目录
一.二叉树类的定义
二.构造二叉树(构造函数)
三.为二叉树插入节点(insert_value)
四.移除根节点(remove_root,lchild_leaf)
五.移除二叉树中的某值(remove,remove_value)
六.清空二叉树
七.前、中、后序遍历
一.二叉树类的定义
二叉树类的定义需定义两个类,分别为BTnode来存放二叉树的相关信息(如节点的值,左子树、右子树的地址等)和BinaryTree来声明二叉树的相关操作。
C++代码:
//BinaryTree.h
#ifndef _BINARYTREE_H_
#define _BINARYTREE_H_
#pragma once
#include<iostream>
using namespace std;
template<typename valType>
class BTnode
{
//使BTnode与BinaryTree类建立友谊关系,BinaryTree类可以直接使用BTnode类中的data member
friend class BinaryTree<valType>;
private:
valType _val;
int _cnt;
BTnode* _lchild;
BTnode* _rchild;
public:
BTnode() { _val = 0; _cnt = 0;_lchild=_rchild =0 };
BTnode(const valType& val);
~BTnode() { };
void lchind_leaf(BTnode* leaf, BTnode* subtree); //remove操作中的某个特殊情况
void remove_value(const valType& val, BTnode*& prev); //作为remove操作中的操作函数
};
template<typename elemType>
class BinaryTree
{
private:
BTnode<elemType>* _root;
public:
BinaryTree() { _root = 0 }; //默认构造函数
BinaryTree(const BinaryTree&rhs);
~BinrayTree(){} ;
void remove(const elemType& elem); //移除某值
void remove_root(); //移除根节点
void clear(BTnode<elemType>*pt); //清空二叉树
void insert_value(const elemType& val); //为二叉树插入节点
//遍历:
//前序
void preorder(BTnode*pt,ostream& os)const;
//中序
void inorder(BTnode*pt,ostream& os)const;
//后序
void postorder(BTnode*pt,ostream& os)const;
void display_val(BTnode*pt,ostream* os)const;
};
#endif
friend class BinaryTree<valType>;在BTnode类中加入上述语句使BTnode类与BinaryTree类建立友谊关系,BinaryTree类可以直接使用BTnode类中的data member。
二.构造二叉树(构造函数)
通过成员初始化完成data member _val的初始化(因为_val的类型是valType,如果valType是一个类,则可能无法通过简单的赋值运算通过初始化)。
建议将所有的template类型参数当作为"class"类型来处理,因而将其声明为一个const reference而不是by value来传递。
C++代码:
template<typename valType>
BTnode<valType>::BTnode(const valType& val):_val(val)
{
_cnt = 1;
_lchild = _rchild = 0;
}
template<typename elemType>
BinaryTree<elemType>::BinaryTree(const BinaryTree& rhs):_root(rhs._root)
{
}对于模板类,第一次出现需要声明为BTnode<valType>加以限定,第二次出现的BTnode已经被视为在class定义范围内,则把无需再加以限定
三.为二叉树插入节点(insert_value)
主要通过递归实现
节点插入的基本原理:左子树的值小于根节点,右子树的值大于根节点。通过递归直到找到某个根节点的左/右子树不存在,创建左/右子树并将val赋值给该节点。
C++代码:
template<typename elemType>
void BinaryTree<elemType>::insert_value(const elemType& val)
{
if (val == _val)
{
_cnt++;
return;
}
if (val < _val)
{
if (!_child) //如果此时该根节点的左子树不存在,则创造一个新的左子树用于存放新节点
{
_lchild = new BTnode(val);
}
//如果存在,则继续递归直到找到不存在的地方
else
{
_lchild->insert_value(val);
}
}
else
{
//对于右子树的操作相同
if (!_rchild)
{
_rchild = new BTnode(val);
}
else
{
_rchild->insert_value(val);
}
}
}四.移除根节点(remove_root,lchild_leaf)
原理:如果根节点拥有任何子节点,remove_root将重设根节点。如果右节点存在,则以右节点取而代之;如果右节点不存在而左节点存在,则root直接用左节点取代。
细节:当根节点的右节点存在时,用右节点取代该根节点,但此时左节点应当如何放置?有两种情况。
①.该右节点的左子节点存在:
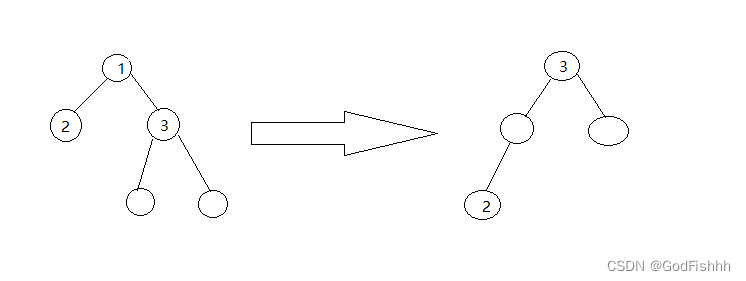 左节点接在右节点(即当前的根节点)的左子节点的左端。
左节点接在右节点(即当前的根节点)的左子节点的左端。
②.该右节点的左子节点不存在
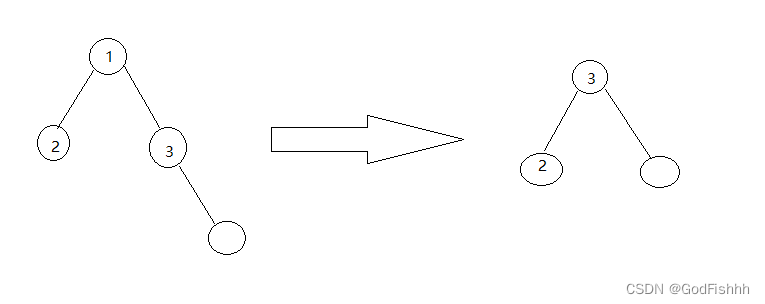
左节点直接接在右节点(即当前根节点)的左子节点处。
C++代码:
template<typename valType>
void BTnode<valType>::lchind_leaf(BTnode* leaf, BTnode* subtree)
{
while (subtree->_lchild) //如果subtree的左子节点存在,则一直向下递归直到某个subtree不存在
左子节点再将leaf放在subtree的左子节点处
{
subtree = subtree->_lchild;
}
subtree->_lchild = leaf;
}
template<typename elemType>
void BinaryTree<elemType>::remove_root()
{
if (!_root)
{
return;
}
//创建一个指针用来保存要删除的节点
BTnode<elemType>* tmp = _root;
if (_root->rchild) //如果右节点存在,则用右节点来替换根节点
{
_root = _root->_rchild;
}
if (tmp->_lchild) //如果根节点的左节点存在
{
BTnode<elemType>* lc = tmp->_lchild; //lc是是根节点的左节点
BTnode<elemType>* newlc = _root->_lchild; //newlc是右节点的左节点
if (!newlc) //如果右节点的左节点不存在
{
_root->_lchild = lc; //则直接将左节点放在此处
}
else
{
BTnode<elemType>::lchild)leaf(lc,newlc); //若右节点的左节点存在,则将根节点的左节点放在右节点的左子树的最底段的左节点处。
}
}
else //右节点不存在
{
_root = _root->lchild;
}
delete tmp;
}
五.移除二叉树中的某值(remove,remove_value)
原理:左子树的值小于根节点,右子树的值大于根节点,再通过递归一层一层的搜索下去。
C++代码:
template<typename valType>
void BTnode<valType>::remove_value(const valType& val, BTnode*& prev)
{
if (val < _val) //则往左子树递归
{
if (!_child) //已经不存在左节点,即该二叉树中不存在该值
{
return;
}
else
{
_lchild->remove_value(val, _lchild);
}
}
else if (val > _val) //则刚右子树递归
{
if (!_right)
{
retur;
}
else
{
_rchild->remove_value(val,_rchild)
}
}
else //val = _val的情况,即找到该节点,接下来考虑remove操作的过程
{
if (_rchild)//如果右子树存在,则用右子树来替换根节点 (_rchild其实为this->rchild)
{
prev = _rchild;
if (_lchild) //如果左子树存在,则需要进行下列操作来处理左子树
{
if (!prev->_lchild) //如果该右节点不存在左子节点,则直接将_lchild接在该位置
{
prev->_lchild = _lchild;
}
else
{
//右节点的左子节点存在,通过提前设定好的lchild_leaf函数将_lchild放在_rchild的左子节点的左端
lchind_leaf(_lchild, prev->_lchild);
}
}
}
else //右子树不存在
{
prev = _lchild;
}
delete this; //删除节点
}
}
template<typename elemType>
void BinaryTree<elemType>::remove(const elemType& elem)
{
if (_root) //_root节点仍存在
{
if (_root->_val == elem) //如果此时节点的值已经等于参数elem,则直接删除该根节点
{
remove_root();
}
else //如果此时节点的值不等于参数elem,则通过remove_value函数递归找到该节点并删除
{
_root->remove_value(elem, _root);
}
}
}void BTnode<valType>::remove_value(const valType& val, BTnode*& prev)remove_value第二个参数是一个reference to pointer,因为我们既需要改变pointer所指之物,也要改变pointer本身。
①pointer作为参数: 改变pointer所指之物。
②reference作为参数:改变reference引用本身。
六.清空二叉树
原理:通过递归分左右两条路线进行delete操作来清空二叉树
C++代码:
template<typename elemType>
void BinaryTree<elemType>::clear(BTnode<elemType>*pt)
{
if (pt)
{
clear(pt->_lchild);
clear(pt->_rchild);
delete pt;
}
}七.前、中、后序遍历
原理:以对根的访问顺序来作为分类点。
①.前序遍历:根节点 左节点 右节点
②.中序遍历:左节点 根节点 右节点
③.后序遍历:左节点 右节点 根节点
而访问根节点 左节点 右节点的代码实现如下:
根节点:
display_val(pt, os);左节点:
if (pt->_lchild)
{
preorder(pt->_lchild, os);
}右节点:
if (pt->_rchild)
{
preorder(pt->_rchild, os);
}因此只需要对这三段代码进行排列组合,即可得到三种遍历方法。
C++代码:
//遍历:
//前序
template<typename valType>
void BTnode<valType>::preorder(BTnode* pt, ostream& os)const
{
display_val(pt, os);
if (pt->_lchild)
{
preorder(pt->_lchild, os);
}
if (pt->_rchild)
{
preorder(pt->_rchild, os);
}
}
//中序
template<typename valType>
void BTnode<valType>::inorder(BTnode* pt, ostream& os)const
{
if (pt->_lchild)
{
preorder(pt->_lchild, os);
}
display_val(pt, os);
if (pt->_rchild)
{
preorder(pt->_rchild, os);
}
}
//后序
template<typename valType>
void BTnode<valType>::postorder(BTnode* pt, ostream& os)const
{
if (pt->_lchild)
{
preorder(pt->_lchild, os);
}
if (pt->_rchild)
{
preorder(pt->_rchild, os);
}
display_val(pt, os);
}




![Java高效率复习-线程基础[线程]](https://img-blog.csdnimg.cn/cc96b79b2579424abc2e6ec1846ac666.png)