
],
"filter":[
{
"range":{
"age":{
"gte":10,
"lte":20
}
}
}
]
}
} ↑ 为OR右侧的() 中的条件
]
}
}
}可以看到,布尔查询也可以被当作逻辑组(must、filter、should、must_not)的一个条件 ,逻辑是可以嵌套的,可以根据需求,选择不同的逻辑组,通过不同的嵌套组合就可以完成复杂逻辑的查询。
另外一点就是must和filter,它俩都可以表示且的关系,但是在执行原理和性能上会有不同:
| 关键字 | 作用 | 缓存 |
| filter | 用于定义查询的过滤条件,这些条件用于限制返回的文档集合。过滤条件通常用于结构化数据(如数值范围、日期范围、确切的值匹配等) | 通常会对 filter 子句使用缓存,这意味着如果相同的过滤条件被多次使用,它们的执行结果可以被缓存和重用,从而提高查询性能 |
| must | 用于定义查询的搜索条件,这些条件用于计算文档的相关性得分。must 子句中的查询通常用于全文搜索,影响返回文档的排序 | must 子句通常不使用缓存,因为它们影响文档的相关性得分,每次查询可能都会产生不同的结果 |
对于结构化的查询,建议优先使用filter
字符串构建查询
字符串构建查询也是Es常用的一种查询,它适用于需要复杂文本搜索的场景,如搜索引擎的查询框。它允许用户以类 SQL 的方式执行复杂的文本搜索,使用一个查询字符串来构建查询,支持多种查询语法和操作符,使用关键字为:query_string
{
"query": {
"query_string": {
"query": "title:guide AND (title OR body):Elasticsearch"
}
}
}
这里主要是query_string中的query内容,它是一个类SQL的语法,表示我们要查询 (titile字段中包含“guide”词项) 且 (title字段或者body字段中包含"Elasticsearch"词项)的文章,这里query支持的形式包含:
- 布尔逻辑(AND, OR, NOT)
- 通配符搜索(使用
*和?) - 模糊搜索(使用
~后跟编辑距离) - 正则表达式搜索(使用
/包围) - 短语搜索(使用双引号
" "包围词组) - 字段特定搜索(使用
FIELD:指定字段) - 提升(Boosting)搜索词项(使用
^后跟提升值)
一个完整的query_string还包含字符串查询的一些控制项:
{
"query": {
"query_string": {
"query": "title:guide AND (title OR body):Elasticsearch",
"default_operator": "AND",
"fields": ["title", "body"],
"use_dis_max": true,
"tie_breaker": 0.3,
"minimum_should_match": "2<75%",
"boost": 1.0,
"analyzer": "standard",
"quote_field_suffix": ".exact",
"fuzzy_max_expansions": 50,
"fuzzy_prefix_length": 2,
"phrase_slop": 2,
"escape": false,
"auto_generate_phrase_queries": true
}
}
}-
default_operator:设置默认的布尔操作符。AND表示默认使用 AND 逻辑,即所有条件都需要匹配。 -
fields:指定搜索的字段列表。这里我们在title和body字段中搜索。 -
use_dis_max:当设置为true时,使用dis_max查询来组合多个字段的搜索结果,以提高相关性。 -
tie_breaker:在use_dis_max为true时,用于控制多字段搜索的相关性得分计算。 -
minimum_should_match:对于使用OR操作符的查询,定义至少需要匹配的最小条件数量。这里的 "2<75%" 表示至少匹配两个条件,或者匹配超过 75% 的条件。 -
boost:提升查询的整体相关性得分。 -
analyzer:指定查询时使用的分析器。 -
quote_field_suffix:后缀,用于指定精确匹配的字段版本。 -
fuzzy_max_expansions:模糊查询可以扩展的最大项数。 -
fuzzy_prefix_length:在模糊查询中,前缀的最小字符数。 -
phrase_slop:短语查询中的间隔。 -
escape:是否转义查询字符串中的特殊字符。 -
auto_generate_phrase_queries:是否自动将双引号内的词组转换为短语查询。
_source
_source在DSL语法中是比较简单的,类比SQL中SELECT 之后的返回内容控制,即这次检索我需要查询的数据需要JSON文档中的哪几个字段,例如索引中数据:
{
"id": "1",
"title": "Elasticsearch Basics",
"content": "Elasticsearch is a powerful search engine based on the Lucene library. It provides full-text search, analysis, and indexing of data. This article will guide you through the basics of Elasticsearch.",
"date": "2024-06-08T08:00:00Z",
"author": "John Doe"
}查询文章标题为Elstaicsearch的文章:
#查询文章名称为Elasticsearch的文档
{
"query":{
"term":{
"title":"Elasticsearch"
}
}
}
#返回:
{
"took": 10,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "articles",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": { #返回了Json文档全部的字段
"id": "1",
"title": "Elasticsearch Basics",
"content": "Elasticsearch is a powerful search engine based on the Lucene library...",
"date": "2024-06-08T08:00:00Z",
"author": "John Doe"
}
}
]
}
}如果只需要其中的author和context,则使用_source进行指定:
#查询文章名称为Elasticsearch的文章,需要文章作者和内容两部分
{
"query":{
"term":{
"title":"Elasticsearch"
}
},
"_source":["author","context"]
}
#返回
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "articles",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": { #只根据_source指定的内容进行返回
"author": "John Doe",
"content": "Elasticsearch is a powerful search engine based on the Lucene library. It provides full-text search, analysis, and indexing of data."
}
}
]
}
}关于查询文档内容,可以根据需求和性能要求使用stored在Mapping定义阶段就使用,也可以通过_source进行灵活指定,各有利弊,详细可以参考在ElasticSearch性能原理拆解中提过Stored Fields
from和size
from 和 size 是用于分页和限制返回结果集的参数,等同于SQL中的Limit语法,
from 参数指定了搜索结果中跳过的文档数量。这可以用于实现分页功能,其中第一页的结果可以跳过0个结果,第二页跳过10个结果(如果每页显示10个结果),以此类推。
size 参数定义了搜索结果中返回的最大文档数量。使用 size 可以限制返回的文档数量,这对于性能和网络带宽管理非常重要,因为它可以防止一次性返回大量数据。
例如:
#执行一个分页查询
{
"from": 2,
"size": 10,
"query": {
"match_all": {}
}
}
#输出:
{
"took": 5,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1000,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "my_index",
"_type": "_doc",
"_id": "doc_11",
"_score": 1.0,
"_source": { ... },
},
// ... 其他文档,直到第10个
]
}
}但是使用form 和size去实现分页查询存在一个问题,因为对于用户看到的是返回了10条数据,而对于Es而言则是
- 执行
match_all查询,匹配my_index索引中的所有文档。 - 计算所有文档的相关性得分。
- 忽略前30个文档。
- 选择第31到40个文档。
- 将这10个文档的相关信息返回给用户。
当不停地滑动页码,from的值越来越大时,会让Es过度计算和内存消耗,必要时会让Es抛出异常。所以,尽管form+size在分页查询的场景下是有效的,但是面对深度分页时,form+size是不推荐的,在面对大批量数据且有分页查询的诉求时,Elasticsearch推荐使用 search_after 参数,因为它可以提供更高效的分页机制。search_after 通过指定一个或多个排序值来检索结果集的一部分,这使得它可以避免重新计算所有文档的得分,从而提高性能。
sort
sort 用于对搜索结果进行排序。sort 允许你指定一个或多个字段,根据这些字段的值对结果进行排序。以下是 sort 的使用方法:
#对查询结果,根据学号进行正序排序
{
"query": {
"match_all": {}
},
"sort": [
{
"stu_no": {
"order": "asc" //或者desc
}
}
]
}也可以指定多个字段进行排序,第一个字段的排序完成后,如果存在相同值,则根据第二个字段排序,以此类推。
{
"query": {
"match_all": {}
},
"sort": [
{
"stu_no": {
"order": "asc"
}
},
{
"age": {
"order": "desc"
}
}
]
}
还可以通过脚本进行排序
{
"query": {
"match_all": {}
},
"sort": [
{
"_script": {
"type": "number",
"script": {
"lang": "painless",
"source": "doc['age'].value * 2"
},
"order": "asc"
}
}
]
}关于sort和查询的相关性评分
使用 sort 语句在 Elasticsearch 中对查询结果进行排序不会直接影响查询的相关性评分(_score)。相关性评分是由查询自身的算法决定的,例如 match 查询或 term 查询等,这些查询根据文档与查询条件的匹配程度来计算每个文档的得分。
sort 语句通常用于在相关性评分的基础上对结果进行进一步的排序。例如,当你使用 match_all 查询时,所有文档的相关性评分可能相同,此时你可以使用 sort 来根据其他标准(如日期、数值字段等)对结果进行排序。
- 独立性:
sort操作是独立的,它基于你指定的字段和排序顺序对文档进行排序,与文档的相关性评分无关。 - 组合使用: 你可以在任何类型的查询之后使用
sort,包括那些返回相关性评分的查询。 - 优先级: 当使用
bool查询时,可以在must、should或filter子句中组合多个查询,并使用sort来确定最终的排序顺序。 - 不改变评分: 即使文档经过
sort操作被重新排序,它们的相关性评分 (_score) 保持不变。 - 混合使用: 你可以将基于评分的排序与基于其他字段的排序混合使用。例如,首先根据相关性评分降序排序,然后根据日期字段升序排序。
关于sort的性能
使用 sort 可能会对查询性能产生影响,虽然DocValues的存在会对sort有一定的优化,但是DocValues不是适用所有字段:
-
keyword:对于keyword类型的字段,会默认使用 DocValues 存储
-
数值和日期: 对于数值(如
integer、float、double)和日期(date)类型的字段,默认使用 DocValues 存储。 -
Text:文本(
text)类型的字段默认不使用 DocValues,它需要经过分析(analysis)来支持全文搜索。但是,可以为text字段显式定义一个keyword子字段,该子字段将使用 DocValues。
使用 search_after 进行深度分页时,排序字段必须在索引时定义为 docValues,以便高效地检索和排序。
关于聚合部分,放在下一篇介绍:
理解DSL语法(二):聚合