在人工智能领域,尤其是在自然语言处理(NLP)中,大模型(LLMs)的预训练和推理效率一直是研究的热点。最近,一项突破性的研究提出了一种新型神经网络架构——MEGALODON,旨在解决传统Transformer架构在处理长序列时面临的挑战。

大模型(LLMs)在处理诸如多轮对话、长文档理解和视频生成等实际应用时,需要高效地处理长序列数据,并生成连贯的输出。然而,现有的Transformer架构由于其二次数方的计算复杂性以及对长度泛化的有限归纳偏差,使得其在长序列建模上效率不高。尽管已经提出了一些次二次数方的解决方案,如线性注意力和状态空间模型,但它们在预训练效率和下游任务准确性上仍不如Transformer。

为了克服这些限制,MEGALODON架构应运而生。它继承了MEGA(指数移动平均与门控注意力)的架构,并进一步引入了多个技术组件以提高其能力和稳定性。这些组件包括复杂指数移动平均(CEMA)、时间步归一化层、归一化注意力机制以及预归一化和双跳残差配置。
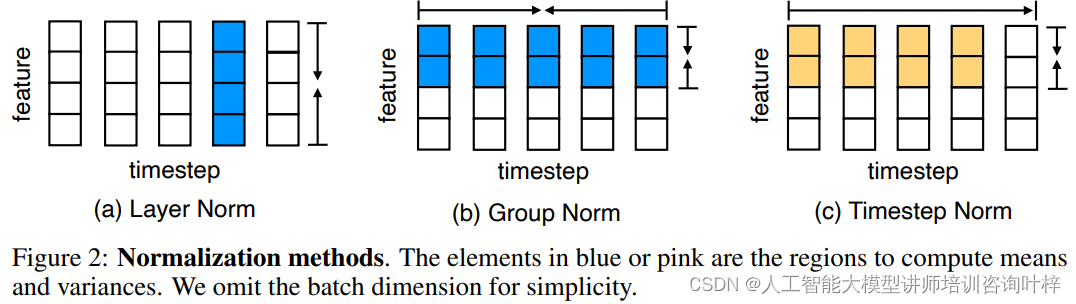
Figure 2展示了不同归一化方法的计算方式,这些方法在神经网络中用于稳定训练过程并提高模型的性能。归一化通过调整激活输出的分布,减少内部协变量偏移,从而使得模型更加稳定,便于学习和泛化。归一化方法包括:
-
Layer Normalization(层归一化):这是一种常用的归一化技术,它在神经网络的层级上对数据进行归一化处理。Layer Normalization会在神经网络的每一层计算激活值的均值和方差,然后使用这些统计量来归一化当前层的激活输出。
-
Group Normalization(分组归一化):这种方法是对Layer Normalization的一个扩展,它将特征维度分成多个组,并在每个组内分别计算均值和方差来归一化激活值。Group Normalization允许模型在特征维度上捕捉局部依赖性,同时减少参数数量。
-
Timestep Normalization(时间步归一化):这是MEGALODON架构中特别提出的一种归一化方法,它专门用于处理序列数据。Timestep Normalization在序列的时间步上计算累积的均值和方差,以此来归一化序列数据。这种方法对于自回归模型特别有用,因为它可以防止时间步上的梯度消失或爆炸问题,同时避免未来信息的泄露。
MEGALODON架构中,这些归一化方法被用来增强模型处理长序列的能力。通过合理地选择和应用这些归一化技术,MEGALODON能够在保持计算效率的同时,提高模型在长序列数据上的稳定性和性能。

Figure 3提供了MEGALODON架构的详细图解,展示了其核心组件和配置。这个架构是为了提高大型语言模型(LLMs)在长序列数据上的效率和性能而设计的
Figure 3(a) 展示了一个MEGALODON层的草图,它包括以下几个关键组件:
-
CEMA (Complex Exponential Moving Average) Output: 这是MEGALODON中的一个创新组件,它扩展了传统的指数移动平均(EMA)到复数域,以增强模型捕捉长距离依赖的能力。
-
Gate: 门控机制是控制信息流的一种方式,在MEGALODON中,可能包括重置门(reset gate)和更新门(update gate),它们共同作用于注意力机制的输出。
-
Q, K, V (Query, Key, Value): 这些是注意力机制中的查询、键和值,它们是模型用来计算注意力分数和加权输出的基础。
-
Normalized Attention Unit: 归一化注意力单元是MEGALODON中的另一个关键创新,它通过归一化查询和键的表示来提高注意力机制的稳定性。
-
Output Y: 经过注意力机制和后续的归一化处理后,得到的输出将被送入下一层或作为最终的预测结果。
-
Layer Norm: 层归一化被应用于输入和注意力输出上,以稳定训练过程并提高模型的泛化能力。
-
FFN (Feed-Forward Network): 这是每个Transformer层中的标准组件,用于在注意力机制之后进一步处理数据。
Figure 3(b) 展示了预归一化(Pre-Norm)的配置,这是Transformer架构中常用的一种归一化策略。在这种配置中:
-
输入X首先被送入归一化层,然后进入注意力机制。
-
注意力机制的输出与原始输入X相加,形成残差连接。
-
残差连接的输出再次经过归一化,然后送入前馈网络(FFN)。
这种配置有助于减少训练过程中的内部协变量偏移,并且由于归一化层在每个子层(如注意力机制和FFN)之前应用,因此有助于稳定深层网络的训练。
Figure 3(c)展示了MEGALODON中的另一种配置,即预归一化结合双跳残差连接。这种配置对预归一化进行了改进:
-
输入X首先经过归一化,然后送入注意力机制。
-
注意力机制的输出与原始输入X相加,形成第一跳残差连接。
-
这个残差连接的输出再次经过归一化,然后送入前馈网络(FFN)。
-
FFN的输出与原始输入X再次相加,形成第二跳残差连接。
这种双跳残差连接的设计有助于进一步稳定深层网络的训练,特别是在模型规模非常大时。通过在每个主要组件(如注意力机制和FFN)之后重新使用原始输入作为残差连接,这种配置减少了深层网络中梯度消失或爆炸的风险。
MEGALODON架构是针对现有Transformer架构在处理长序列数据时遇到的挑战而设计的。它基于MEGA架构,引入了一系列创新技术,以提高模型处理长序列的能力,并保持了高效的计算性能。
MEGALODON采用了复杂指数移动平均(CEMA),这是对MEGA中使用的多维阻尼指数移动平均(EMA)的扩展。CEMA通过在复数域中操作,增加了模型捕捉长序列依赖关系的能力。CEMA通过将EMA中的衰减和阻尼因子扩展到复数参数,使得模型能够在保持时间序列信息的同时,更好地捕捉序列中的长距离依赖。
MEGALODON引入了时间步归一化层(Timestep Normalization Layer),这是一种对现有归一化技术(如Layer Normalization和Group Normalization)的改进。时间步归一化层通过在序列的时间维度上计算累积的均值和方差,来减少序列内部的协变量偏移。这种归一化方法特别适用于自回归序列建模任务,因为它可以防止未来信息的泄露,同时提高了模型的稳定性。
MEGALODON采用了归一化注意力机制(Normalized Attention Mechanism),这是一种改进的注意力计算方法,通过使用归一化的共享表示来计算查询(Q)、键(K)和值(V)。这种方法简化了注意力分数的计算,并且通过引入非线性,提高了模型的表达能力。
MEGALODON还提出了预归一化和双跳残差配置(Pre-Norm with Two-hop Residual Configuration)。这种配置通过重新组织每个块中的残差连接,减少了深层网络训练中的不稳定性。在这种配置中,输入序列在经过归一化后直接用于残差连接,从而简化了模型的架构并提高了训练的稳定性。
MEGALODON架构通过将输入序列分块处理,实现了线性的计算和内存复杂度。这意味着无论序列长度如何,模型都能够以恒定的资源消耗来处理数据,这对于大规模语言模型的预训练和推理尤为重要。
MEGALODON还提出了一种新的分布式预训练算法,该算法通过在时间步/序列维度上进行并行化,进一步提高了模型的可扩展性。这种并行化策略允许模型在保持通信开销较低的同时,有效地利用多个计算设备,加速了模型的训练过程。
研究人员对MEGALODON架构进行了全面的评估,以验证其在长上下文序列建模上的性能。为此,他们构建了一个70亿参数的模型,并在2万亿个训练token上进行了预训练,这是一个前所未有的规模,旨在模拟真实世界中可能遇到的复杂和庞大的数据集。
在实验中,MEGALODON展现出了卓越的效率和可扩展性。与LLAMA2相比,MEGALODON在训练困惑度上取得了显著的降低,这是一个衡量模型对数据集预测准确性的关键指标。低困惑度意味着模型在预测下一个token时更加自信,这在长序列建模中尤为重要,因为即使是微小的误差也可能会随着序列的增长而累积。

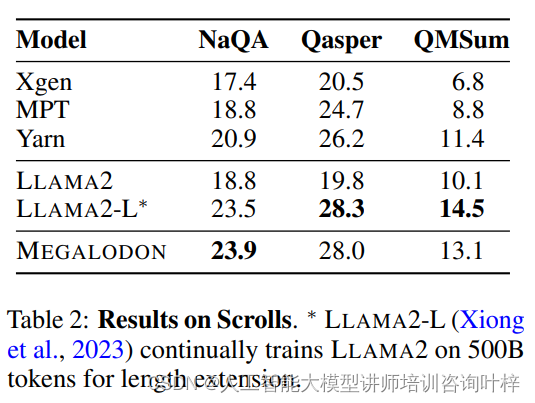
除了训练效率外,MEGALODON在多个下游任务中也表现出色。研究人员在不同的学术基准测试中对MEGALODON进行了评估,包括常识推理、世界知识问答和阅读理解等任务。在这些测试中,MEGALODON不仅超越了LLAMA2,而且在某些任务上达到了与更大模型规模相当的性能水平。
在长上下文评估中,MEGALODON的能力得到了进一步的证明。研究人员构建了一个包含不同上下文长度的验证数据集,从几千到两百万token不等。MEGALODON在这个数据集上的表现显示,随着上下文长度的增加,模型的预测性能稳步提高,这表明MEGALODON能够有效地利用更长的上下文信息来做出更准确的预测。
MEGALODON在中等规模的基准测试中也显示出了其鲁棒性。研究人员在图像分类和自回归语言建模等任务上对MEGALODON进行了测试。在ImageNet-1K数据集上的图像分类任务中,MEGALODON达到了比现有最先进模型更高的准确率。在PG-19数据集上的自回归语言建模任务中,MEGALODON同样展现出了更低的困惑度,这意味着它能够更准确地预测文本序列中的下一个单词。

这些实验结果不仅证明了MEGALODON在长上下文序列建模上的有效性,也展示了其在多种任务和数据类型上的通用性和鲁棒性。MEGALODON的这些特性使其成为一个有潜力的架构,可以应用于各种实际应用中,包括但不限于自然语言处理、计算机视觉和其他需要处理长序列数据的领域。随着人工智能技术的不断进步,MEGALODON架构有望在未来的AI研究和应用中发挥重要作用。
论文链接:https://arxiv.org/abs/2404.08801
GitHub 地址:https://github.com/XuezheMax/megalodon