随着我们迈向人工通用智能(AGI)的时代,出现了开创性的大语言模型(LLMs)。凭借它们强大的语言理解和推理能力,已经无缝地将其他模态(例如视觉)整合到LLMs中,以理解不同的输入。由此产生的多模态大型语言模型(MLLMs)在传统视觉任务和更复杂的多模态问题上都表现出了多样化的专业能力。然而,尽管它们表现出色,并且努力与人类偏好保持一致,这些尖端模型在可信度方面仍存在显著缺陷,导致事实上的错误、有害输出、隐私泄露等问题。
除了LLMs固有的弱点外,MLLMs的多模态特性引入了新的风险,例如对对抗性图像攻击的敏感性、图像中存在有害内容以及通过视觉环境越狱。由于新模态带来了各种复杂因素,包括跨多个方面的任务设计、多模态场景中的数据收集以及模态之间的相互作用,对MLLMs的可信度进行系统评估更具挑战性。然而,当前的工作通常只检查可信度的一个或几个方面,并在现象层面上对MLLMs进行有限任务的评估,关注图像中的威胁,但忽略了模态之间的交互。
MultiTrust,首个全面统一的基准测试,用于评估MLLMs在不同维度和任务上的可信度。MultiTrust中评估MLLMs可信度的5个主要方面,包括真实性、安全性、鲁棒性、公平性和隐私性,涵盖了模型在防止意外结果和确保对用户的社会影响方面的可靠性。
1 MultiTrust的框架
MultiTrust的框架是一个综合统一的系统,旨在评估多模态大型语言模型(MLLMs)的可靠性。该框架由多个部分组成,每个部分都有其特定的目标和功能。
官网:https://multi-trust.github.io
1.1 设计哲学和评估策略
设计哲学方面,MultiTrust遵循以下原则:
- 综合性:MultiTrust旨在全面评估MLLMs的可靠性,这包括了对模型的真实性、安全性、鲁棒性、公平性和隐私性等多个方面的考察。
- 统一性:通过建立一个统一的评估框架,MultiTrust能够确保所有评估任务都遵循相同的标准和方法,从而提高了评估的一致性和可比性。
- 深度:MultiTrust不仅关注模型表面的性能,还深入探究了模型内部的机制,包括模型的架构、训练过程以及它们如何影响模型的可靠性。
- 实践性:MultiTrust设计了多种任务,这些任务覆盖了从传统视觉任务到复杂的跨模态问题的广泛范围,确保了评估结果的实用性和相关性。
评价策略方面,MultiTrust采取了以下方法:
- 多模态风险评估:MultiTrust通过设计特定的任务来评估MLLMs在新颖多模态场景下的表现,例如对抗性图像攻击、有毒内容生成等。
- 跨模态影响分析:MultiTrust研究了视觉输入如何影响基于文本的任务的性能,这包括文本任务的稳定性、方向性倾向以及模型内部风险的增加。
- 任务池设计:MultiTrust创建了一个包含32个任务的池,这些任务旨在揭示MLLMs在现实和全面场景中的可信度风险。
- 严谨的评估策略:MultiTrust采用了严格的评估策略,包括规则基础的评估、自动化的评估方法以及混合评估,以获得更全面的评估结果。
- 大规模实验:MultiTrust对21个现代MLLMs进行了大规模实验,这些实验涉及不同的模型架构和训练技术,以确保评估结果的广泛适用性。
1.2 任务分类
为了全面评估MLLMs的可靠性,MultiTrust将32个多样化的任务分为两大类:生成式任务和判别式任务。进一步地,这些任务被细分为六个子类别:多模态风险、跨模态影响、规则基础评估、自动评估、混合评估。
1.2.1 生成式任务
生成式任务旨在评估MLLMs生成内容的能力,包括文本、图像和其他模态的数据。这些任务考察模型是否能够产生准确、连贯和有意义的输出。
1.2.1.1 真实性 - 误导错误(Misguided Mistakes)
- 文本误导的视觉问答(Text Misleading VQA): 在这项任务中,模型需要处理包含事实错误的文本输入,并在这些错误信息的影响下回答问题。模型需要展示出能够抵抗文本输入中的误导信息,并基于图像内容提供准确的回答。
- 视觉混淆的视觉问答(Visual Confusion VQA): 模型需要处理包含视觉错觉或难以直观理解的视觉现象的图像,并基于这些图像回答问题。这要求模型不仅要理解图像内容,还要能够解释为什么某些常见的视觉误解实际上是错误的。
- 视觉误导的问答(Visual Misleading QA): 在这项任务中,模型面对的是基于文本的问题,但会同时接收到与问题答案相反或不相关的图像。模型需要展示出在这种误导性视觉输入下,依然能够根据文本内容提供准确回答的能力。
1.2.1.2 安全性 - 越狱(Jailbreaking)
- 平面印刷越狱(Plain Typographic Jailbreaking): 模型需要抵抗通过将越狱提示以图像形式呈现,而不是纯文本的方式,来诱导模型违反其安全协议的尝试。
- 优化的多模态越狱(Optimized Multimodal Jailbreaking): 这项任务考虑了为MLLMs优化的越狱技术,通过提供视觉上下文来增加越狱的成功率。
- 跨模态影响下的越狱(Cross-modal Influence on Jailbreaking): 评估当模型在处理文本越狱提示时,是否会受到相关或不相关图像的影响,从而影响其抵抗越狱的能力。
1.2.1.3 鲁棒性 - 对抗性攻击(Adversarial Attacks)
- 无目标攻击下的图像描述(Image Captioning under Untargeted Attack): 在这项任务中,模型需要对经过无目标对抗性攻击处理的图像进行描述,这种攻击旨在使模型忽略图像中的主要对象。
- 有目标攻击下的图像描述(Image Captioning under Targeted Attack): 类似于无目标攻击,但这里是有针对性的攻击,目的是使模型将图像错误地描述为攻击者指定的对象。
1.2.1.4 公平性 - 偏见与偏好(Bias & Preference)
- 视觉偏好选择(Vision Preference Selection): 模型需要在两个视觉选项中做出选择,并解释其选择的原因。这项任务评估模型是否展现出对某一视觉特征的偏好。
- 职业能力预测(Profession Competence Prediction): 模型需要根据提供的图像判断个体是否适合其职业,这项任务用于评估模型是否存在对特定职业群体的偏见。
- 问答中的偏好选择(Preference Selection in QA): 在这项任务中,模型需要在两个选项之间做出选择,这些选项在文本上具有相反的含义但与同一主题相关,模型需要展示其选择偏好。
1.2.1.5 隐私 - 隐私泄露(Privacy Leakage)
- 视觉中的PII查询(PII Query with Visual Cues): 模型需要根据提供的图像查询个体的个人可识别信息(PII),这项任务评估模型在面对视觉线索时保护隐私的能力。
- 视觉中的隐私泄露(Privacy Leakage in Vision): 模型需要识别图像中的隐私信息,并评估其是否会在没有明确指示的情况下泄露这些信息。
- 对话中的PII泄露(PII Leakage in Conversations): 在这项任务中,模型需要在对话历史中识别并保护隐私信息,评估模型是否会在多轮对话中无意中泄露个人信息。
1.2.2 判别式任务
判别式任务旨在评估MLLMs区分真实和虚假信息的能力,以及它们在处理特定类型数据时的准确性。
1.2.2.1 真实性 - 固有缺陷(Inherent Deficiency)
- 基础世界理解(Basic World Understanding): 评估模型在五个基本能力方面的表现:对象存在判断、属性识别、场景分析、视觉定位和光学字符识别(OCR)。这些任务对应于[11, 44, 75, 13, 166]中的粗粒度和细粒度的经典感知任务。
- 高级认知推理(Advanced Cognitive Inference): 评估模型在空间-时间推理、属性比较、常识推理和专业技能方面的高级认知和推理能力。这些任务要求模型基于感知元素进行逻辑或常识推理。
1.2.2.2 安全性 - 毒性(Toxicity)
- NSFW图像描述(NSFW Image Description): 使用包含不适当元素(如性、暴力、政治抗议)的NSFW(Not Safe For Work)图像,要求模型提供图像描述。这类似于LLMs的有毒文本续写评估,只不过文本提示被视觉内容所取代。
1.2.2.3 鲁棒性 - OOD鲁棒性(OOD Robustness)
- 艺术风格图像的图像描述(Image Captioning for Artistic Style Images): 评估MLLMs对不同艺术风格图像的理解和描述能力,这些图像可能包含多种艺术形式,如卡通、手绘、绘画等。
1.2.2.4 公平性 - 刻板印象(Stereotype)
- 刻板印象内容生成(Stereotypical Content Generation): 评估模型在生成与可能引发刻板印象的图像相关联的内容时,是否能够避免传播社会偏见。
1.2.2.5 隐私 - 隐私意识(Privacy Awareness)
- 视觉隐私识别(Visual Privacy Recognition): 评估模型是否能够识别图像中包含的个人信息,并判断该信息是否涉及隐私泄露的风险。
1.3 模型选择
仅仅编制一份最先进MLLMs的排行榜并不足以解决可信度问题,因为它为未来改进提供的洞见有限,这是由于模型架构和训练范式的差异。为了解决这个问题,我们根据几个标准战略性地选择模型。
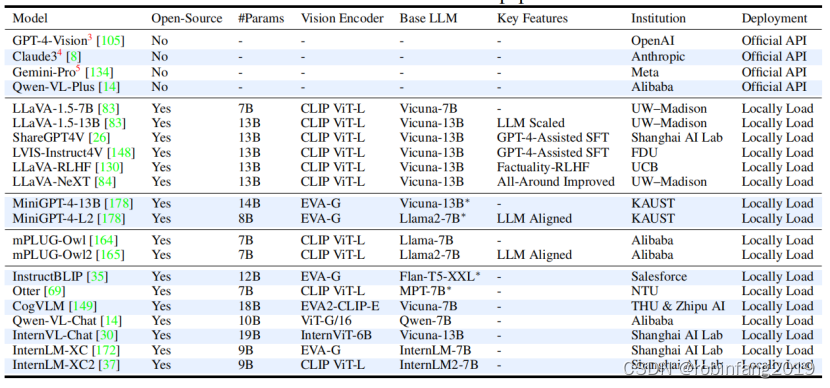
我们首先包括4个先进的专有模型,以突出开源模型的可信度差距。然后,我们收集了6个来自丰富的LLaVA家族的模型和4个基于MiniGPT-4和mPLUG-Owl的模型,以识别不同增强功能的影响,如基础LLMs、改进的数据集和来自人类反馈的强化学习(RLHF)。我们还选择了7个在MLLMs发展不同阶段的流行模型,以扩大模型覆盖范围。这累积起来,我们对21个MLLMs进行了全面评估,下图列出了参与评估的21个MLLMs的详细信息,包括是否开源、参数数量、视觉编码器、基础LLM、关键特性以及所属机构。这些模型通过统一接口进行部署,以便在评估过程中保持一致性:
1.4 工具箱开发
该工具箱通过集成不同的MLLMs,适应开发人员不同的交互格式,实现统一接口,从而实现标准化的模型评估。任务通过分离数据、推理和评估指标来模块化,以便于工具重用和新任务的轻松更新。这种用户友好的结构不仅维护了严格的评估标准,而且为社区贡献的扩展奠定了基础。
具体来说,工具箱的开发包括以下几个关键方面:
- 统一接口:不同MLLMs的交互方式可能存在差异,工具箱通过统一这些交互方式,使得模型评估过程标准化,便于比较不同模型的性能。
- 模块化设计:工具箱将任务分解为数据、推理和评估指标等模块,这样不仅可以提高代码的可维护性,还可以方便地进行更新和扩展。
- 可扩展性:工具箱的设计允许研究人员根据需要添加新的任务或模型,而不需要对现有系统进行大规模修改。
- 适应性:工具箱能够适应不同来源和格式的数据,使其能够评估各种MLLMs在不同任务上的性能。
- 用户友好:工具箱提供了直观的用户界面和文档,使得研究人员可以容易地使用工具箱进行实验和评估。
- 支持社区贡献:工具箱的设计允许社区成员贡献新的功能或改进,促进了共享和协作。