作者:来自 Elastic Andrei Dan

今天,我们将探索 Elasticsearch 针对数据流的新数据管理系统:数据流生命周期,从版本 8.14 开始提供。凭借其简单而强大的执行模型,数据流生命周期可让n 你专注于数据生命周期的业务相关方面,例如降采样和保留。在后台,它会自动确保存储数据的 Elasticsearch 结构得到有效管理。
Elasticsearch 中的数据生命周期管理演变
自 6.x Elasticsearch 系列以来,索引生命周期管理 (index lifecycle management - ILM) 已使用户能够通过自动在层之间迁移数据来维护健康的索引并节省成本。
ILM 根据索引独特的性能、弹性和保留需求来处理索引,同时提供对成本的显着控制并详细定义索引的生命周期。
ILM 是一种非常通用的解决方案,可满足广泛的用例,从时间序列索引和数据流到存储文本内容的索引。对于所有这些用例,生命周期定义将非常不同,当我们考虑每个单独部署的可用硬件和数据分层资源时,它会变得更加不同。因此,ILM 允许完全可定制的生命周期定义,但代价是复杂性(精确的滚动定义;何时强制合并、收缩和(部分)挂载索引)。
当我们开始研究无服务器(serverless)解决方案时,我们有机会通过新的视角来审视生命周期管理,我们的用户可以(并且将)免受 Elasticsearch 内部概念(如分片、分配或集群拓扑)的影响。更重要的是,在无服务器中,我们希望能够根据需要更改内部 Elasticsearch 配置,以保持用户的最佳体验。
在这种新情况下,我们研究了现有的 ILM 解决方案,该解决方案为用户提供了内部 Elasticsearch 概念作为构建块,并决定我们需要一个新的解决方案来管理数据的生命周期。
我们吸取了从大规模构建和维护 ILM 中吸取的经验教训,并为未来创建了一个更简单的生命周期管理系统。该系统更具体,仅适用于数据流(data streams)。它直接在数据流上配置为属性(类似于索引设置属于索引的方式),我们称之为数据流生命周期。它是一种内置机制(继续使用索引设置类比),始终处于开启状态,并且始终对数据流的生命周期需求做出反应。
通过将适用范围限定在数据流(即带有很少更新的时间戳的数据),我们能够避免自定义,转而使用易用性和自动默认值。数据流生命周期将自动执行数据结构维护操作,如滚动和强制合并,并允许你仅处理你应该关心的业务相关生命周期功能,例如降采样(downsampling)和数据保留(data retention)。
数据流生命周期的功能不如 ILM 丰富;最值得注意的是,它目前不支持数据分层、缩减或可搜索快照。但是,不需要这些特定功能的用例将更好地由数据流生命周期服务。
虽然数据流生命周期最初是为无服务器环境的需求而设计的,但它们也可用于常规本地和 ESS Elasticsearch 部署。
配置数据流生命周期
让我们创建一个 Elasticsearch Serverless 项目,并开始创建由数据流生命周期管理的数据流。
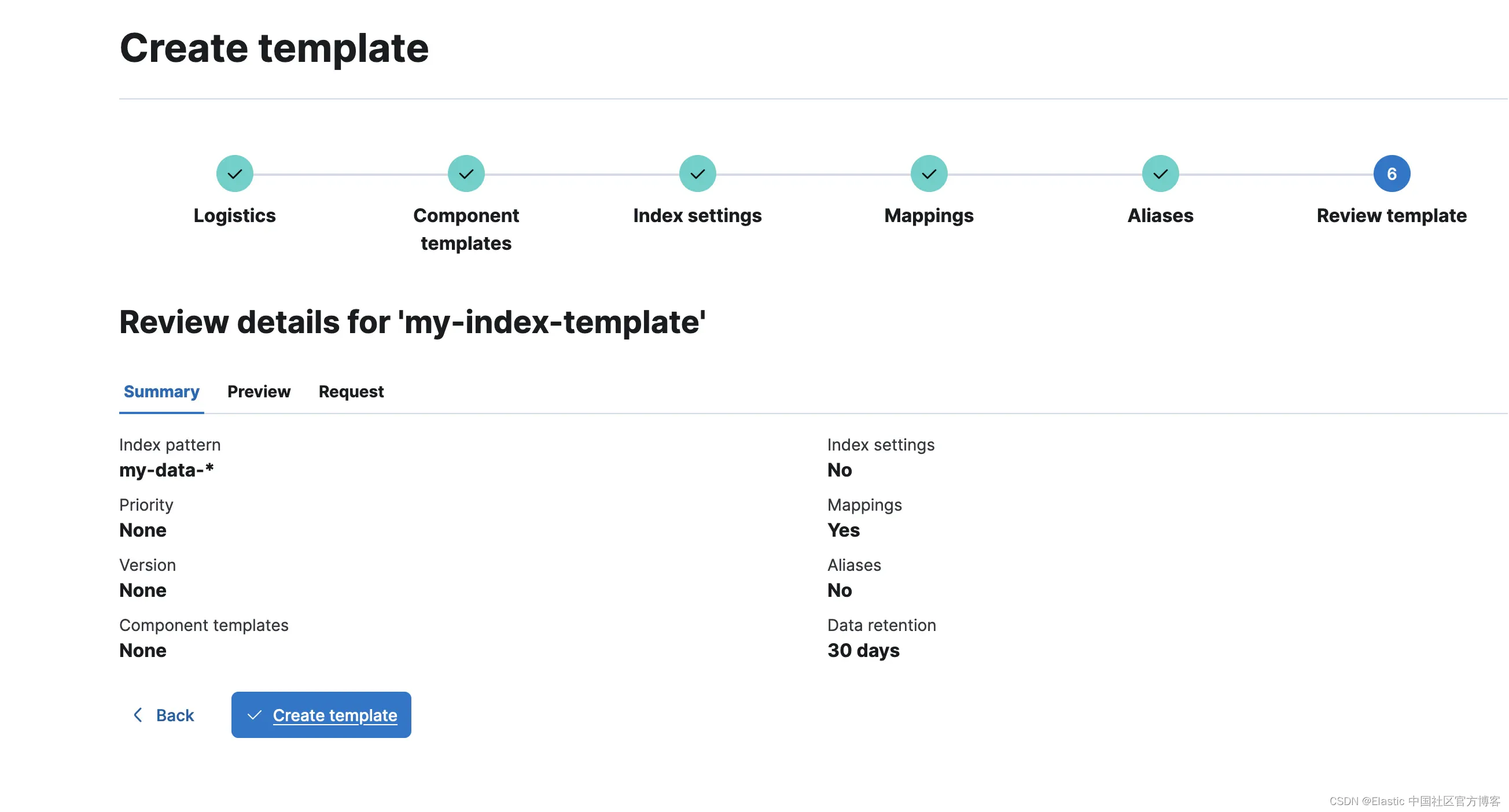
创建项目后,转到索引管理并为 my-data-* 索引模式创建索引模板并配置 30 天的保留期:

让我们浏览这些步骤并完成此索引模板(我在映射部分配置了一个文本字段,但这是可选的):
现在,我们将提取一些以 my-data-stream 命名空间为目标的数据。我将使用左侧的 Dev Tools 部分,但你也可以选择自己喜欢的数据提取方式:

my-data-stream 现已创建,它包含 2 个文档。让我们转到 Index Management/Data Streams 并检查一下:

就这样!🎉 我们的数据流由数据流生命周期管理,数据保留期配置为 30 天。所有与 my-data-* 模式匹配的新数据流都将由数据流管理,并获得 30 天的数据保留期。
更新已配置的生命周期
数据流生命周期属性属于数据流。因此,我们可以通过直接导航到数据流来配置更新现有数据流的生命周期。让我们转到索引管理/数据流并将 my-data-stream 的保留期编辑为 7 天:
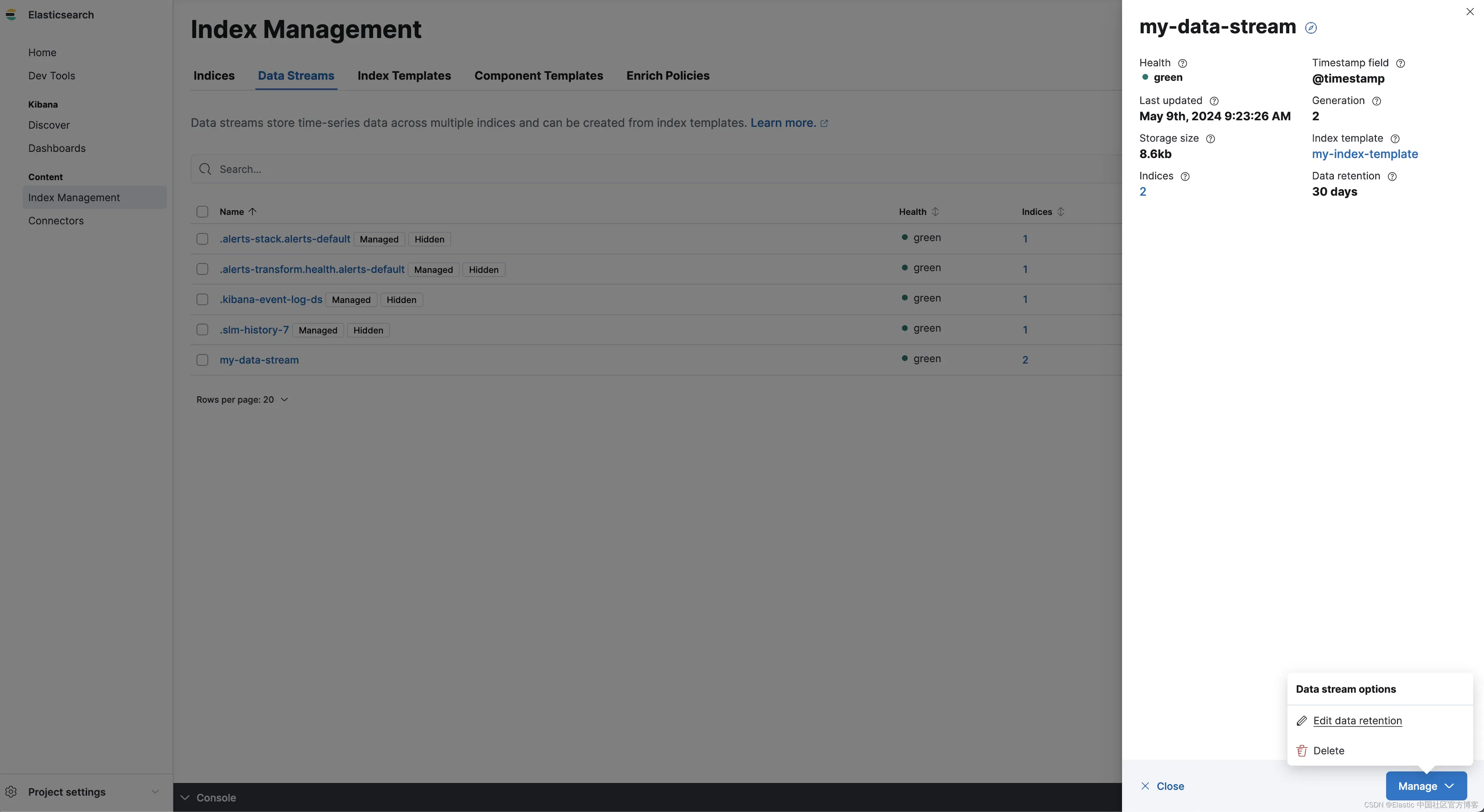

我们现在看到我们的数据流的数据保留期为 7 天:
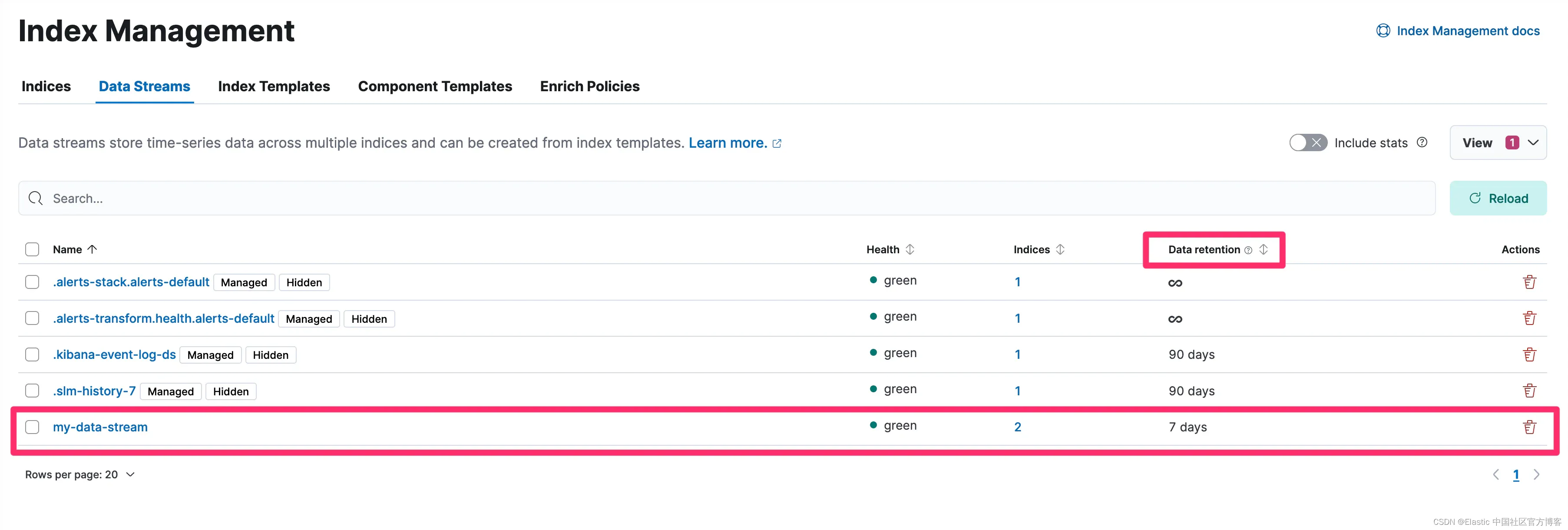
现在系统中现有数据流已配置所需的 7 天保留期,我们还要更新索引模板保留,以便创建的新数据流也能获得 7 天的保留期:


实施细节
主节点定期(根据 data_streams.lifecycle.poll_interval 设置,默认情况下每 5 分钟一次)迭代系统中配置为由生命周期管理的数据流。在每次迭代中,系统中的每个后备索引状态都会被评估,并执行一个操作以实现配置的生命周期所描述的目标状态。
对于每个管理的数据流,我们首先尝试根据 cluster.lifecycle.default.rollover 条件滚动数据流。这是对数据流的写入索引尝试的唯一操作。
滚动后,前一个写入索引将有资格进行合并。由于我们希望分片维护任务的合并是我们自动执行的,因此我们实施了一个更轻量的合并操作,这是强制合并到 1 个段的替代方法,它只合并小段的长尾(long tail)而不是整个分片。这种方法的主要好处是它可以在滚动后自动和尽早应用。
合并后备索引后,在下一次生命周期执行运行时,索引将被降采样。
完成所有计划的降采样轮次后,每次生命周期运行时,都会检查后备索引是否符合数据保留条件。当指定的数据保留期过后(自滚动时间起),后备索引将被删除。
降采样和数据保留都是基于时间的操作(例如 data_retention: 7d),并且是从索引滚动以来计算的。索引滚动以来的时间在 explain lifecycle API 中可见,我们称之为generation_time,表示后备索引成为世代索引(而不是数据流的写入索引)以来的时间。
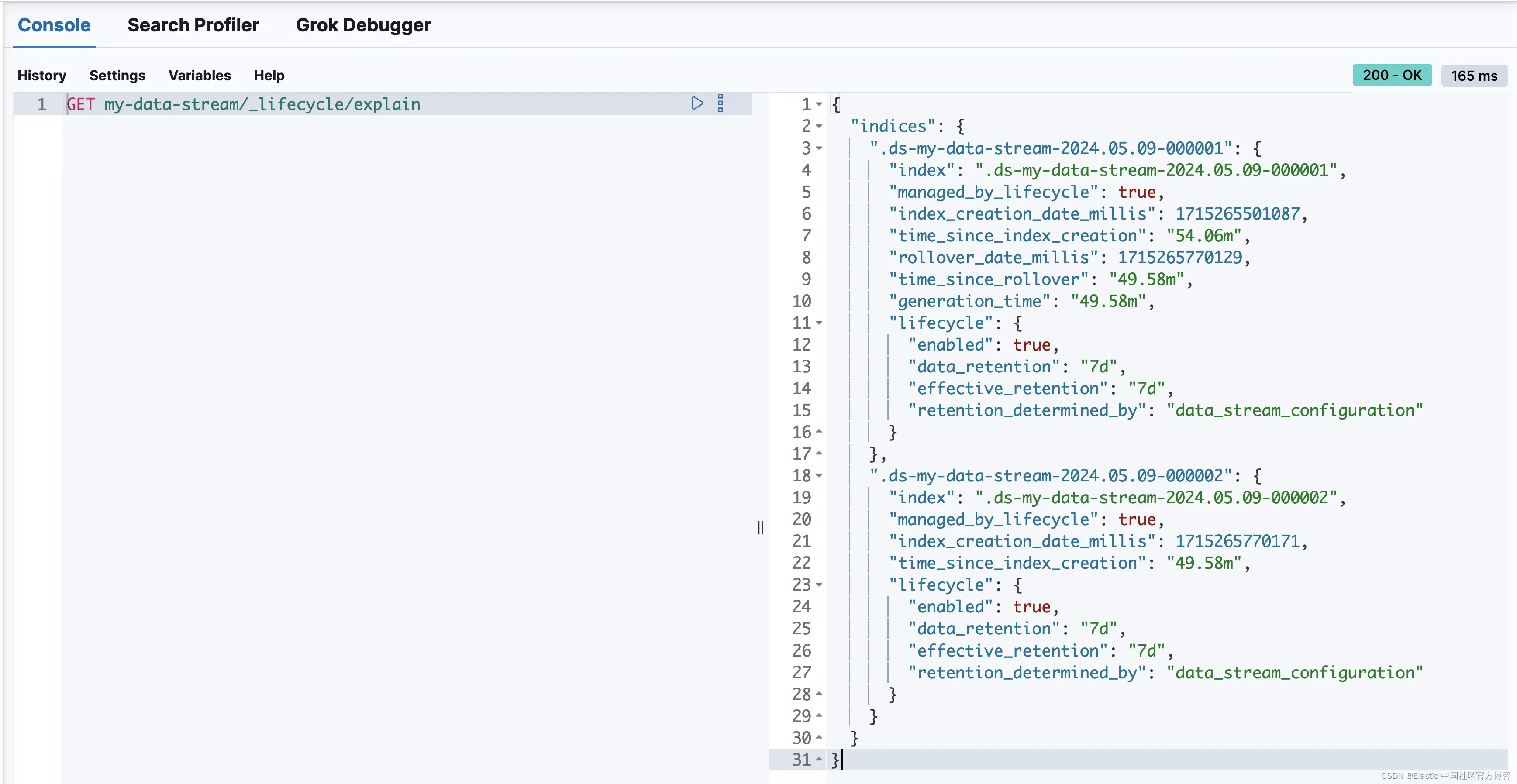
我已经运行了 my-data-stream(在轮转时有 2 个后备索引)的 explain lifecycle API,以深入了解
我们可以看到两个索引的 lifecycle 定义都包括 7 天的更新数据保留期。
较旧的索引 .ds-my-data-stream-2024.05.09-000001 不再是数据流的写入索引,我们可以看到解释 API 将 generation_time 报告为 49 分钟。一旦生成时间达到 7 天,.ds-my-data-stream-2024.05.09-000001 后备索引将被删除以符合配置的数据保留期。
索引 .ds-my-data-stream-2024.05.09-000002 是数据流的写入索引,一旦满足 rollover 标准,就会等待轮转。
time_since_index_creation 字段用于帮助计算当数据流不再接收大量数据时何时根据自动 max_age 标准滚动数据流。
从 ILM 迁移到数据流生命周期
促进数据流生命周期的平稳过渡,以便对数据流进行测试、试验,并最终将其迁移到生产环境,这始终是此功能的目标。因此,我们决定允许 ILM 和数据流生命周期在云环境和本地部署中的数据流上共存。
ILM 配置继续直接存在于支持索引上,而数据流生命周期则配置在数据流本身上。
支持索引一次只能由一个管理系统管理。如果 ILM 和数据流生命周期都适用于支持索引,则 ILM 优先(默认情况下,但可以使用 index.lifecycle.prefer_ilm 索引设置将优先级更改为数据流生命周期)。
数据流的迁移路径将允许现有的 ILM 管理的支持索引老化并最终被 ILM 删除,而新的支持索引将开始由数据流生命周期管理。
我们增强了 GET _data_stream API,使其包含每个支持索引的滚动信息(managed_by 字段,可能值为 Index Lifecycle Management、Data stream lifecycle 或Unmanaged,以及 prefer_ilm 设置的值),并在数据流级别包含 next_generation_managed_by 字段,以指示将管理下一代支持索引的系统。
要将未来的支持索引(在数据流滚动后创建)配置为由数据流生命周期管理,需要执行两个步骤:
- 更新支持数据流的索引模板,将 prefer_ilm 设置为 false(请注意,prefer_ilm 是一个索引设置,因此在索引模板中配置它意味着它只会在新的支持索引上配置)并配置所需的数据流生命周期(这将确保新的数据流将开始由数据流生命周期管理)。
- 使用 lifecycle API 为现有数据流配置数据流生命周期。
有关迁移到数据流生命周期的完整教程,请查看我们的文档。
结论
我们为数据流构建了一个生命周期功能,可以自动处理底层数据结构的维护,让你专注于业务生命周期需求,如降采样和数据保留。
试用我们新的无服务器(serverless)产品,并了解更多有关数据流生命周期的可能性的信息。
准备好自己尝试一下了吗?开始免费试用。
想要获得 Elastic 认证?了解下一期 Elasticsearch 工程师培训何时举行!
原文:Data lifecycle management: Simplifying data lifecycle management for data streams — Elastic Search Labs