在当前主流的分布式架构中,各种各样的集群技术几乎成了任何想要提升系统稳定性和处理能力的团队的必备技能。虽然各种中间件和系统都有让人看似眼花缭乱的集群实现方案,但其背后仍然逃不过一些核心的技术概念,我会结合几个我比较熟悉的中间件,简单聊一下我对集群的理解:
集群的类型
按照搭建集群的目标来划分,大致可以划分为三类集群
高可用集群
高可用性集群的主要目的是使集群的整体服务尽可能可用,在集群中任意一个节点失效的情况下,该节点上的所有任务会自动转移到其他正常的节点上。此过程并不影响整个集群的运行,能够有效的避免单点故障。高可用集群要求节点间可以进行任务和状态的迁移。我们通常所说的双机热备,也就是某种意义上的高可用集群。
负载均衡集群
负载均衡集群的主要是通过一个或多个负载均衡器,基于一定的算法将客户端集中的访问请求负载压力尽可能平均地分摊在集群中的各个节点进行处理,实现访问请求在各节点之间动态分配,以提升集群整体的吞吐量和性能,避免单个节点的网络,硬件资源等成为性能瓶颈,实现服务的横向扩展。这个例子就很多了,比如通过nginx反向代理多个后端的web服务器实例,实现多实例间的负载均衡。
高性能集群
主要用于大型任务的并行计算,将一个复杂问题拆分为多个可以并行执行的任务在多个节点同时进行计算,主要用于大数据领域,比如hadoop的mapreduce,flink,spark等等。
常用中间件的集群实现
Kafka集群
kafka的集群基于副本机制来实现了高可用,然后通过多broker,多分区来实现消息生产和消费的负载均衡,整个集群的架构图如下:
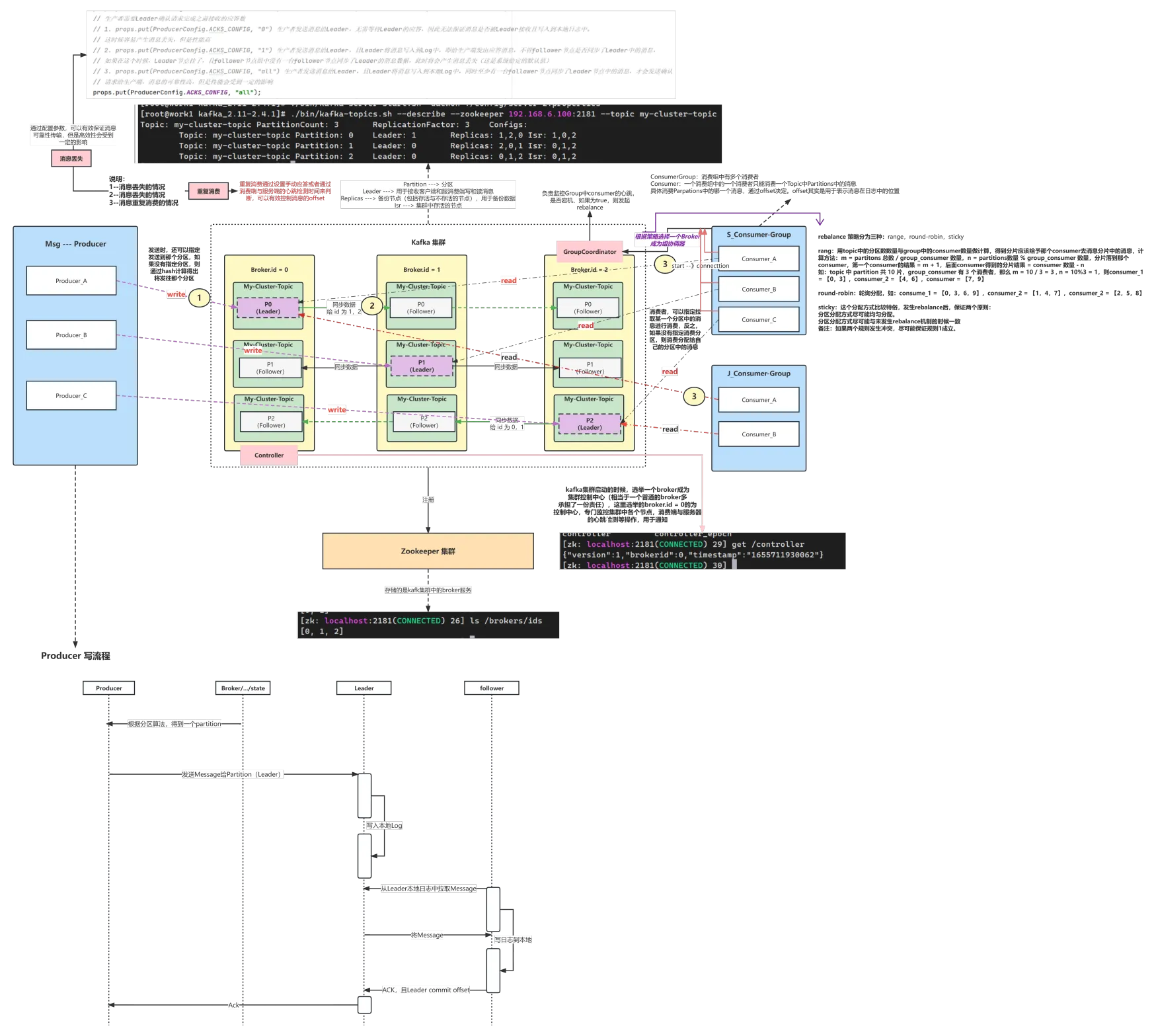
| 核心概念 | 作用 |
|---|---|
| Broker | 消息中间件处理节点,一个Kafka节点就是一个broker,一个或者多个Broker可以组成一个Kafka集群 |
| Topic | Kafka根据topic对消息进行归类,发布到Kafka集群的每条消息都需要指定一个topic |
| Partition | 分区,物理上的概念,一个topic可以分为多个partition,每个partition内部消息是有序的,一个分区可以简单的看作一个日志文件 |
| Producer | 消息生产者,向Broker发送消息的客户端 |
| Consumer | 消息消费者,从Broker读取消息的客户端 |
| ConsumerGroup | 消费者组,每个Consumer属于一个特定的Consumer Group,一条消息可以被多个不同的Consumer Group消费,但是一个Consumer Group中只能有一个Consumer能够消费该消息Partition |
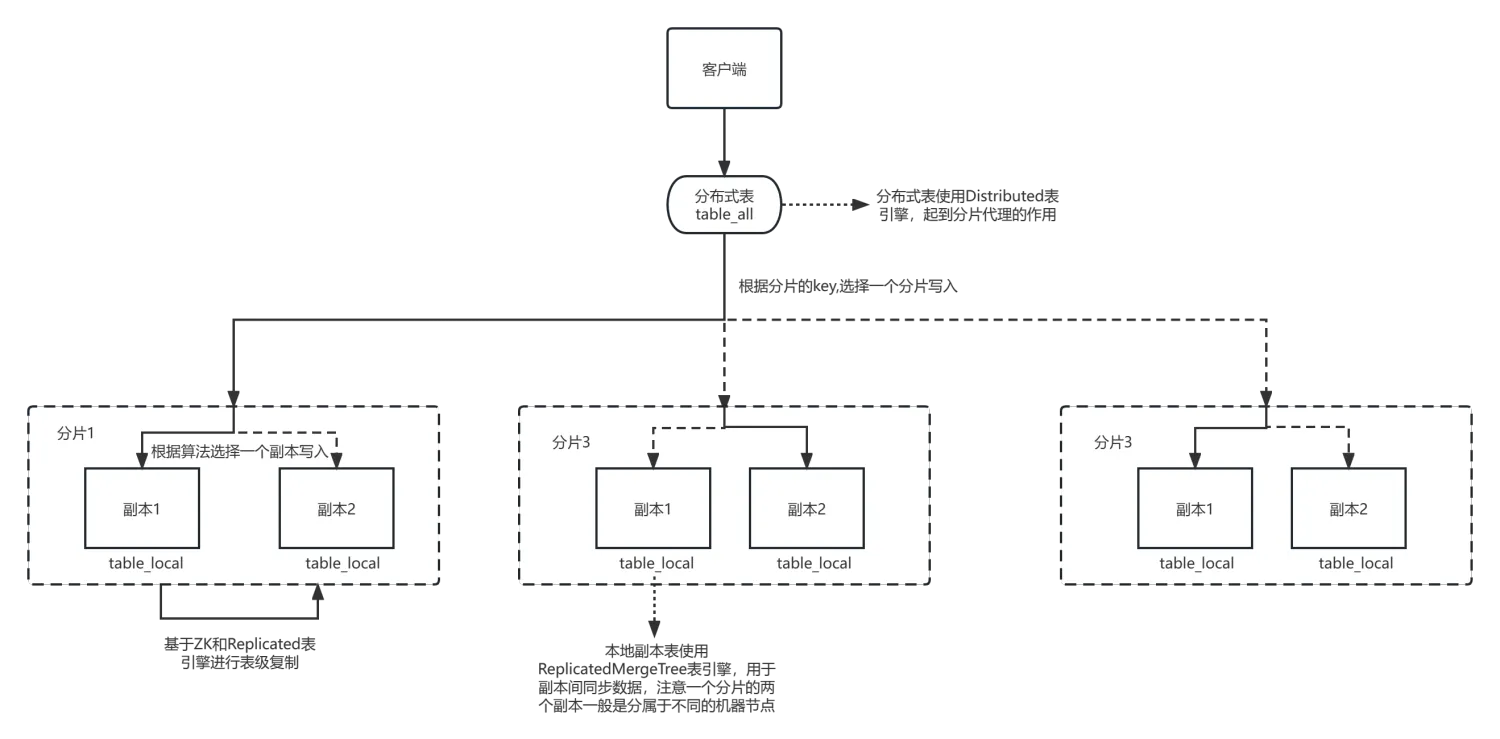
Clickhouse集群
clickhouse集群有两个重要的概念:分片(shard)和 副本(replica),分片与分片间存储了不同的数据,而副本与副本之间数据是一致的(最终一致),一个分片可以有多个副本。从这里就可以看出它是通过分片实现负载均衡,而对分片创建副本来实现分片的高可用。一个典型的clickhouse集群主要由六个节点组成,分别为3个分片以及每个分片一个副本,:

这六个节点构成集群的配置如下:
<remote_servers>
<!-- User-specified clusters -->
<replicated>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chi-clickhouse-replicated-0-0</host>
<port>9000</port>
<secure>0</secure>
</replica>
<replica>
<host>chi-clickhouse-replicated-0-1</host>
<port>9000</port>
<secure>0</secure>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chi-clickhouse-replicated-1-0</host>
<port>9000</port>
<secure>0</secure>
</replica>
<replica>
<host>chi-clickhouse-replicated-1-1</host>
<port>9000</port>
<secure>0</secure>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>chi-clickhouse-replicated-2-0</host>
<port>9000</port>
<secure>0</secure>
</replica>
<replica>
<host>chi-clickhouse-replicated-2-1</host>
<port>9000</port>
<secure>0</secure>
</replica>
</shard>
</replicated>
客户端在使用clickhouse集群时,一般会用到两种特定类型的表引擎,用于在集群间分发和同步数据,一个是ReplicatedMergeTree,这类表引擎在写入时如果某个分区配置了副本,就会基于zk的异步复制机制去同步所有的副本节点。另一类是Distributed,这类表引擎创建的表并不会实际存储数据,只是起到一个代理的作用,将SQL操作分发到各个分区去执行。使用示例如下:
-- 创建数据的的物理表,使用ReplicatedMergeTree进行副本复制,注意需要添加**on cluster**关键字,这样才会在所有的集群节点上创建表,否则只会在当前执行SQL的节点上创建。
create table IF NOT EXISTS testdb.table_local on cluster replicated (
`id` String,
`value` String,
`ts` DateTime64
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/table', '{replica}')
PARTITION BY toYYYYMM(time)
ORDER BY (time,pk,deviceId,identifier,tenantId)
TTL toDateTime(time) + INTERVAL 7 DAY
SETTINGS index_granularity = 8192;
-- 创建物理表的代理表,实现请求分发和负载均衡
create table IF NOT EXISTS testdb.data_table_all on cluster replicated as table_local ENGINE = Distributed(replicated, testdb, table_local, rand());
整个客户端将数据写入clickhouse集群的数据流图如下:
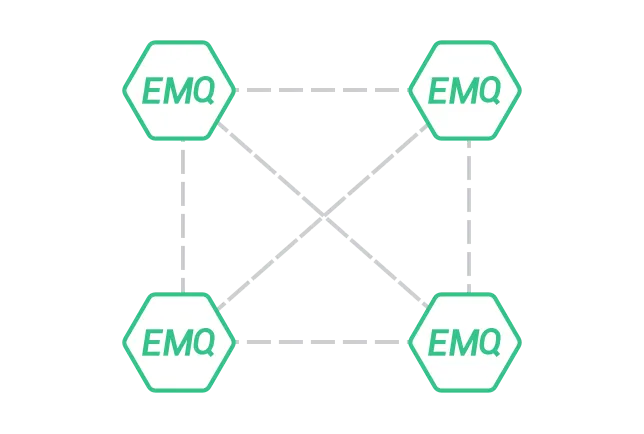
EMQX集群
emqx集群中的每个emqx实例称之为一个节点(node),集群中的所有节点之间都会相互建立TCP连接进行通讯,形成一个网状结构:
 EMQX 分布式的基本功能是将消息转发和投递给各节点上的订阅者,如下图所示:
EMQX 分布式的基本功能是将消息转发和投递给各节点上的订阅者,如下图所示:
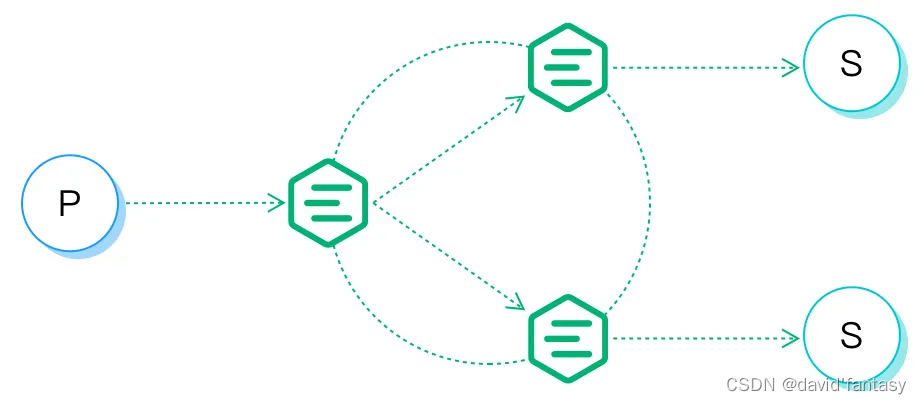
为实现此过程,EMQX 维护了几个与之相关的数据结构:订阅表,路由表,主题树。
订阅表:
主要保存了从主题(topic)到订阅者(Subscriber)的映射关系,订阅表只保存在于订阅者所在的 EMQX 节点上,并不会在整个集群间共享,数据结构如下:
node1:
topic1 -> client1, client2
topic2 -> client3
node2:
topic1 -> client4
路由表:
主要保存了从主题(topic)到节点(node)的映射关系,这里的节点是指连接了该主题订阅者(客户端)的节点,例如:
topic1 -> node1, node2
topic2 -> node3
topic3 -> node2, node4
集群中的所有节点都会复制一份相同的路由表。
主题树:
每个emqx节点除了都会维护一份路由表以外,还会维护一份主题树,保存的信息为带通配符的主题与实际的topic之间的映射关系,例如如果存在下述主题订阅关系:
| 客户端 | 节点 | 订阅主题 |
|---|---|---|
| client1 | node1 | t/+/x, t/+/y |
| client2 | node2 | t/# |
| client3 | node1 | t/+/x, t/a |
在所有订阅完成时,EMQX 中会维护如下主题树 (Topic Trie) 和路由表 (Route Table):

由此可见,EMQX集群只实现了分片,而没有通常意义上的副本,而是通过将需要维护状态的数据广播到所有节点来保持系统的高可用,这样在某个节点离线后,连接到该节点的客户端只需要重新连接一次集群,即可恢复对消息的处理。
消息派发过程:
根据上面的例子,整个消息派发过程如下:

订阅者负载均衡
emqx提供共享订阅机制来在客户端订阅者中实现负载均衡,多个订阅者可以订阅同一个topic,emqx根据一定的算法将消息分发给不同的订阅者
[subscriber1] got msg1
msg1, msg2, msg3 /
[publisher] ----------------> "$share/g/topic" -- [subscriber2] got msg2
\
[subscriber3] got msg3
上图中,共享 3 个 subscriber 用共享订阅的方式订阅了同一个主题 $share/g/topic,其中topic 是它们订阅的真实主题名,而 $share/g/ 是共享订阅前缀。EMQX 支持两种格式的共享订阅前缀:
| 示例 | 前缀 | 真实主题名 |
|---|---|---|
| $queue/t/1 | $queue/ | t/1 |
| $share/abc/t/1 | $share/abc | t/1 |
在同一个订阅群组内,可以选择以下的负责均衡策略:
| 均衡策略 | 描述 |
|---|---|
| hash_clientid | 按照发布者 ClientID 的哈希值 |
| hash_topic | 按照源消息主题的哈希值 |
| local | 优先选择和发布者在同一各节点的共享订阅者来派发消息,否则进行随机派发 |
| random | 在所有订阅者中随机选择 |
| round_robin | 按照一个固定的顺序选择下一个订阅者 |
| sticky | 首次分发时随机选择一个订阅者,后续消息一直发往这一个订阅者直到该订阅者离线或该发布者重连 |
生产者负载均衡
emqx没有提供broker的代理,所以客户端连接emqx集群时依赖于外部机制来确保负载均衡,比如在OS内部是使用K8S服务名的方式,将每个客户端的连接请求均匀的分发到不同的emqx broker。客户端断线重连后可能会连接到不同的broker节点。
集群技术总结
不同的中间件虽然在集群实现细节上有不少差异,但是一些基本概念是共同的:
- 都存在分片(分区) 和副本的概念,集群中不同的分片保存了不同的数据和状态,但同一个分片一般具备多个副本,副本与副本间的数据和状态是一致的(最终一致),副本一般分为master(leader) 和 slave两种角色,仅master接收读写请求(clickhouse例外,多个副本可以同时接收写请求,是多写结构),slave在master挂掉以后通过选举算法确定出新的master。分片的目标是负载均衡,副本的目标是高可用;
- 集群的状态和数据分为两种,一种算是元数据,元数据需要在集群所有实例间进行共享;另一种是实例状态数据,这部分数据一般只保留在实例节点本地;
- 集群间状态和数据的共享分为两种形式,一是利用外部独立的中间件作为分布式协调器(比如zookeeper,etcd等等)保存需要共享的元数据,确保元数据在不同节点上的强一致性;另一种是通过某种协议主动在集群节点间同步需要共享的数据,比如redis的gossip协议,这种一般只能做到数据的最终一致性。