本文将概述当前动作识别(action recognition)的方法和途径。
为了展示动作识别任务的复杂性,我想举这个例子:

你能明白我在这里做什么吗?我想不能。至少你不会确定答案。我正在钻孔。
你能弄清楚我接下来要做什么吗?

可能也猜不出来。好吧,我的意思是,钉钉子,这很明显。但这个动作的全名应该是“挂画”。
- 在第一个例子中,我们的相机设置是错误的。因此,只有当你有透视能力或知道上下文时,才能识别出这个动作。
- 在第二个例子中,我们有一个非平凡的上下文,其中动作描述具有特定于任务的复杂结构。我见过有几十个类似动作的任务。
而这只是动作识别问题的一小部分。一个有效的算法必须能够稳定地应对如此复杂的情况。我们将不得不面对以下问题:
- 问题陈述的不完整性(动作的边界不明确,不清楚如何处理中间动作)
- 任务解决方案需要大量数据集。
- 现代动作识别的强大算法需要合适的硬件。
- 任务是可变的:新的相机悬挂、不同的衣服、新的动作方式等。
但是,如果事情真的那么糟糕——我就不会写这篇文章了。因此,在这里你可以找到如何偷工减料、解决了哪些问题、最近出现了哪些工作以及问题陈述中包含哪些生活技巧。

NSDT工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器 - REVIT导出3D模型插件 - 3D模型语义搜索引擎 - Three.js虚拟轴心开发包 - 3D模型在线减面 - STL模型在线切割
1、问题定义
让我们先试着构造问题。但是,我马上要说的是,在一般情况下,这是不可能的。什么是“动作”?如果我们看看研究任务“动作识别”,这里也没有共识。第一个最受欢迎的学术数据集包含 2-20 秒的涉及人物情景的镜头片段:
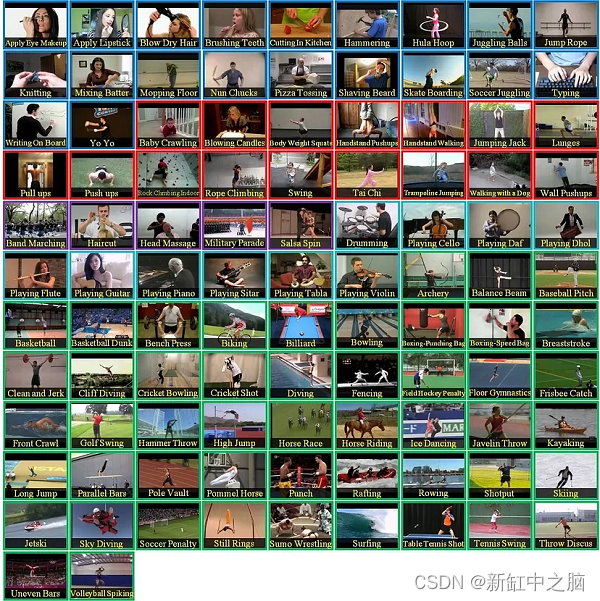
CRCV | Center for Research in Computer Vision at the University of Central Florida
第二受欢迎的数据集包含来自附在衣服上的摄像机的记录:

Moving Objects Dataset: Something-Something v. 2 - Qualcomm Developer Network
但这只是其中很小的一部分。还有“动作分类”、“视频分类”和“自监督动作识别”等任务(这些是部分重叠的任务 1、2、3)。有带骨架的数据集;有带烹饪过程的数据集:

EPIC-KITCHENS Dataset
在某些数据集中,它是短视频;无关紧要的是长视频。
什么是动作?动作是可以在视频上标记的事件,并且事先知道它可以在那里发生。人、机器、动物或其他东西可以产生事件。为什么我更喜欢这个定义?通常,在实践中(99% 的时间),动作识别用于某些确定性过程。确定发生了需要计数/说明/控制的某些事件。
对于实际的 ComputerVision 任务,这个定义通常是正确的,但对于需要“通用定义”的学术研究来说,它并不那么好。它也不适用于所有视频流和内容分析系统。
它有什么不同?什么是“现实世界的任务”?实际任务通常具有有限的数据、摄像机位置和情况。例如,我从未见过需要从任何角度找到 400 种不同动作的任务。相反,现实世界的问题可能是这样的:
- 控制生产中动作的执行
- 监督客户/店员
- 监督厨房中的正确程序
- 用挂在头上/身上的摄像头进行行为控制(运动员、警察等)
- 事故探测器
- 牲畜过程识别
- 等等。
这只是其中很小的一部分。但仍然:
- 摄像头很可能是固定的/至少是拧在人身上的。
- 你需要检测 1-10 个动作。非常非常罕见的是 10-100 个
我将描述的方案通常适用于许多任务。我将从比学术方法简单得多的方法开始。并以更具实验性和学术性的方法结束。
为了清楚起见,在大多数例子中,我将使用人作为参考,从侧面某处看。
我不会在这里写。相同的算法用于视频分析任务。我相信 Youtube 和 Netflix 有很多动作识别和视频分类。
2、区域检测
好的,让我们从一个基本想法开始。假设你想识别某人何时按门铃。你将如何做?
在这种情况下,你能做的最后一件事是从 Papers With Code 的首选开始运行训练。毕竟,从以下内容检测某些东西要容易得多:
- 男人的手靠近门铃
- 一个男人在门口站了一会儿
你不需要火箭科学。一个训练有素的检测器和良好的定位相机就可以工作。工作结果将得到保证和可解释。例如,如果没有检测到手,你可以了解原因 - 并尝试重新训练它(手套/奇怪的光线等)。
所以。物体检测->检查工作区域->检查相关条件工作非常出色:

你不需要知道“牛吃草”的动作,你需要知道她站在哪里
基本思路是,你不需要行动;你需要了解发生了什么。
3、对象检测
方法大致相同,其中动作描述是对象。当然,“在一般情况下”,你手中的煎锅并不意味着什么。但是,了解摄像头安装的环境,它可能是在厨房里“做饭”,在商店里“卖东西”,或者在 PUBG 中“打架”。

通过结合“位置”和“对象”之间的逻辑,你可以组合长动作或动作序列。
对象可以是任何东西。框架中的衣服/产品/汽车等。
4、时序动作
让我们继续讨论处理视频片段的方法。在这里,我会立即将“一段视频”的概念分成两种:
- 使用对象的骨架模型
- 直接处理视频,处理整个视频,处理选定的对象(人,汽车等)
- 组合方法,使用感兴趣的区域,与对象检测器组合,使用一些预处理,如光流……等等,我甚至不会写这些
有什么区别?当你需要处理视频时,神经网络非常不方便。最好有更高的性能、更复杂的数据集和更苛刻的训练。一种摆脱处理视频的方法是预先检测骨架并使用它。这可能是:
人物骨骼:

GitHub - CMU-Perceptual-Computing-Lab/openpose: OpenPose: Real-time multi-person keypoint detection library for body, face, hands, and foot estimation
动物骨骼:
DeepLabCut Benchmark Datasets — DeepLabCut benchmark
手臂骨骼:
InterHand2.6M dataset | InterHand2.6M
脸部点模型:

https://www.epfl.ch/labs/vita/
物体的骨架模型(汽车、沙发等)。当然,更有趣的是那些可以动态的模型,例如挖掘机/机器人/等:

Car Keypoints — OpenPifPaf Guide
骨骼动画会丢失可能至关重要的纹理信息:衣服、与之交互的物体和面部表情……
也可以将两个领域的某些内容结合起来。例如,将骨骼用于可以从骨骼中识别出的部分动作。以及不能使用纹理信息的方法。
5、分类,经典方法
这里有一个很好的实现经典分类的方法集合:
MMAction 是一个基于 MMCV 和 PyTorch 的开发但粗糙的框架。它变得越来越好。但还远远不够完美。
PyTorchVideo 是 Facebook 尝试制作一个模拟,但它仍然很弱。但原生的 PyTorch。
这里有一个很好的文章集合——动作分类,动作识别,来自Papers with code。
从全局来看,任务是按原样设置的,现在仍然是。“输入一堆帧”(或骨架),输出动作。一切都始于 2D 卷积:

2015 год, https://arxiv.org/pdf/1412.0767.pdf
然后的发展对应于经典的“骨干,衰减”:

2020 — https://arxiv.org/abs/2005.06803
将所有内容移至 TimesFormer(所有轴上的transformer):
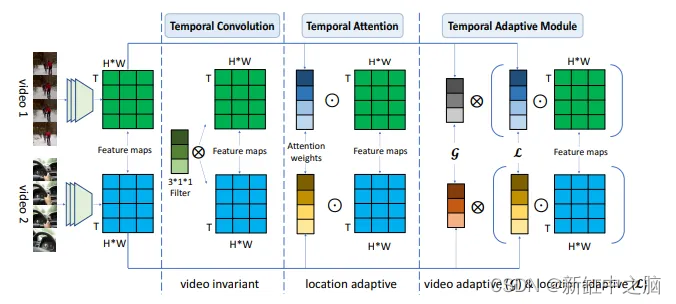
2021 — https://arxiv.org/pdf/2102.05095.pdf
现在他们甚至把 RL 放在了它之上:

2022 — https://arxiv.org/pdf/2112.14238v1.pdf
2023年最流行的是超大型预训练网络(我们稍后会谈到它们)。
注意:此外,所有基准测试通常都在不同的数据集上,因此您无法进行比较。
可能需要注意的是,所有方法都存在相同的问题:
- 数据集。很难构建,也很难标记。常规数据集包含数千个示例。你需要各种人物、姿势和角度(如果这是目标的话)。没有人喜欢组装这样的数据集。
- 收敛。许多模型很难收敛。有时你可以构建一个小的数据集,但它不会收敛。但很难事先估计这一点。例如,我们遇到过在三个数据集上起作用的动作识别模型在第四个数据集上不起作用的情况。很难理解它不起作用的原因。
- 框架不同部分中的相同动作是同一件事吗?在不同的姿势中呢?对于类似的活动,边界会经过哪里?复杂的动作呢?问题的模糊性在动作分类任务中得到了很好的体现。
关于“使用整个视频”与“使用裁剪视频”的工作。选择算法时不要忘记这一点,并正确选择它。你可以一次识别整个视频,也可以识别人物的区域(预先检测和跟踪)。在第一种情况下,帧中有许多人时会出现问题。但是,当帧中有大量信息来帮助识别动作时,它会很好地工作。
此外,关于骨骼动画分类的几句话:那里没有什么魔法。文章很少。最好的作品是 PoseC3D,它属于上述 MMAction。这些作品的主要区别在于精确使用卷积网络,而不是在点阵列上工作的经典方法:

https://arxiv.org/pdf/2104.13586v1.pdf
但是,如你所见,该模型对于 2021 年来说足够简单。并且它有很多地方使用:

https://github.com/open-mmlab/mmaction2
许多网络都在处理点阵列。但是,由于速度快,我更经常使用它们。
6、无监督 / 聚类 / 嵌入
Papers with code中的 Zero-shot 带代码。自监督也在那里。
我能摆脱一些问题吗?是的。你可以摆脱数据集收集和训练。当然,这有利于准确性。
当前顶级方法使用类似 CLIP 的神经网络 + 一些技巧。例如,蒙版视频编码器(或其他一些技巧):
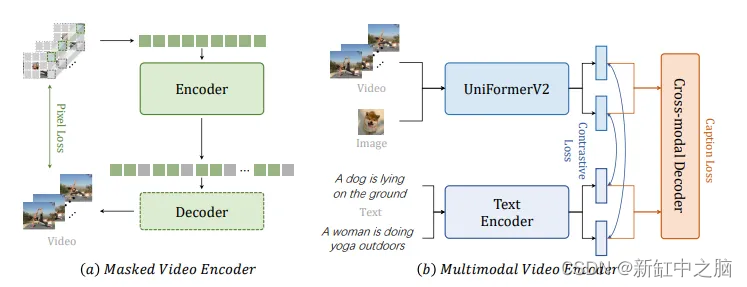
GitHub - OpenGVLab/InternVideo: Video Foundation Models & Data for Multimodal Understanding
一般来说,大多数方法都是基于创建一些表征动作的“嵌入”向量。
但当然,主要问题是一样的。训练数据集与你将使用的数据集有多远?
另一种流行的方法是自监督。当我们在数据集 A 上进行训练,用这个网络标记数据集 B,并在这个“自动标记”的数据上进行训练时。有时可以使用这种方法(当数据集很大但不容易标记时)。
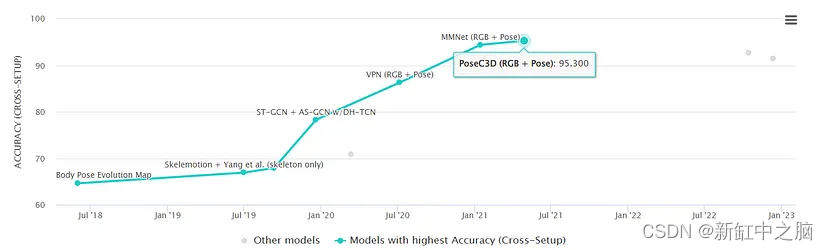
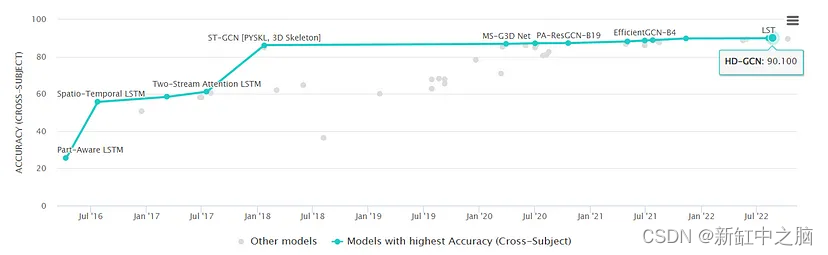
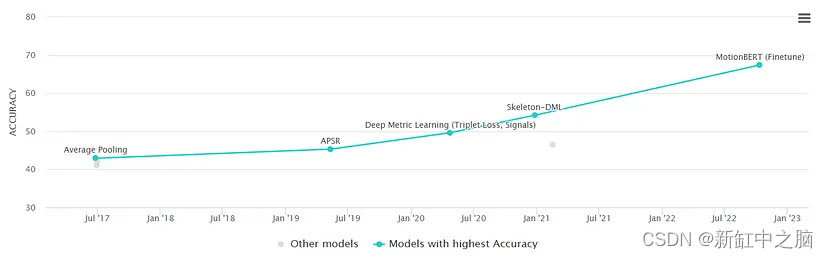
这在近年来准确率如何进步的图像中也很明显(来自 Papers with Code):
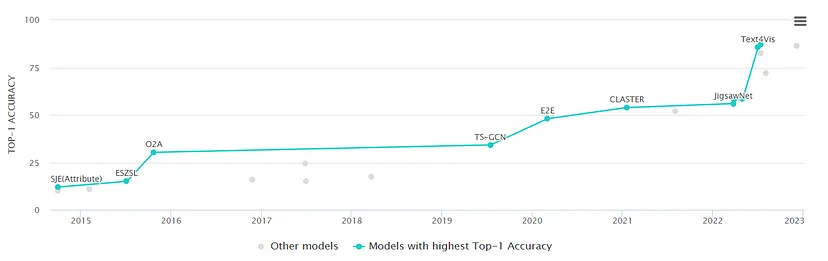
这是无监督的示例(87%)
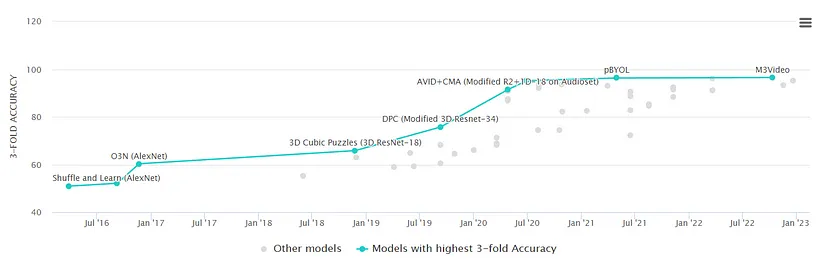
这是自监督的 96%
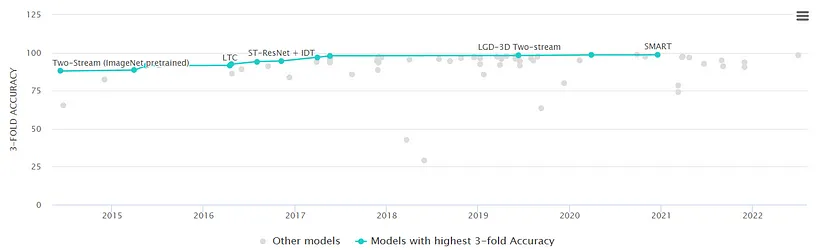
这是一个完全监督的解决方案,准确率 98.6%
关于错误我们稍后会讨论。
随着最新的大型数据集预训练模型的发布,事情将变得相当简单。
7、骨骼和 3D 动画
以下是几个示例。这里许多动作都被骨骼成功识别(我与这家公司合作过很多次):

https://get.cherryhome.ai/howitworks/
对于某些动作,1-2 个示例足以进行训练。但你必须非常小心选择实施的位置。
以下是有关该主题的一些学术论文和排序,以帮助构建逻辑。这里是带有代码的论文。
当然,每个人都通过嵌入来实现这一点,但神奇之处在于如何创建它。
几年前在 ODS Data Fest 上,来自 Yandex 的人对人脸模型(68 分)说了类似的话(骨架嵌入),形成嵌入并使用它们来设置数据集/分类动作:

https://www.youtube.com/watch?v=4qwc_AQv8Z8
但视频是俄语的。
有几个项目为手生成了嵌入。其中一个是这样的:
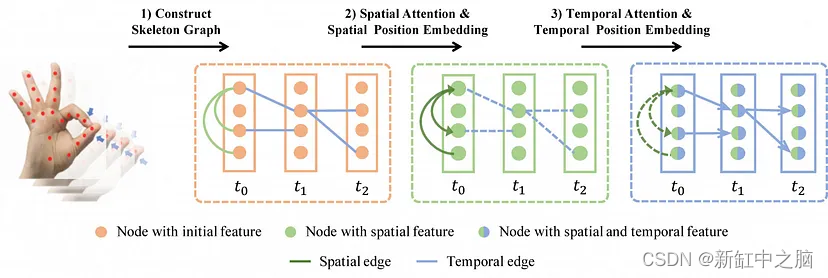
GitHub - yuxiaochen1103/DG-STA
我觉得应该有人在产品中使用它来识别/记住手势。我们已经使用了类似的方法进行时间手部过滤和咀嚼速度计算。
所以,总结一下——文章很少,但我经常在产品中看到它们。
计算简单,易于训练(你不必在另一个数据集上进行训练),逻辑简单。如果将其与传统方法进行比较:
全视频分类
 骨架基础分类
骨架基础分类
基于骨架的一次性动作识别(上篇文章不是“骨架”而是骨架+3d网格)
错误也有所不同!
8、预训练
近年来的一个趋势是出现了强大的预训练网络。近年来最有趣的网络是 InterVideo。但到目前为止,只有一些声明的功能出现在开源中。它看起来很神奇:
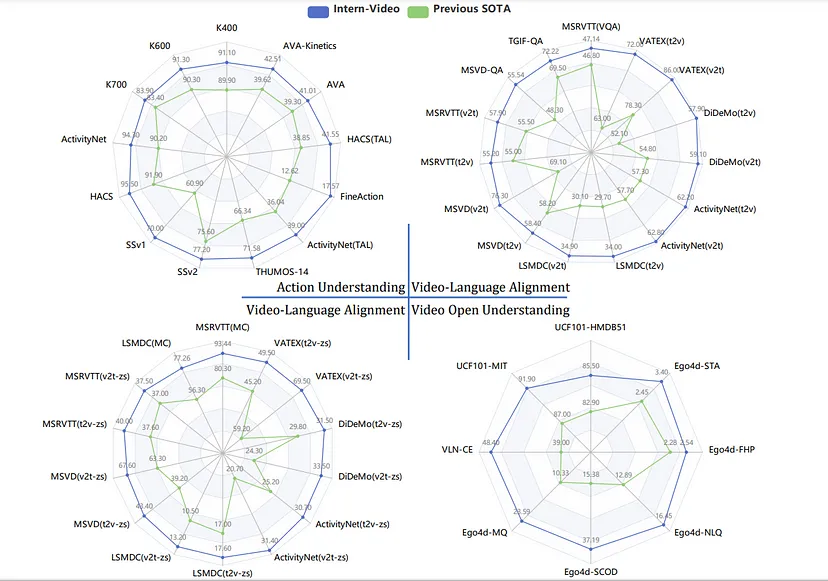
https://arxiv.org/pdf/2212.03191.pdf
并非所有事情都令人兴奋。这样的网络只需训练一次,因为要只教授网络的一部分,你需要 128 个 A100 持续两周。
在 Inter Video 的情况下,它是两个编码器的训练:
- 蒙版视频编码器
- 类似 CLIP 的神经网络
在此之后,对下游任务进行transformer训练。
未来几年,这一领域可能会取得重大进展。当前的实现将变得更快,使用调整的成本也更低。
9、无监督与监督
然而,我描述了监督和无监督方法。哪一个更容易/更快/更方便?哪一个在哪里使用?
同样,这个问题没有明确的答案:
- 如果你只有几个动作并且可以构建一个数据集,最好使用监督。它更准确、更稳定、更可预测。
- 无监督通常用于数据挖掘。有时用于一些初步分析。
- 无监督在纯视频上更难提取,在骨架上更容易提取。这又是一个限制。
- 所以,你可以同时使用它们。首先运行无监督,然后慢慢进入监督。
- 奇怪的是,有些动作/例子类别在无监督下表现不佳。通常,这些动作具有很高的可变性。例如,你不能对一个动作进行稳定的嵌入。一个很好的例子是跳舞。有数百种。而且没有稳定的嵌入。但常规训练效果相当不错。
正如我之前提到的,在 OneShot 视频数据集上,错误率相差三倍。而在 OneShot 骨架和骨架之间的数据集上,错误率相差三倍,等等。
但在这里,你必须明白错误率并不统一。有些动作几乎可以完美地被 OneShot 识别。这些主要是与纹理没有交互的短动作。最好是没有变化的活动。例如,你可以用一百种方式“摔倒”。但“从地板上捡起盒子”可能只有一种正确方式,而有两三种方式是错误的。对于某些算法来说,角度至关重要。
如果你正确设置了问题,你可以大大地偷工减料。
10、结束语
我将从头开始。在我看来,对于非学术性的动作识别任务,开头描述的更直接的方法通常就足够了。只有百分之几的任务需要良好的动作识别。
解决问题时,你必须回答几个问题:
- 我需要准确的动作识别,还是将就使用可理解的逻辑?
- 我需要骨架,还是使用视频?
- 我需要 One-Shot 方法提供的灵活性,还是需要准确度和处理复杂动作的能力?
- 预先训练的网络可以处理我的数据吗?这种神经网络的速度是否足够?
这些问题的答案将大大简化和加快你的任务。
原文链接:动作识别综合指南 - BimAnt