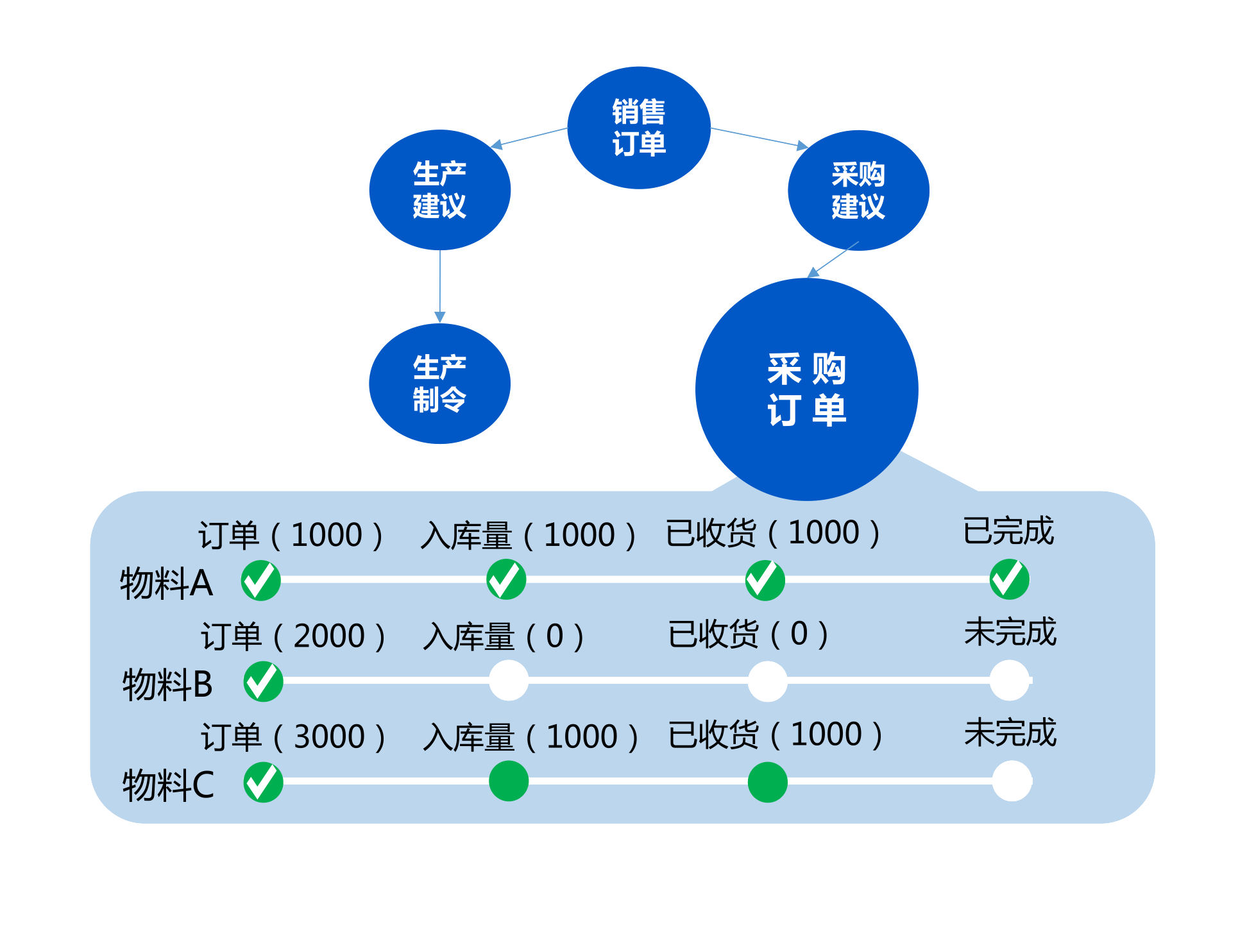
在编写kettle任务时往往需要连接数据库,kettle一共提供了四种数据库配置方式,JDBC、ODBC、OCI、JNDI,我最初直接使用的最为熟悉的JDBC,但是多写几个转换程序就会发现,每新建一个转换任务文件时都需要重新配置数据信息,不胜其烦,那么有没有快捷一些的方式避免这个问题呢?我们先来了解以下这几种方式的区别:
首先,因为我目前也是在逐步的学习中,可能存在一定偏颇。先下结论,逐步印证。
JDBC(测试使用推荐,复杂场景不推荐)
JNDI(测试、复杂场景都试用)
OCI (用于Oracle)
ODBC(我没用过)
复杂场景:主要指正式场景下会出现多环境(开发、测试、生产),每一个转换任务数据库的配置就会写入到响应的文件中,复杂场景多人协作、功能拆分,很可能一个JOB会由很多个转换联合,当部署生产时再去挨个文件改配置不现实。
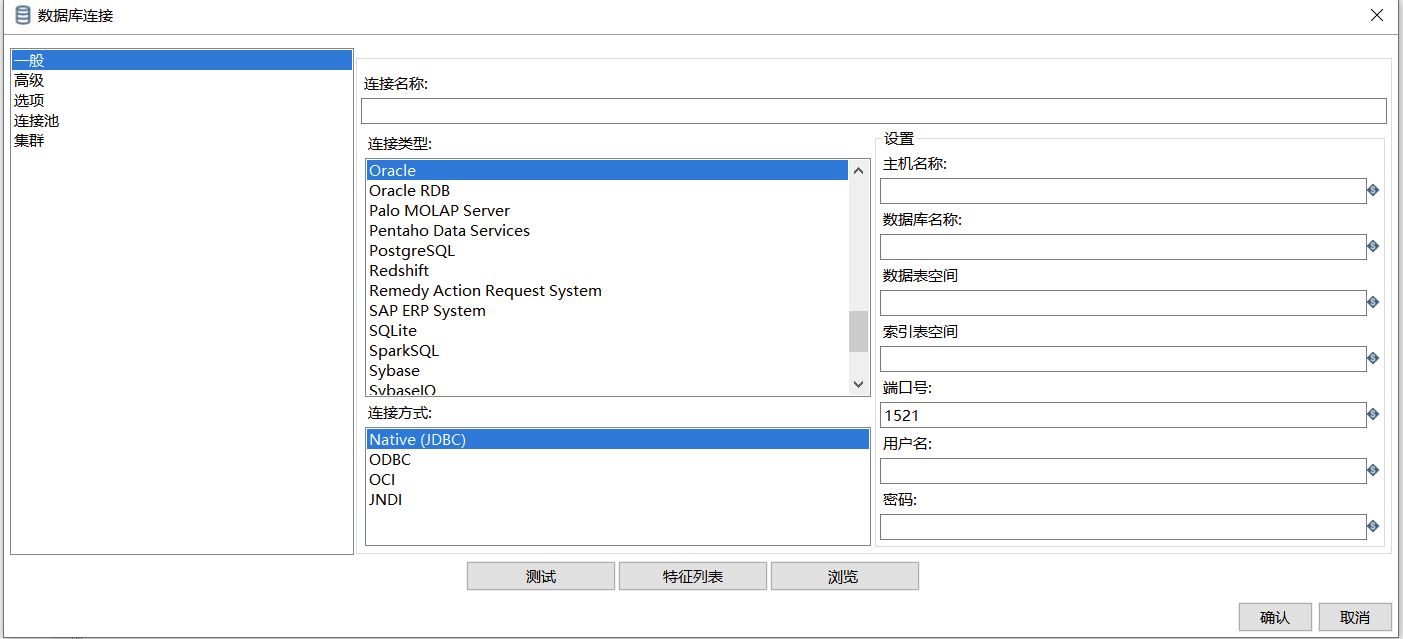
JDBC(测试使用推荐,复杂场景不推荐)
最常用的数据库,相信一看见就明白,不再赘述。至于为什么测试使用推荐,因为常用、熟悉、直观。为什么复杂场景不推荐,首先需要了解数据库配置去了哪里?kettle是怎么应用数据库配置连接数据库的?其实数据库的配置都存储在了我们的转换任务里,每换一次环境就要改一次配置,不现实。

2. JNDI(测试、复杂场景都试用)

通过上图可以看出,我们只需要提供一个数据库自定义名称 以及 一个JNDI名称。具体JNDI的名称从哪里来?
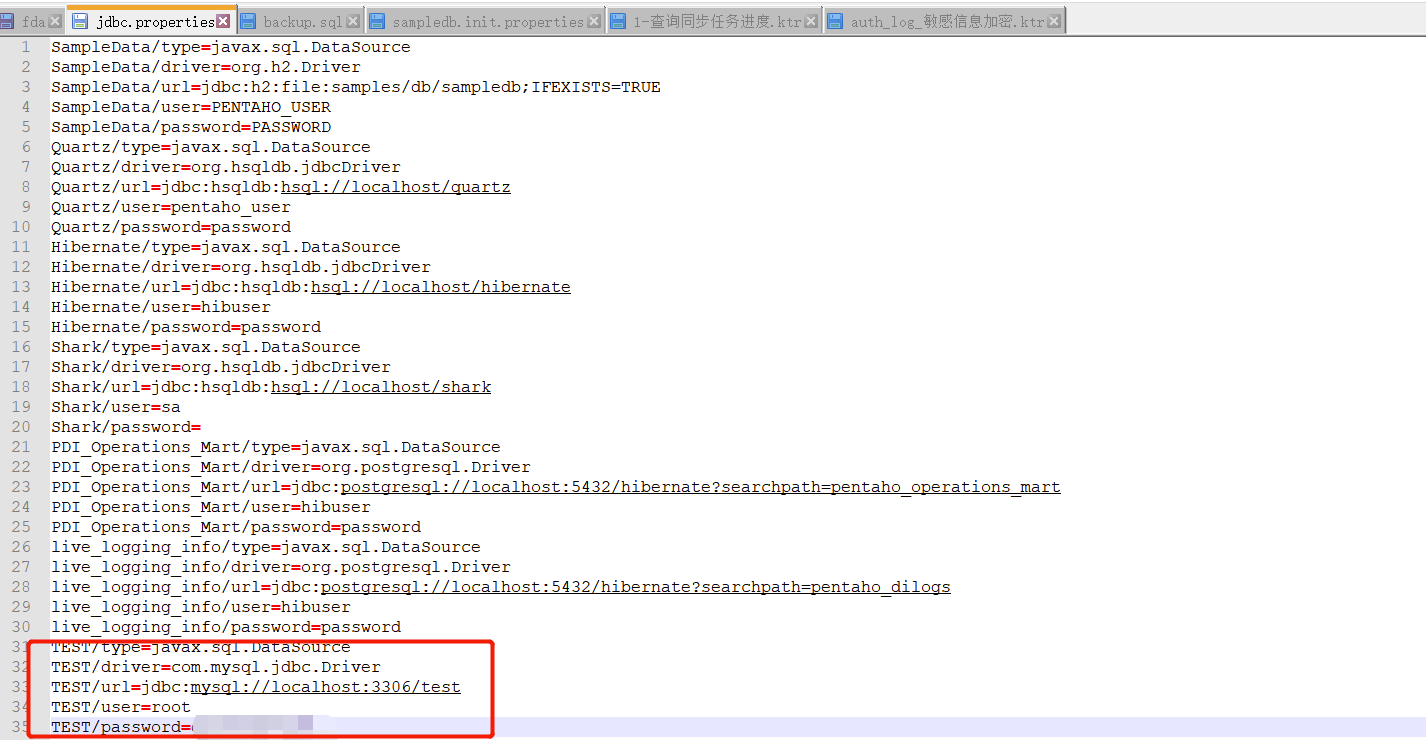
在kettle的安装路径,data-integration\simple-jndi下有一个配置文件jdbc.properties,主需要按照如下图所示增加数据库配置即可,生产部署时只需要修改为响应的配置即可,所有转换任务中通过JNDI“TEST”创建的转换直接生效使用。