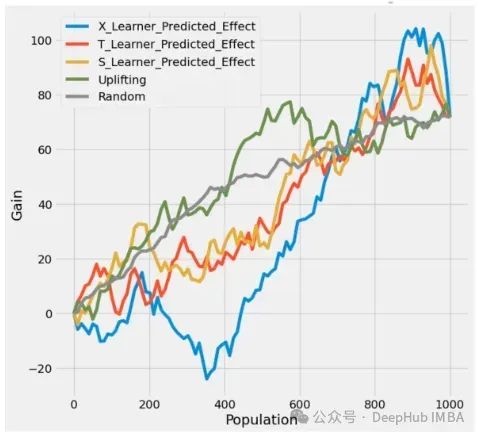
两者本质上是一个东西,都是用来求自注意力的,但具体而言还是有一些差别;
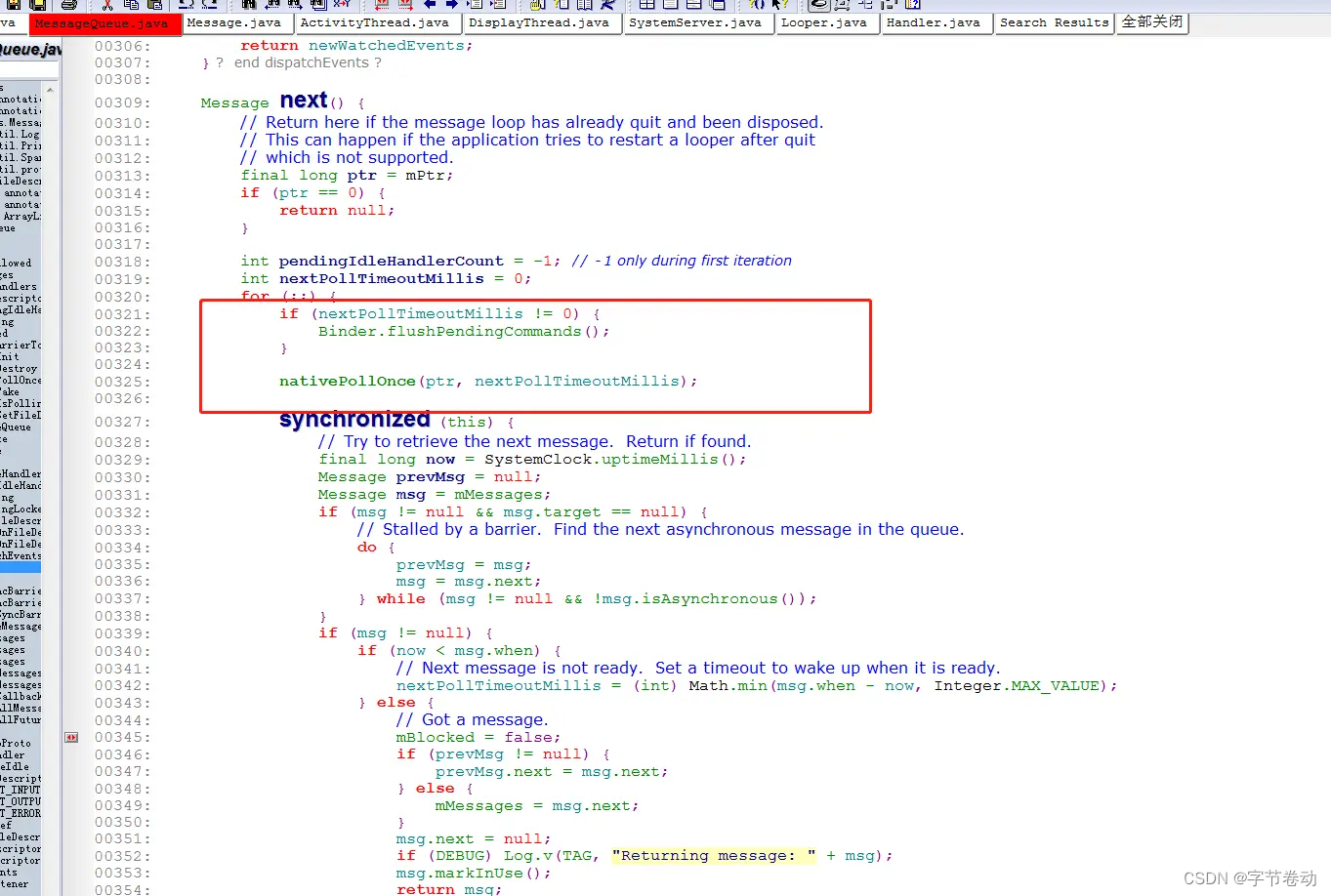
1:首先说Non-local,它是像素级别的self-attention,算的是图片中各个像素点对指定像素点的影响;
2:transformer我们拿swin-transformer和vision-transformer,来举例子。
如下可,我们可以看到,两者都对图像进行了分块,不同的是swin-transformer先分了大块,再在大块里面分小块,而VIT就只分为固定的快,然后他们在做self-attention的时候,其实是算的块与块之间的注意力,但值得注意的是swintranformer只算每一个大块里面的小块之间的注意力,也就是大块与大块之间不做注意力计算。
图和内容均参考自:http://Vision transformer_MarDino的博客-CSDN博客_transformer vision
https://zhuanlan.zhihu.com/p/485716110

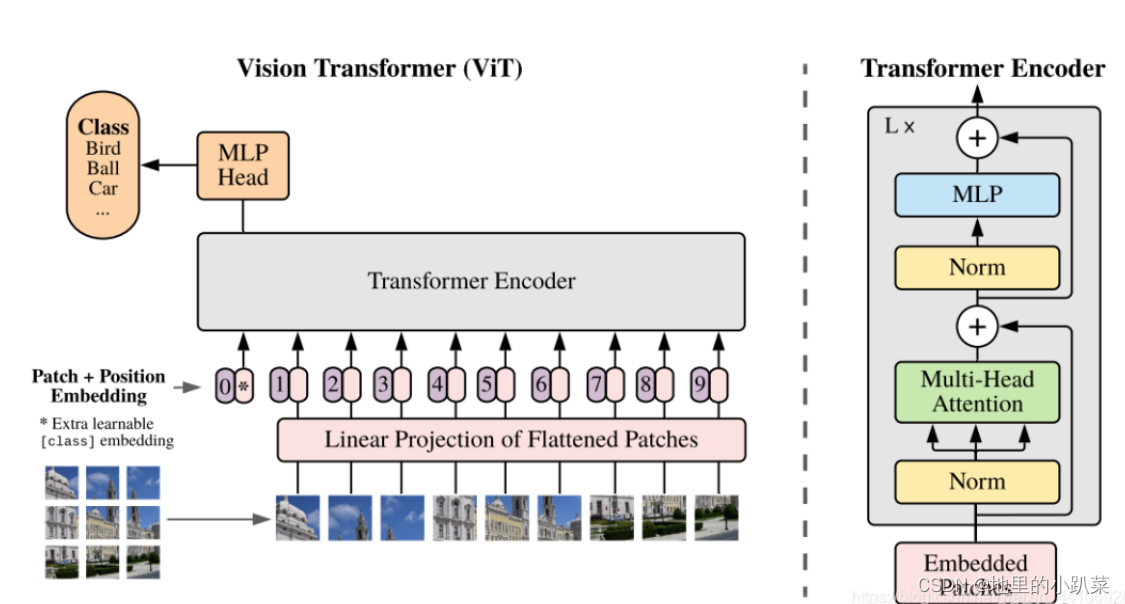
什么是transformer?
整个 transformer 的重点在 QKV 结构上。
以前的 CNN 试图通过卷积来表达不同位置数值之间的关系,学习卷积值也就是学习矩阵里的数值之间的特征,所以适合用在图像里面。因为图像就是一个个的像素点形成的矩阵。
RNN 试图通过加入反馈机制来理解一串数值前后的关系,所以适用于语言模型,因为这些数值之间有前后关系,像我们的句子里有先后逻辑。
而 transformer 里的 QKV 给你提供了一个新的思路:只研究问题和答案之间的关系。不去找前后,不去找相邻,就是单纯的问题(Query)和答案(Value),最多加了一个(Key)来辅助。
那为什么要用 QKV 呢?因为这是谷歌搜索等搜索引擎最开始的结构。一个搜索引擎的设计其实就是给一个问题然后找到对应答案。
任何一个问题(Query),会有很多的答案(Value),而之所以能找到这些答案,是因为这些答案里面包包含了有关于这个问题的关键信息(Key)
V=f(Q,K)
这是一个万能形式,任何问题的答案都是通过“问题本身+相关的关键信息”找到的,比如你去谷歌搜索“今天天气怎么样”,这个问题本身就是 Q,而你的语言是“中文”,你的位置是“北京”,你的时间是“今天”,这些就都是 K,那么找到的答案“下雨”就是 V。
一般来说肯定是通过方法找到 f( Q, K) 中的一些系数,就可以找到正确的 V 了。我们也可以把 V挪到公式右边,并且把他们存在的关系叫成 attention,那么就是:
attention = F(Q, K, V)
这就是整个 transformer 的最基础结构,有了这个万能结构,只需要学习 F里的各个参数,就可以回答你想要的问题。
那么,又为什么叫 transformer而不是简单的 attention 呢?
因为 transformer 它为了提高这个 F的 运算效率,做了一些规定,比如你的 attention 的输入输出维度需要一样,这样矩阵运算就可以加快。而且多个 attention 合在一起来算,也是为了加快运算速度和效率。
那整个 Transformer里的 encoded decoder 又是干嘛呢?
这个 QKV 结构是最基础的单元,为了适应不同的目标,把多个 QKV 的 attention 合在一起以后,它分了两个部分,一个用来学怎么 encode,一个用来学怎么 decode。这个就跟 GAN,对抗神经网络很像,基本就是还是为了找到数据高维空间下的一个空间分割平面。而这里为了前后关系,它把上一个运算出来的结果又给进去去计算下一个部分(decoder 部分),所以就可以放在语言任务上(因为语言有前后关系)。
对于像翻译这种任务,encoder 部分输入是第一种语言,而 decoder 部分是第二种语言,这样一来训练出来的模型就可以做翻译。
而 GPT 的全名是 Generative Pretrained Transformers,它用的是 self-attention 结构,也就是 encoder 部分是前半句(一个字,一个句子),decoder 部分是后半句(或者下一个字,或者下个句子,都行),就是自己学自己,不是两种不同语言,所以就是 self-attention。
当然这只是语言上的应用,像 ChatGPT,LLama 这种的。
因为 QKV 就是简单的“问题—答案”结构,这个可以应用在一切问题上,图片,语音,文字,或者相互关联相互变化,都可以。
所以现在如果我回过头来看的话,整个 transformers里面的重点就是它把基本的单元从原来神经元之间的连接结构变成了问答的(QKV)attention 结构。