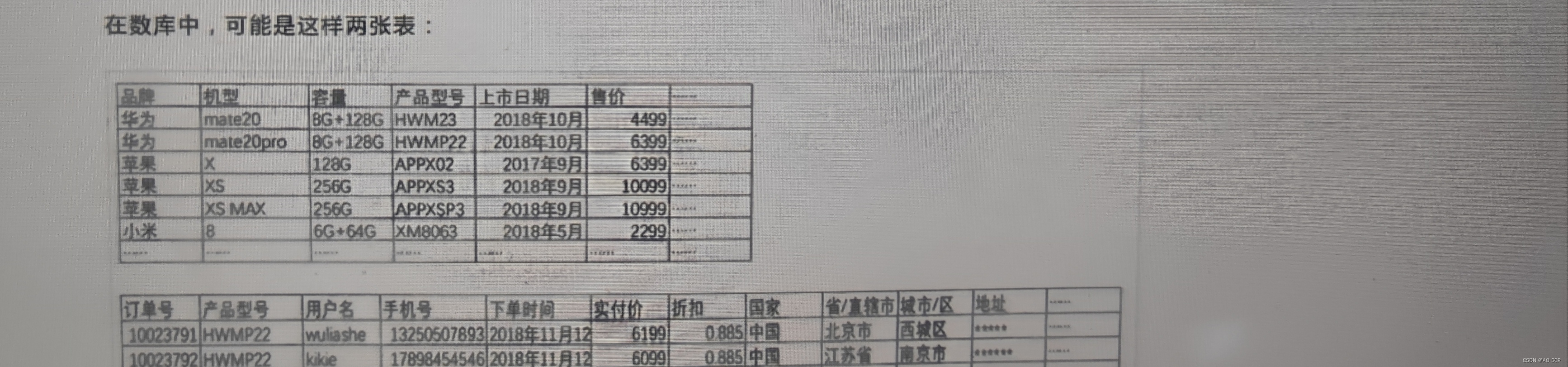
本文ppt来自深蓝学院《机器人中的数值优化》
目录
1 Newton's Method
2 Pratical Newton's Method
1 Newton's Method
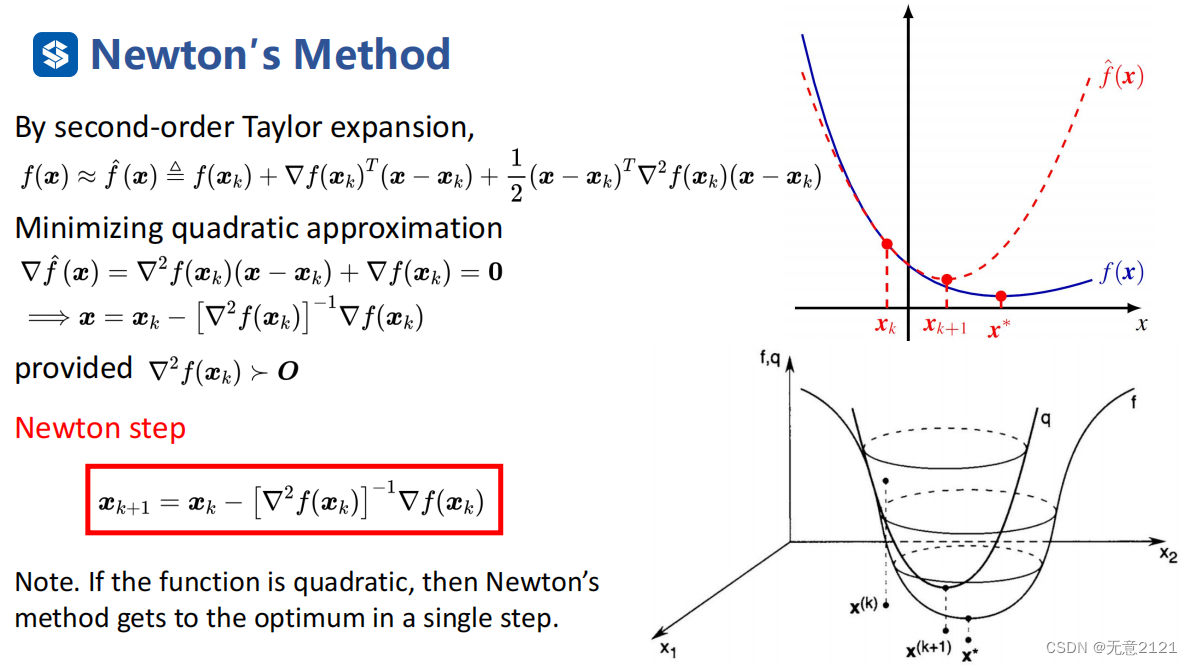
当我们引入函数的二阶信息就考虑到了curvature info,这里先对函数进行泰勒展开,取二阶近似,对近似后的函数取最优解,通过梯度等于0得到一个等式
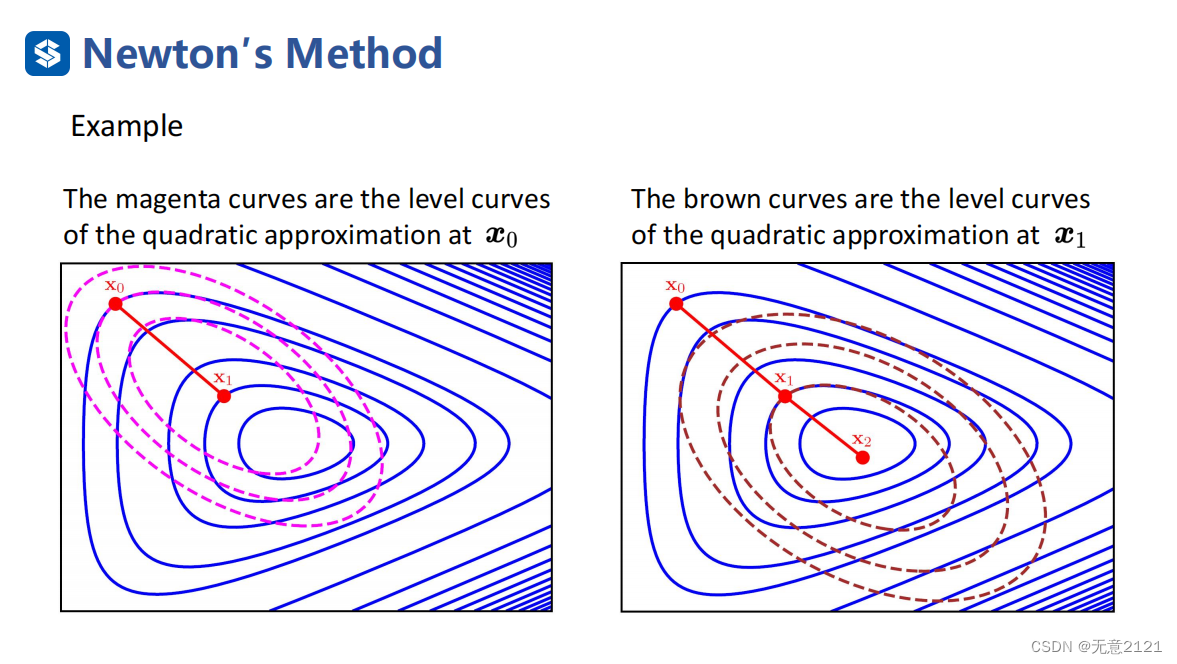 当函数是二次型时,近似没有起到效果,迭代的过程就是求解原函数最优解的过程,因此当然一次迭代就能得到最优解
当函数是二次型时,近似没有起到效果,迭代的过程就是求解原函数最优解的过程,因此当然一次迭代就能得到最优解
 这是利用牛顿法的一次迭代举例
这是利用牛顿法的一次迭代举例
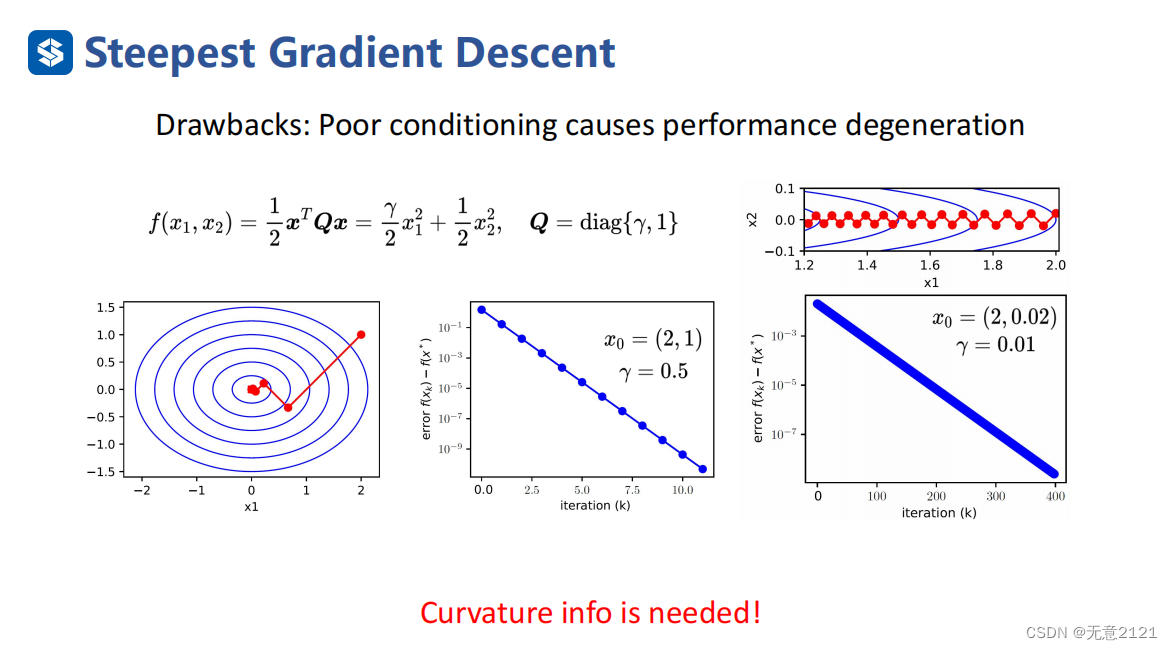
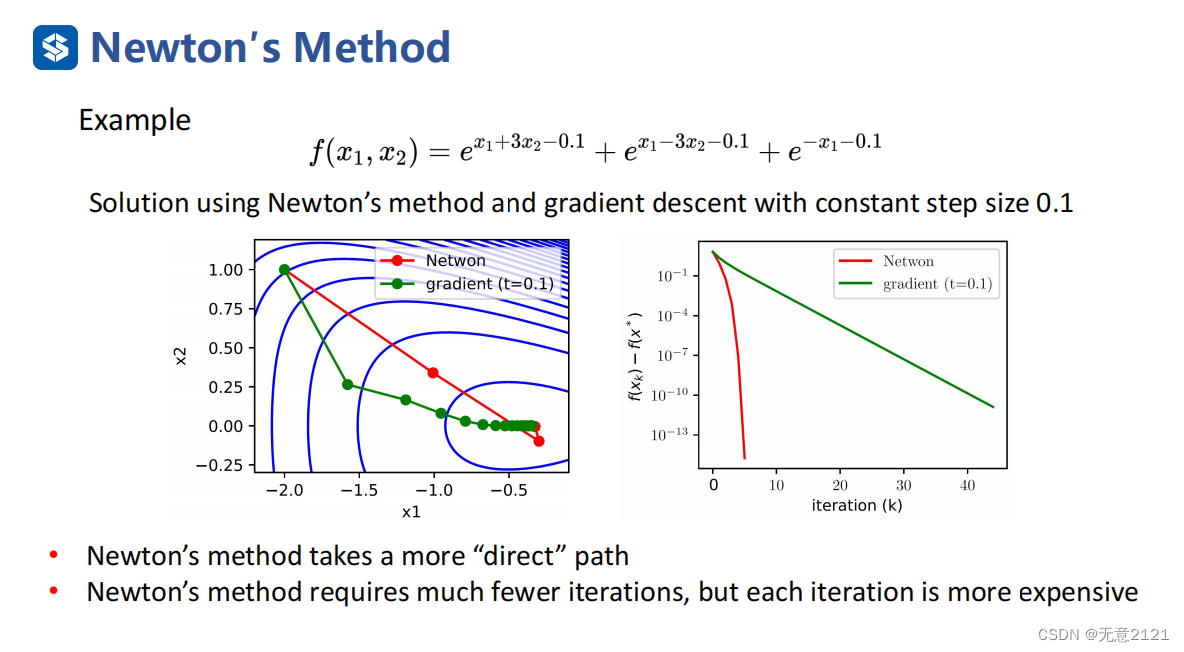 将牛顿法与最速下降法相比,牛顿法需要的迭代次数很少就能直达最优解,但是由于需要求解hessian矩阵的逆,导致,每一步的迭代时间有所增加
将牛顿法与最速下降法相比,牛顿法需要的迭代次数很少就能直达最优解,但是由于需要求解hessian矩阵的逆,导致,每一步的迭代时间有所增加
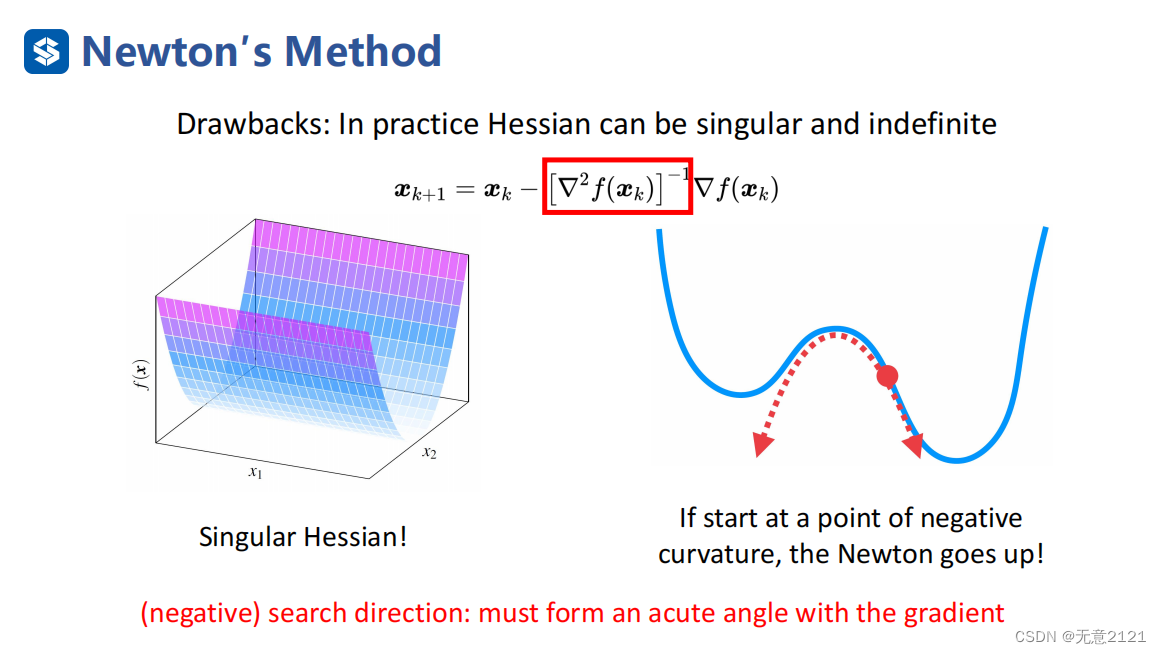 但我们还需要注意牛顿法的适用条件是hessian矩阵正定,否则会出现上述两种情况,若半正定可能找不到最优解,若负定,将使迭代方向变成上升方向,因此我们必须保证迭代方向与负梯度方向成锐角
但我们还需要注意牛顿法的适用条件是hessian矩阵正定,否则会出现上述两种情况,若半正定可能找不到最优解,若负定,将使迭代方向变成上升方向,因此我们必须保证迭代方向与负梯度方向成锐角
2 Pratical Newton's Method
 当遇到hessian矩阵不是正定时,我们需要构造一个足够接近hessian的正定矩阵M
当遇到hessian矩阵不是正定时,我们需要构造一个足够接近hessian的正定矩阵M
backtracking line search不需要梯度与hessian

首先M矩阵等于hessian矩阵加上一个单位阵乘上一个系数
对于对称正定线性方程组而言,可采用Cholesky分解或Bunch-Kaufman 分解对下降方向d进行快速求解。
假如函数为凸函数,M矩阵可以利用 cholesky 分解,将稠密的矩阵分解为上三角与下三角乘积,具体的数学推导请参考[数值计算] LU分解、LUP分解、Cholesky分解 - 知乎 (zhihu.com)
假如函数为非凸函数, M矩阵可以利用 Bunch-Kaufman 分解,具体的数学推导请参考LDLT分解法_百度百科 (baidu.com)






![Java高效率复习-线程基础[线程]](https://img-blog.csdnimg.cn/cc96b79b2579424abc2e6ec1846ac666.png)