转载请注明出处:小锋学长生活大爆炸[xfxuezhagn.cn]
如果本文帮助到了你,欢迎[点赞、收藏、关注]哦~
目录
发现问题
问题分析
修复思路
思路一
思路二
思路二对应代码
这个问题真的找了我好久,但说起来其实也简单,就是GPU温度太高了。
发现问题
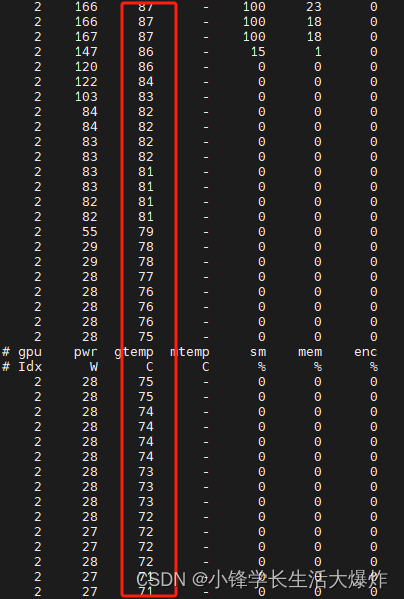
1、运行监控指令:
nvidia-smi dmon -i 00000000:41:00.0 -s pucvmet --gpm-metrics 10
2、运行你的代码,等到出问题。
3、看图就知道,密集的GPU运算,导致GPU温度达到限制了。高温限制是会影响性能的。

问题分析
本节内容来自:对于GPU显卡来说,多热算太热?
对于GPU来说,温度大致分为以下几个层次:
- 60°C以下 - 低温,GPU性能基本未发挥。
- 60-75°C - 正常工作温度,GPU性能发挥良好且寿命长。
- 75-85°C - 开始偏热,但性能基本无影响,如果长时间在此范围可能缩短服务寿命。
- 85-95°C - 极限工作温度,性能会受影响。如果长期工作在此温度就可能锁频下降性能。
- 95°C以上 - 非常热乃至太热,此温度下GPU性能将受很大影响,极易发生故障或损坏元件。
一般来说:
- 75°C以下算正常,保持这个度数(或更低)的温度应该可以让您安心,因为您的 GPU 正在发挥其最大潜力。
- 75-85°C需要注意,保持通风以避免长期这样。
- 85°C以上已经属于比较热了,需要改进散热或降低负荷。
- 95°C以上就已经属于非常危险的热度域,需要立即采取措施降温。
- 所以对GPU来说,75°C应该算做热的标准,85°C开始需要特别注意,95°C以上就可能导致不可恢复的损坏。
对GPU来说,长时间工作在85°C以上,会有以下影响:
- 加速老化速度。高温环境下,GPU内各个组件如芯片封装材料、焊料连接等将会以更快的速度老化和失效。
- 故障率增加。85°C及以上的高温会促进GPU内部各种微观装配和结构性问题的暴露,从而加大故障发生概率。
- 缩短可用年限。85°C高温下,GPU将在5-7年内即达到其可用服务寿命极限,比常温使用寿命短1-3年。
- 锁频降级性能。为保护内部元器件,85°C时GPU极有可能自动下调时钟频率来降温,导致长期性能下降。大多数现代显卡都具有固有的热保护机制,当其内部温度过高时,该机制会导致 GPU 节流。驱动程序采取的第一步是限制性能,以减少过热 GPU 的负载。尽管采取了这些措施,如果温度继续升高,系统将开始强制关闭。这通常可以防止对 GPU 造成任何物理损坏,但如果经常发生过热,永久性硬件损坏将是不可避免的。
所以总体来说,如果GPU显卡长期工作在85°C以上高温,会明显缩短GPU的平均使用寿命,从1-3年不等,同时也影响其锁定频率和稳定性能输出,建议尽量降低和控制工作温度。
修复思路
思路一
来自对于GPU显卡来说,多热算太热?
这里是一些建议,可以帮助降低GPU的工作温度:
- 清除尘垢。定期清洁GPU风扇及散热片上积聚的灰尘,以保持散热效率。
- 优化固件。检查显卡驱动是否为最新版本,更新可以改善电源管理降温。
- 散热风扇速度。调整风扇转速提高冷风流量对GPU进行更有效的降温。
- 流通散热。确保GPU周围有足够通风间隙,有助热空气迅速排出。
- 改用散热板。更换散热更强的板后型显卡可以有效降温5-10°C。
- 升级电源。GPU功耗大时需要足够功率输出的电源降温支持。
- 温控软件。使用温控软件根据温度自动调整GPU时钟、风扇速度等。
- 水冷模式。水冷传热效率高,能最大限度降低GPU温度。
- 温度监测。实时了解GPU温曲线有助于查找问题热点进行改进。
以上方法结合使用可以有效帮助控制GPU的工作温度,延长使用寿命。
思路二
GPU的降温挺快的,不调用GPU运算,它的温度就会开始降低,因此可以考虑适当的降低GPU的连续使用时间。
思路二对应代码
或者,可以在运行代码前,等待GPU的问题降低到一定的程度再执行。给个自己写的参考代码吧:
def check_gpu_temperatures(gpu_ids, temp_threshold=40, timeout=None):
gpu_ids_list = gpu_ids.split(',')
start_time = time.time()
while True:
temperatures = []
all_below_threshold = True
for gpu_id in gpu_ids_list:
result = subprocess.run(['nvidia-smi', '-i', gpu_id, '--query-gpu=temperature.gpu', '--format=csv,noheader,nounits'], stdout=subprocess.PIPE)
temp = int(result.stdout.decode('utf-8').strip())
temperatures.append(f'GPU {gpu_id}: {temp}°')
if temp > temp_threshold: all_below_threshold = False
if all_below_threshold:
print('>> 当前GPU温度: ' + ' | '.join(temperatures))
break
print(f'>> 为防止GPU高温导致性能限制,等待降温中({temp_threshold}°): ' + ' | '.join(temperatures), end='\r')
if timeout and (time.time() - start_time) > timeout:
print('\n已达超时,不在等待 GPU 温度下降。')
break
time.sleep(1)
print()
用法:
gpus = '2,3,4'
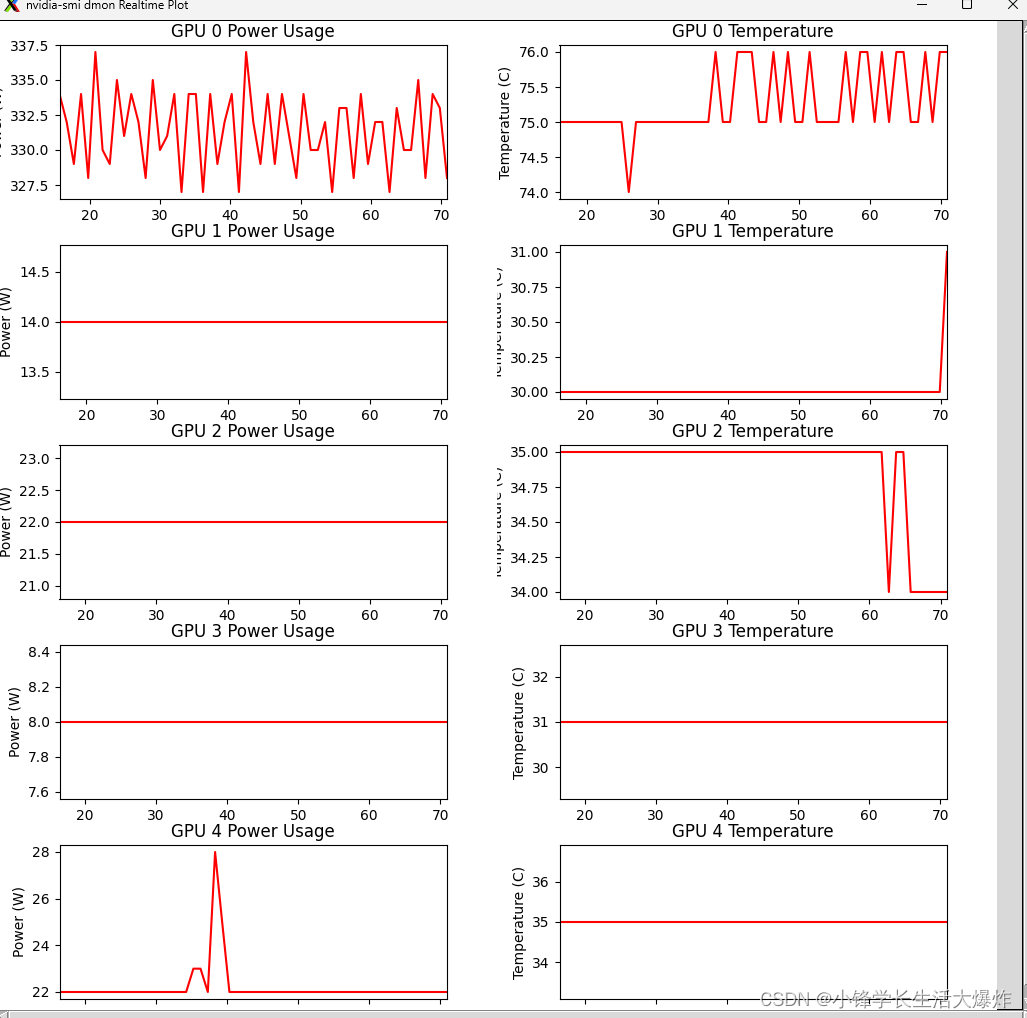
check_gpu_temperatures(gpu_ids=gpus , temp_threshold=60, timeout=None)效果:


温度监控UI代码
为了方便监控GPU的温度:
import sys
import subprocess
import threading
import time
import numpy as np
import tkinter as tk
from tkinter import ttk
from matplotlib.backends.backend_tkagg import FigureCanvasTkAgg
from matplotlib.figure import Figure
class RealtimePlot:
def __init__(self, parent, title, ylabel):
self.fig = Figure(figsize=(5, 2), dpi=100) # 设定图像尺寸
self.ax = self.fig.add_subplot(111)
self.ax.set_title(title)
self.ax.set_ylabel(ylabel)
self.ax.set_xlabel('Time')
self.xdata = []
self.ydata = []
self.line, = self.ax.plot(self.xdata, self.ydata, 'r-')
self.canvas = FigureCanvasTkAgg(self.fig, master=parent)
self.canvas.draw()
self.canvas.get_tk_widget().pack(side=tk.LEFT, fill=tk.BOTH, expand=1)
def update_plot(self, y):
self.xdata.append(time.time())
self.ydata.append(y)
if len(self.xdata) == 1: # 防止 transformation singular 错误
self.ax.set_xlim(self.xdata[0], self.xdata[0] + 1)
else:
self.ax.set_xlim(self.xdata[0], self.xdata[-1])
self.line.set_xdata(self.xdata)
self.line.set_ydata(self.ydata)
self.ax.relim()
self.ax.autoscale_view()
self.canvas.draw()
def resize(self, event):
self.fig.set_size_inches(event.width / self.canvas.get_tk_widget().winfo_fpixels('1i'),
event.height / self.canvas.get_tk_widget().winfo_fpixels('1i'))
self.canvas.draw()
class GPU_MonitorApp:
def __init__(self, root):
self.root = root
self.root.title("nvidia-smi dmon Realtime Plot")
self.plots = []
gpu_ids = ['00000000:3d:00.0', '00000000:3e:00.0', '00000000:1D:00.0', '00000000:1E:00.0', '00000000:41:00.0']
main_frame = tk.Frame(root)
main_frame.pack(fill=tk.BOTH, expand=1)
canvas = tk.Canvas(main_frame)
canvas.pack(side=tk.LEFT, fill=tk.BOTH, expand=1)
scrollbar_y = tk.Scrollbar(main_frame, orient=tk.VERTICAL, command=canvas.yview)
scrollbar_y.pack(side=tk.RIGHT, fill=tk.Y)
scrollbar_x = tk.Scrollbar(root, orient=tk.HORIZONTAL, command=canvas.xview)
scrollbar_x.pack(side=tk.BOTTOM, fill=tk.X)
canvas.configure(yscrollcommand=scrollbar_y.set, xscrollcommand=scrollbar_x.set)
canvas.bind('<Configure>', lambda e: canvas.configure(scrollregion=canvas.bbox("all")))
second_frame = tk.Frame(canvas)
canvas.create_window((0, 0), window=second_frame, anchor="nw")
plot_width = 500 # 每个图的宽度(以像素为单位)
plot_height = 200 # 每个图的高度(以像素为单位)
for i, gpu_id in enumerate(gpu_ids):
frame = ttk.Frame(second_frame, width=plot_width * 2, height=plot_height)
frame.pack(side=tk.TOP, fill=tk.BOTH, expand=1)
plot_power = RealtimePlot(frame, f"GPU {i} Power Usage", "Power (W)")
plot_temp = RealtimePlot(frame, f"GPU {i} Temperature", "Temperature (C)")
self.plots.append((plot_power, plot_temp))
frame.bind("<Configure>", plot_power.resize)
frame.bind("<Configure>", plot_temp.resize)
# 计算窗口初始尺寸
window_width = plot_width * 2 + 40 # 两个图表并排 + 滚动条和边距
window_height = plot_height * len(gpu_ids) + 40 # 每个GPU占一行 + 滚动条和边距
self.root.geometry(f"{window_width}x{window_height}")
self.start_monitoring(gpu_ids)
def start_monitoring(self, gpu_ids):
self.monitor_thread = threading.Thread(target=self.monitor_gpu, args=(gpu_ids,))
self.monitor_thread.daemon = True
self.monitor_thread.start()
def monitor_gpu(self, gpu_ids):
command = ['nvidia-smi', 'dmon', '-i', ','.join(gpu_ids), '-s', 'pm']
process = subprocess.Popen(command, stdout=subprocess.PIPE, stderr=subprocess.PIPE, text=True)
skip_header = True # 用于跳过表头
for line in process.stdout:
try:
if skip_header:
if line.startswith('#'):
continue # 跳过表头行
skip_header = False
parts = line.split()
if len(parts) == 0 or parts[0] == '#':
continue # 跳过表头或空行
if len(parts) >= 7 and parts[0].isdigit(): # 确保行数据完整
gpu_idx = int(parts[0])
if gpu_idx < len(gpu_ids):
gpu_power = float(parts[1]) if parts[1] != '-' else None
gpu_temp = float(parts[2]) if parts[2] != '-' else None
print(f"GPU {gpu_idx} power: {gpu_power}, temp: {gpu_temp}") # Debug info
if gpu_power is not None:
self.plots[gpu_idx][0].update_plot(gpu_power)
if gpu_temp is not None:
self.plots[gpu_idx][1].update_plot(gpu_temp)
except Exception as e:
print(f"Error parsing line: {line}\n{e}")
if __name__ == '__main__':
root = tk.Tk()
app = GPU_MonitorApp(root)
root.mainloop()



![[大模型]Qwen2-7B-Instruct 接入 LangChain 搭建知识库助手](https://img-blog.csdnimg.cn/direct/35a9895a6529488ba6e1ae90cd568f55.png#pic_center)