文章目录
- 1、离线评估
- 1.1、评估排序算法
- 1.1.1、AUC和GAUC
- 1.1.2、NDCG
- 1.2、评估召回算法
- 1.2.1、Precision&Recall
- 1.2.2、MAP
- 1.2.3、Hit Rate
- 1.2.4、持续评估
- 2、在线评估
- 2.1、线上:流量划分
- 2.1.1、根据User ID划分流量
- 2.1.2、分层重叠划分流量
- 2.1.3、A/A实验的重要性
- 2.2、线下:统计分析
- 2.3、其他事项
- 模型上线前需要进行离线评估;模型上线后需要进行在线评估。
- 推荐系统的评估流程:
1)离线评估:在相同的训练集上,不同算法训练出新旧两版模型,在同一个测试集上进行评估。若新模型的指标优于旧模型,则通过离线测试,可进入下一阶段。注意:离线评估的训练集一般采用连续3天或7天的历史数据;在第4天或第8天的数据上测试
2)上线前回溯:新模型在上线评估之前必须先进行回溯,比如自两周前的历史数据开始训练,直到追平并接入线上的实时样本流。之后,新旧模型就能够同步接收线上的实时反馈并自我更新,才能进行后续A/B实验的在线评估
3)在线评估:A/B 实验,随机划分为两份流量:控制组(流入老模型);实验组(流入新模型,可以有多个)。实验一段时间后,统计关键业务指标(例如CTR、平均观看时长等),若实验组显著优于控制组,就认为新模型优于旧模型,可考虑推广至全部流量
1、离线评估
- 主要针对排序(粗排和精排)和召回算法,存在不同的评估指标
1.1、评估排序算法
1.1.1、AUC和GAUC
- 评估排序模型最重要的指标是AUC(ROC曲线下面积,以TPR和FPR分别为纵坐标和横坐标 )
- AUC更为直观的解释:模型给一堆样本(正负类别标签已知)预测打分,然后将他们从大到小排序,正样本能够正确排在负样本前面的概率就是AUC
A U C = 正确排序的样本对 所有样本对 AUC = \frac{正确排序的样本对}{所有样本对} AUC=所有样本对正确排序的样本对
一个正样本和负样本可组成一个样本对
正确排序是指按概率,将正样本排在负样本之前
下图显示的AUC为7/9

- 从上述定义来看,AUC天然适合衡量模型的排序性能,然而AUC体现的是全局的性能,会将所有用户的排序结果都考虑进来,可能会存在失真,因此可以引入GAUC(Groupwise AUC),将样本划分为group,每个group计算一个AUC,最后再加权平均
- 一般以用户为单位划分group计算GAUC:
G A U C = ∑ u w u A U C u ∑ u n u GAUC = \frac{ {\textstyle \sum_{u}w_uAUC_u} }{\sum_{u}n_u} GAUC=∑unu∑uwuAUCu
A U C u AUC_u AUCu是在用户u的样本上计算的AUC, n u n_u nu是给用户u曝光过的物料数目
- 由于AUC/GAUC只能针对的是二分类,对于CTR、CVR指标是可以的,针对实数型目标(比如观看时长、销售金额),可以转换为二分类目标,例如是否会有效播放(观看超过15秒)、是否会长播放
1.1.2、NDCG
- 需要注意的一点是,物料在展示列表的位置可以反映物料的价值(越靠前,价值越高)
- 而AUC无法反应排序位置这个因素的影响
- 因此,引入DCG(Discounted Cumulative Gain)指标:
D C G @ K = ∑ k = 1 K 2 c k − 1 l o g 2 k + 1 DCG@K = \sum_{k=1}^{K}\frac{2^{c_k}-1}{log_2{k+1}} DCG@K=k=1∑Klog2k+12ck−1
- K是排序结果的长度
- c k c_k ck是第k个位置的物料贡献,未点击为0,点击为观看时长、点赞等的函数
- 从上述公式可看出,越靠后的位置,其DCG越大
- 为了做归一化,定义理想情况下的DCG为IDCG,即按照物料的真实贡献从高到低排序计算出的DCG,然后得到NDCG(Normalized DCG):
N D C G @ K = D C G @ K I D C G @ K NDCG@K = \frac{DCG@K}{IDCG@K} NDCG@K=IDCG@KDCG@K - 由于排序长度不同,直接计算DCG不易比较,而归一化后的NDCG可以进行比较
1.2、评估召回算法
- 评估召回模型时,一般不用AUC这样强调排序性能的指标
如果用AUC进行评估,正样本为点击过的样本,而负样本若为曝光未点击的样本,与召回的真实样本情况(包含大量和用户毫不相关的样本)不符;若负样本为除点击之外的其他物料,也不能保证这些物料一定不喜欢
*因此,要避免直接统计负样本,而是从预测的正样本与真实的正样本之间的命中率、覆盖度角度进行评估
1.2.1、Precision&Recall
- 以双塔召回模型为例,可进行如下P和R值的计算:
u i u_i ui表示第i次推荐请求的用户
T i e x p o s e T_i^{expose} Tiexpose表示第i次请求中向用户曝光的物料集合
T i c l i c k T_i^{click} Ticlick表示用户点击的物料集合
- 计算得到的**
P
r
e
c
i
s
i
o
n
@
K
Precision@K
Precision@K:平均下来,每次召回的物料中真正被用户喜欢的占比;
R
e
c
a
l
l
@
K
Recall@K
Recall@K:平均下来,一个用户真正喜欢的物料中有多大占比能被模型召回。**


1.2.2、MAP
- Precision和Recall是一对此消彼长的指标,即召回的越多,Recall越高,Precision会随之下降
- 因此采用AP值来衡量召回能力比P和R值更全面,计算过程为:设置不同i值,即取前i个物料作为召回结果计算PR曲线,以及曲线下面积即为AP。AP值的计算方法如下:
A P @ K = ∑ i = 1 K P r e c i s i o n @ i × I s P o s i t i v e @ i T o t a l P o s i t i v e s AP@K = \frac{ {\textstyle \sum_{i=1}^{K}}Precision@i\times IsPositive@i }{TotalPositives} AP@K=TotalPositives∑i=1KPrecision@i×IsPositive@i
- K表示最大的召回数量
- TotalPositives表示本次召回中用户喜欢物料的数目
- Precision@i表示前i个召回结果的Precision
- IsPositive@i表示第i个召回结果是否为用户所喜欢,喜欢为1,不喜欢为0
- 将多次召回结果的AP取平均,几位MAP,可以用来衡量模型的整体召回性能
- 例子和具体计算流程如下:


1.2.3、Hit Rate
- Hit Rate表示在N条点击记录中,有多少物料可以被召回模型所覆盖

1.2.4、持续评估
- 模型需要实时地持续更新,同时也需要持续评估
- 为了实现无偏的估计,常采用Progressive Validation的方法
1)模型拿到最新一批的用户反馈后,先进行前向传播得到预测结果
2)一边反向传播更新模型,一边拿预测结果与用户反馈真值计算各种评估指标
- 这种方式可以共用前向传播环节,避免重复计算;同时由于模型未更新,基于当前预测结果的指标是无偏的,更可信
2、在线评估
- A/B实验是推荐系统中的最常用的线上评估方式,思路如下:
1)将用户流量随机划分为控制组和实验组
2)控制组流量流入老模型,实验组流量流入新模型,其中只有模型不同,其余的用户分布、物料分布等必须完全相同
3)上线实验一段时间,积累足够多的用户反馈
4)根据收集到的用户反馈,统计关键业务指标
5)若实验组的指标优于控制组,可以考虑新模型替换旧模型
- A/B实验更加客观、公平可靠,但是其整个实验系统功能复杂、实现难度高,并且要求进行足够长的时间,至少覆盖一个完整的周期,例如一周(周中和周末不一样)
- 下面介绍线上实验和线下分析的关键知识点
2.1、线上:流量划分
- 线上的流量划分需要遵循以下两个原则,以保证两组流量的同分布原则:
1)随机性:一个用户被划分到控制组和实验组是完全随机的
2)确定性:当一个用户被划分到哪个组,今后的访问也必须在相同的组
2.1.1、根据User ID划分流量
- 最简单的方式是根据User ID随机划分到控制组和实验组
- 但是这种方式最大问题在于,一个用户一次只能进行一个实验,例如召回和精排很容易就将全部流量占满了,而通常有很多实验需要上线验证,就会导致排队阻塞的问题。
- 因此一般利用分层重叠的方式

2.1.2、分层重叠划分流量
- 分层划分的思想如下:
1)如果进行N个实验,就将流量划分为N层,每个实验独占一层流量
2)同一层实验的各个实验组的流量是互斥的,即一个用户只会被划分到一个组里
3)不同层的实验,流量是重叠的,一个用户可以被分配到不同层的多个组里
- 这种方式中,上下层的实验的流量完全正交,用户流量在前几层实验的不同划分,并不会在后续实验引入偏差。

- 需要注意的是,Layer层并没有层次的关系,就只是指的不同的实验,并且流量在进入一个新的实验前会被重新打散
2.1.3、A/A实验的重要性
- A/A实验就是在控制组和实验组采用完全相同的配置
- 在进行正式的A/B实验前最好先进行一段时间的A/A实验,检验实验的两组流量是否存在偏差
2.2、线下:统计分析
- 可以通过显著性检验的方式验证新模型的性能,是否显著优于旧模型
- 常会遇到I类错误和II类错误
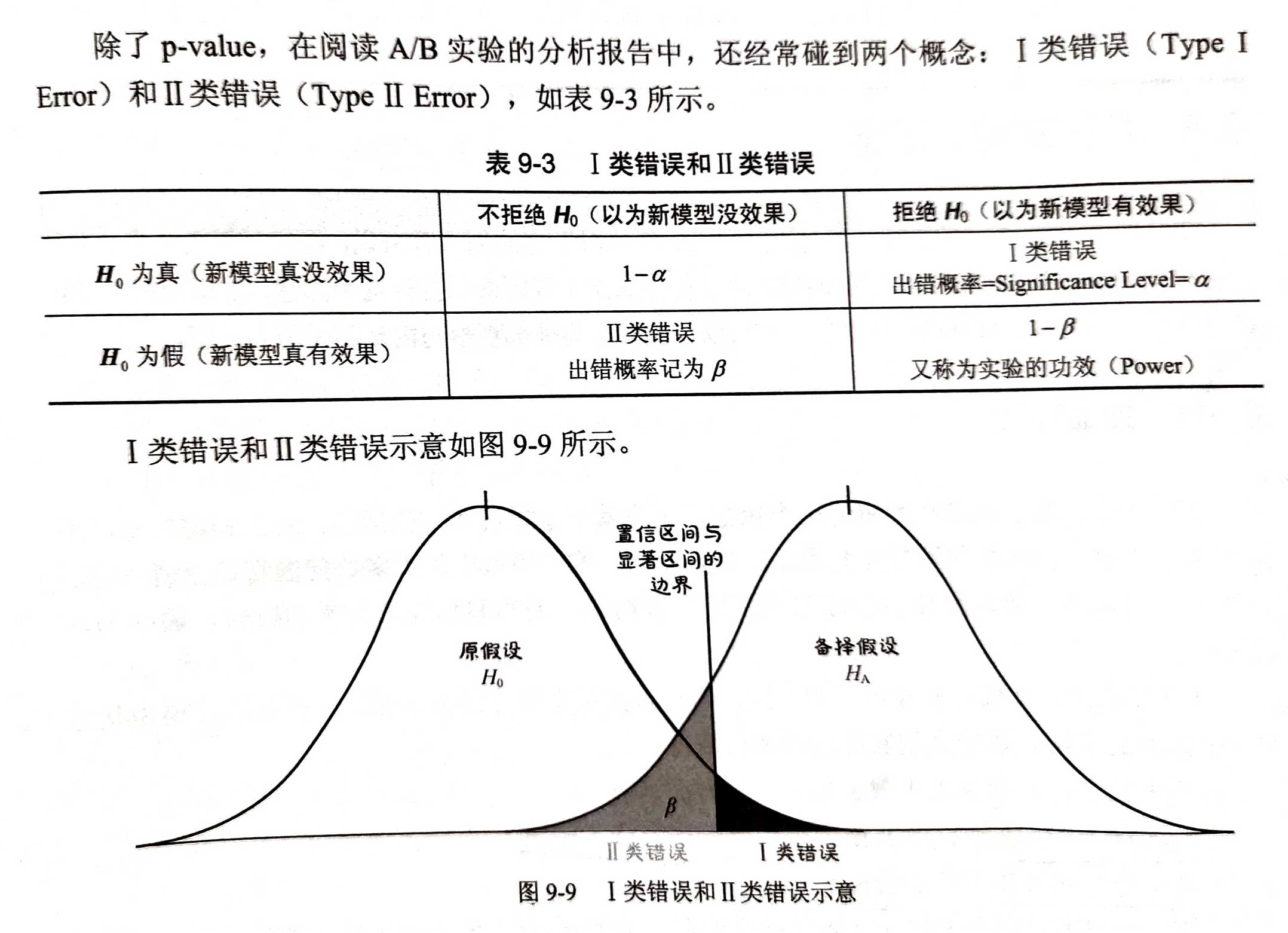
2.3、其他事项
- 在做出新模型推广至全部流量的决定时,还要综合来考虑业务收益的性价比,如果只有微小提升,对业务的影响微乎其微,就不值得推广
- 不止要考虑在全体流量上的结果,也要考察在细分流量上的差异(例如新老客户、不同国家、不同频道等)
参考书籍:
《互联网大厂推荐算法实战》