>>>raise LookupError('value does not appear in the dictionary')
Traceback (most recent call last):
File "<stdin>", line 1,in<module>
LookupError: value does not appear in the dictionary
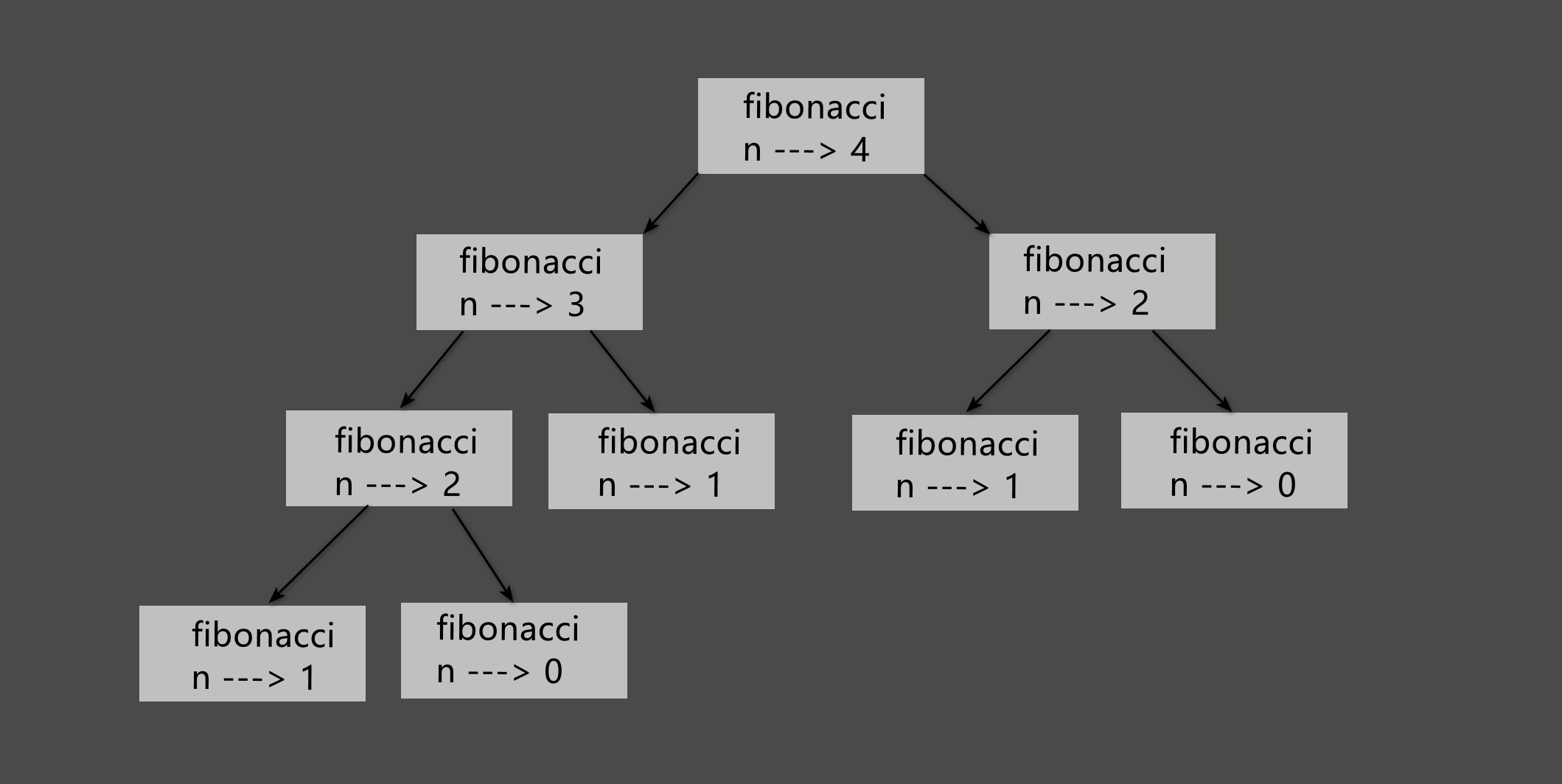
# 原始版本deffibonacci(n):if n ==0:return0elif n ==1:return1else:return fibonacci(n -1)+ fibonacci(n -2)
# 对应了n为0返回0, n为1返回1
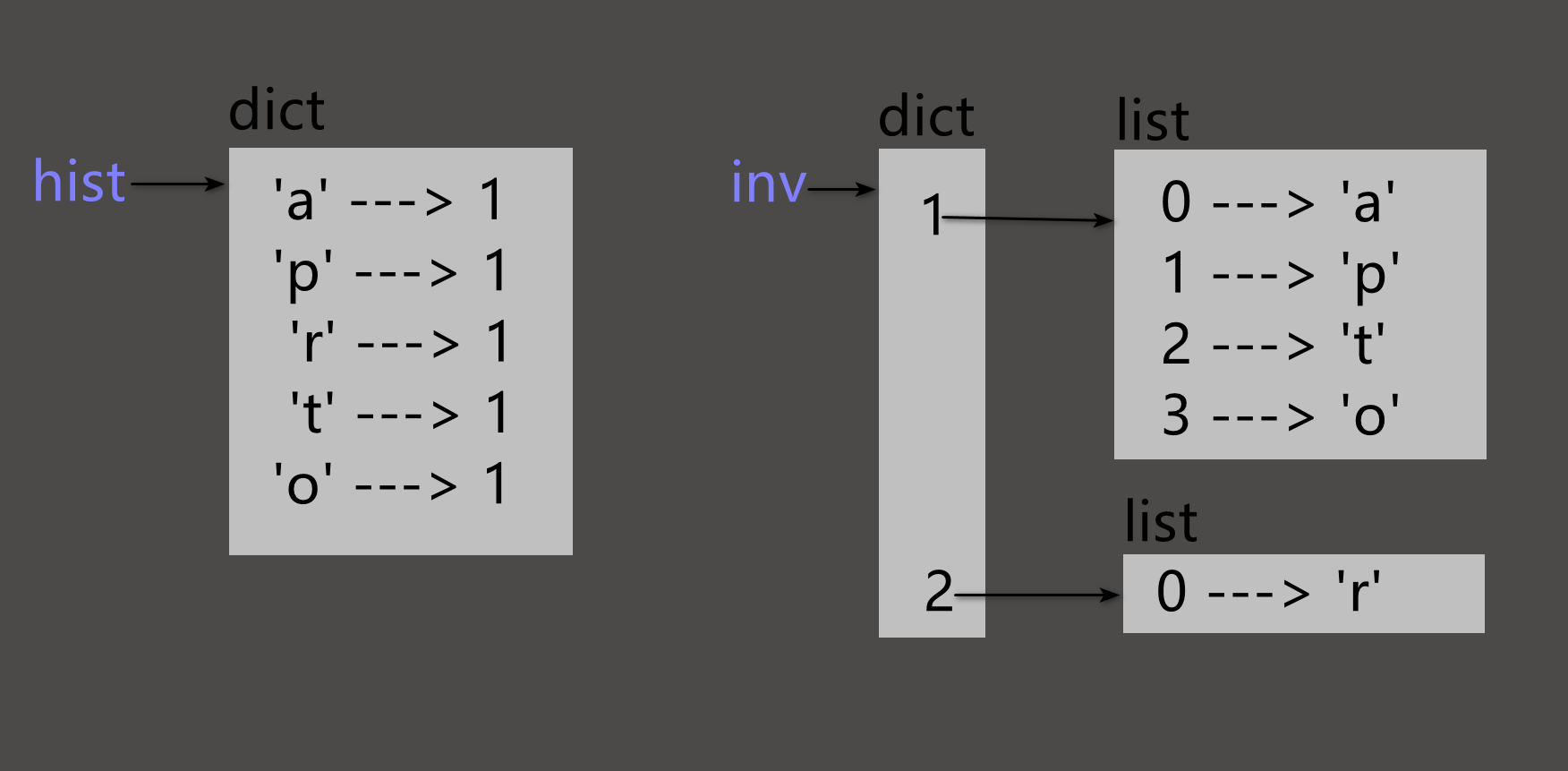
known ={0:0,1:1}deffibonacci(n):# n是数字, (0-1-2-3-n)if n in known:# n存在则, 返回值斐波那契数列的值.return known[n]# n不存在则进行计算, 将计算的结果保存到字典中.
res = fibonacci(n -1)+ fibonacci(n -2)
known[n]= res
return res
defackermann(m, n):"""
计算阿克曼函数 A(m, n)
See http://en.wikipedia.org/wiki/Ackermann_function
n, m: 非负整数
"""print(m, n)if m ==0:return n +1if n ==0:return ackermann(m -1,1)return ackermann(m -1, ackermann(m, n -1))print(ackermann(3,4))
notes ={}defackermann(m, n):if m ==0:return n +1if n ==0:return ackermann(m -1,1)# 有两个参数, 合并在一个.(目前值学了字符串, 后续使用元组更加合理)
key =str(m)+str(n)if key in notes:return notes[key]# 将原本的语句拆分了, 看的清楚点.
res1 = ackermann(m, n -1)
res2 = ackermann(m -1, res1)
notes[key]= res2
return res2
print(ackermann(3,4))# 125print(ackermann(3,6))# 509print(notes)
# (修改列表为字典, in操作符字典比 in列表快n倍.)defhas_duplicates(list1):# 新建一个字典
tem_dict =dict()# 遍历列表for i in list1:# i不在字典, 则添加. if i notin tem_dict:
tem_dict[i]=0else:returnTruereturnFalseprint(has_duplicates([1,1,2,3,4,5,5,6]))# Trueprint(has_duplicates([1,2,3,4,5,6]))# False
# 单词字典defmake_word_dict():
fin =open(r'C:\Users\13600\Desktop\words.txt')# 新建字典
word_dict =dict()for line in fin:
word = line.strip()# 将所有的列表元素作为字典的键.
word_dict.setdefault(word,None)return word_dict
# 轮转单词defrotate_words(tem_word, digit):# a - z 对应 97 - 123# 新建列表
word_list =[]for i in tem_word:
letter =chr((ord(i)-97+ digit)%26+97)
word_list.append(letter)
res_word =''.join(word_list)return res_word
# 查找轮转对defcheck_wheelset():
word_dict = make_word_dict()for word in word_dict:for i inrange(1,26):# 返回轮转后的单词
rotation = rotate_words(word, i)# 判断轮转后的单词是否存在if rotation in word_dict:print('单词: '+ word +' 轮转'+str(i)+'次后为 '+ rotation)
check_wheelset()
# 运行终端显示:
单词: aah 轮转4次后为 eel
单词: aba 轮转19次后为 tut
单词: abet 轮转7次后为 hila
单词: abjurer 轮转13次后为 nowhere
单词: abo 轮转4次后为 efs
单词: abo 轮转13次后为 nob
单词: aby 轮转3次后为 deb
单词: aby 轮转25次后为 zax
单词: ache 轮转6次后为 gink
单词: act 轮转24次后为 yar
6. 练习6
下面是<<车迷天下>>节目中的另一个谜题(http://www.cartalk.com/content/puzzlers).这个谜题是一个叫作DanO'Leary的伙计寄过来的.他曾经遇到一个单音节,5字母的常用单词,有如下所述的特殊属性.当你删除第一个字母时,剩下的字母组成原单词的一个同音词,即发音完全相同的词,将第一个字母放回去,并删除第二个字母,结果也是原单词的另一个同音词,问题是,这个单词是什么?接下来我给你一个示例,但它并不能完全符合条件.我们看这5个字母单词'wrack',W-R-A-C-K,也就是'weack with pain(带来伤害)'里的那个词.如果我删除掉第一个字母,会剩下一个4个字母的单词,'R-A-C-K'.也就是,'Holy cow, did you sess the rack on that buck! It must have a nine-pointer!'(天哪!你看到哪匹雄鹿的鹿角了吗!一定有9个犄角!)中的那个单词.它是一个完美的同音词.但如果你把'w'放回去,并删除掉'r'会得到单词'wack'也是一个真实的单词,但它的读音和其他两个不一样.但就Dam个我所知,至少有一个单词能够通过删除前两个字母得到两个同音词.问题是,这个单词是什么?你可以使用11-1中的字典来检测一个字符串是否出现在单词表中.要检查两个单词是不是同音词,你可以使用CMU发音词典.你可以从下面的地址下载它:http:www.speech.cs.cum.edu/cgi-bin/cmudicthttps://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/c06d下面脚本提供了一个叫作read_dictionary的函数来读入发音词典并返回一个Python字典,将每个单词映射到表示其只要发音的字符串上.https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/pronounce.py编写一个程序,列出所有可以解答这个谜题的单词.解答:https://raw.githubusercontent.com/AllenDowney/ThinkPython2/master/code/homophone.py
defmake_dict():
fin =open(r'C:\Users\13600\Desktop\words.txt')# 创建一个空字典
tem_words_dict =dict()# 遍历文件对象for line in fin:# 移除'\n'
word = line.strip()# 值是什么不所谓..
tem_words_dict[word]= word
# 将字典返回return tem_words_dict
defread_dictionary(filename='c06d'):# 新建空字典
d =dict()# 读取文件
fin =open(filename)# 遍历文件for line in fin:# 跳过评论, 文件中很有很多#开头的段落.if line[0]=='#':continue# 去除\n
t = line.split()# 将单词的第一个单词转为小写, 赋值给word, SCHLARB --> schlarb
word = t[0].lower()# 使用空格拼接, SH L AA1 R B
pron =' '.join(t[1:])# schlarb = SH L AA1 R B
d[word]= pron
return d
# 发音单词字典
phonetic = read_dictionary()# 单词字典
words_dict = make_dict()# 遍历单词for word in words_dict:# 第一个单词, 去除首字母
word1 = word[1:]# 第二个单词, 去除第二个字母
word2 = word[:1]+ word[2:]# 这两个单词在字典中.if word1 in words_dict and word2 in words_dict:# 三个单词都在phonetic中if word1 in phonetic and word2 in phonetic and word in phonetic:# 单词1, 单词2, 与单词的值一样.if phonetic[word1]== phonetic[word2]== phonetic[word]:print(word, word1, word2)