# 先执行for遍历将容器中的值赋给i, 在列表其它位置就可以使用i, 这里i仅作为列表的元素.print([i for i inrange(10)])# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
list1 =['kid','qz','qq']# 先执行for遍历将容器中的值赋给i, i在做字符串拼接.print([i +'_vip'for i in list1])# ['kid_vip', 'qz_vip', 'qq_vip']
list1 =['kid_vip','qz_vip','qq_vip']# 先执行for遍历将容器中的值赋给i, i做移除字符串操作.print([i.strip('_vip')for i in list1])# ['kid', 'qz', 'qq']
# 复杂格式, 先执行for, 在执行if语句,
list1 =['kid_vip','qz_vip','qq_vip']# 遍历列表, 取出元素马上进行if判断print([i.strip('_vip')for i in list1 if i =='kid_vip'])# ['kid']
# 面试题
list1 =[lambda x: x + i for i inrange(10)]# 保存十个匿名函数print(list1)# [<function <listcomp>.<lambda> at 0x000001D0B252F700>, ...]# 调用第一个匿名函数print(list1[0](10))# 19# 调用第二个匿名函数print(list1[1](10))# 19# 调用第三个匿名函数print(list1[2](10))# 19
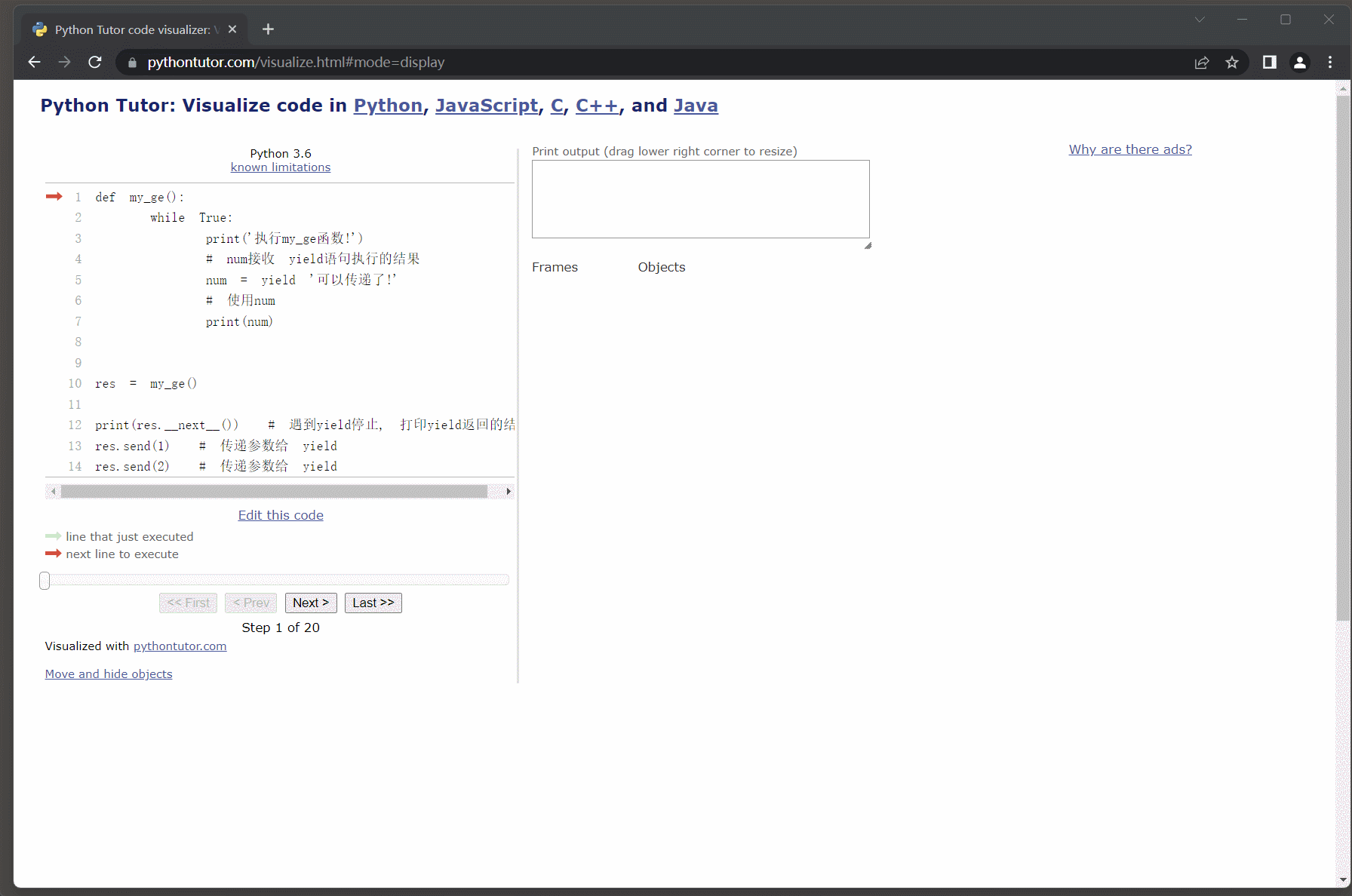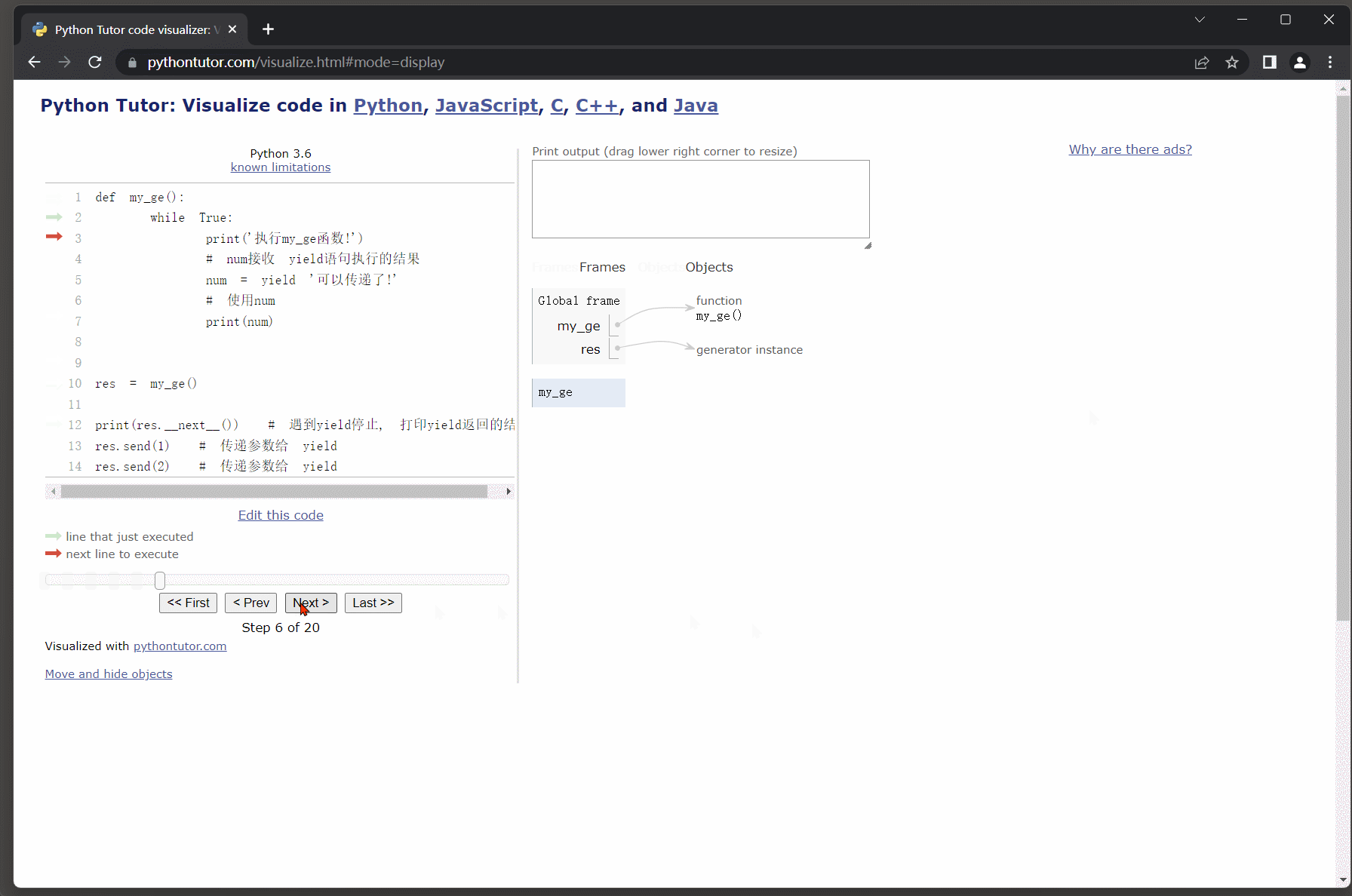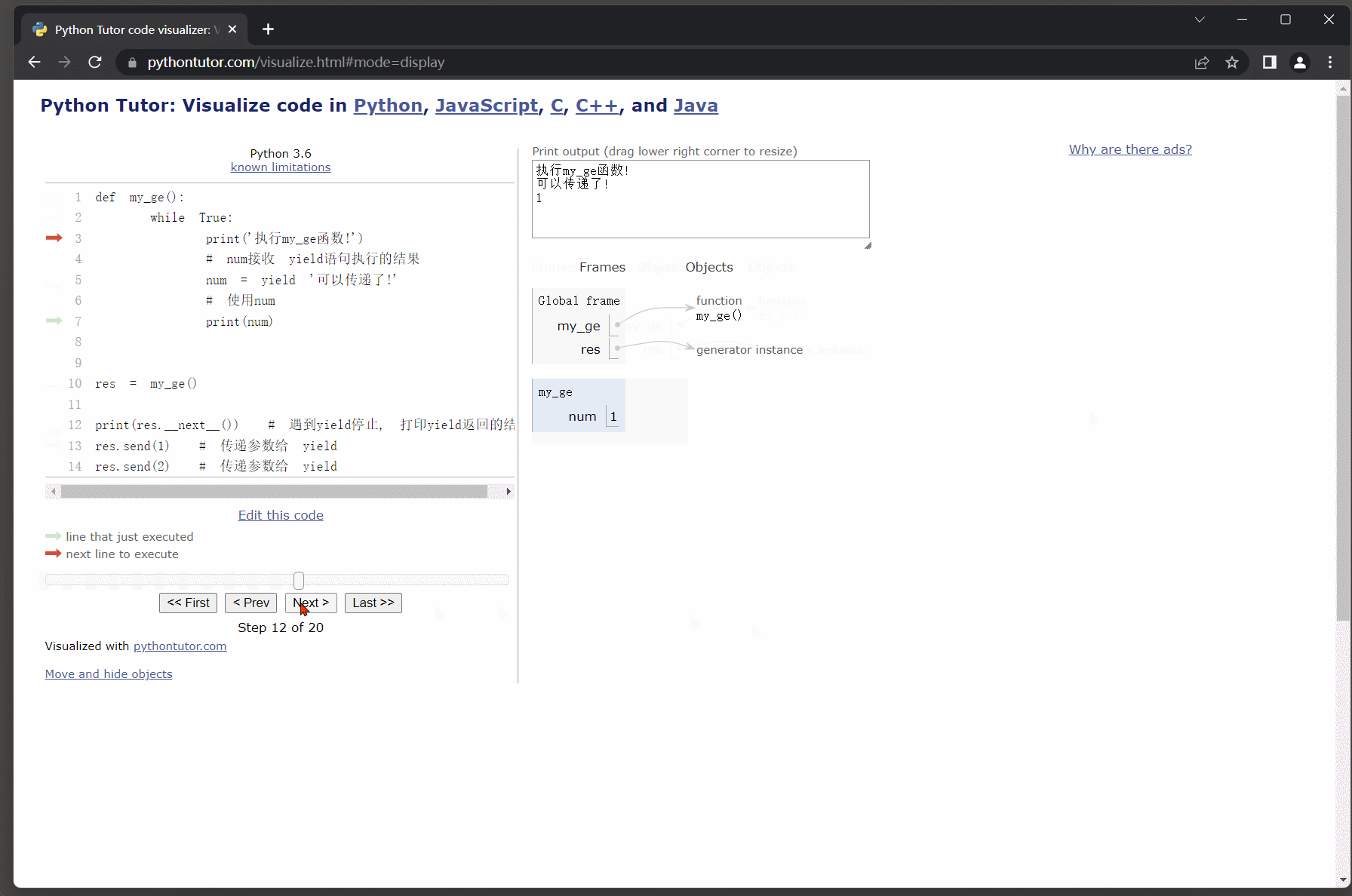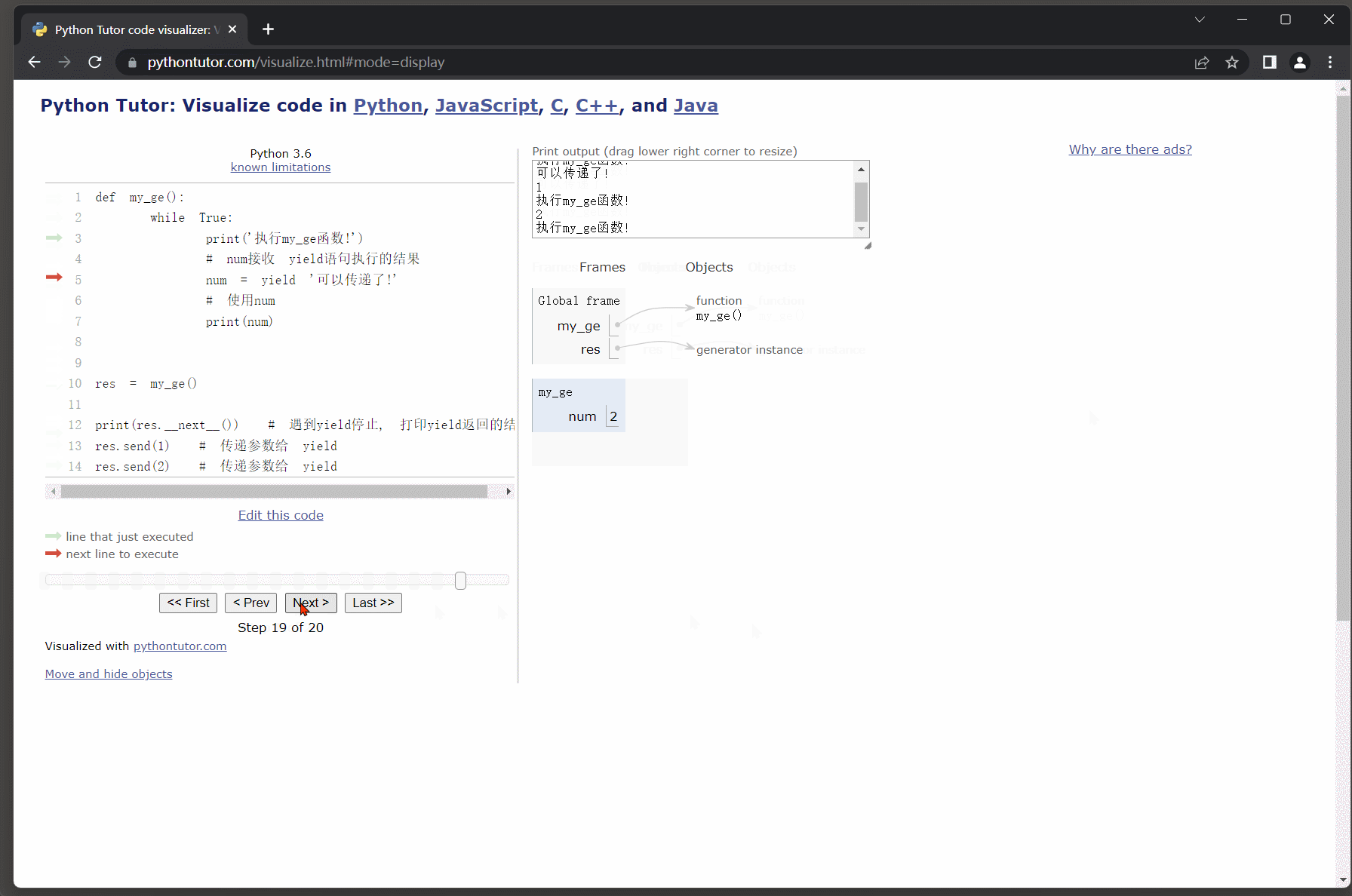
deffunc():
num =0print(num)# 通过yield返回值yield'yield1'
num +=1print(num)# 通过yield返回值yield'yield2'
num +=1print(num)# 接收生成器
res = func()# 迭代取值, 遇到yield语句则返回跟随它的值, 并且会暂停函数的运行保存函数的状态.print(res.__next__())# 再次迭代取值, 让函数继续运行, 从上次暂停的位置开始往后执行.print(res.__next__())# 函数还没执行完, 还需要通过.__next__()方法让程序继续完后执行,# 但执行之后.__next__()方法要求必须有返回值(也是就说说必须要有yield语句),# 后续并没有yield语句则会报错: StopIteration.try:
res.__next__()# 报错没有提示信息, 空白.except StopIteration as e:print(e)
运行工具窗口显示:0yield11yield22
# yield返回值deffunc():
num =0print(num)# 通过yield返回值yield'yield1'
num +=1print(num)# 通过yield返回值yield'yield2'
num +=1print(num)# 接收生成器
res = func()# for迭代取值for i in res:print(i)
# yield默认返回值deffunc():print(1)# 默认返回Noneyield# 接收生成器
res = func()# 迭代取值for i in res:print(i)# None
# 面试题deftest():for i inrange(4):yield i
# 得到一个生成器
g = test()for n in[1,10]:# 再次得到一个生成器, 生成器中的for不会执行, 它不会保存值只保留表达式.
g =(i + n for i in g)"""
n = 1
g = (i + n for i in g)
n = 10
g = (i + n for i in (i + n for i in test()))
"""
res =list(g)"""
g = (i + n for i in (i + n for i in (0, 1, 2, 3)) # n 为 10.
g = (i + 10 for i in (i + 10 for in (0, 1, 2, 3))
g = (i + 10 for i in (10, 11, 12, 13)
g = (10+10, 11+10, 12+10, 13+10
"""print(res)# 20 21 22 23
6. 练习
1.使用递归打印斐波那契数列(前两个数的和得到第三个数,如:1,2,3,5,8,13..)
defnum(x, y):if y >100:# 结束条件return# z = y# y = x + y# x = z
y, x = y + x, y
print(y, end=' ')# 1 2 3 5 8 13 21 34 55 89 144
num(x, y)
num(0,1)
2.一个嵌套很多层的列表,用递归取出所有的值.
list1 =[1,2,[3,[4,5,6,[7,8,[9,10,[11,12,13,[14,15]]]]]]]defget_num(list1):ifnotlen(list1):# 结束条件returnfor i in list1:# i是整数就打印iftype(i)==int:print(i, end=' ')# 否则就 递归else:
get_num(i)
get_num(list1)
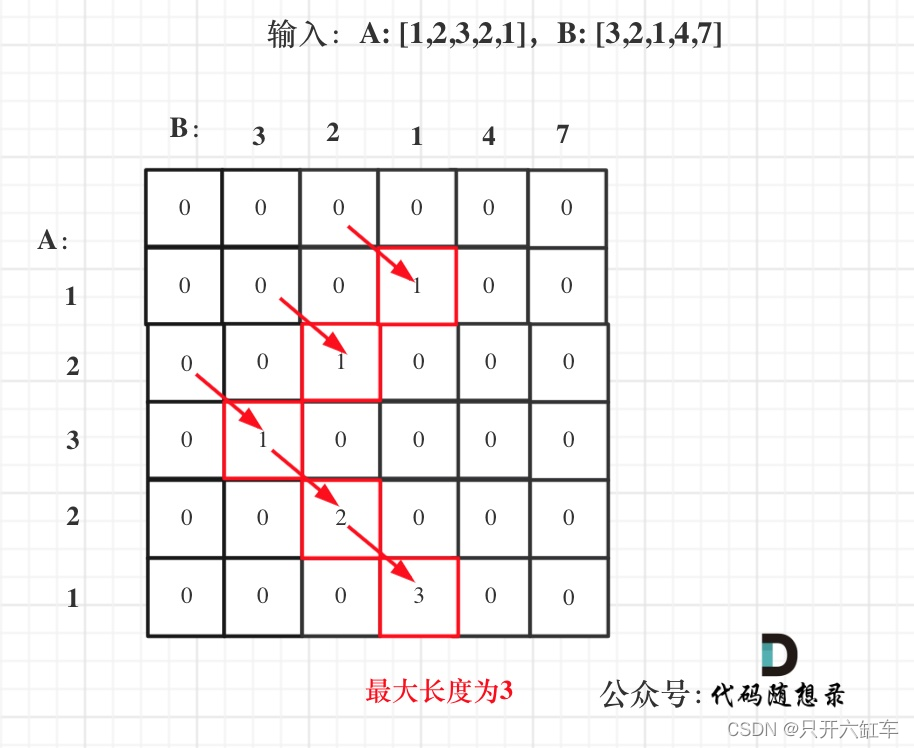
本题不算难,但是如果直接想dp数组怎么定义的话就会头晕,先想递推公式的含义就知道为什么需要冗余的dp[0][0]了 class Solution {public int findLength(int[] nums1, int[] nums2) {int res 0;//1.确定dp数组含义int[][] dp new int[nums1.length1][nu…
在制造业的广阔天地里,FMEA(Failure Modes and Effects Analysis,失效模式与影响分析)一直被视为质量控制的关键武器。然而,很多人认为只有懂产品和工艺的行家才能玩转FMEA,对于小白来说似乎遥不可及。今天…