早在19年5月就在某站上看到sylar的视频了,一直认为这是一个非常不错的视频。
由于本人一直是自学编程,基础不扎实,也没有任何人的督促,没能坚持下去。
每每想起倍感惋惜,遂提笔再续前缘。
为了能更好的看懂sylar,本套笔记会分两步走,每个系统都会分为两篇博客。
分别是【知识储备篇】和【代码分析篇】
(ps:纯粹做笔记的形式给自己记录下,欢迎大家评论,不足之处请多多赐教)
QQ交流群:957100923
ByteArray模块-代码分析篇
一、我们的约定
关于字节和比特,很多书本也好,视频也罢,总喜欢节省很多文字或者时间来描述这部分内容。比如书本中会轻描淡写的来一句 “一个字节等于八个比特”,后续就直接用 字节 作为最小单元来描述了。这可能对于大部分人来说都很好理解,但是我属于不太聪明的类型,容易比特字节字节比特的傻傻分不清楚。考虑到有和我一样属于不太聪明的那一类人,我们在这里先约定一下,在我们听到 比特、字节的时候请在脑海中浮现以下的图片!
我们先来看图
1.一个字节 int8_t / uint8_t(也就是8个比特)内存图
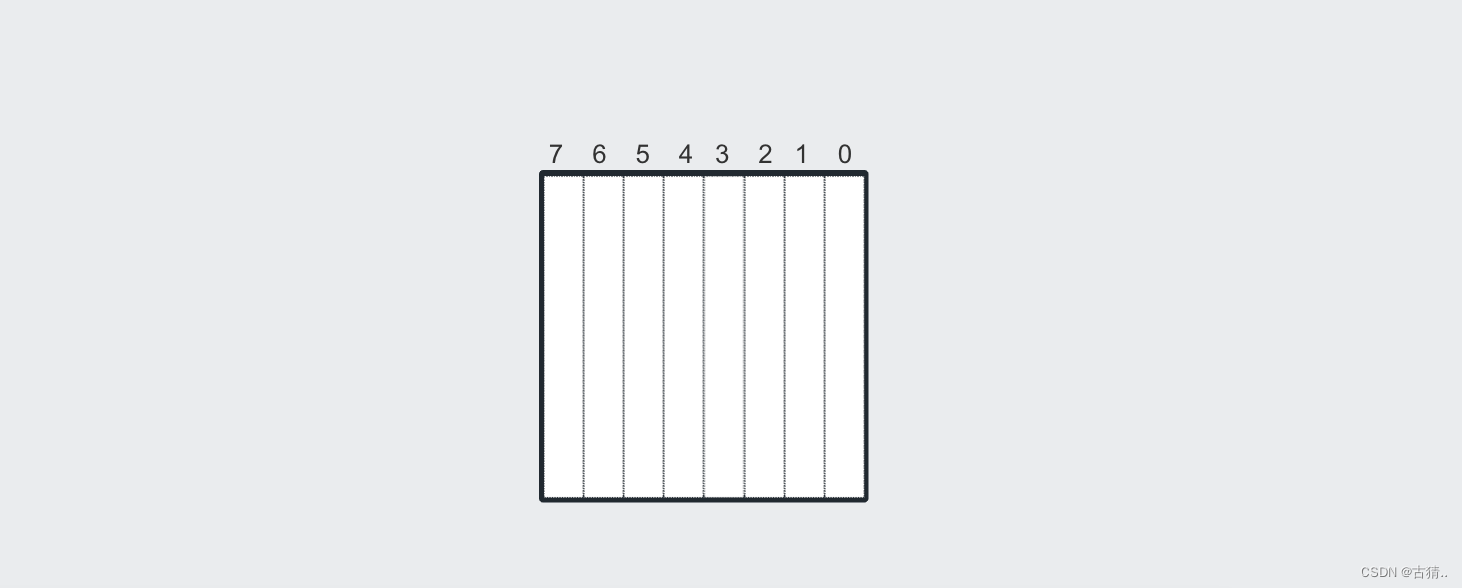
2.int16_t / uint16_t 类型(也就是16个比特)的内存图
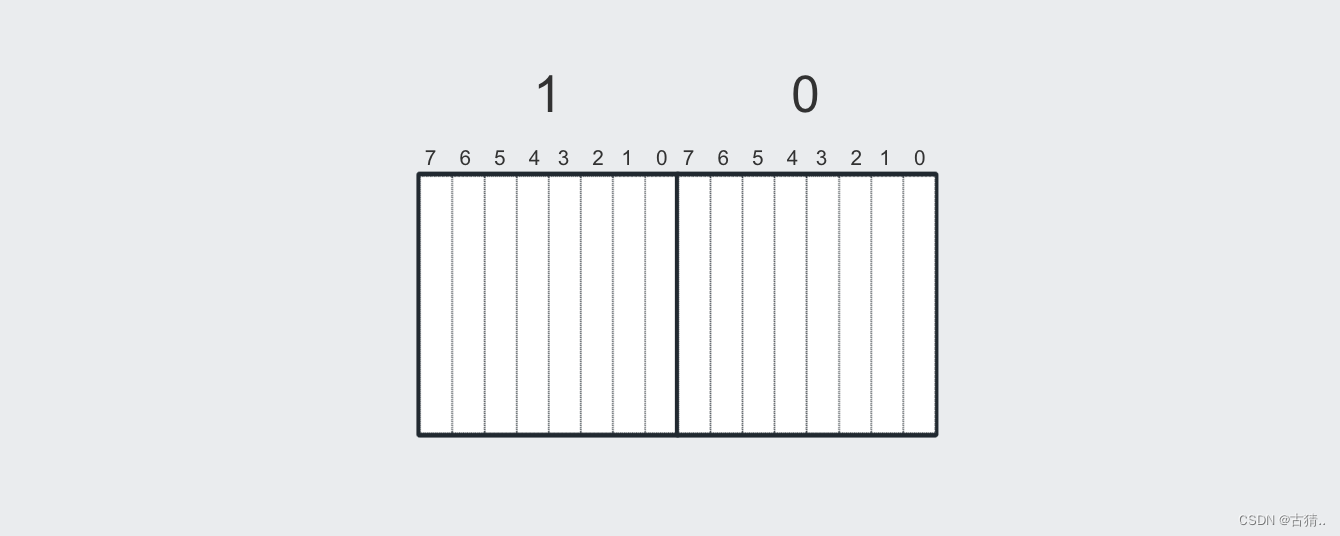
3.int32_t / uint32_t 类型(也就是32个比特)的内存图
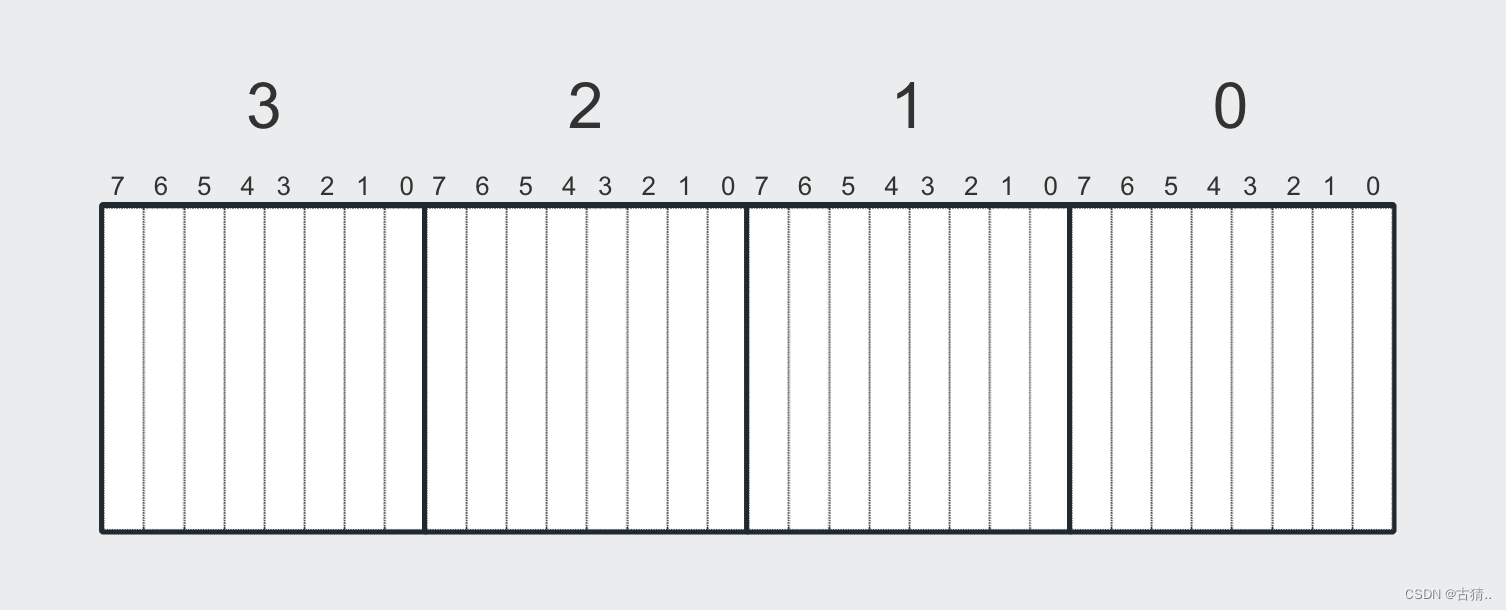
4.int64_t / uint64_t 类型(也就是64个比特)的内存图
这么一看你会发现,平时对于空间大小不敏感,int32_t 是最常用的,原来有这么大,以后要注意了,是不是可以用小一点的类型
二、int32_t 在内存中的表现
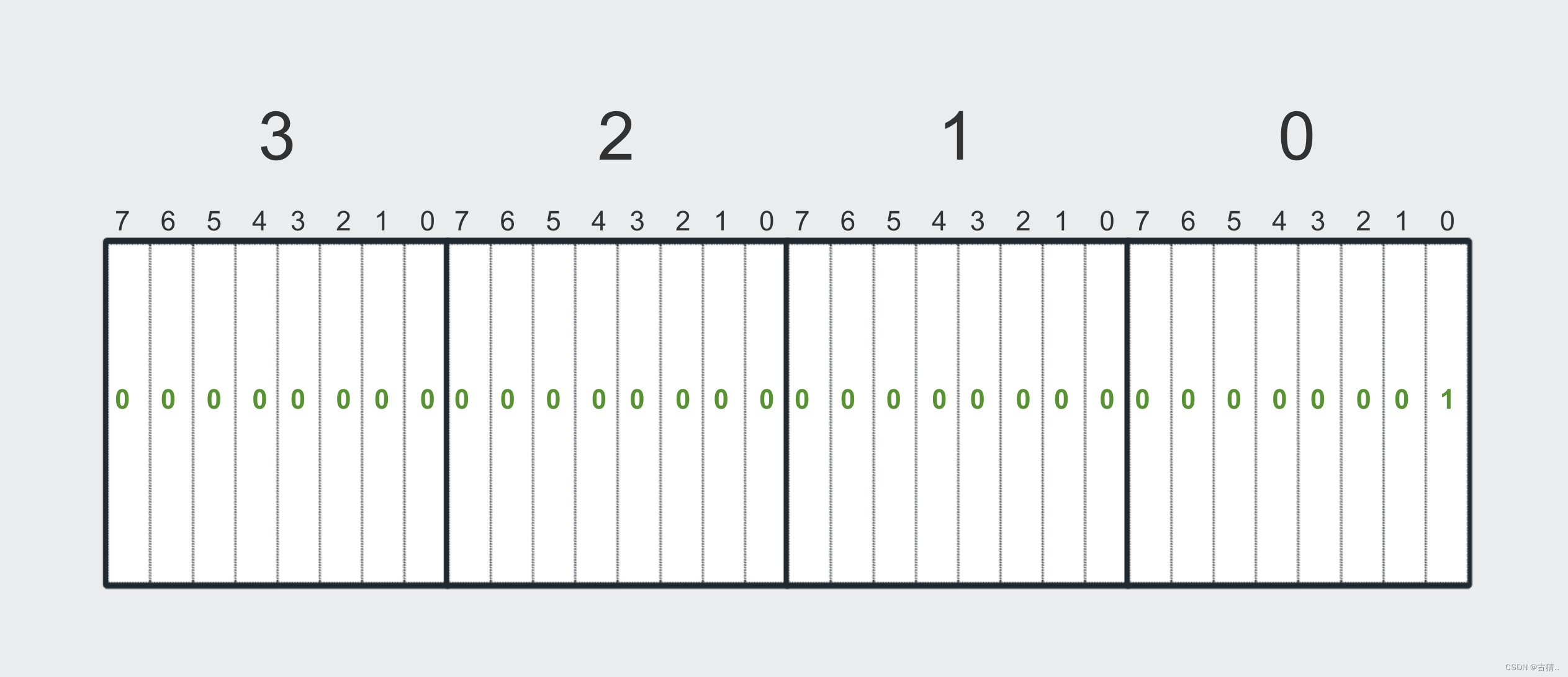
如果有一个十进制数 1 我们该如何表示:
十进制 1 对应 二进制 00000000 00000000 00000000 00000001
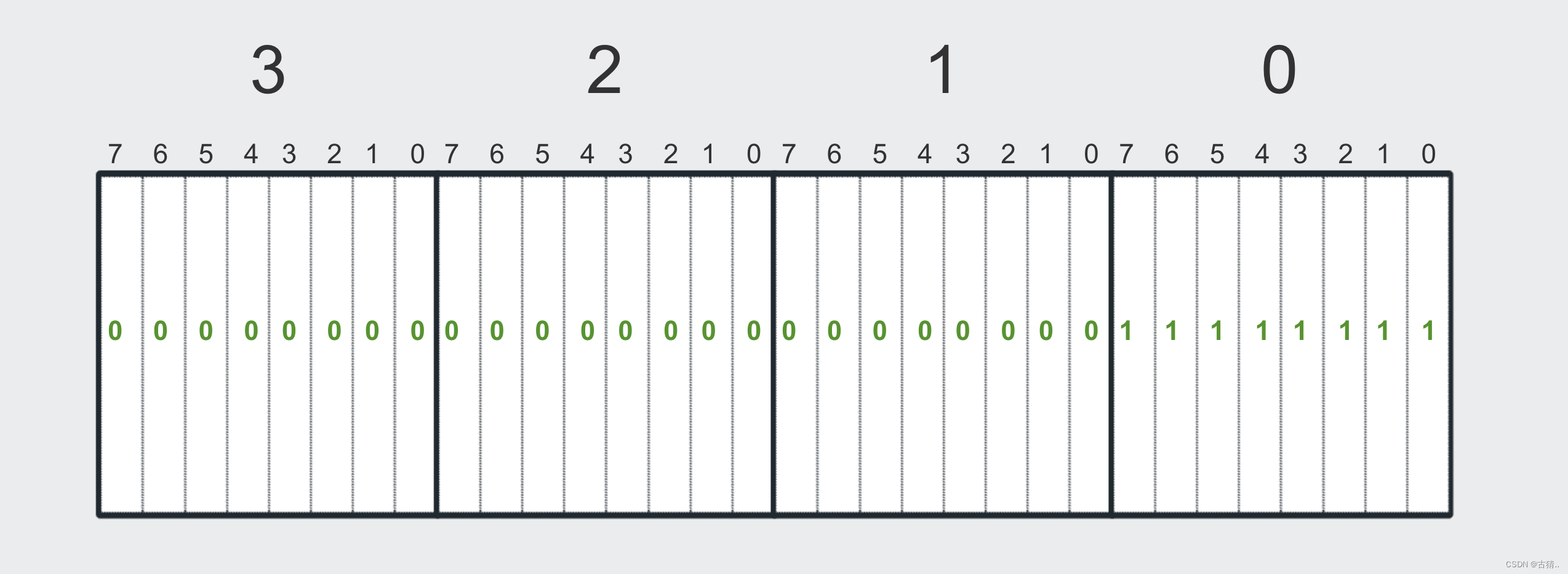
如果有一个十进制数 255 我们该如何表示:
十进制 255 对应 二进制 11111111 11111111 11111111 11111111
如果有一个十进制数 256 我们该如何表示:
十进制 256 对应 二进制 10000000 00000000 00000000 00000000
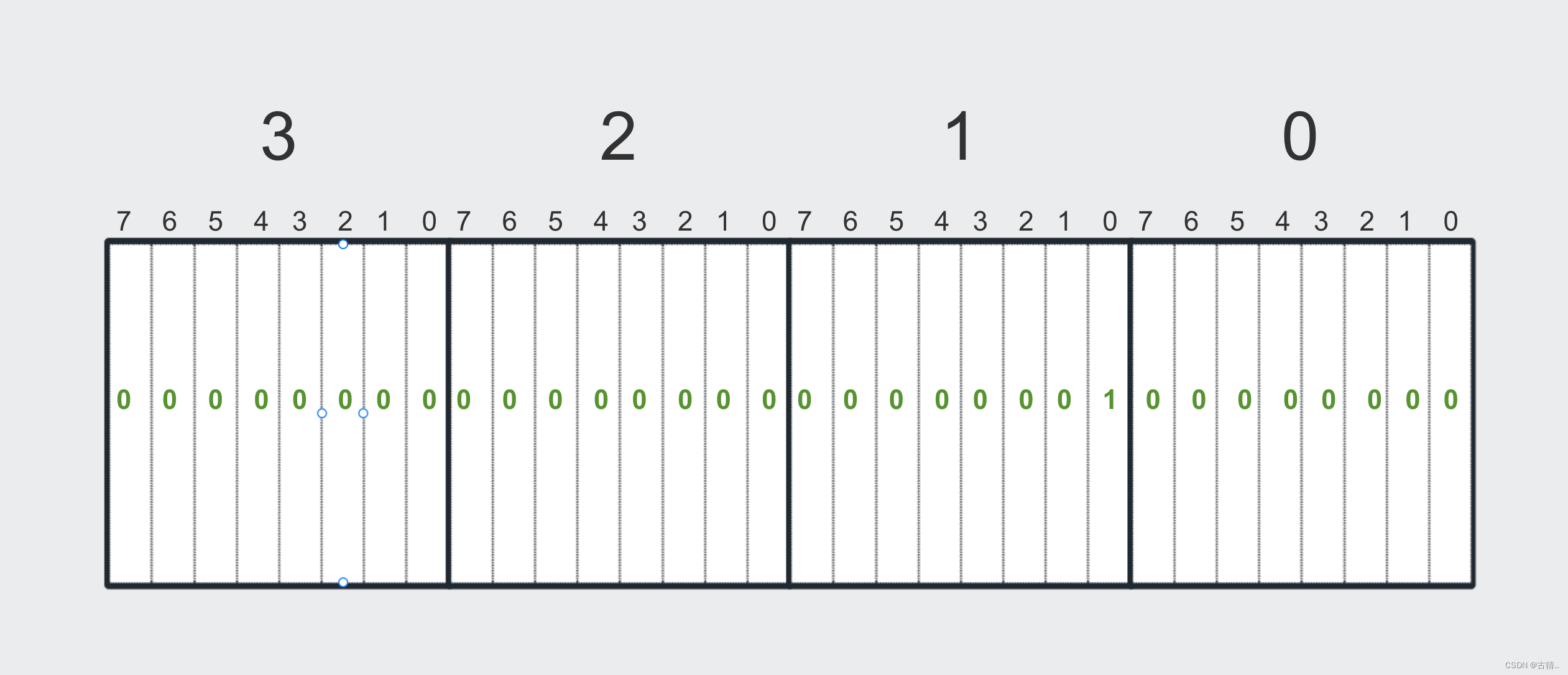
首先,最小存储单位是 比特,但是由于计算机的设计原因,我们能操作的最小单位是 字节(8比特)。
所以由上面的几个图可以发现:
当数值小于等于 255 时,我们仅需要一个字节就可以表示了,足足浪费了三个字节的空间
当数值大于255小于等于65535时,我们需要两个字节就能表示了,浪费了一半的空间(也就是浪费了两个字节)
当数值大于65535小于等于16777215时,我们需要三个字节,浪费了一个字节的空间
当数值大于16777215小于等于4294967295时,我们需要四个字节,刚好用完
但是,在大多是情况下,我们接触到的数值是偏小的,所以我们其实浪费了太多的空间,这时候我们就想要在保证数据正确的情况下能否压缩使用空间。这就出现了 Varint编码 可以查看我的上一篇博客的第五点。
三、使用Varint编码
假如有一个数值 300
普通的内存图:
现在我们来使用Varint编码:
操作图示(此图建议放大后仔细观看):
再说一遍!此图很很很很很很很很很很很很很很很很很很很很很很很很很很很很很很重要!!!
看懂此图就好比你悟了!
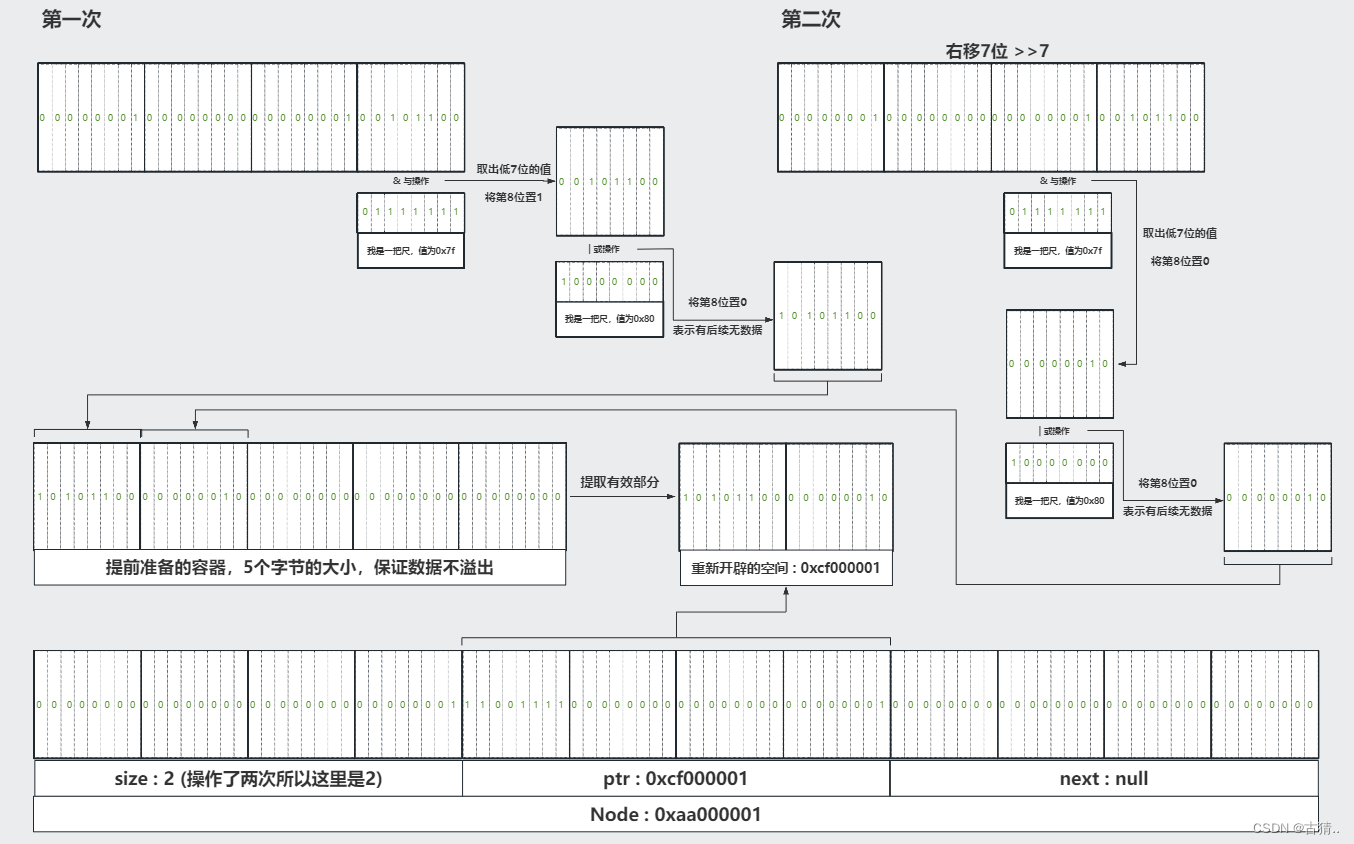
由上图我们可以看到,我们将 300 这个十进制数进行了编码
int32_t 类型 300 的二进制表示是: 00000000 00000000 00000001 00000000
通过编码后变成了: 10101100 00000010
由于这只是一个基本数据 int32_t 的编码流程,在实际开发中我们肯定是对一系列或者一组数据进行编码,
所以为了更好的管理这些单个的编码,将他们组装起来。我们需要用一个容器来存放这一组编码。
我们可以使用数组,但是数组是固定长度的,当数据超过长度时需要重新开辟更大的空间来存放,而且会有拷贝的操作。
所以这里使用链表结构来存放,这样可以不用考虑扩容的问题。
所以这里将单个的编码结果用了一个链表节点Node来管理。之后我们处理一组数据的时候就可以通过链表操作来关联各个单体之间的联系。
这里我们先不考虑如何管理一组数据(管理各个链表节点)的操作,我们继续来看 Varint编码 会带来的问题。
四、Varint 编码的问题
根据上述的分析,仿佛Varint编码非常完美,没有什么问题,成功的减少了内存的使用。
但是还有一种情况我们没有考虑,那就是负数的情况。
由于正负在计算机中是通过最高位的值决定的 最高位为0表示正数,最高位为1表示负数。
在最高位为1时,就没法进行压缩了,反而 Varint 编码 需要额外的添加一位来表示是否有后续,而计算机会因为这一位的需要,而开辟一个字节(8位)来存放这个标记。这样一来我们的压缩就变成了膨胀了。
如果上述描述不够清楚,我们来看下以下的图:
当前有一个十进制数: -1073741824
看到以下图后你会发现 卧槽 不减反增!!!虽然这种大的数值并不常见,但是这违背了我们的初心,我们需要处理掉他。

出现上述问题的根本原因就是:负数的最高位是1,无法被省略,所以要想办法把最高位的1去掉。
五、Zigzag 编码
这个编码可以查看我的上一篇博客,Zigzag编码 简单来说就是:
1.如果是正数n 那么转换公式是 z = 2n 例如 1 -> 2 * 1 = 2
2.如果是负数n 那么转换公式是 z = 2|n|-1 例如 -2 -> 2 * |-2| -1 = 3
这样一来就不会存在负数了,也就是最高位必定不会是1,这样我们的 Varint编码 就又有了价值。
无非就是要先进行 Zigzag编码 再进行 Varint 编码。
六、编码相关的核心代码
EncodeZigzag32
static uint32_t EncodeZigzag32(const int32_t& v) {
if(v < 0) {
//如果是负数n 那么转换公式是 z = 2|n|-1 例如 -2 -> 2 * |-2| -1 = 3
return ((uint32_t)(-v)) * 2 - 1;
} else {
//如果是正数n 那么转换公式是 z = 2n 例如 1 -> 2 * 1 = 2
return v * 2;
}
}
DecodeZigzag32
static int32_t DecodeZigzag32(const uint32_t& v) {
return (v >> 1) ^ -(v & 1);
}
writeUint32
void ByteArray::writeUint32 (uint32_t value) {
//定义临时空间用于存储编码后的值
//由于一个字节是8个比特,所以这里用 uint8_t 类型
//因为 uint32_t 有32个比特也就是4个字节,当用Varint编码时需要每7位添加一个是否有后续的标记位
//所以多给一个字节用于存放大值情况下多出来的标记位
uint8_t tmp[5];
//定义一个按字节大小的偏移量
uint8_t i = 0;
//判断这个值是否大于等于 10000000
//如果小于证明没有后续
while(value >= 0x80) {
//value & 0x7F 就是提取将当前这个字节中的低7位的值
// | 0x80 就是将当前这个字节中的最高位设置为 1 ,也就是表示有后续
tmp[i++] = (value & 0x7F) | 0x80;
//将值右移7位,准备下一步的编码
value >>= 7;
}
//将编码后的值存放到临时变量中对应偏移的一个字节空间里
tmp[i++] = value;
write(tmp, i);
}
readUint32
//这就是 writeUint32 的反推,今天累了,不写了
uint32_t ByteArray::readUint32() {
uint32_t result = 0;
for(int i = 0; i < 32; i += 7) {
uint8_t b = readFuint8();
if(b < 0x80) {
result |= ((uint32_t)b) << i;
break;
} else {
result |= (((uint32_t)(b & 0x7f)) << i);
}
}
return result;
}
七、Node节点的管理
在这之前,我们聊得都是关于一个节点内的东西,当然那是最核心的。
接下来我们要聊的是如何管理一系列的节点。
节点管理其实是比较简单的,首先我们管理的是一个单向链表,我们要做的就是封装链表的操作,暴露出去的是一种连续内存地址的表象。这听上去有点不好理解,我们直接看核心代码。
以下三段代码是最核心的节点管理部分的代码,看懂之后再去看其他部分的代码会豁然开朗。
扩容方法
//扩容 传入想要扩张的大小
void ByteArray::addCapacity(size_t size) {
//如果指定容量是0,则不处理
if(size == 0) {
return;
}
//获取还能写入的容量
size_t old_cap = getCapacity();
//如果容量够用,则不扩容处理
if(old_cap >= size) {
return;
}
//当前实际需要追加的大小 = 想要追加的大小 - 当前可用的大小
size = size - old_cap;
//需要追加的内存块数量 = 当前实际需要追加的大小 / 每个基本内存块的大小
//这里的 1.0 * size 为了隐式转换为小数类型
//向上取整,确保内存块数量足够
size_t count = ceil(1.0 * size / m_baseSize);
//用临时指针指向根节点 准备开始遍历链表
Node* tmp = m_root;
//遍历链表,最终将临时指针 tmp 指向最后一个节点
while(tmp->next) {
tmp = tmp->next;
}
//定义要追加的起始节点指针
Node* first = NULL;
//循环要增加的节点个数 准备添加新节点
for(size_t i = 0; i < count; ++i) {
//将新创建的节点依次向后追加
tmp->next = new Node(m_baseSize);
//并且记录下开始追加的首节点
if(first == NULL) {
first = tmp->next;
}
//将临时指针指向被添加的节点,以便下一个循环继续追加
tmp = tmp->next;
//将当前总容量重新计算,算上新追加的节点尺寸
m_capacity += m_baseSize;
}
//这里特殊判断,如果原容器没有可用容量
//那么其当前操作的内存块指针将是null
//当我们扩容后应该要将当前操作的内存块指针指向 首个追加的节点上
if(old_cap == 0) {
m_cur = first;
}
}
write方法
//将编码后的数据写入到指定内存中
void ByteArray::write(const void* buf, size_t size) {
//0就是在搞笑,直接不处理
if(size == 0) {
return;
}
//做一下扩容处理,避免空间不足
addCapacity(size);
//当前开始写的相对位置 = 当前位置 % 每个基本内存块的大小
size_t npos = m_position % m_baseSize;
//当前的容量 = 当前操作节点数据内存块大小 - 当前写的起始下标
size_t ncap = m_cur->size - npos;
//
size_t bpos = 0;
//开始遍历需要写入的尺寸
while(size > 0) {
if(ncap >= size) {
//如果容量足够
//拷贝内存 将当前操作节点的数据起始地址+当前开始写的偏移
//拷贝到当前要写入的地址
memcpy(m_cur->ptr + npos, (const char*)buf + bpos, size);
//如果当前节点刚好写完
if(m_cur->size == (npos + size)) {
//那么将当前节点向后偏移
m_cur = m_cur->next;
}
//将偏移地址修改
m_position += size;
//其实这一个++是没有必要的,不过逻辑上是要这样操作一下
bpos += size;
//跳出循环
size = 0;
} else {
//如果容量不够,那么就将当前节点的可用容量全部使用
memcpy(m_cur->ptr + npos, (const char*)buf + bpos, ncap);
//偏移就是增加当前节点可用容量大小
m_position += ncap;
//buf的偏移增加值就是当前可用容量大小
bpos += ncap;
//计算剩余要拷贝的尺寸
size -= ncap;
//将节点向后偏移(因为当前节点的所有容量已经用完)
m_cur = m_cur->next;
//新的可用容量大小就是下一个节点的容量大小
ncap = m_cur->size;
//新的相对偏移就是下个节点的起始位置
npos = 0;
}
}
//循环结束后,判断总偏移是否大于当前总数据的尺寸记录
if(m_position > m_size) {
//将当前数据尺寸的记录更新为当前的总偏移
m_size = m_position;
}
}
read方法
void ByteArray::read(void* buf, size_t size) {
//判断要读的尺寸是否大于可读的尺寸
if(size > getReadSize()) {
throw std::out_of_range("not enough len");
}
//计算得到当前节点的相对偏移值
size_t npos = m_position % m_baseSize;
//计算得到当前节点的可读容量
size_t ncap = m_cur->size - npos;
//设置buf的偏移为0
size_t bpos = 0;
//开始循环读操作,直到想读的尺寸为0
while(size > 0) {
if(ncap >= size) {
//如果当前节点的可读容量大于等于想读的尺寸
//那么从当前节点数据偏移处开始,将想读的尺寸全部读取到buf中
memcpy((char*)buf + bpos, m_cur->ptr + npos, size);
//如果当前节点的总容量刚好等于当前节点偏移量+想读尺寸,也就是刚好读完这一个节点的内容
if(m_cur->size == (npos + size)) {
//那么将当前节点指针后移(因为当前节点刚好读完了)
m_cur = m_cur->next;
}
//重新计算总偏移量
m_position += size;
//计算buf偏移量(其实这里要不要都行,写上的画在逻辑上会更合理)
bpos += size;
//跳出循环
size = 0;
} else {
//如果当前节点的可读容量不足,那么就将当前节点的内容全部读完
memcpy((char*)buf + bpos, m_cur->ptr + npos, ncap);
//计算总偏移就是加上当前节点的可读容量
m_position += ncap;
//将buf的偏移重新计算,也就是加上当前可读容量的大小
bpos += ncap;
//重新计算想读的尺寸,也就是原来想读的尺寸-当前节点的可读容量
size -= ncap;
//当前节点后移,因为当前节点已经读取完毕
m_cur = m_cur->next;
//当前节点的可读容量就是当前节点的总容量
ncap = m_cur->size;
//将节点的偏移重置,因为这里刚好是新的节点的开始
npos = 0;
}
}
}
八、广告
QQ交流群:957100923
九、全部代码
这里部分代码来自 zhongluqiang 这里表示感谢!不过 .cc文件中的注释更加重要。
bytearray.h
#ifndef __SYLAR_BYTEARRAY_H__
#define __SYLAR_BYTEARRAY_H__
#include <memory>
#include <string>
#include <stdint.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <vector>
namespace sylar {
/**
* @brief 二进制数组,提供基础类型的序列化,反序列化功能
*/
class ByteArray {
public:
typedef std::shared_ptr<ByteArray> ptr;
/**
* @brief ByteArray的存储节点
*/
struct Node {
/**
* @brief 构造指定大小的内存块
* @param[in] s 内存块字节数
*/
Node(size_t s);
/**
* 无参构造函数
*/
Node();
/**
* 析构函数,释放内存
*/
~Node();
/// 内存块地址指针
char* ptr;
/// 下一个内存块地址
Node* next;
/// 内存块大小
size_t size;
};
/**
* @brief 使用指定长度的内存块构造ByteArray
* @param[in] base_size 内存块大小
*/
ByteArray(size_t base_size = 4096);
/**
* @brief 析构函数
*/
~ByteArray();
/**
* @brief 写入固定长度int8_t类型的数据
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFint8 (int8_t value);
/**
* @brief 写入固定长度uint8_t类型的数据
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFuint8 (uint8_t value);
/**
* @brief 写入固定长度int16_t类型的数据(大端/小端)
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFint16 (int16_t value);
/**
* @brief 写入固定长度uint16_t类型的数据(大端/小端)
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFuint16(uint16_t value);
/**
* @brief 写入固定长度int32_t类型的数据(大端/小端)
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFint32 (int32_t value);
/**
* @brief 写入固定长度uint32_t类型的数据(大端/小端)
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFuint32(uint32_t value);
/**
* @brief 写入固定长度int64_t类型的数据(大端/小端)
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFint64 (int64_t value);
/**
* @brief 写入固定长度uint64_t类型的数据(大端/小端)
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFuint64(uint64_t value);
/**
* @brief 写入有符号Varint32类型的数据
* @post m_position += 实际占用内存(1 ~ 5)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeInt32 (int32_t value);
/**
* @brief 写入无符号Varint32类型的数据
* @post m_position += 实际占用内存(1 ~ 5)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeUint32 (uint32_t value);
/**
* @brief 写入有符号Varint64类型的数据
* @post m_position += 实际占用内存(1 ~ 10)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeInt64 (int64_t value);
/**
* @brief 写入无符号Varint64类型的数据
* @post m_position += 实际占用内存(1 ~ 10)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeUint64 (uint64_t value);
/**
* @brief 写入float类型的数据
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeFloat (float value);
/**
* @brief 写入double类型的数据
* @post m_position += sizeof(value)
* 如果m_position > m_size 则 m_size = m_position
*/
void writeDouble (double value);
/**
* @brief 写入std::string类型的数据,用uint16_t作为长度类型
* @post m_position += 2 + value.size()
* 如果m_position > m_size 则 m_size = m_position
*/
void writeStringF16(const std::string& value);
/**
* @brief 写入std::string类型的数据,用uint32_t作为长度类型
* @post m_position += 4 + value.size()
* 如果m_position > m_size 则 m_size = m_position
*/
void writeStringF32(const std::string& value);
/**
* @brief 写入std::string类型的数据,用uint64_t作为长度类型
* @post m_position += 8 + value.size()
* 如果m_position > m_size 则 m_size = m_position
*/
void writeStringF64(const std::string& value);
/**
* @brief 写入std::string类型的数据,用无符号Varint64作为长度类型
* @post m_position += Varint64长度 + value.size()
* 如果m_position > m_size 则 m_size = m_position
*/
void writeStringVint(const std::string& value);
/**
* @brief 写入std::string类型的数据,无长度
* @post m_position += value.size()
* 如果m_position > m_size 则 m_size = m_position
*/
void writeStringWithoutLength(const std::string& value);
/**
* @brief 读取int8_t类型的数据
* @pre getReadSize() >= sizeof(int8_t)
* @post m_position += sizeof(int8_t);
* @exception 如果getReadSize() < sizeof(int8_t) 抛出 std::out_of_range
*/
int8_t readFint8();
/**
* @brief 读取uint8_t类型的数据
* @pre getReadSize() >= sizeof(uint8_t)
* @post m_position += sizeof(uint8_t);
* @exception 如果getReadSize() < sizeof(uint8_t) 抛出 std::out_of_range
*/
uint8_t readFuint8();
/**
* @brief 读取int16_t类型的数据
* @pre getReadSize() >= sizeof(int16_t)
* @post m_position += sizeof(int16_t);
* @exception 如果getReadSize() < sizeof(int16_t) 抛出 std::out_of_range
*/
int16_t readFint16();
/**
* @brief 读取uint16_t类型的数据
* @pre getReadSize() >= sizeof(uint16_t)
* @post m_position += sizeof(uint16_t);
* @exception 如果getReadSize() < sizeof(uint16_t) 抛出 std::out_of_range
*/
uint16_t readFuint16();
/**
* @brief 读取int32_t类型的数据
* @pre getReadSize() >= sizeof(int32_t)
* @post m_position += sizeof(int32_t);
* @exception 如果getReadSize() < sizeof(int32_t) 抛出 std::out_of_range
*/
int32_t readFint32();
/**
* @brief 读取uint32_t类型的数据
* @pre getReadSize() >= sizeof(uint32_t)
* @post m_position += sizeof(uint32_t);
* @exception 如果getReadSize() < sizeof(uint32_t) 抛出 std::out_of_range
*/
uint32_t readFuint32();
/**
* @brief 读取int64_t类型的数据
* @pre getReadSize() >= sizeof(int64_t)
* @post m_position += sizeof(int64_t);
* @exception 如果getReadSize() < sizeof(int64_t) 抛出 std::out_of_range
*/
int64_t readFint64();
/**
* @brief 读取uint64_t类型的数据
* @pre getReadSize() >= sizeof(uint64_t)
* @post m_position += sizeof(uint64_t);
* @exception 如果getReadSize() < sizeof(uint64_t) 抛出 std::out_of_range
*/
uint64_t readFuint64();
/**
* @brief 读取有符号Varint32类型的数据
* @pre getReadSize() >= 有符号Varint32实际占用内存
* @post m_position += 有符号Varint32实际占用内存
* @exception 如果getReadSize() < 有符号Varint32实际占用内存 抛出 std::out_of_range
*/
int32_t readInt32();
/**
* @brief 读取无符号Varint32类型的数据
* @pre getReadSize() >= 无符号Varint32实际占用内存
* @post m_position += 无符号Varint32实际占用内存
* @exception 如果getReadSize() < 无符号Varint32实际占用内存 抛出 std::out_of_range
*/
uint32_t readUint32();
/**
* @brief 读取有符号Varint64类型的数据
* @pre getReadSize() >= 有符号Varint64实际占用内存
* @post m_position += 有符号Varint64实际占用内存
* @exception 如果getReadSize() < 有符号Varint64实际占用内存 抛出 std::out_of_range
*/
int64_t readInt64();
/**
* @brief 读取无符号Varint64类型的数据
* @pre getReadSize() >= 无符号Varint64实际占用内存
* @post m_position += 无符号Varint64实际占用内存
* @exception 如果getReadSize() < 无符号Varint64实际占用内存 抛出 std::out_of_range
*/
uint64_t readUint64();
/**
* @brief 读取float类型的数据
* @pre getReadSize() >= sizeof(float)
* @post m_position += sizeof(float);
* @exception 如果getReadSize() < sizeof(float) 抛出 std::out_of_range
*/
float readFloat();
/**
* @brief 读取double类型的数据
* @pre getReadSize() >= sizeof(double)
* @post m_position += sizeof(double);
* @exception 如果getReadSize() < sizeof(double) 抛出 std::out_of_range
*/
double readDouble();
/**
* @brief 读取std::string类型的数据,用uint16_t作为长度
* @pre getReadSize() >= sizeof(uint16_t) + size
* @post m_position += sizeof(uint16_t) + size;
* @exception 如果getReadSize() < sizeof(uint16_t) + size 抛出 std::out_of_range
*/
std::string readStringF16();
/**
* @brief 读取std::string类型的数据,用uint32_t作为长度
* @pre getReadSize() >= sizeof(uint32_t) + size
* @post m_position += sizeof(uint32_t) + size;
* @exception 如果getReadSize() < sizeof(uint32_t) + size 抛出 std::out_of_range
*/
std::string readStringF32();
/**
* @brief 读取std::string类型的数据,用uint64_t作为长度
* @pre getReadSize() >= sizeof(uint64_t) + size
* @post m_position += sizeof(uint64_t) + size;
* @exception 如果getReadSize() < sizeof(uint64_t) + size 抛出 std::out_of_range
*/
std::string readStringF64();
/**
* @brief 读取std::string类型的数据,用无符号Varint64作为长度
* @pre getReadSize() >= 无符号Varint64实际大小 + size
* @post m_position += 无符号Varint64实际大小 + size;
* @exception 如果getReadSize() < 无符号Varint64实际大小 + size 抛出 std::out_of_range
*/
std::string readStringVint();
/**
* @brief 清空ByteArray
* @post m_position = 0, m_size = 0
*/
void clear();
/**
* @brief 写入size长度的数据
* @param[in] buf 内存缓存指针
* @param[in] size 数据大小
* @post m_position += size, 如果m_position > m_size 则 m_size = m_position
*/
void write(const void* buf, size_t size);
/**
* @brief 读取size长度的数据
* @param[out] buf 内存缓存指针
* @param[in] size 数据大小
* @post m_position += size, 如果m_position > m_size 则 m_size = m_position
* @exception 如果getReadSize() < size 则抛出 std::out_of_range
*/
void read(void* buf, size_t size);
/**
* @brief 读取size长度的数据
* @param[out] buf 内存缓存指针
* @param[in] size 数据大小
* @param[in] position 读取开始位置
* @exception 如果 (m_size - position) < size 则抛出 std::out_of_range
*/
void read(void* buf, size_t size, size_t position) const;
/**
* @brief 返回ByteArray当前位置
*/
size_t getPosition() const { return m_position;}
/**
* @brief 设置ByteArray当前位置
* @post 如果m_position > m_size 则 m_size = m_position
* @exception 如果m_position > m_capacity 则抛出 std::out_of_range
*/
void setPosition(size_t v);
/**
* @brief 把ByteArray的数据写入到文件中
* @param[in] name 文件名
*/
bool writeToFile(const std::string& name) const;
/**
* @brief 从文件中读取数据
* @param[in] name 文件名
*/
bool readFromFile(const std::string& name);
/**
* @brief 返回内存块的大小
*/
size_t getBaseSize() const { return m_baseSize;}
/**
* @brief 返回可读取数据大小
*/
size_t getReadSize() const { return m_size - m_position;}
/**
* @brief 是否是小端
*/
bool isLittleEndian() const;
/**
* @brief 设置是否为小端
*/
void setIsLittleEndian(bool val);
/**
* @brief 将ByteArray里面的数据[m_position, m_size)转成std::string
*/
std::string toString() const;
/**
* @brief 将ByteArray里面的数据[m_position, m_size)转成16进制的std::string(格式:FF FF FF)
*/
std::string toHexString() const;
/**
* @brief 获取可读取的缓存,保存成iovec数组
* @param[out] buffers 保存可读取数据的iovec数组
* @param[in] len 读取数据的长度,如果len > getReadSize() 则 len = getReadSize()
* @return 返回实际数据的长度
*/
uint64_t getReadBuffers(std::vector<iovec>& buffers, uint64_t len = ~0ull) const;
/**
* @brief 获取可读取的缓存,保存成iovec数组,从position位置开始
* @param[out] buffers 保存可读取数据的iovec数组
* @param[in] len 读取数据的长度,如果len > getReadSize() 则 len = getReadSize()
* @param[in] position 读取数据的位置
* @return 返回实际数据的长度
*/
uint64_t getReadBuffers(std::vector<iovec>& buffers, uint64_t len, uint64_t position) const;
/**
* @brief 获取可写入的缓存,保存成iovec数组
* @param[out] buffers 保存可写入的内存的iovec数组
* @param[in] len 写入的长度
* @return 返回实际的长度
* @post 如果(m_position + len) > m_capacity 则 m_capacity扩容N个节点以容纳len长度
*/
uint64_t getWriteBuffers(std::vector<iovec>& buffers, uint64_t len);
/**
* @brief 返回数据的长度
*/
size_t getSize() const { return m_size;}
private:
/**
* @brief 扩容ByteArray,使其可以容纳size个数据(如果原本可以可以容纳,则不扩容)
*/
void addCapacity(size_t size);
/**
* @brief 获取当前的可写入容量
*/
size_t getCapacity() const { return m_capacity - m_position;}
private:
/// 内存块的大小
size_t m_baseSize;
/// 当前操作位置
size_t m_position;
/// 当前的总容量
size_t m_capacity;
/// 当前数据的大小
size_t m_size;
/// 字节序,默认大端
int8_t m_endian;
/// 第一个内存块指针
Node* m_root;
/// 当前操作的内存块指针
Node* m_cur;
};
}
#endif
bytearray.cc
#include "bytearray.h"
#include <fstream>
#include <sstream>
#include <string.h>
#include <iomanip>
#include <cmath>
#include "endian.h"
#include "log.h"
namespace sylar {
static sylar::Logger::ptr g_logger = SYLAR_LOG_NAME("system");
ByteArray::Node::Node(size_t s)
:ptr(new char[s])
,next(nullptr)
,size(s) {
}
ByteArray::Node::Node()
:ptr(nullptr)
,next(nullptr)
,size(0) {
}
ByteArray::Node::~Node() {
if(ptr) {
delete[] ptr;
}
}
ByteArray::ByteArray(size_t base_size)
:m_baseSize(base_size)
,m_position(0)
,m_capacity(base_size)
,m_size(0)
,m_endian(SYLAR_BIG_ENDIAN)
,m_root(new Node(base_size))
,m_cur(m_root) {
}
ByteArray::~ByteArray() {
Node* tmp = m_root;
while(tmp) {
m_cur = tmp;
tmp = tmp->next;
delete m_cur;
}
}
bool ByteArray::isLittleEndian() const {
return m_endian == SYLAR_LITTLE_ENDIAN;
}
void ByteArray::setIsLittleEndian(bool val) {
if(val) {
m_endian = SYLAR_LITTLE_ENDIAN;
} else {
m_endian = SYLAR_BIG_ENDIAN;
}
}
void ByteArray::writeFint8 (int8_t value) {
write(&value, sizeof(value));
}
void ByteArray::writeFuint8 (uint8_t value) {
write(&value, sizeof(value));
}
void ByteArray::writeFint16 (int16_t value) {
if(m_endian != SYLAR_BYTE_ORDER) {
value = byteswap(value);
}
write(&value, sizeof(value));
}
void ByteArray::writeFuint16(uint16_t value) {
if(m_endian != SYLAR_BYTE_ORDER) {
value = byteswap(value);
}
write(&value, sizeof(value));
}
void ByteArray::writeFint32 (int32_t value) {
if(m_endian != SYLAR_BYTE_ORDER) {
value = byteswap(value);
}
write(&value, sizeof(value));
}
void ByteArray::writeFuint32(uint32_t value) {
if(m_endian != SYLAR_BYTE_ORDER) {
value = byteswap(value);
}
write(&value, sizeof(value));
}
void ByteArray::writeFint64 (int64_t value) {
if(m_endian != SYLAR_BYTE_ORDER) {
value = byteswap(value);
}
write(&value, sizeof(value));
}
void ByteArray::writeFuint64(uint64_t value) {
if(m_endian != SYLAR_BYTE_ORDER) {
value = byteswap(value);
}
write(&value, sizeof(value));
}
static uint32_t EncodeZigzag32(const int32_t& v) {
if(v < 0) {
return ((uint32_t)(-v)) * 2 - 1;
} else {
return v * 2;
}
}
static uint64_t EncodeZigzag64(const int64_t& v) {
if(v < 0) {
return ((uint64_t)(-v)) * 2 - 1;
} else {
return v * 2;
}
}
static int32_t DecodeZigzag32(const uint32_t& v) {
return (v >> 1) ^ -(v & 1);
}
static int64_t DecodeZigzag64(const uint64_t& v) {
return (v >> 1) ^ -(v & 1);
}
void ByteArray::writeInt32 (int32_t value) {
writeUint32(EncodeZigzag32(value));
}
void ByteArray::writeUint32 (uint32_t value) {
uint8_t tmp[5];
uint8_t i = 0;
while(value >= 0x80) {
tmp[i++] = (value & 0x7F) | 0x80;
value >>= 7;
}
tmp[i++] = value;
write(tmp, i);
}
void ByteArray::writeInt64 (int64_t value) {
writeUint64(EncodeZigzag64(value));
}
void ByteArray::writeUint64 (uint64_t value) {
uint8_t tmp[10];
uint8_t i = 0;
while(value >= 0x80) {
tmp[i++] = (value & 0x7F) | 0x80;
value >>= 7;
}
tmp[i++] = value;
write(tmp, i);
}
void ByteArray::writeFloat (float value) {
uint32_t v;
memcpy(&v, &value, sizeof(value));
writeFuint32(v);
}
void ByteArray::writeDouble (double value) {
uint64_t v;
memcpy(&v, &value, sizeof(value));
writeFuint64(v);
}
void ByteArray::writeStringF16(const std::string& value) {
writeFuint16(value.size());
write(value.c_str(), value.size());
}
void ByteArray::writeStringF32(const std::string& value) {
writeFuint32(value.size());
write(value.c_str(), value.size());
}
void ByteArray::writeStringF64(const std::string& value) {
writeFuint64(value.size());
write(value.c_str(), value.size());
}
void ByteArray::writeStringVint(const std::string& value) {
writeUint64(value.size());
write(value.c_str(), value.size());
}
void ByteArray::writeStringWithoutLength(const std::string& value) {
write(value.c_str(), value.size());
}
int8_t ByteArray::readFint8() {
int8_t v;
read(&v, sizeof(v));
return v;
}
uint8_t ByteArray::readFuint8() {
uint8_t v;
read(&v, sizeof(v));
return v;
}
#define XX(type) \
type v; \
read(&v, sizeof(v)); \
if(m_endian == SYLAR_BYTE_ORDER) { \
return v; \
} else { \
return byteswap(v); \
}
int16_t ByteArray::readFint16() {
XX(int16_t);
}
uint16_t ByteArray::readFuint16() {
XX(uint16_t);
}
int32_t ByteArray::readFint32() {
XX(int32_t);
}
uint32_t ByteArray::readFuint32() {
XX(uint32_t);
}
int64_t ByteArray::readFint64() {
XX(int64_t);
}
uint64_t ByteArray::readFuint64() {
XX(uint64_t);
}
#undef XX
int32_t ByteArray::readInt32() {
return DecodeZigzag32(readUint32());
}
uint32_t ByteArray::readUint32() {
uint32_t result = 0;
for(int i = 0; i < 32; i += 7) {
uint8_t b = readFuint8();
if(b < 0x80) {
result |= ((uint32_t)b) << i;
break;
} else {
result |= (((uint32_t)(b & 0x7f)) << i);
}
}
return result;
}
int64_t ByteArray::readInt64() {
return DecodeZigzag64(readUint64());
}
uint64_t ByteArray::readUint64() {
uint64_t result = 0;
for(int i = 0; i < 64; i += 7) {
uint8_t b = readFuint8();
if(b < 0x80) {
result |= ((uint64_t)b) << i;
break;
} else {
result |= (((uint64_t)(b & 0x7f)) << i);
}
}
return result;
}
float ByteArray::readFloat() {
uint32_t v = readFuint32();
float value;
memcpy(&value, &v, sizeof(v));
return value;
}
double ByteArray::readDouble() {
uint64_t v = readFuint64();
double value;
memcpy(&value, &v, sizeof(v));
return value;
}
std::string ByteArray::readStringF16() {
uint16_t len = readFuint16();
std::string buff;
buff.resize(len);
read(&buff[0], len);
return buff;
}
std::string ByteArray::readStringF32() {
uint32_t len = readFuint32();
std::string buff;
buff.resize(len);
read(&buff[0], len);
return buff;
}
std::string ByteArray::readStringF64() {
uint64_t len = readFuint64();
std::string buff;
buff.resize(len);
read(&buff[0], len);
return buff;
}
std::string ByteArray::readStringVint() {
uint64_t len = readUint64();
std::string buff;
buff.resize(len);
read(&buff[0], len);
return buff;
}
void ByteArray::clear() {
m_position = m_size = 0;
m_capacity = m_baseSize;
Node* tmp = m_root->next;
while(tmp) {
m_cur = tmp;
tmp = tmp->next;
delete m_cur;
}
m_cur = m_root;
m_root->next = NULL;
}
//将编码后的数据写入到指定内存中
void ByteArray::write(const void* buf, size_t size) {
//0就是在搞笑,直接不处理
if(size == 0) {
return;
}
//做一下扩容处理,避免空间不足
addCapacity(size);
//当前开始写的相对位置 = 当前位置 % 每个基本内存块的大小
size_t npos = m_position % m_baseSize;
//当前的容量 = 当前操作节点数据内存块大小 - 当前写的起始下标
size_t ncap = m_cur->size - npos;
//
size_t bpos = 0;
//开始遍历需要写入的尺寸
while(size > 0) {
if(ncap >= size) {
//如果容量足够
//拷贝内存 将当前操作节点的数据起始地址+当前开始写的偏移
//拷贝到当前要写入的地址
memcpy(m_cur->ptr + npos, (const char*)buf + bpos, size);
//如果当前节点刚好写完
if(m_cur->size == (npos + size)) {
//那么将当前节点向后偏移
m_cur = m_cur->next;
}
//将偏移地址修改
m_position += size;
//其实这一个++是没有必要的,不过逻辑上是要这样操作一下
bpos += size;
//跳出循环
size = 0;
} else {
//如果容量不够,那么就将当前节点的可用容量全部使用
memcpy(m_cur->ptr + npos, (const char*)buf + bpos, ncap);
//偏移就是增加当前节点可用容量大小
m_position += ncap;
//buf的偏移增加值就是当前可用容量大小
bpos += ncap;
//计算剩余要拷贝的尺寸
size -= ncap;
//将节点向后偏移(因为当前节点的所有容量已经用完)
m_cur = m_cur->next;
//新的可用容量大小就是下一个节点的容量大小
ncap = m_cur->size;
//新的相对偏移就是下个节点的起始位置
npos = 0;
}
}
//循环结束后,判断总偏移是否大于当前总数据的尺寸记录
if(m_position > m_size) {
//将当前数据尺寸的记录更新为当前的总偏移
m_size = m_position;
}
}
//有副作用的读
void ByteArray::read(void* buf, size_t size) {
//判断要读的尺寸是否大于可读的尺寸
if(size > getReadSize()) {
throw std::out_of_range("not enough len");
}
//计算得到当前节点的相对偏移值
size_t npos = m_position % m_baseSize;
//计算得到当前节点的可读容量
size_t ncap = m_cur->size - npos;
//设置buf的偏移为0
size_t bpos = 0;
//开始循环读操作,直到想读的尺寸为0
while(size > 0) {
if(ncap >= size) {
//如果当前节点的可读容量大于等于想读的尺寸
//那么从当前节点数据偏移处开始,将想读的尺寸全部读取到buf中
memcpy((char*)buf + bpos, m_cur->ptr + npos, size);
//如果当前节点的总容量刚好等于当前节点偏移量+想读尺寸,也就是刚好读完这一个节点的内容
if(m_cur->size == (npos + size)) {
//那么将当前节点指针后移(因为当前节点刚好读完了)
m_cur = m_cur->next;
}
//重新计算总偏移量
m_position += size;
//计算buf偏移量(其实这里要不要都行,写上的画在逻辑上会更合理)
bpos += size;
//跳出循环
size = 0;
} else {
//如果当前节点的可读容量不足,那么就将当前节点的内容全部读完
memcpy((char*)buf + bpos, m_cur->ptr + npos, ncap);
//计算总偏移就是加上当前节点的可读容量
m_position += ncap;
//将buf的偏移重新计算,也就是加上当前可读容量的大小
bpos += ncap;
//重新计算想读的尺寸,也就是原来想读的尺寸-当前节点的可读容量
size -= ncap;
//当前节点后移,因为当前节点已经读取完毕
m_cur = m_cur->next;
//当前节点的可读容量就是当前节点的总容量
ncap = m_cur->size;
//将节点的偏移重置,因为这里刚好是新的节点的开始
npos = 0;
}
}
}
//没有副作用的读
void ByteArray::read(void* buf, size_t size, size_t position) const {
//判断想读尺寸是否大于可读容量
if(size > (m_size - position)) {
throw std::out_of_range("not enough len");
}
//计算得到当前节点的相对偏移值
size_t npos = position % m_baseSize;
//计算得到当前节点的可读容量
size_t ncap = m_cur->size - npos;
//设置buf的偏移为0
size_t bpos = 0;
//使用临时指针,防止副作用的产生
Node* cur = m_cur;
//开始循环读操作,直到想读的尺寸为0
while(size > 0) {
if(ncap >= size) {
//如果当前节点的可读容量大于等于想读的尺寸
//那么从当前节点数据偏移处开始,将想读的尺寸全部读取到buf中
memcpy((char*)buf + bpos, cur->ptr + npos, size);
//如果当前节点的总容量刚好等于当前节点偏移量+想读尺寸,也就是刚好读完这一个节点的内容
if(cur->size == (npos + size)) {
//那么将当前节点指针后移(因为当前节点刚好读完了)
cur = cur->next;
}
//重新计算总偏移量
position += size;
//计算buf偏移量(其实这里要不要都行,写上的画在逻辑上会更合理)
bpos += size;
//跳出循环
size = 0;
} else {
//如果当前节点的可读容量不足,那么就将当前节点的内容全部读完
memcpy((char*)buf + bpos, cur->ptr + npos, ncap);
//计算总偏移就是加上当前节点的可读容量
position += ncap;
//将buf的偏移重新计算,也就是加上当前可读容量的大小
bpos += ncap;
//重新计算想读的尺寸,也就是原来想读的尺寸-当前节点的可读容量
size -= ncap;
//当前节点后移,因为当前节点已经读取完毕
cur = cur->next;
//当前节点的可读容量就是当前节点的总容量
ncap = cur->size;
//将节点的偏移重置,因为这里刚好是新的节点的开始
npos = 0;
}
}
}
void ByteArray::setPosition(size_t v) {
if(v > m_capacity) {
throw std::out_of_range("set_position out of range");
}
m_position = v;
if(m_position > m_size) {
m_size = m_position;
}
m_cur = m_root;
while(v > m_cur->size) {
v -= m_cur->size;
m_cur = m_cur->next;
}
if(v == m_cur->size) {
m_cur = m_cur->next;
}
}
bool ByteArray::writeToFile(const std::string& name) const {
std::ofstream ofs;
ofs.open(name, std::ios::trunc | std::ios::binary);
if(!ofs) {
SYLAR_LOG_ERROR(g_logger) << "writeToFile name=" << name
<< " error , errno=" << errno << " errstr=" << strerror(errno);
return false;
}
int64_t read_size = getReadSize();
int64_t pos = m_position;
Node* cur = m_cur;
while(read_size > 0) {
int diff = pos % m_baseSize;
int64_t len = (read_size > (int64_t)m_baseSize ? m_baseSize : read_size) - diff;
ofs.write(cur->ptr + diff, len);
cur = cur->next;
pos += len;
read_size -= len;
}
return true;
}
bool ByteArray::readFromFile(const std::string& name) {
std::ifstream ifs;
ifs.open(name, std::ios::binary);
if(!ifs) {
SYLAR_LOG_ERROR(g_logger) << "readFromFile name=" << name
<< " error, errno=" << errno << " errstr=" << strerror(errno);
return false;
}
std::shared_ptr<char> buff(new char[m_baseSize], [](char* ptr) { delete[] ptr;});
while(!ifs.eof()) {
ifs.read(buff.get(), m_baseSize);
write(buff.get(), ifs.gcount());
}
return true;
}
//扩容 传入想要扩张的大小
void ByteArray::addCapacity(size_t size) {
//如果指定容量是0,则不处理
if(size == 0) {
return;
}
//获取还能写入的容量
size_t old_cap = getCapacity();
//如果容量够用,则不扩容处理
if(old_cap >= size) {
return;
}
//当前实际需要追加的大小 = 想要追加的大小 - 当前可用的大小
size = size - old_cap;
//需要追加的内存块数量 = 当前实际需要追加的大小 / 每个基本内存块的大小
//这里的 1.0 * size 为了隐式转换为小数类型
//向上取整,确保内存块数量足够
size_t count = ceil(1.0 * size / m_baseSize);
//用临时指针指向根节点 准备开始遍历链表
Node* tmp = m_root;
//遍历链表,最终将临时指针 tmp 指向最后一个节点
while(tmp->next) {
tmp = tmp->next;
}
//定义要追加的起始节点指针
Node* first = NULL;
//循环要增加的节点个数 准备添加新节点
for(size_t i = 0; i < count; ++i) {
//将新创建的节点依次向后追加
tmp->next = new Node(m_baseSize);
//并且记录下开始追加的首节点
if(first == NULL) {
first = tmp->next;
}
//将临时指针指向被添加的节点,以便下一个循环继续追加
tmp = tmp->next;
//将当前总容量重新计算,算上新追加的节点尺寸
m_capacity += m_baseSize;
}
//这里特殊判断,如果原容器没有可用容量
//那么其当前操作的内存块指针将是null
//当我们扩容后应该要将当前操作的内存块指针指向 首个追加的节点上
if(old_cap == 0) {
m_cur = first;
}
}
//将读取的数据转为字符串
std::string ByteArray::toString() const {
std::string str;
//初始化字符串的大小,也就是用可读尺寸来确定大小
str.resize(getReadSize());
//判空
if(str.empty()) {
return str;
}
//将内容从当前偏移处一直读取到结尾,全部存放到字符串中
read(&str[0], str.size(), m_position);
return str;
}
//将读取的数据以16进制字符串的形式展示
std::string ByteArray::toHexString() const {
std::string str = toString();
std::stringstream ss;
for(size_t i = 0; i < str.size(); ++i) {
if(i > 0 && i % 32 == 0) {
ss << std::endl;
}
ss << std::setw(2) << std::setfill('0') << std::hex
<< (int)(uint8_t)str[i] << " ";
}
return ss.str();
}
uint64_t ByteArray::getReadBuffers(std::vector<iovec>& buffers, uint64_t len) const {
len = len > getReadSize() ? getReadSize() : len;
if(len == 0) {
return 0;
}
uint64_t size = len;
size_t npos = m_position % m_baseSize;
size_t ncap = m_cur->size - npos;
//iovec是一个结构体,用于描述一个数据缓冲区。
// struct iovec {
// void *iov_base; // 缓冲区起始地址
// size_t iov_len; // 缓冲区长度
// };
struct iovec iov;
Node* cur = m_cur;
while(len > 0) {
if(ncap >= len) {
//如果当前容量大于等于想读长度
//那么缓冲区的起始位置就是当前节点的内容起始地址加上当前节点的相对偏移量
iov.iov_base = cur->ptr + npos;
//缓冲区的长度就是想读长度
iov.iov_len = len;
//跳出循环
len = 0;
} else {
//如果当前可读容量小于想读长度
//那么缓冲区的起始位置就是当前节点的内容起始地址加上当前节点的相对偏移量
iov.iov_base = cur->ptr + npos;
//缓冲区的长度就是当前可读容量大小
iov.iov_len = ncap;
//将想读长度减少
len -= ncap;
//当前节点指针后移,因为当前节点已经读完
cur = cur->next;
//当前可读容量重置为当前节点的总尺寸
ncap = cur->size;
//重置节点相对偏移量
npos = 0;
}
//将缓冲区依次保存到buffers中
buffers.push_back(iov);
}
return size;
}
//没有副作用的buffer读取
uint64_t ByteArray::getReadBuffers(std::vector<iovec>& buffers
,uint64_t len, uint64_t position) const {
len = len > getReadSize() ? getReadSize() : len;
if(len == 0) {
return 0;
}
uint64_t size = len;
size_t npos = position % m_baseSize;
size_t count = position / m_baseSize;
Node* cur = m_root;
while(count > 0) {
cur = cur->next;
--count;
}
size_t ncap = cur->size - npos;
struct iovec iov;
while(len > 0) {
if(ncap >= len) {
iov.iov_base = cur->ptr + npos;
iov.iov_len = len;
len = 0;
} else {
iov.iov_base = cur->ptr + npos;
iov.iov_len = ncap;
len -= ncap;
cur = cur->next;
ncap = cur->size;
npos = 0;
}
buffers.push_back(iov);
}
return size;
}
uint64_t ByteArray::getWriteBuffers(std::vector<iovec>& buffers, uint64_t len) {
if(len == 0) {
return 0;
}
addCapacity(len);
uint64_t size = len;
size_t npos = m_position % m_baseSize;
size_t ncap = m_cur->size - npos;
struct iovec iov;
Node* cur = m_cur;
while(len > 0) {
if(ncap >= len) {
iov.iov_base = cur->ptr + npos;
iov.iov_len = len;
len = 0;
} else {
iov.iov_base = cur->ptr + npos;
iov.iov_len = ncap;
len -= ncap;
cur = cur->next;
ncap = cur->size;
npos = 0;
}
buffers.push_back(iov);
}
return size;
}
}
test_bytearray.cc
/**
* @file test_bytearray.cc
* @brief Bytearray类测试
* @version 0.1
* @date 2021-09-18
*/
#include <algorithm>
#include <sylar/sylar.h>
static sylar::Logger::ptr g_logger = SYLAR_LOG_ROOT();
void test() {
/*
* 测试用例设计:
* 随机生成长度为len,类型为type的数组,调用write_fun将这个数组全部写入块大小为base_len的ByteArray对象中,
* 再将ByteArray的当前操作位置重设为0,也就是从起点开始,用read_fun重复读取数据,并与写入的数据比较,
* 当读取出的数据与写入的数据全部相等时,该测试用例通过
*/
#define XX(type, len, write_fun, read_fun, base_len) \
{ \
std::vector<type> vec; \
for (int i = 0; i < len; ++i) { \
vec.push_back(rand()); \
} \
sylar::ByteArray::ptr ba(new sylar::ByteArray(base_len)); \
for (auto &i : vec) { \
ba->write_fun(i); \
} \
ba->setPosition(0); \
for (size_t i = 0; i < vec.size(); ++i) { \
type v = ba->read_fun(); \
SYLAR_ASSERT(v == vec[i]); \
} \
SYLAR_ASSERT(ba->getReadSize() == 0); \
SYLAR_LOG_INFO(g_logger) << #write_fun "/" #read_fun \
" (" #type ") len=" \
<< len \
<< " base_len=" << base_len \
<< " size=" << ba->getSize(); \
}
XX(int8_t, 100, writeFint8, readFint8, 1);
XX(uint8_t, 100, writeFuint8, readFuint8, 1);
XX(int16_t, 100, writeFint16, readFint16, 1);
XX(uint16_t, 100, writeFuint16, readFuint16, 1);
XX(int32_t, 100, writeFint32, readFint32, 1);
XX(uint32_t, 100, writeFuint32, readFuint32, 1);
XX(int64_t, 100, writeFint64, readFint64, 1);
XX(uint64_t, 100, writeFuint64, readFuint64, 1);
XX(int32_t, 100, writeInt32, readInt32, 1);
XX(uint32_t, 100, writeUint32, readUint32, 1);
XX(int64_t, 100, writeInt64, readInt64, 1);
XX(uint64_t, 100, writeUint64, readUint64, 1);
#undef XX
/*
* 测试用例设计:
* 在前面的测试用例基础上,增加文件序列化和反序列化操作,
* 当写入文件的内容与从文件读取出的内容完全一致时,测试用例通过
*/
#define XX(type, len, write_fun, read_fun, base_len) \
{ \
std::vector<type> vec; \
for (int i = 0; i < len; ++i) { \
vec.push_back(rand()); \
} \
sylar::ByteArray::ptr ba(new sylar::ByteArray(base_len)); \
for (auto &i : vec) { \
ba->write_fun(i); \
} \
ba->setPosition(0); \
for (size_t i = 0; i < vec.size(); ++i) { \
type v = ba->read_fun(); \
SYLAR_ASSERT(v == vec[i]); \
} \
SYLAR_ASSERT(ba->getReadSize() == 0); \
SYLAR_LOG_INFO(g_logger) << #write_fun "/" #read_fun \
" (" #type ") len=" \
<< len \
<< " base_len=" << base_len \
<< " size=" << ba->getSize(); \
ba->setPosition(0); \
SYLAR_ASSERT(ba->writeToFile("/tmp/" #type "_" #len "-" #read_fun ".dat")); \
sylar::ByteArray::ptr ba2(new sylar::ByteArray(base_len * 2)); \
SYLAR_ASSERT(ba2->readFromFile("/tmp/" #type "_" #len "-" #read_fun ".dat")); \
ba2->setPosition(0); \
SYLAR_ASSERT(ba->toString() == ba2->toString()); \
SYLAR_ASSERT(ba->getPosition() == 0); \
SYLAR_ASSERT(ba2->getPosition() == 0); \
}
XX(int8_t, 100, writeFint8, readFint8, 1);
XX(uint8_t, 100, writeFuint8, readFuint8, 1);
XX(int16_t, 100, writeFint16, readFint16, 1);
XX(uint16_t, 100, writeFuint16, readFuint16, 1);
XX(int32_t, 100, writeFint32, readFint32, 1);
XX(uint32_t, 100, writeFuint32, readFuint32, 1);
XX(int64_t, 100, writeFint64, readFint64, 1);
XX(uint64_t, 100, writeFuint64, readFuint64, 1);
XX(int32_t, 100, writeInt32, readInt32, 1);
XX(uint32_t, 100, writeUint32, readUint32, 1);
XX(int64_t, 100, writeInt64, readInt64, 1);
XX(uint64_t, 100, writeUint64, readUint64, 1);
#undef XX
/*
* 测试用例设计:
* 在前面的测试基础上,增加对字符串序列化/反序列化的测试
*/
#define XX(len, write_fun, read_fun, base_len) \
{ \
std::string s = "qwertyuiopasdfghjklzxcvbnm"; \
std::vector<std::string> vec; \
for (int i = 0; i < len; i++) { \
random_shuffle(s.begin(), s.end()); \
vec.push_back(s); \
} \
sylar::ByteArray::ptr ba(new sylar::ByteArray(base_len)); \
for (auto &i : vec) { \
ba->write_fun(i); \
} \
ba->setPosition(0); \
for (size_t i = 0; i < vec.size(); ++i) { \
std::string v = ba->read_fun(); \
SYLAR_ASSERT(v == vec[i]); \
} \
SYLAR_ASSERT(ba->getReadSize() == 0); \
SYLAR_LOG_INFO(g_logger) << #write_fun "/" #read_fun \
" (" \
"string" \
") len=" \
<< len \
<< " base_len=" << base_len \
<< " size=" << ba->getSize(); \
}
XX(100, writeStringF16, readStringF16, 10);
XX(100, writeStringF32, readStringF32, 10);
XX(100, writeStringF64, readStringF64, 10);
XX(100, writeStringVint, readStringVint, 26);
#undef XX
}
int main(int argc, char *argv[]) {
test();
return 0;
}
【最后求关注、点赞、转发】
QQ交流群:957100923