集成学习是一种机器学习方法,它通过结合多个模型的预测结果来提高整体性能和稳定性。这种方法的主要思想是“集合智慧”,通过将多个模型(比如决策树、随机森林、梯度提升机等)的预测集成起来,可以减少单个模型的过拟合风险,同时提高对未知数据的泛化能力。
集成学习主要有两种主要形式:
- bagging(自助法/Bootstrap aggregating):这种方法创建多个训练集,每个训练集由原始数据随机抽取并保持数据的多样性。然后,对每个子集训练独立的模型,最后将它们的预测结果取平均或投票来得出最终结果。
- boosting:这是一种迭代过程,每次训练时专注于那些被前一轮错误分类的样本。 AdaBoost、Gradient Boosting Machine (GBM) 等就是典型的 boosting 方法。它们逐步提高弱模型的权重,形成一个强健的组合模型。
优点:
- 提高准确性和稳定性:通过集成多个模型,降低了单个模型失效带来的影响。
- 减少过拟合:由于模型之间有竞争,它们可能不会过度拟合特定的训练数据。
- 可以处理各种类型的数据:包括数值型、分类型和非结构化数据。
集成学习在以下情况下特别有效:
- 处理复杂数据:当数据集包含多个特征和复杂的非线性关系时,集成方法如随机森林或梯度提升机能够通过组合多个模型的结果提高预测精度。
- 减少过拟合:通过结合多个基础模型,集成学习可以降低单个模型过拟合的风险,因为每个模型可能学习到数据的不同部分。
- 提高稳定性和鲁棒性:集成学习模型通常比单个模型更稳定,即使其中一个模型表现不佳,整体性能也往往不会受到太大影响。
- 利用不同学习算法的优势:可以将弱学习器组合成强学习器,如AdaBoost将弱分类器逐步调整以关注难以分类的数据。
- 数据不平衡问题:集成方法能更好地处理类别分布不均的数据,通过加权或平衡采样等方式,提高少数类别的预测能力。
- 模型融合:例如,通过投票、平均等方式,将不同的模型预测结果整合起来,提高最终决策的可靠性。
应用案例:信用卡还贷情况预测。
数据获取(UCI_Credit_Card.csv) 30000 行客户等还款记录,有 25 列,包含客户的基本信息,每月的 还款记录,以及需要我们预测的目标—是否违约。
首先加载数据集,查看数据集概况,并做数据清洗:
1)EDUCATION(教育背景):将其中值为 0,5,6 的样本对应值修改为 4
2)MARRIAGE(婚姻状况):0 值的样本修改为 3
#加载数据
import pandas as pd
data = pd.read_csv('UCI_Credit_Card.csv')
#查看数据概况
data.info()
#数据清洗
#将'EDUCATION'列中值为0,5,6,改为4
data['EDUCATION'].replace({0:4,5:4,6:4},inplace=True)
#将'MARRIAGE'列中值为0,改为3
data['MARRIAGE'].replace({0:3},inplace=True)
#划分特征集和类别集
x = data.iloc[:,1:-1]
y = data.iloc[:,-1]
#划分数据集
from sklearn import model_selection
x_train,x_test,y_train,y_test = model_selection.train_test_split(x,y,
test_size=0.2,
random_state=1)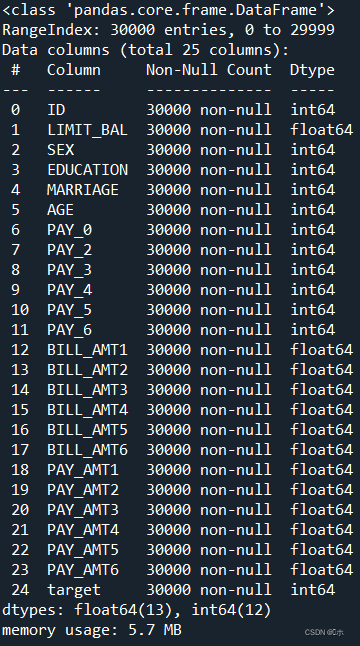
通过.info查看数据集概况可知,该数据集有25个属性列,共30000个样本数据。没有缺失值,最后一个属性列“target”为下个月还款违约情况
建立预测集成训练模型:
1、Bagging集成模型
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import BaggingClassifier
bagging = BaggingClassifier(KNeighborsClassifier(),
max_samples=0.5,
max_features=0.5)
bagging.fit(x_train,y_train)
pred1 = bagging.predict(x_test)
from sklearn.metrics import classification_report
#输出:Accuracy、Precisio、Recall、F1分数等信息
print('bagging模型评估报告:\n',classification_report(y_test,pred1))
print('bagging模型的准确率为:',bagging.score(x_test,y_test))
#计算AUC得分
y_predict_proba_1 = bagging.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_1, tpr_1, thretholds_1 = roc_curve(y_test, y_predict_proba_1[:,1])
from sklearn.metrics import auc
AUC_1 = auc(fpr_1,tpr_1)
print('ROC曲线下面积AUC为:',AUC_1)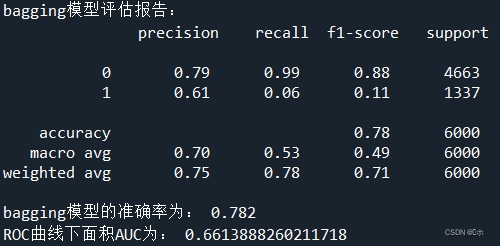
指标说明:
Accuracy:准确率
Precisio:查准率 、精确率
Recall:查全率 、召回率、敏感率、真正例率
F1分数:衡量分类模型精确度的一个指标,可视为精确率和召回率的一种调和平均
2、Random Forest集成模型
from sklearn.ensemble import RandomForestClassifier
RF = RandomForestClassifier()
RF.fit(x_train,y_train)
pred2 = RF.predict(x_test)
print('RandomFore模型评估报告:\n',classification_report(y_test,pred2))
print('RandomFore模型的准确率为:',RF.score(x_test,y_test))
#计算AUC得分
y_predict_proba_2 = RF.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_2, tpr_2, thretholds_2 = roc_curve(y_test, y_predict_proba_2[:,1])
from sklearn.metrics import auc
AUC_2 = auc(fpr_2,tpr_2)
print('ROC曲线下面积AUC为:',AUC_2)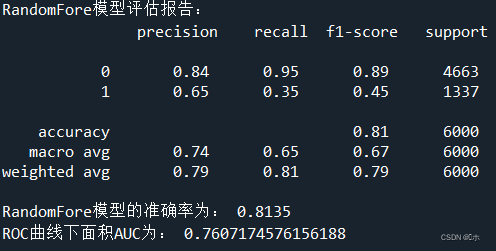
3、AdaBoost集成模型
from sklearn.ensemble import AdaBoostClassifier
AB = AdaBoostClassifier(n_estimators = 10)
AB.fit(x_train,y_train)
pred3 = AB.predict(x_test)
print('AdaBoost模型评估报告:\n',classification_report(y_test,pred3))
print('AdaBoost模型的准确率为:',AB.score(x_test,y_test))
#计算AUC得分
y_predict_proba_3 = AB.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_3, tpr_3, thretholds_3 = roc_curve(y_test, y_predict_proba_3[:,1])
from sklearn.metrics import auc
AUC_3 = auc(fpr_3,tpr_3)
print('ROC曲线下面积AUC为:',AUC_3)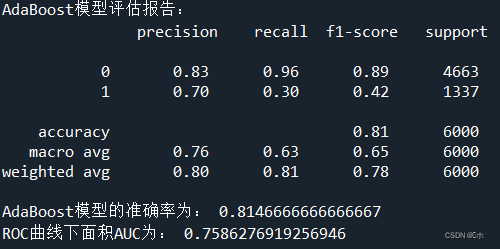
#特征重要性
impotrances = RF.feature_importances_
#模型参数
RF.get_params()#模型验证交叉验证
from sklearn.ensemble import AdaBoostClassifier
from sklearn.model_selection import cross_val_score
clf = AdaBoostClassifier(n_estimators=30)
scores = cross_val_score(clf,x,y,cv=10)
scores.mean()
4、决策树
from sklearn.tree import DecisionTreeClassifier
dct = DecisionTreeClassifier()
dct.fit(x_train,y_train)
pred4 = dct.predict(x_test)
print('决策树 模型评估报告:\n',classification_report(y_test,pred4))
print('决策树 模型的准确率为:',dct.score(x_test,y_test))
#计算AUC得分
y_predict_proba_4 =dct.predict_proba(x_test)
from sklearn.metrics import roc_curve
fpr_4, tpr_4, thretholds_4 = roc_curve(y_test, y_predict_proba_4[:,1])
from sklearn.metrics import auc
AUC_4 = auc(fpr_4,tpr_4)
print('ROC曲线下面积AUC为:',AUC_4)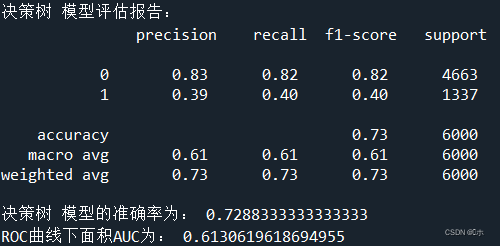
对四个模型测试结果ROC曲线对比:
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.family'] = ['SimHei'] #用来显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示符号
matplotlib.rc('axes', facecolor = 'white') #设置背景颜色是白色
matplotlib.rc('font', size = 14) #全局设置字体
matplotlib.rc('figure', figsize = (12, 8)) #全局设置大小
matplotlib.rc('axes', grid = True) #显示网格
fig = plt.figure()
ax = fig.add_subplot(1,1,1)
ax.plot(fpr_1,tpr_1,'d:y',linestyle = 'dashed',
label = 'bagging--AUC=%0.4f'%auc(fpr_1,tpr_1))
ax.plot(fpr_2,tpr_2,'s:r',linestyle = 'dashed',
label = 'RandomFore --AUC=%0.4f'%auc(fpr_2,tpr_2))
ax.plot(fpr_3,tpr_3,'v:b',linestyle = 'dashed',
label = 'AdaBoost--AUC=%0.4f'%auc(fpr_3,tpr_3))
ax.plot(fpr_4,tpr_4,'o:k',linestyle = 'dashed',
label = 'decision tree--AUC=%0.4f'%auc(fpr_4,tpr_4))
ax.legend(loc = 'best')
plt.title('测试结果 ROC曲线对比')
plt.xlabel('FPR')
plt.ylabel('TPR')
plt.savefig('测试结果 ROC曲线对比.png')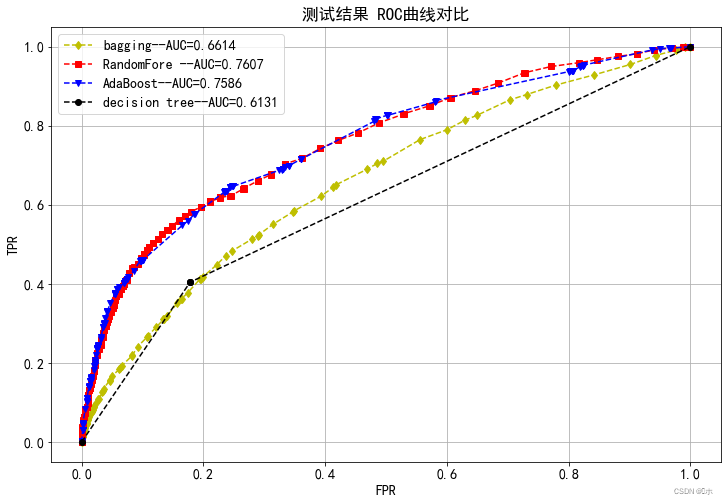
通过以上结果可以总结出:
| 模型 | 测试结果 | |||
| accuracy | precision(macro avg) | recall(macro avg) | AUC | |
| bagging | 0.78 | 0.7 | 0.53 | 0.6587 |
| Random Forest | 0.81 | 0.74 | 0.65 | 0.7594 |
| AdaBoost | 0.81 | 0.76 | 0.63 | 0.7586 |
| 决策树 | 0.72 | 0.6 | 0.61 | 0.609 |
可以看出四种模型中,随机森林和AdaBoost两个模型得到的结果在各个性能评估指标上都明显地优于baging和决策树。
随机森林和AdaBoost两个模型的各个指标都十分的相近,两模型之间的性能几乎没有什么差别;而baging和决策树两个模型之间,bagging的各个性能评估指标略微地优于决策树。
由此得出:最优的模型是随机森林和AdaBoost,其次是bagging,最后是决策树。