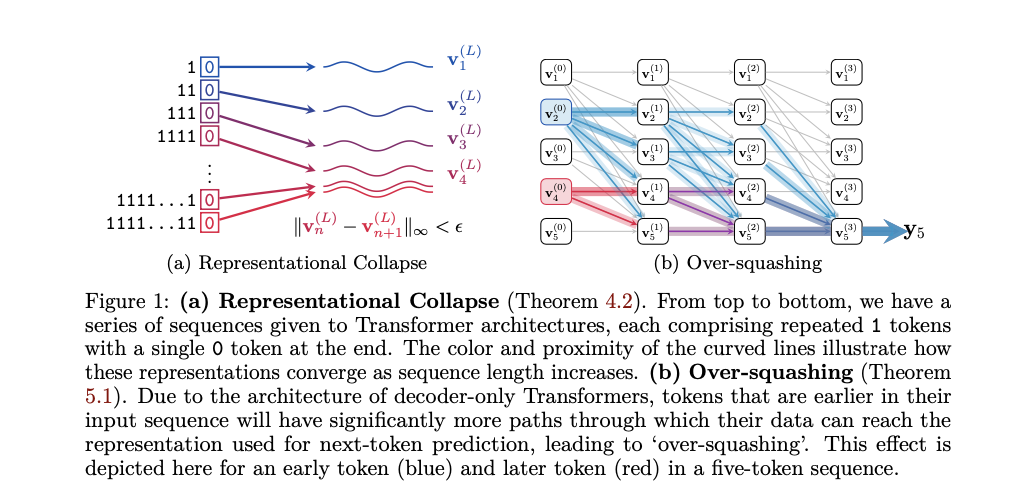
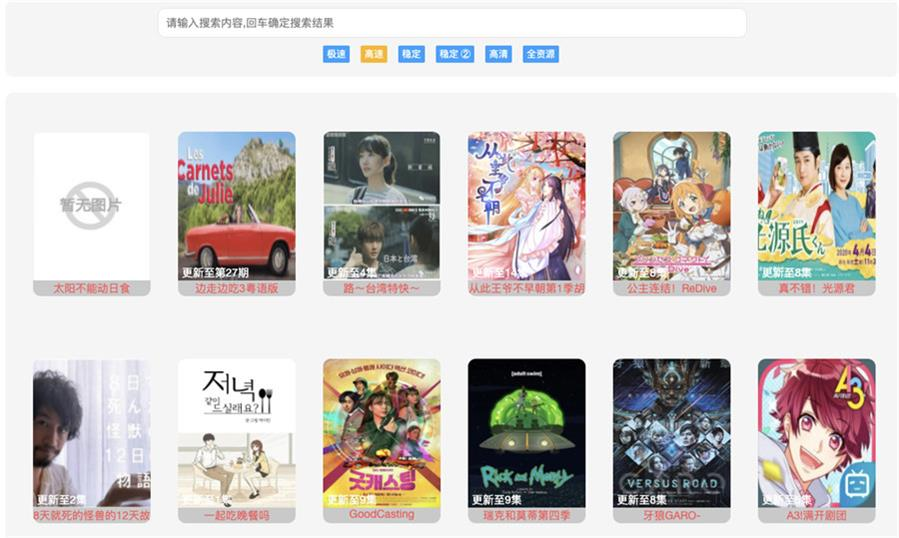
从json格式数据中抽出句子和标签
首先查看json格式的数据文件:
:~/nlp/tnews/src$ less train.json
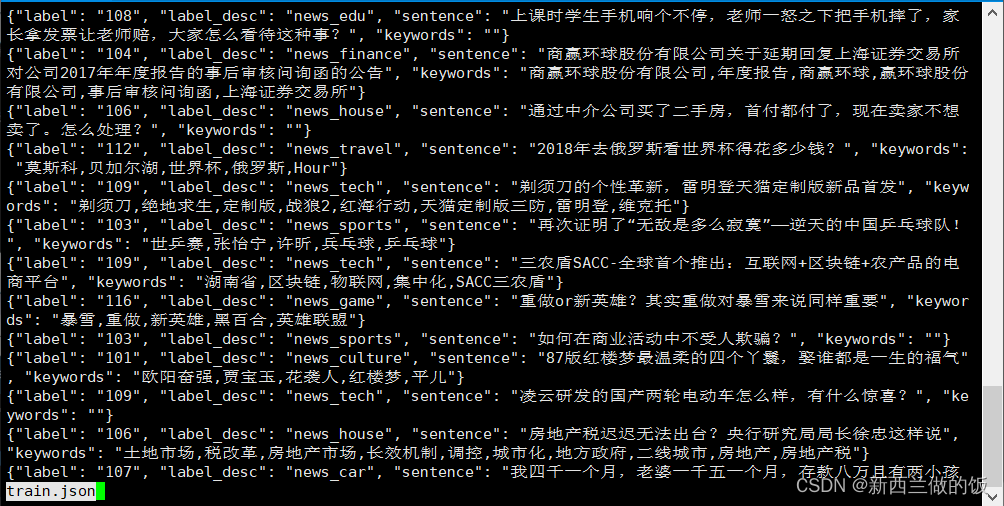
可以看到json字符串表示一个对象,我们利用json.loads() 函数会将其转换为一个 Python 字典。docs python json
#ext.py
#encoding: utf-8
import sys
from json import loads
def handle(srcf, rsf, rstf):#打开三个文件,将句子写入rsf,将标签写入rstf
ens = "\n".encode("utf-8")
with open(srcf,"rb") as frd, open(rsf,"wb") as fwrts, open(rstf, "wb") as fwrtt:
for line in frd:
tmp = line.strip()
if tmp:
tmp = loads(tmp.decode("utf-8"))#将json对象取出转换成字典
src, tgt = tmp.get("sentence",""), tmp.get("label_desc", "")#python dict的get方法,取出sentence标签的值,若不存在则返回空串
if src and tgt: #若非空
fwrts.write(src.encode("utf-8"))
fwrts.write(ens)
fwrtt.write(tgt.encode("utf-8"))
fwrtt.write(ens)
if __name__=="__main__":
handle(*sys.argv[1:])
在命令行输入:
:~/nlp/tnews/src$ python ext.py train.json src.train.txt tgt.train.txt
:~/nlp/tnews/src$ python ext.py dev.json src.dev.txt tgt.dev.txt
得到的分别为原数据中训练集以及验证集中的句子和标签,src.文件中每个句子占一行,tgt.文件中每个句子的类别占一行。
对训练集和验证集做数据的预处理
随后我们对这四个提取出来的数据文件做数据预处理的编码规范化以及繁体转简体,得到四个预处理后的文件:
:~/nlp/tnews$ python ~/bin/text-tools/data/normu8.py src.train.txt - | python ~/bin/text-tools/data/zht2s.py - src.train.s.txt &
:~/nlp/tnews$ python ~/bin/text-tools/data/normu8.py src.dev.txt - | python ~/bin/text-tools/data/zht2s.py - src.dev.s.txt &
:~/nlp/tnews$ python ~/bin/text-tools/data/normu8.py tgt.dev.txt - | python ~/bin/text-tools/data/zht2s.py - tgt.dev.s.txt &
:~/nlp/tnews$ python ~/bin/text-tools/data/normu8.py tgt.train.txt - | python ~/bin/text-tools/data/zht2s.py - tgt.train.s.txt &
def handle(srcf, rsf, d="t2s"):
with sys.stdin.buffer if srcf == "-" else open(srcf, "rb") as frd, sys.stdout.buffer if rsf == "-" else open(rsf, "wb") as fwrt:
在normu8.py和zht2s.py中添加以上代码,如果输入是字符‘-’则从输入缓冲区中读文件,如果输出文件是字符‘-’则将文件写入输出缓冲区中。
这样做的好处是可以将文件在命令行中串起来,避免生成中间我们不需要的文件。例如:
python normu8.py tgt.train.txt - | python zht2s.py - tgt.train.s.txt &
顺序执行命令行,normu8.py输入文件是tgt.train.txt,输出文件是-,那么就把经过处理的输入文件输出到sys.stdout.buffer缓冲区中,利用管道线将前半部分的输出给后半部分的输入,执行zht2s.py输入是-,则从sys.stdin.buffer缓冲区中读入,输出文件是tgt.train.s.txt,则写入到这个文件中。
缓冲区在内存中,在缓冲区操作比文件操作要快很多。
执行预处理后查看他们的行号,发现行号正常:
:~/nlp/tnews/src$ wc -l *.s.txt
10000 src.dev.s.txt
53360 src.train.s.txt
10000 tgt.dev.s.txt
53360 tgt.train.s.txt
126720 总计
接着,对编码规范化后的文件分词并查看分词后的词表大小:
:~/nlp/tnews/src$ python ~/nlp/token/seg.py src.train.s.txt src.train.c.txt &
:~/nlp/tnews/src$ python ~/nlp/token/seg.py src.dev.s.txt src.dev.c.txt
:~/nlp/tnews/src$ python ~/nlp/token/vcb.py src.train.c.txt
67733
对训练集和验证集做子词切分
:~/nlp/tnews/src$ subword-nmt learn-bpe -s 8000 < src.train.c.txt > src.cds
由于文件词表本身的长度较小,因此合并操作不能太多,我们设置学习8000个词,随后利用得到的词表进行子词切分,并得到每个子词的频率src.bvcb:
:~/nlp/tnews/src$ subword-nmt apply-bpe -c src.cds < src.train.c.txt | subword-nmt get-vocab > src.bvcb
最后我们设置阈值8,利用学习到的src.bvcb子词频率表来对整个子词表进行过滤,得到最终完整的经过bpe算法处理后的文件:
:~/nlp/tnews/src$ subword-nmt apply-bpe -c src.cds --vocabulary src.bvcb --vocabulary-threshold 8 < src.train.c.txt > src.train.bpe.txt
:~/nlp/tnews/src$ subword-nmt apply-bpe -c src.cds --vocabulary src.bvcb --vocabulary-threshold 8 < src.dev.c.txt > src.dev.bpe.txt
我们可以查看bpe算法后的分词效果:
less src.train.bpe.txt

less src.dev.bpe.txt

统计词表中每个子词在该类别出现的频率
#p.train.py
#encoding: utf-8
import sys
from json import dump
from math import log
def count(srcf, tgtf):
#{class: {word: freq}} #model为字典嵌套,外层为每个类别,内层统计每个类别出现的子词频率
model = {}
with open(srcf,"rb") as fsrc, open(tgtf,"rb") as ftgt:
for sline, tline in zip(fsrc, ftgt):
_s, _t = sline.strip(), tline.strip()
if _s and _t:
_s, _class = _s.decode("utf-8"), _t.decode("utf-8")
if _class not in model:#如果model中没有这个类别
model[_class] = {}#为model中这个类别作初始化
_ = model[_class]#取出model中_class的类别的字典
for word in _s.split():#遍历一行里面空格隔开的每个分词
_[word] = _.get(word,0) + 1 #出现一次则将分词的词频+1
return model
def log_normalize(modin):#将子词出现次数转化成频率
rs = {}
for _class, v in modin.items():#遍历整个词典;键为modin.keys(),值为modin.values()
_ = float(sum(v.values()))#统计这个类别中所有子词出现的总个数,转化成浮点数
rs[_class] = {word: log(freq / _) for word, freq in v.items()}#遍历所有的子词,用每个子词出现的频率除以总数
#为了防止溢出,将频率取对数
return rs#得到的rs字典即为每个子词在这个类别中出现的频率
def save(modin, frs):
with open(frs, "w") as f:
dump(modin, f) #用dump方法向文件写str
if __name__=="__main__":
save(log_normalize(count(*sys.argv[1:3])),sys.argv[3])
#第一和第二个文件传给count,之后将返回model字典传给log_normalize,再将第三个写入文件传给save保存
为了防止因为频率太低导致的精度丢失,我们将频率取对数后存储成json格式文件:
:~/nlp/tnews/src$ python p.train.py src.train.bpe.txt tgt.train.s.txt logp.model.txt
查看logp.model.txt文件,由于log(a)+log(b)=log(ab),我们可以采用对取log后的频率相加得到组合子词的概率对数:
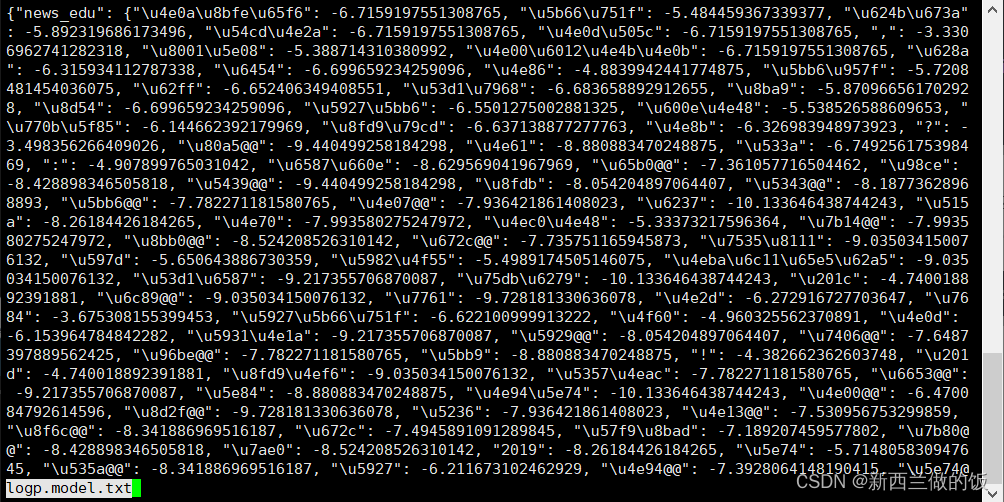
对每行每句话的类别作预测、比较准确率
#pnorm.predict.py
#encoding: utf-8
import sys
from json import loads
from math import inf
def load(fname):
with open(fname, "r") as f:
model = loads(f.read())#从json对象取出转化成字典
return model
#model: {class: {word,logp}}
def predict_instance(lin, model):
_max_score, _max_class = -inf, None
for _class, _cd in model.items():#取出 类别 和 {子词 : log频率}
#_s = sum([_cd.get(word, 0.0) for word in lin])
_s = 0.0 #记录总分数
_n = 0 #记录总词数
for word in lin: #遍历每行的分词
if word in _cd: #如果分词在分词表里面
_s += _cd[word] #累加总频率
_n += 1 #总词数+1
if _s > 0.0: #排除n=0的情况
_s = _s / _n #求平均分数
if _s > _max_score: #更新每行出现词标签频率最高的logp以及类别
_max_class = _class
_max_score = _s
if _max_class is None:
_max_class = _class
return _max_class, _max_score#返回封装成一个tuple:(_max_class,_max_score)
def predict(fsrc, fmodel, frs):
model = load(fmodel)
ens = '\n'.encode("utf-8")
with open(fsrc, "rb") as frd, open(frs, "wb") as fwrt:
for line in frd:
_ = line.strip()
if _: #将每行数据传入predict_instance()函数
_ =predict_instance( _.decode("utf-8").split(), model)[0]#取出类别_max_class
fwrt.write(_.encode("utf-8")) #将类别写入文件,作为每行(每句话)的预测类别
fwrt.write(ens)
if __name__=="__main__":
predict(*sys.argv[1:])
我们对整个model文件进行遍历,统计每句话的分词出现的频率,在遍历完整个model后,会得到一句话中分词出现频率最高的情况,将这个分词属于的类别标记为这句话的类别。
在命令行执行输入以下代码,src.dev.bpe.txt是分词后的验证集;模型文件是logp.model.txt,是json格式的文件;最后pred.dev.txt 是预测的标签写入的文件。
:~/nlp/tnews$ python pnorm.predict.py src.dev.bpe.txt logp.model.txt pred.dev.txt
查看pred.dev.txt文件:

可以看到,预测是股票类的句子最多。下面我们统计对比预测的准确率:
#acc.py
#encoding: utf-8
import sys
def handle(predf, ref):
t = c = 0 #t是总标签数,c是预测正确的标签数
with open(predf, "rb") as fp, open(ref, "rb") as fr:
for lp, lr in zip(fp, fr):
_p, _r = lp.strip(), lr.strip()
if _p and _r:
_p, _r = _p.decode("utf-8"), _r.decode("utf-8")
if _p == _r:
c += 1 #如果预测正确,累加c
t += 1 #统计总标签数
return float(c) / t *100.0 #返回预测的准确率
if __name__ == "__main__":
print(handle(*sys.argv[1:]))
第一个输入文件是预测的标签文件,第二个是真实的验证集标签:
:~/nlp/tnews$ python acc.py pred.dev.txt tgt.dev.s.txt
0.44999999999999996
预测的准确率大约是是0.45%,这个准确率是很低的。
准确率分析
将模型加载到内存中,我们查看模型文件的全部类别:
>>> from predict import load
>>> model=load("logp.model.txt")
>>> model.keys()
dict_keys(['news_edu', 'news_finance', 'news_house', 'news_travel', 'news_tech', 'news_sports', 'news_game', 'news_culture', 'news_car', 'news_story', 'news_entertainment', 'news_military', 'news_agriculture', 'news_world', 'news_stock'])
接着,我们查看逗号这个分词在不同类别中的频率:
>>> model["news_edu"][',']
-3.3306962741282318
>>> model["news_finance"][',']
-3.507571369597401
>>> model["news_house"][',']
-3.1864756857742638
可以看到,由于log函数的单调性,在以上三个类别中逗号在news_house标签中的频率最高,因此对最终句子标签的判定产生影响。
因为 ',' 实际上并不具有标签的意义,只是作为标点符号存在,但在我们的模型以及判定方法中,对结果产生了不良影响。又由于逗号大量的存在,故使得准确率大大降低。
TF-IDF算法
TF(Term Frequency)即词频,表示某一词在某类文档中出现的频率,我们上文所求的logp中的p即为TF,公式是:
T
F
=
某类词中某个词出现的次数
这类词的总词数
TF=\frac {某类词中某个词出现的次数}{这类词的总词数}
TF=这类词的总词数某类词中某个词出现的次数
上面的例子中,逗号在news_house标签中的频率最高,TF值最大,因此TF认为逗号是此类别的单词。
IDF(Inverse Document Frequency)即逆向文件频率,表示一个词在整个语料库中的普遍性。IDF值越高,说明其频率越低,越能代表不同的文档。公式为:
I
D
F
(
t
)
=
log
(
N
d
t
)
IDF(t)= \log(\frac{N}{d_t})
IDF(t)=log(dtN)
N为文档总数,d_t为包含词语的文档数。上面的例子中,逗号广泛存在于几乎所有的类别文本中。因此,他的IDF值会极低,甚至接近于0.
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
T
F
−
I
D
F
=
T
F
∗
I
D
F
TF-IDF=TF*IDF
TF−IDF=TF∗IDF
这样,对逗号的TF值乘以IDF值作为总体的值,则最终值会受到IDF值的影响而变得极小。则逗号就会大大减弱用其来分类文本的作用。
我们修改p.train.py,来求每个子词的 TF-IDF值,我们将类别的粒度设置在class,也就是说N为15(总标签数),d_t为每个子词拥有的标签数。
#tfidf.train.py
#encoding: utf-8
import sys
from json import dump
from math import log
def count(srcf, tgtf):
#{class: {word: freq}} #model为字典嵌套,外层为每个类别,内层统计每个类别出现的子词频率
model = {}
with open(srcf,"rb") as fsrc, open(tgtf,"rb") as ftgt:
for sline, tline in zip(fsrc, ftgt):
_s, _t = sline.strip(), tline.strip()
if _s and _t:
_s, _class = _s.decode("utf-8"), _t.decode("utf-8")
if _class not in model:#如果model中没有这个类别
model[_class] = {}#为model中这个类别作初始化
_ = model[_class]#取出model中_class的类别的字典
for word in _s.split():#遍历一行里面空格隔开的每个分词
_[word] = _.get(word,0) + 1 #出现一次则将分词的词频+1
return model
def getidf(modin):
rs = {}
for v in modin.values():
for word in v.keys():
if word in rs:
continue
for _class in modin.keys():
dic = modin[_class]
if word in dic :
rs[word] = rs.get(word,0) + 1
_ = len(modin) #统计所有类别的个数
return {word: -log(freq / _) for word, freq in rs.items()}# 返回{分词:分词出现的类别数/总类别数}
def tfidf(modin)
idf = getidf(modin)
rs = {}
for _class, v in modin.items():#遍历整个词典;键为modin.keys(),值为modin.values()
_ = float(sum(v.values()))#统计这个类别中所有子词出现的总个数,转化成浮点数
rs[_class] = {word: (freq / _ * idf[word]) for word, freq in v.items()}
#tf * idf
return rs#得到的rs字典即为每个子词的 tf * idf 值
def save(modin, frs):
with open(frs, "w") as f:
dump(modin, f) #用dump方法向文件写str
if __name__=="__main__":
save(tfidf(count(*sys.argv[1:3])),sys.argv[3])
和仅基于TF算模型的步骤相似,在命令行输入:
:~/nlp/tnews$ python tfidf.train.py src.train.bpe.txt tgt.train.s.txt model/tfidf/model.txt
:~/nlp/tnews$ python predict.py src.dev.bpe.txt model/tfidf/model.txt pred.tfidf.dev.txt
:~/nlp/tnews$ python acc.py pred.tfidf.dev.txt tgt.dev.s.txt
47.4
可以看到,经过TF-IDF算法调整后,模型预测的准确率可以达到47.4%,相比于之前的0.45%有显著的提高。
![[大模型]Phi-3-mini-4k-instruct langchain 接入](https://img-blog.csdnimg.cn/direct/dc2da995c6774ca7b9aa54bf7e52df2c.png#pic_center)




![[C][数据结构][排序][下][快速排序][归并排序]详细讲解](https://img-blog.csdnimg.cn/direct/c796ea2467cc4ed2b904f1fa55adb17f.png)