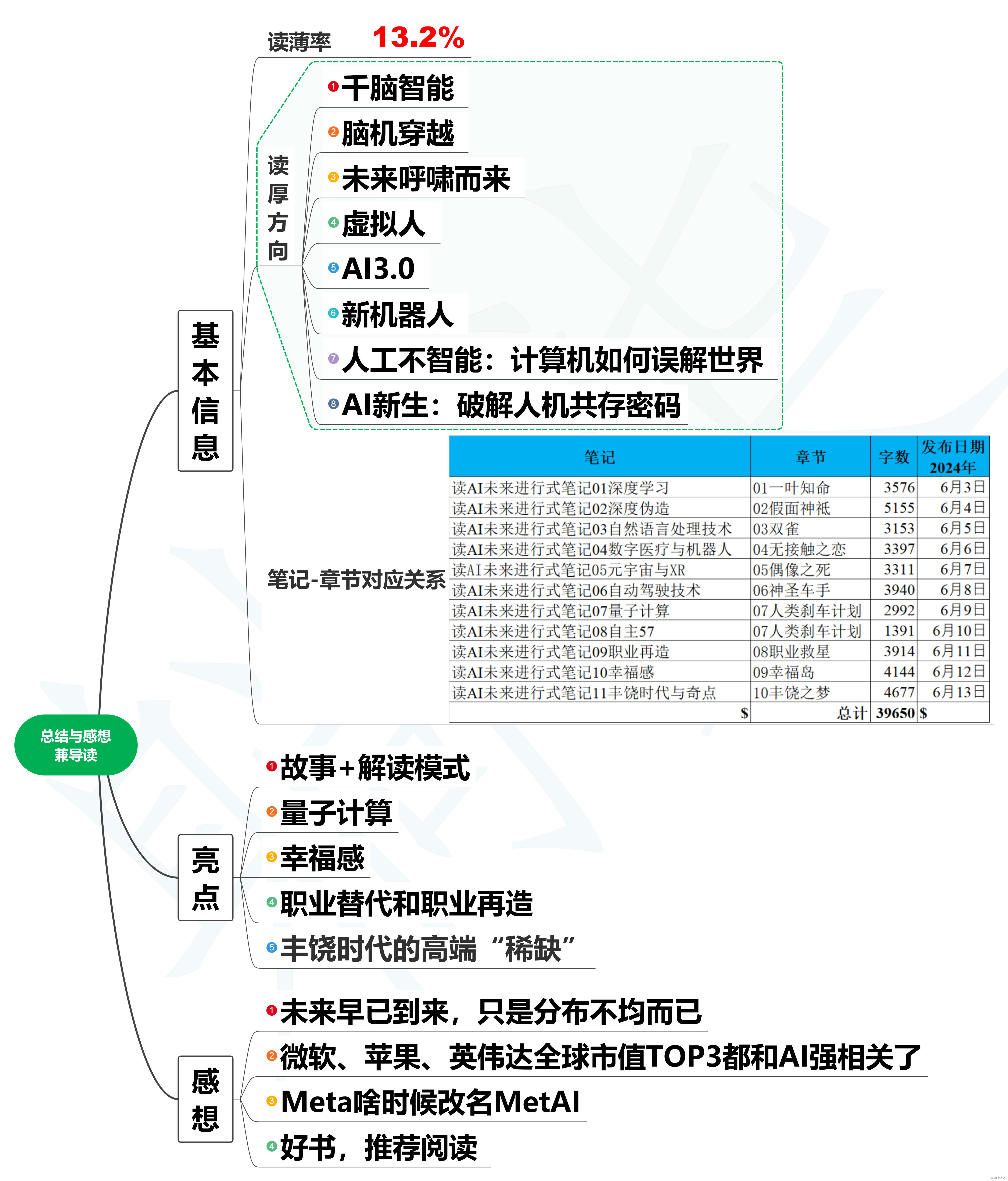
目录
一.CRUD
1.什么是CRUD
2.CRUD的特点
二.新增(Create)
单列插入+全行数据
表的复制
额外小知识
三.阅读(Read)
1.全表查询+指定列查询
2.查询字段为表达式
3.别名
编辑
4.去重
5.排序
1.根据列名进行排序
2.使用表达式及别名进行排序
3.可以对多个字段进行排序,排序优先级随书写顺序
6.条件查询:WHERE
1.比较操作符
2.逻辑运算符
7.分页查询
8.聚合查询
9.联合查询
笛卡尔积
解决方法
表名.列名=表名.列名
内连接(INNER JOIN)
外连接
自连接
10.合并查询
UNION
UNION ALL
11.子表查询(了解)
四.修改(UPDATE)
1.基本操作
五.删除(DELETE)
数据库约束条件
1.非空条件(NOT NULL)
2.唯一约束(UNIQUE)
3.主键约束(PRIMARY KEY)
自增长(AUTO_INCREMENT//AUTOINCREMENT/IDENTITY)
4.外键约束(FOREIGN KEY)
5.默认值约束(DEFAULT)
6.检查约束(CHECK)

在前一章,已经讲述了表是如何创建的,以及表是如何删除的。本章就讲解如何对表进行操作。
一.CRUD
1.什么是CRUD
CRUD即Create(新增)、Read(阅读)、(Update)更新、(Delete)删除。
2.CRUD的特点
- 灵活性:CRUD操作提供了对数据库数据的高度灵活性,可以根据需要添加、修改、删除和检索数据。
- 原子性:在事务处理中,这些操作通常是原子性的,即它们要么全部成功,要么全部失败,保证了数据的一致性。
- 安全性:通过使用WHERE子句和其他条件,可以限制对数据的访问,防止意外更改或删除重要数据。此外,还可以通过权限设置来限制用户对数据库的CRUD操作。
- 效率:优化的CRUD操作可以提高数据库性能。例如,使用索引可以加速查询,而批量插入可以减少多次写入的开销。
- 可扩展性:随着数据的增长,CRUD操作可以轻松适应,允许数据库管理系统处理大量数据。
- 标准化:CRUD操作遵循SQL标准,使得不同数据库系统之间的代码移植成为可能。
- 事务支持:MySQL支持事务处理,确保在多步骤操作中,如果其中一个步骤失败,整个事务可以回滚,保持数据的完整性。
- 错误处理:当CRUD操作遇到错误时,MySQL会返回错误信息,帮助开发者诊断并解决问题。
- 日志记录:MySQL通常记录所有的CRUD操作,以便在需要时进行审计或恢复操作。
- 并发控制:在多用户环境中,MySQL通过锁机制和行级锁定来管理并发的CRUD操作,避免数据冲突。
二.新增(Create)
在创建一个表之后,我们想要在表数据库表中添加新的记录,那么我们就得使用INSERT语句。
示例:创建一个学生表,要求这个表中要学生编号、姓名、以及学号;
注意:要创建表,首先要用一个数据库,并且使用,若字符想输入的是中文,那么就需要指定支持中文的字符集,例如utf8。
#创建数据库
create database if not exists test;
#使用数据库并指定字符集
use test character set utf8;
-- 创建学生表
create table student(seque int,student_name varchar(20),Student_ID int(11));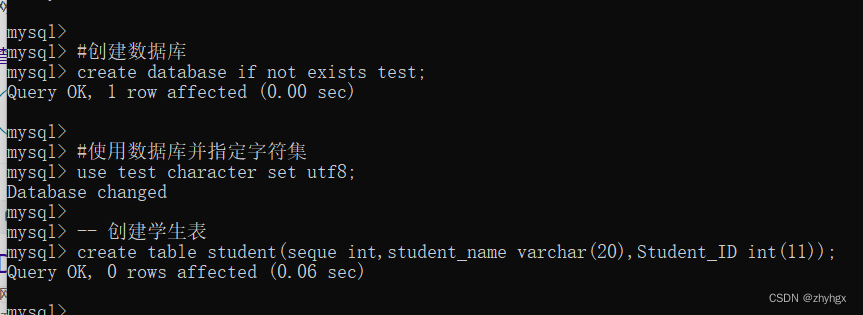
单列插入+全行数据
-- 单行插入
insert into 表名 (列名,列名,列名,...) values(值,值,值,...);
-- 多行插入
insert into 表名 (列名,列名,列名,...)
values(值,值,值,...),
(值,值,值,...),
(值,值,值,...);注意:
- 对于全行数据插入时,列名可以省略不写
- 对于指定列插入时,需要在表后写相应的列名,并且在输入值的时候要对于相应的列名输入值。
- 在插入数据的时候,表中有多少列,相应插入的value值就要有多少个。(在没有指定列的情况下)
示例:
-- 单行插入+全列
insert into student values(6,"李逵",11223);
-- 单行插入+指定列
insert into student (student_name,Student_ID) values("宋江",11267);
-- 多行插入+全列输入
insert into student values(2,"猪八戒",1123),
(3,"孙悟空",1124);
-- 多行插入+指定列
insert into student (student_name,Student_ID)
values("李四",1125),
("王五",1126);

表的复制
在数据库中,复制一个表通常涉及创建一个新的表结构,并可能根据需求复制原有表的数据。
若想要把一个表中的满足特定条件的数据移动到一个新表中,我们若一个一个移动,效率不高,所以,可以使用插入+查询
--复制表中的数据并插入新表中
insert into 新表名 select 列名,列名,... from 旧表;
insert into 新表名 select * from 旧表;
示例:
-- 学生表1
create table student1(id int ,name varchar(20));
-- 学生表2
create table student2(id int ,name varchar(20));
-- 在表1中插入4个学生的信息
insert into student1 values(1,"张三"),(2,"李四"),(3,"王五"),(101,"赵六");
-- 将表1中序号在前100的学生复制到表2中
insert into student2 select * from student1 where id<100;
额外小知识
create table student(seque int,student_name varchar(20),Student_ID int(11));以学生表为例,在插入的时候,seque是int类型,student_name是varchar类型,Student_ID是int类型。
在下图,在seque和Student_ID插入的是字符串类型,而在student_name中反而插入的是整型,结果可以插入。但是如果想在seque中插入非数字的数据,却会报错。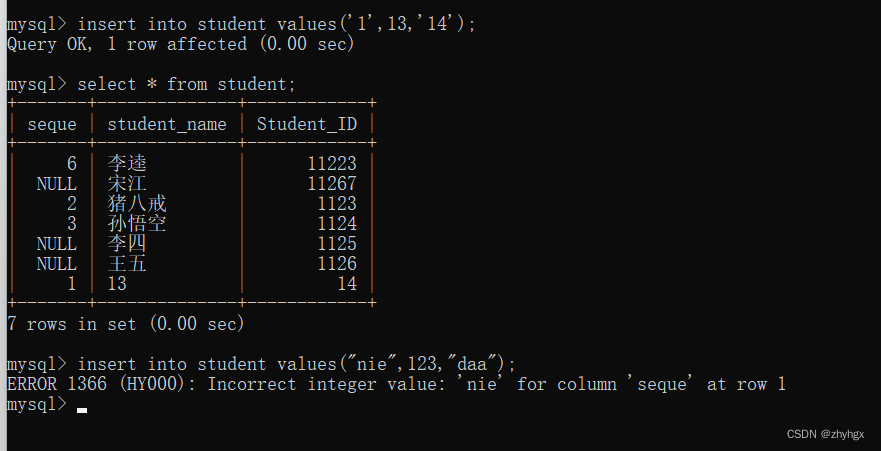
在插入数据的时候,虽然values后面第一列写的是字符串类型,但是MySQL会尝试自动转成int类型,对于第二列,写的是int类型,也会尝试自动转成字符串类型。在第二条插入语句中,由于字符串不是数字,无法转换成int类型的数据,因此会报错。
上述就是隐式类型转换。
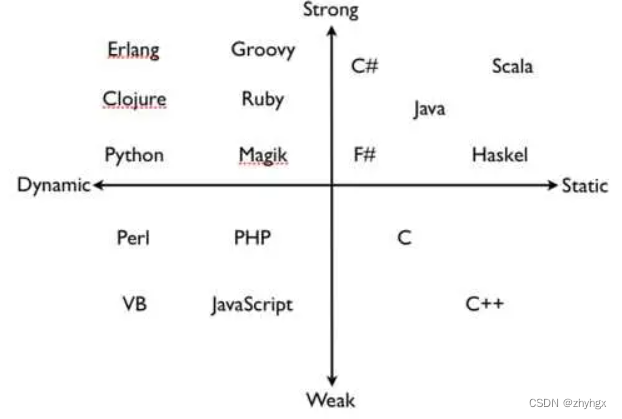
对于比较支持隐式类型转换的,称为“弱类型系统”;
对于不太支持隐式类型转换的,称为“强类型系统”。
静态类型:编译时就知道变量类型的是静态类型;例如,C,C++,Java等。
- 优点:
- 类型严格,在编译的时候就知道变量类型,提供了清晰的结构和早期的错误检测。编译器可以进行更有效的优化。
- 缺点:
- 需要对每个变量声明类型,增加了代码量和复杂性。
- 灵活性降低:类型约束可能会导致代码更难进行某些类型的重构。
动态类型:运行时才知道一个变量类型的叫做动态类型。例如,Python,js,PHP等。
- 优点:
- 快速开发:无需声明类型,可以快速编写和测试代码。
- 灵活性:可以轻松修改数据类型。
- 简洁的代码:不需要类型声明,代码更短,易于阅读。
2.缺点:
- 运行时错误:类型错误可能在运行时才暴露,导致难以调试。
- 维护困难:没有类型信息,代码可能更难以理解和维护,尤其是在大型项目。
三.阅读(Read)
在MySQL中,想要查看已经插入的数据信息,需要用select语句进行查看。
1.全表查询+指定列查询
-- 全表查询
select * from 表名;
-- 指定列查询
select 列名,列名,列名,... from 表名;注意:通常情况下,不建议使用*(通配符,可以指定全列)进行全列查询,查询的列越多,意味着需要传输的数据量越大;可能会影响到索引的使用。
示例:
查看学生表
-- 查看全列
select * from student;
-- 查看学生名和学号
select student_name,Student_ID from student;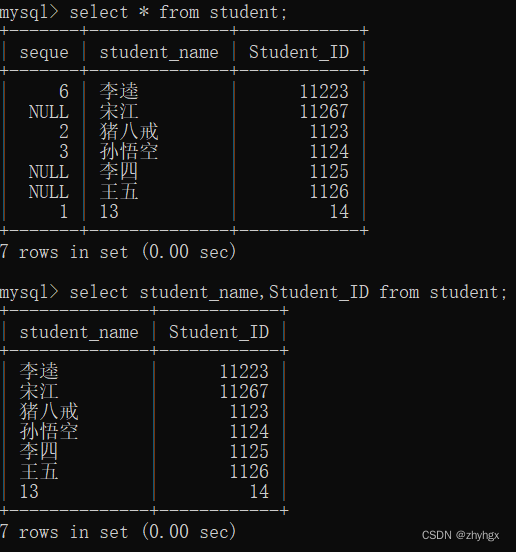
2.查询字段为表达式
-- 表达式不包含字段
SELECT id, name, 10 FROM exam_result;
-- 表达式包含一个字段
SELECT id, name, english + 10 FROM exam_result;
-- 表达式包含多个字段
SELECT id, name, chinese + math + english FROM exam_result3.别名
为查询结果中的列指定别名,表示返回的结果集中,以别名作为该列的名称,语法:
SELECT column [AS] alias_name [...] FROM table_name;示例:
-- 创建一个学生表来记录成绩
create table students(id int,name varchar(20),Chinese decimal,Math decimal,English decimal);
-- 在表中插入数据
insert into students values(1,"张三",78,88,75),
(2,"李四",87,78,90),
(3,"王五",88,86,73),
(4,"赵敏",98,88,76);
-- 查询学生的成绩总分,并给将三科总分起别名exam_result
select id,name,Chinese+Math+English as exam_result from students;
4.去重
在查表的时候,可能会遇到多组重复的数据,若只想显示其中一个,可以使用DISTINCT关键字对某列数据进行去重。
示例:
-- 查看学生表中学生的数学成绩
select math from students;
-- 进行去重
select distinct math from students;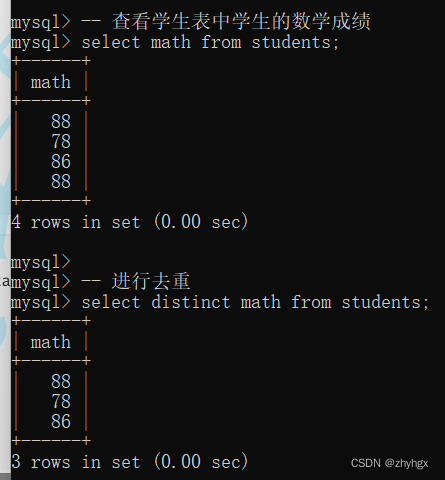
5.排序
在查看表中数据时,返回的数据都是无序的,观赏度差,可能使用ORDER BY进行排序。
SELECT 列名,列名,... FROM 表名 ORDER BY 列名 ASC/DESC;
ASC为升序,DESC 为降序,默认升序。
没有ORDER BY 的子句查询,返回的顺序都是无序的,不能依赖此顺序;
NULL数据排序,视为比任何值都小,升序时出现在最上面,降序时出现在最下面。
示例:
1.根据列名进行排序
以学生表为例,按照数学成绩进行排序
-- 按照数学成绩进行排序
select * from students order by Math;
2.使用表达式及别名进行排序
以学生表为例,按照三科总分进行升序,并将总分为设为exam_result;
select id,Chinese+Math+English as exam_result from students order by exam_result;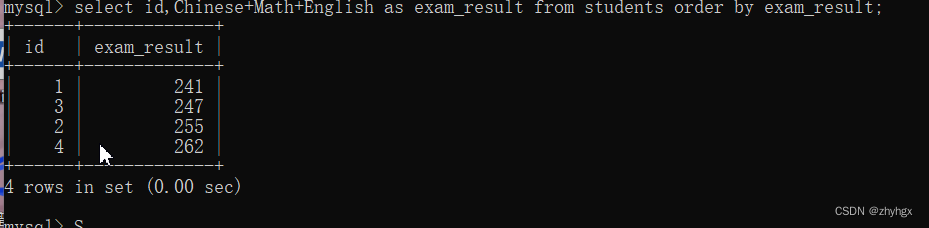
3.可以对多个字段进行排序,排序优先级随书写顺序
-- 查找学生表,依次按语文降序,数学升序,英语升序的方式进行查询
select id,name,Chinese,Math,English from students order by Chinese desc ,Math,English;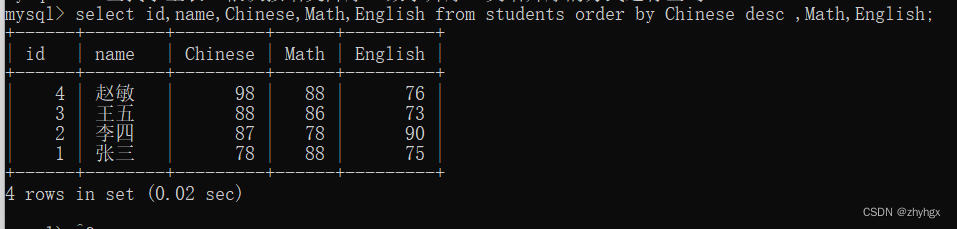
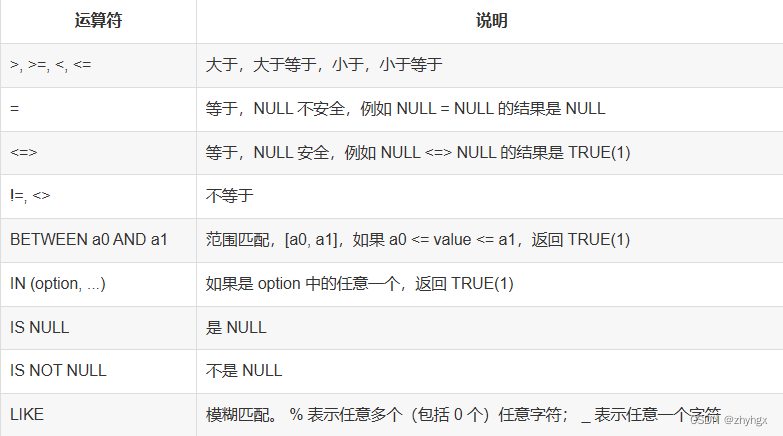
6.条件查询:WHERE
1.比较操作符
2.逻辑运算符

注意:
- WHERE条件可以使用表达式,但不能使用别名。
- AND的优先级高于OR,在同时使用时,需要使用小括号()包裹优先执行的部分。
示例:
1.基本查询
-- 查询数学成绩大于80的同学
select name,Math from students where Math>80;
-- 查询语文成绩小于90的同学
select name,Chinese from students where Chinese<90;
-- 查询英语成绩大于80的同学
select name,English from students where English>80;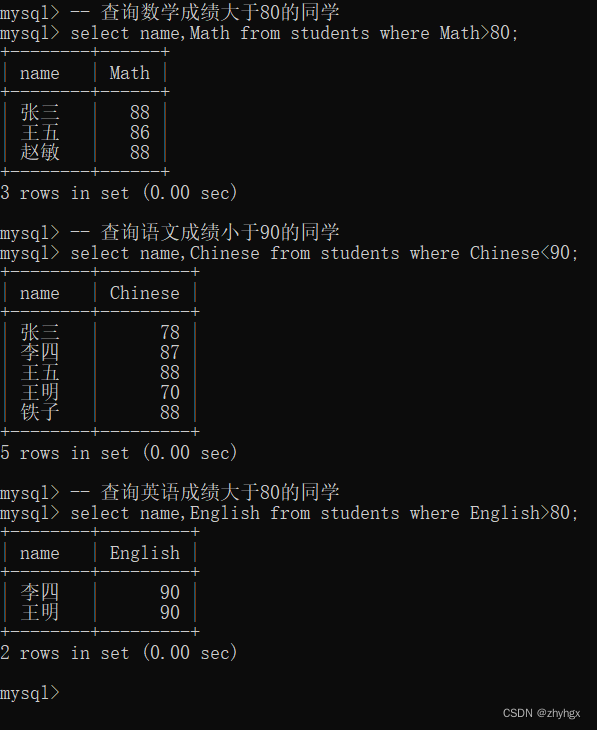
2.AND&&OR查询
-- 查询数学成绩大于80,并且英语成绩大于80的同学
select name,Math from students where Math>80 and English>80;
-- 查询语文成绩小于90,或者数学成绩小于80的同学
select name,Chinese from students where Chinese<90 or Math<80;
-- 观察AND 与 OR 的优先级
select * from students where Chinese > 80 or Math > 90 and English > 80;
select * from students where (Chinese > 80 or Math > 80) and English >80;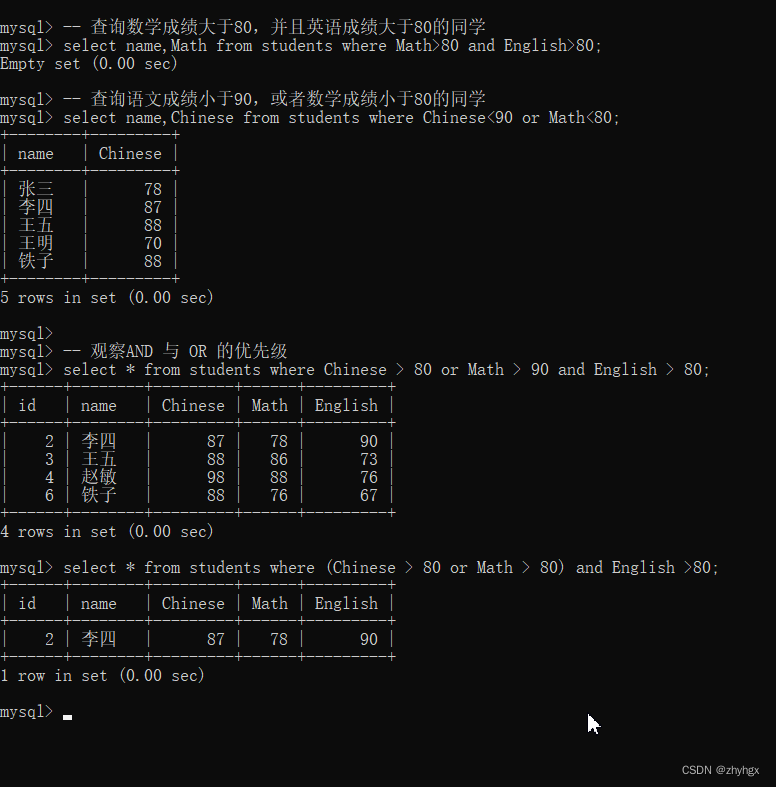
3.范围查询
- between...and..
-- 查询数学成绩在80到90的同学
select * from students where Math between 80 and 90;
-- 查询英语成绩在70到90的同学
select * from students where English between 70 and 90;
- IN
-- 查询数学成绩为88,78,50,76的同学
select * from students where Math in(88,78,50,76);
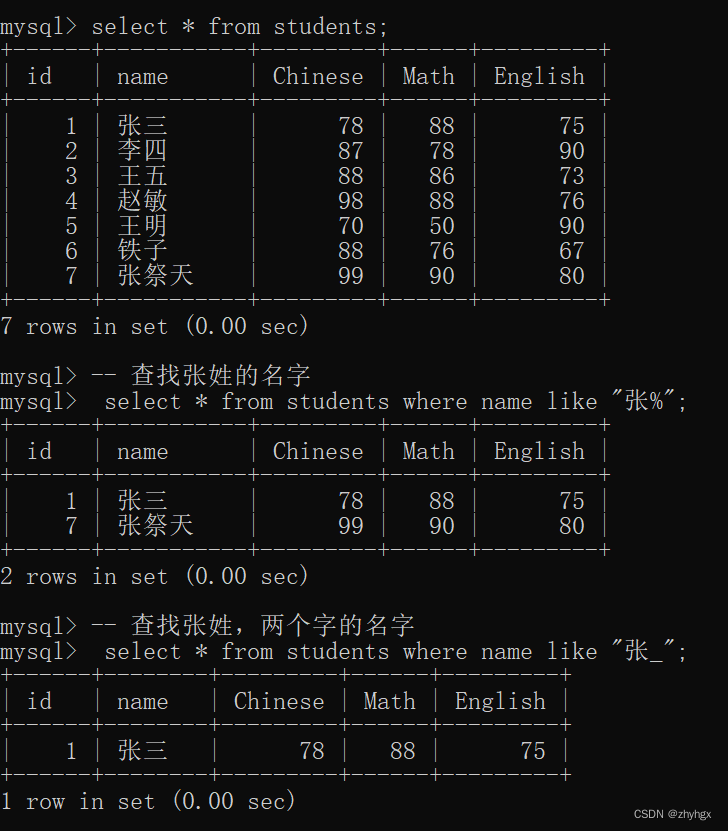
- LIKE (模糊匹配)
-- 查找张姓的名字
select * from students where name like "张%";
-- 查找张姓,两个字的名字
select * from students where name like "张_";
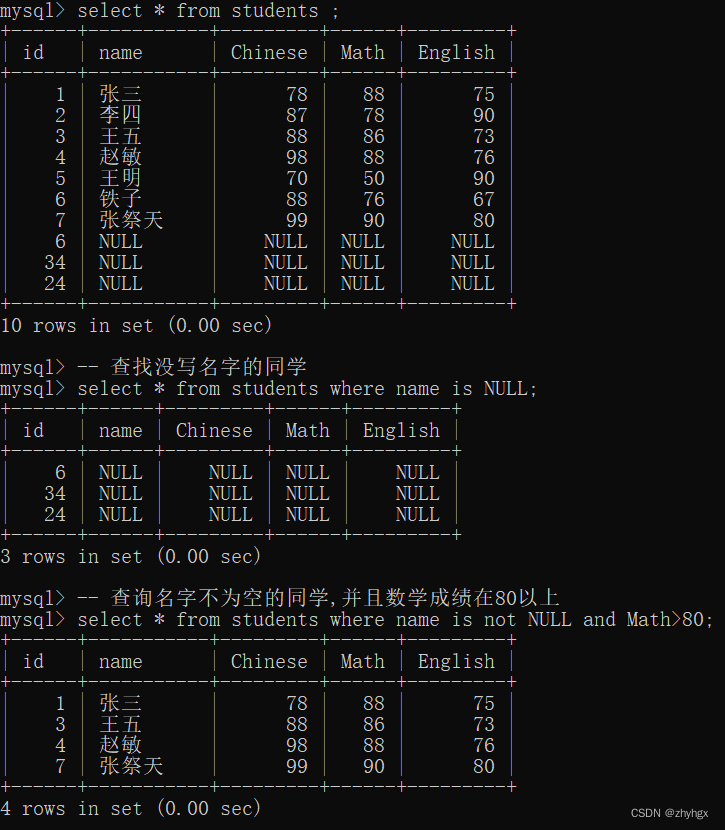
- NULL的查询
-- 查找没写名字的同学
select * from students where name is NULL;
-- 查询名字不为空的同学,并且数学成绩在80以上
select * from students where name is not NULL and Math>80;
7.分页查询
在指定列查询的时候,若查询的列数据太大,可能会出问题,所以,可以通过LIMIT关键字,来限制的记录。在使用LIMIT,经常搭配OFFSET关键字,表示从下表为几开始计算LIMIT。
-- 起始下标为 0
-- 从0开始,筛选n条结果
SELECT ... FROM TABLE_NAME [WHERE ... ] [ORDER BY ... ] LIMIT n;
-- 从 s 开始,筛选 n条结果
SELECT ... FROM TABLE_NAME [WHERE ... ] [ORDER BY ... ] LIMIT s,n;
--从 s 开始,筛选 n条结果,比第二种结果更明确,建议使用
SELECT ... FROM TABLE_NAME [WHERE ... ] [ORDER BY .. ] LIMIT n OFFSET s;示例:按照id分页,每页记录3条,分别显示1,2,3页
-- 第 1 页
SELECT id, name, Math, English, Chinese FROM students ORDER BY id LIMIT 3
OFFSET 0;
-- 第 2 页
SELECT id, name, Math, English, Chinese FROM students ORDER BY id LIMIT 3
OFFSET 3;
-- 第 3 页,如果结果不足 3 个,不会有影响
SELECT id, name, Math, English, Chinese FROM students ORDER BY id LIMIT 3
OFFSET 6;
8.聚合查询
聚合查询在SQL中是一种用于对一组行进行计算以返回单个汇总值的查询类型
8.1聚合函数
| 函数 | 说明 |
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总和,不是数字没有意义 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值,不是数字没有意义 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值,不是数字没有意义 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值,不是数字没有意义 |
示例:
count
-- 统计表内共有多少行数据,包括null
select count(*) from 表名;
-- 统计表内某行共有多少数据,不包括null
select count(列名) from 表名;
-- 统计表内某行共有多少数据进行去重,不包括null
select count(distinct 列名) from 表名;sum
-- 统计某列数据总和
select sum(列名) from 表名;
sum函数在遇到null时会跳过,不参与运算。
AVG
-- 统计平均分x
select avg(列名) from 表名;MAX
-- 返回列中最大数
select max(列名) from 表名;MIN
-- 返回列中最小数
select min(列名) from 表名;分组查询(GROUP BY)
作用:
- 数据汇总:允许用户根据一个或多个列的值将数据行分组到逻辑组中,然后对每个组应用聚合函数(如SUM, AVG, COUNT, MAX, MIN等)来计算每组的汇总信息。例如,计算每个部门的员工数量、销售额总额等。
- 统计分析:便于进行多维度的数据统计分析。通过不同的分组条件,可以快速洞察数据中的模式、趋势或异常情况,为决策提供支持。
- 过滤分组:结合HAVING子句,可以在分组后进一步筛选结果,只保留满足特定条件的组。这与WHERE子句不同,WHERE是在分组前过滤行,而HAVING是在分组后过滤组。
- 报表生成:在商业智能和报表系统中,分组查询是生成各类报表的基础,比如销售报表、库存报表等,能够清晰展示各部分或类别的汇总数据。
- 数据探索:帮助数据分析师或研究人员发现数据内部的关联性和差异性,特别是在大数据分析中,分组查询是探索性数据分析的重要工具。
- 简化复杂查询:对于需要对大量数据进行分类处理的情况,分组查询提供了一种高效且易于理解的方式,避免了复杂的多层查询或子查询。
示例:

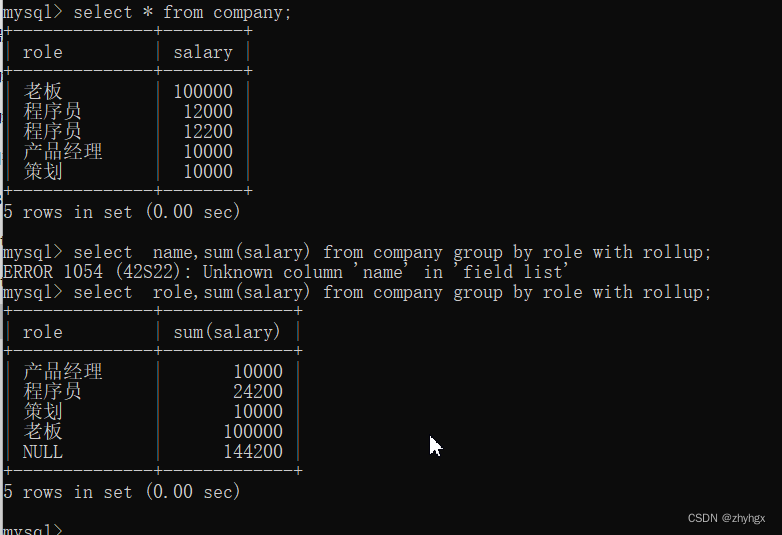
WIHT ROLLUP
使用 WITH ROLLUP,此函数是对聚合函数进行求和,注意 with rollup是对 group by 后的第一个字段,进行分组求和.
示例:
9.联合查询
关联查询是数据库操作中的一个重要概念,它允许用户从两个或更多个相关联的表中检索数据。关联查询的核心目的是通过匹配这些表中的共同字段(通常是外键和主键)来联合数据,从而获取更全面的信息。
在了解关联查询前,需要先了解一下笛卡尔积。
笛卡尔积
笛卡尔积是指在数学中,两个集合X和Y的笛卡尓积(Cartesian product),又称直积,表示为X × Y,第一个对象是X的成员而第二个对象是Y的所有可能有序对的其中一个成员。
笛卡尔积又叫笛卡尔乘积,是一个叫笛卡尔的人提出来的。 简单的说就是两个集合相乘的结果。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
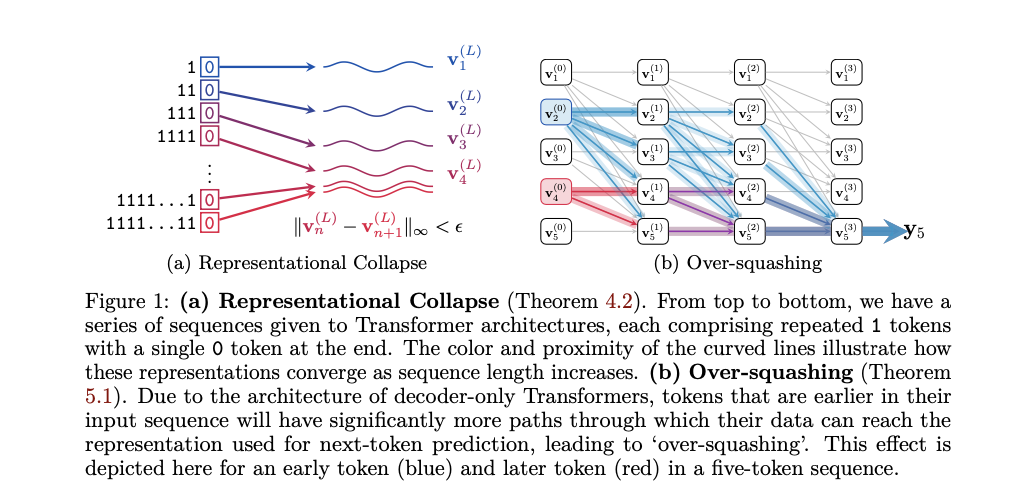
我们在进行关联查询的时候,若没有给指定的关联条件,那么MySQL就会进行一次笛卡尔积运算,造成冗余,如下图:

解决方法
表名.列名=表名.列名
-- 联表查询
select * from 表名,表名 where 表名.列名=表名.列名;内连接(INNER JOIN)
内连接只返回两个表中相匹配的行,如果一个表的某一行在另一个表中匹配不到,那么这一行将不会在结果集中。
语法:
select 字段 from 表1 别名1 [inner] join 表2 别名2 on 连接条件 and 其他条件; select 字段 from 表1 别名1,表2 别名2 where 连接条件 and 其他条件;
示例:
-- 班级表
create table classes(id int primary key auto_increment,name varchar(20),`desc` varchar(20));
-- 学生表
create table student(id int primary key auto_increment,sn varchar(20),name varchar(20),qq_email varchar(20),class_id int);
-- 课表
create table courses(id int primary key auto_increment,name varchar(20));
-- 成绩表
create table score(score decimal(3,1),student_id int,course_id int);
insert into classes (name,`desc`) values
("数字媒体技术2023级1班","学习了计算机原理、c#和c语言、数据结构"),
("软件技术2023级2班","学习了计算机原理、java、数据结构"),
("自动化2023级1班","学习了机械自动化");
insert into student (sn,name,qq_email,class_id) values
('08824','张三',"1517654.qq.com",1),
('09582','李四','14561651.qq.com',1),
('05561','黑旋风李逵','4456465.qq.com',2),
('01234','刑天','14785456.qq.com',1),
('01313','金刚','123156.qq.com',2),
('07894','猪八戒','1546541.qq.com',2),
('03232','孙悟空','134156.qq.com',1);
insert into courses (name) values
("java"),('机械自动化'),('计算机原理'),("c语言"),("数据结构"),("大学英语"),("高等数学");
insert into score (score,student_id,course_id) values
-- 张三
(80.5,1,2),(89.7,1,3),(99,1,5),(88.5,1,7),
-- 李四
(98,2,1),(80,2,3),
-- 黑旋风
(33, 3, 1),(68, 3, 3),(99, 3, 5),
-- 刑天
(67, 4, 1),(23, 4, 3),(56, 4, 5),(72, 4, 6),
-- 金刚
(81,5,1),(67,5,5),
-- 猪八戒
(56, 6, 2),(43, 6, 4),(79, 6, 6),
-- 孙悟空
(80, 7, 2),(92, 7, 6);
-- 查询张三的成绩
select name,score from student inner join score on id=score.student_id and name="张三";
select name,score from student,score where id=score.student_id and name="张三";
-- 查询所有同学的总成绩,及个人信息
select sn,name,qq_email,sum(score) from student join score on id=score.student_id group by student_id;
+-------+-----------------+-----------------+------------+
| sn | name | qq_email | sum(score) |
+-------+-----------------+-----------------+------------+
| 08824 | 张三 | 1517654.qq.com | 357.7 |
| 09582 | 李四 | 14561651.qq.com | 178.0 |
| 05561 | 黑旋风李逵 | 4456465.qq.com | 200.0 |
| 01234 | 刑天 | 14785456.qq.com | 218.0 |
| 01313 | 金刚 | 123156.qq.com | 148.0 |
| 07894 | 猪八戒 | 1546541.qq.com | 178.0 |
| 03232 | 孙悟空 | 134156.qq.com | 172.0 |
+-------+-----------------+-----------------+------------+外连接
外连接分为左外连接和右外连接,如果联合查询,左侧的表完全显示就是左外连接;右侧的表全显示就是右外连接。由于MySQL不支持全外连接,所以只能进行单侧的左右外连接。
语法:
-- 左外连接,表1完全显示
select 字段名 from 表1 left join 表名2 on 连接条件;
-- 右外连接,表2完全显示
select 字段 from 表名1 right join 表名2 on 连接条件;
示例:
查询所有同学的成绩,及同学的个人信息,如果该同学没有成绩,也需要显示
-- 创建一个学生表
create table students (id int auto_increment,name varchar(20));
-- 创建一个成绩表,记录学生成绩
create table score(student_id int,score decimal);
-- 在学生表中添加数据
insert into students (name) values("张三"),("李四"),("王五"),("孙悟空");
-- 在成绩表中添加数据
insert into score values(1,90),(2,76),(5,35),(4,88);
-- 左外连接
select name,score from students left join score on students.id=score.student_id;显示所有成绩
-- 右外连接
select name,score from students right join score on students.id=score.student_id; 自连接
自连接是指在同一张表连接自身进行查询。在SQL中的条件查询,是针对两个列进行比较的,而不能比较两个行,若要对两个行进行比较,就需要用到自连接。
注意:如果直接拿表名进行自连接,就会报错,需要给这个两个表起别名才能进行连接。

示例:显示数学创建比java成绩要好的同学
-- 创建一个课程表
create table course(id int,name varchar(20));
-- 创建一个成绩表
create table score(score decimal,student_id int,course_id int);
-- 在课程表中插入数据
insert into course values(1,"Java"),(2,"中国传统文化"),(3,"语文"),(4,"英文"),(5,"高数");
-- 在成绩表中插入数据
insert into score values(87,1,1),(99,1,3),(98,1,5),
(88,2,2),(78,2,5),(89,3,1),
(78,3,2),(97,3,5),(40,4,1),
(89,4,5),(88,5,1),(90,5,5);
-- 在课程表中查看java和高数的序号
select * from course where name="Java" or name="高数";
-- 将两张表进行连接
select * from score as s1,score as s2;
-- 筛选出java和高数的成绩
select * from score as s1,score as s2 where s1.student_id=s2.student_id and s1.course_id=1 and s2.course_id=5;
-- 筛选出高数成绩比java成绩高的学生
select * from score as s1,score as s2 where s1.student_id=s2.student_id and s1.course_id=1 and s2.course_id=5 and s2.score>s1.score;10.合并查询
在实际应用开发中,为了合并多个select的执行结果,可以使用union,union all,使用union和union all时,前后查询的结果集中,字段需要一致。
UNION
UNION操作符用于合并两个或多个SELECT语句的结果集,同时自动去除结果集中的重复行。
注意:
- 结果集中所有SELECT语句选择的列数必须相同。
- 相应的列也必须具有相似的数据类型。
- UNION默认会对结果进行排序,这可能会影响性能。
-- 合并查询
select 字段名 from 表名 union select 字段名 from 表名;
select * from course where id<3
union
select * from course where name='英文';
-- 或者使用or来实现
select * from course where id<3 or name='英文';UNION ALL
与UNION类似,但UNION ALL不会去除重复行,它直接将所有查询结果合并在一起,包括重复的行.
优点:不会进行去重,提高了查询效率。
-- 可以看到结果集中出现重复数据
select * from course where id<3
union all
select * from course where name='英文';11.子表查询(了解)
子表查询是指嵌入在其他SQL语句中的select语句中,也叫嵌套查询
单行子查询:返回一行记录的子查询
示例:查询与张三同班的同学。
select * from student where class_id=(select class_id from student where name="张三");多行子查询:返回多行记录的子查询
示例:
-- 查询'语文'或'英语'的成绩
-- 使用 IN
select * from score where course_id in (select id from course where
name='语文' or name='英文');
-- 使用 NOT IN
select * from score where course_id not in (select id from course where
name!='语文' and name!='英文');四.修改(UPDATE)
1.基本操作
UPDATE命令用于更新表中的现有记录。可以更新单行或多行,取决WHERE子句的条件。
UPDATE table_name SET column = expr [, column = expr . . . ]
[WHERE ...] [ORDER BY . . .] [LIMIT . . . ];table_name 即要修改的表的名称.
colun = expr 指定了要修改的列名及其值.
WHERE 即指定要修改哪些行需要更新。如果省略,将更新表中的所有行。
-- 修改张三的英语成绩,将其改为90
update students set English=90 where name="张三";
-- 将李四的数学改为60
update students set Math=60 where name="李四";
-- 将为空值的学生三科成绩都设为60
update students set Chinese = 60 ,Math=60,English = 60 where name is null;
-- 将总成绩倒数前三的3位同学的数学成绩加上20分
update students set Math=Math+20 order by Chinese + English + Math limit 3;
-- 将所有同学的语文成绩更新为80分
update students set Chinese = 80;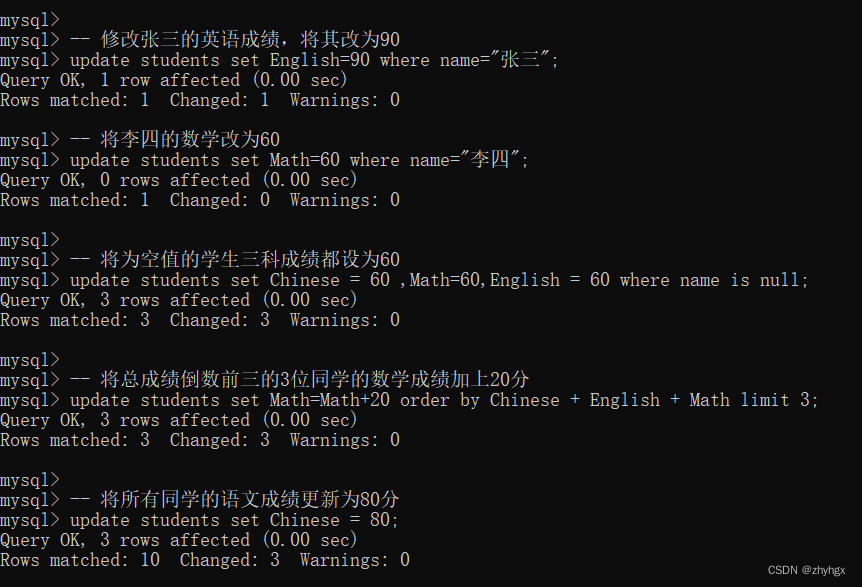
五.删除(DELETE)
在MySQL中,若想要删除数据库,可以用DROP 语句,在删除数据库的时候,其内的表也会一起被删除,若只想删除表或者表内的特定行,可以用DELETE语句。
-- 删除数据库
DROP database 库名;
-- 删表
DELETE FROM table_name WHERE conditionWHERE cindition,condition是可选的,如果没有指定,将删除表中的所以行。
示例:
-- 删除张三的数据
delete from students where name = "张三";
-- 准备测试表
create table testta(
id int,
name varchar(20)
);
-- 删除整张表
delete from testta;
数据库约束条件
1.非空条件(NOT NULL)
定义:非空约束确保某列的值不能为NULL,必须包含实际的数据。
示例:
create table student(id int not null,name varchar(20));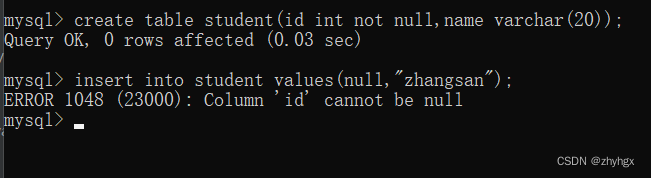
2.唯一约束(UNIQUE)
定义:唯一约束要求被约束的列(或列组合)中的数据具有唯一性,允许NULL值的存在,但最多只能有一个NULL。
示例:
create table student(id int unique,name varchar(20));
insert into student values(1,"zhangsan");
insert into student values(1,"zhangsan");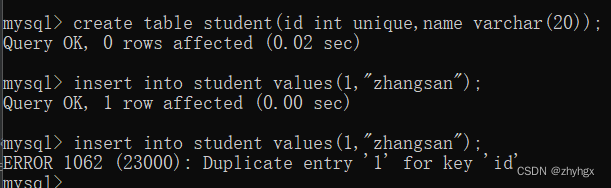
3.主键约束(PRIMARY KEY)
定义:主键约束用于唯一标识表中的每一行记录。一个表只能有一个主键,主键的值必须是唯一的,并且不能为NULL。
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id
INT NOT NULL PRIMARY KEY,
sn
INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
)自增长(AUTO_INCREMENT//AUTOINCREMENT/IDENTITY)
定义:主要用于整数类型的列,每当插入新记录时,该列的值会自动递增,常与主键结合使用,确保其唯一性。
对于整数类型的主键,常配搭自增长auto_increment/AUTOINCREMENT/IDENTITY来使用。插入数据对应字段不给值时,使用最大值+1。
由于主键是NOT NULL 和 UNIQUE 的结合,所以可以不用NOT NULL。
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id
INT PRIMARY KEY auto_increment,
sn
INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);4.外键约束(FOREIGN KEY)
定义:外键约束用于建立两个表之间的关系,确保一个表(从表)中的某个列(或列组合)的值必须参照另一表(主表)中主键列的值。可以设置级联操作来处理相关记录的更新或删除。
语法:foreign key (字段名) references 主表(列)
示例:
创建班级表classes,id为主键
-- 创建班级表,有使用MySQL关键字作为字段时,需要使用``来标识
DROP TABLE IF EXISTS classes;
CREATE TABLE classes (
id INT PRIMARY KEY auto_increment,
name VARCHAR(20),
`desc` VARCHAR(100)
);创建学生表student,一个学生对应一个班级,一个班级对应多个学生。使用id为主键, classes_id为外键,关联班级表id
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT PRIMARY KEY auto_increment,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20),
classes_id int,
FOREIGN KEY (classes_id) REFERENCES classes(id)
);5.默认值约束(DEFAULT)
定义:如果在插入新记录时没有为某一列指定值,那么该列将自动被赋予预先定义的默认值。
在建表的时候,也可以修改默认值
-- 重新设置学生表结构
DROP TABLE IF EXISTS student;
CREATE TABLE student (
id INT NOT NULL,
sn INT UNIQUE,
name VARCHAR(20) DEFAULT 'unkown',
qq_mail VARCHAR(20)
);6.检查约束(CHECK)
定义:检查约束允许对列设置一个布尔表达式的条件,只有当插入或更新的数据满足这个条件时,操作才能成功。常用于限制数据的取值范围或格式。
drop table if exists test_user;
create table test_user (
id
int,
name varchar(20),
sex varchar(1),
check (sex ='男' or sex='女')
)总结
SQL查询中各个关键字的执行先后顺序: from > on> join > where > group by > with > having > select > distinct > order by > limit
约束:
| 约束类型 | 说明 | 示例 |
| NULL约束 | 使用NOT NULL指定列不能为空 | id inr not null |
| UNIQUE(唯一约束) | 指定列唯一,不重复 | id int unique |
| DEFAULT(默认值约束) | 指定列为空时的默认值 | name varchar(20) default "无名" |
| PRIMARY KEY(主键约束) | NOT NULL 和 UNIQUE的结合 | id int primary key |
| FOREIGN KEY(外键) | 关联其他表的主键或唯一键 | foreign key (字段名) references 主表(列) |
| CHECK(检查约束) | 保证列中的值符合指定的条件 | check(sex="男" or sex=“女") |
表的关系:
- 一对一:例如:一名学生只能有一个学号
- 一对多:例如:一个学生可以选择多门课程
- 多对多:需要查看中间表来映射两张表的关系
反思
通过对SQL中对表的增删改查操作的学习,我了解了如何在数据库中新增表以及在表内插入数据,在删除数据时需谨慎,防止误删数据,造成损失。在查找数据时,需要搭配合理的条件,少用通配符*,合理使用索引。在更新数据时,需要谨慎处理,要搭配合理的条件。
以上就是本篇所有内容,若有不足之处,欢迎指正~😊

![[C][数据结构][排序][下][快速排序][归并排序]详细讲解](https://img-blog.csdnimg.cn/direct/c796ea2467cc4ed2b904f1fa55adb17f.png)