Go 语言,作为一种高效、静态类型的编程语言,自其问世以来便以其并发处理能力和简洁的语法结构广受开发者欢迎。虽然 Go 不是传统意义上的面向对象语言,它却以独特的方式支持面向对象编程的核心概念,其中结构体扮演了非常关键的角色。
结构体在 Go 语言中是一种复合数据类型,允许我们将不同类型的数据聚合到一起。它不仅提高了数据管理的效率和逻辑清晰度,还是 Go 语言中实现面向对象编程思想如封装、组合等概念的基石。了解和掌握结构体的使用,对于深入理解 Go 语言的特性和编写高效、可维护的 Go 代码至关重要。
本文将带您全面深入地探索 Go 语言中结构体的各个方面,从基本定义、初始化和使用,到高级特性如结构体的组合、方法定义、内存对齐等,每一个细节都将一一展开。无论您是 Go 语言的新手,还是有一定经验的开发者,相信本文都能为您提供有价值的见解和帮助。让我们一起探索 Go 结构体的奥秘,揭开其背后的原理,优化我们的代码结构,提升编程效率。
版本声明
- Go 1.22.1
- gopkg.in/yaml.v3 v3.0.1
- os: m2max
全文概览
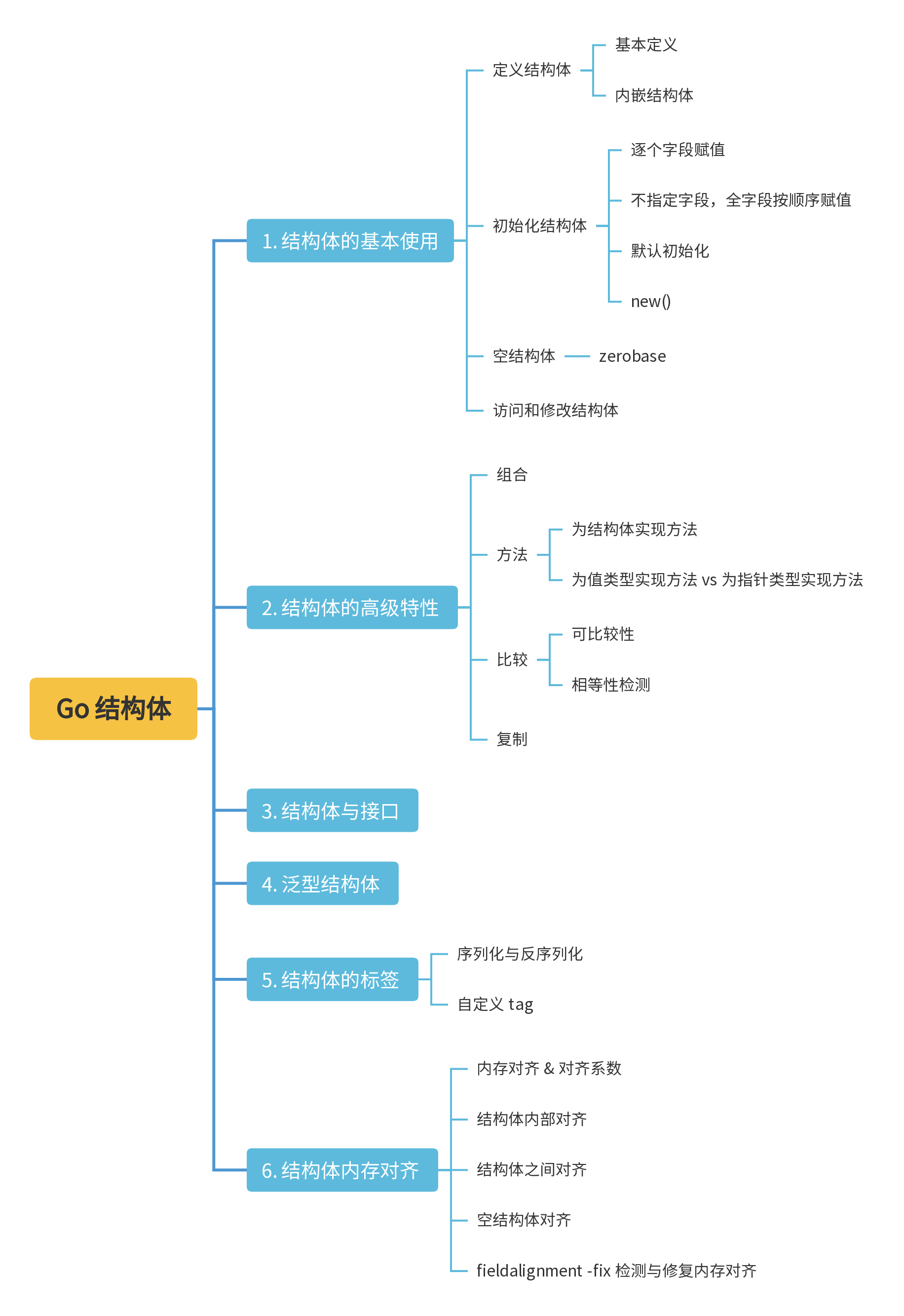
1. 结构体的基本使用
1.1 定义结构体
结构体类型的定义形式如下:
type T struct {
Field T1,
Field T2,
....
FieldN Tn,
}
比如:
type Person struct {
Name string
Age int
ExtraInfo map[string]interface{}
}
结构体内部,也可以内嵌匿名结构体,如:
type Person struct {
Name string
Age int
School struct {
Name string
Address string
Phone string
}
}
但是!注意,如果 Person 中包含了 Person 呢?
type Person struct {
person Person
}
这里会报错:不允许引用自身。
./main.go:5:6: invalid recursive type: Person refers to itself
这是因为 Go 语言在编译时需要知道每个类型的确切大小,以便正确地分配内存。但在这个定义中,因为 Person 包含自身,编译器无法确定 Person 的大小,因此会报错。
如果你需要在一个结构体中引用相同类型的数据,你应该使用指针。指针的大小是固定的,因此编译器可以确定结构体的大小。
type Person struct {
person *Person
}
1.2 初始化结构体
假设我们有以下结构体:
type Person struct {
Name string
Age int
ExtraInfo map[string]interface{}
}
可以有以下几种初始化:
// 逐个字段赋值,顺序不重要,也可以只赋值部分字段
person1 := Person{
Age: 18,
Name: "hedon",
ExtraInfo: make(map[string]interface{}),
}
fmt.Println(person1) // {hedon 18 map[]}
// 可以不指定字段,严格按照顺序
person2 := Person{"hedon2", 19, make(map[string]interface{})}
fmt.Println(person2) // {hedon2 19 map[]}
// 默认初始化,则结构体中的每个字段都会被默认赋予其对应类型的“零值”
var person3 Person
fmt.Println(person3) // { 0 map[]}
fmt.Println(person3.ExtraInfo == nil) // true
// 也可以使用 new() 或 & 来初始化并返回指针
person3 := new(Person)
fmt.Println(person3) // &{ 0 map[]}
1.3 空结构体
有一种特殊的结构体,它一个字段都没有,我们称之为“空结构体”:
type Empty struct{}
空结构体非常特殊,它不占据任何空间!你可以自己验证一下:
type Empty struct{}
func main() {
fmt.Println("the size of empty:", unsafe.Sizeof(Empty{})) // the size of empty: 0
}
而且,所有空结构体的地址都一样:
type Empty struct{}
type Empty1 struct{}
func main() {
e := Empty{}
e1 := Empty1{}
fmt.Printf("the address of empty: %p\n", &e) // the address of empty: 0x10460f520
fmt.Printf("the address of empty1: %p\n", &e1) // the address of empty1: 0x10460f520
}
这是因为 Go 语言为所有大小为 0 的变量都指向了同一个值:
// base address for all 0-byte allocations
var zerobase uintptr
好处就是减少了内存的浪费。典型的用法就是我们可以使用 map 来实现 Set,这样就只花费了存储键的空间,而值不占用任何空间。
type Set = map[string]struct{}
1.4 访问和修改结构体
- 结构体属性的可见性跟 Go 包的可见性规则一样:大写对包外可见,小写仅包内可见。
- 使用
.访问和修改结构体中的属性。 - Go 语言中只有“值传递”,所以如果你要将结构体示例传入一个 func 进行修改,则需要传入其引用。
type Person struct {
Name string
Age int
}
func main() {
p := Person{Name: "hedon", Age: 18}
UpdatePersonName(p)
fmt.Println("1:", p)
UpdatePersonNameWithRef(&p)
fmt.Println("2:", p)
}
func UpdatePersonName(p Person) {
p.Name = "hedon-1"
}
func UpdatePersonNameWithRef(p *Person) {
p.Name = "hedon-2"
}
输出:
1: {hedon 18}
2: {hedon-2 18}
2. 结构体的高级特性
2.1 结构体组合
在 Go 语言中,倡导的是“组合优于继承”的哲学,即倡导使用组合而不是继承来实现代码的复用。该理念鼓励开发者通过组合和接口来构建灵活、可维护的代码,而不是依赖于更严格、更易出错的继承关系。这种方式促进了代码的解耦,增强了代码的灵活性和可重用性,同时也使得代码更加清晰和易于理解。
在 Go 中,组合是通过将一个或多个类型(通常是结构体)嵌入到另一个结构体中来实现的。这使得嵌入的类型的方法被“提升”到包含它的结构体中,允许你调用这些方法就像它们是外部结构体的一部分一样。
type Engine struct {
Power int
}
func (e *Engine) Start() {
// 启动引擎的逻辑
}
type Car struct {
Engine // 通过组合的方式嵌入 Engine
}
// 现在 Car 可以直接调用 Start 方法
car := Car{Engine{Power: 100}}
car.Start() // 调用的是 Engine 的 Start 方法
2.2 结构体的方法
假设我们定义了一个结构体 Person:
type Person struct {
Name string
}
在 Go 中,你可以为结构体的值或指针实现特定的方法:
func(p Person) SetName(name string) string {
p.Name = name
}
func(p *Person) SetName(name string) string {
p.Name = name
}
这两者最核心的区别是:当你为结构体的指针类型定义方法时,该方法会在原始结构体实例上操作。这意味着方法内部对结构体的任何修改都会影响到原始结构体。
所以这两段代码的输出是不一样的:
func main() {
p := Person{Name: "hedon"}
p.SetName("new_name")
fmt.Println(p.Name) // name_name
}
func (p *Person) SetName(name string) {
p.Name = name
}
func main() {
p := Person{Name: "hedon"}
p.SetName("new_name")
fmt.Println(p.Name) // hedon
}
func (p Person) SetName(name string) {
p.Name = name
}
但是这里我想再补充两个小点。请先思考一下下面这两段代码是否可以编译通过?如果可以输出是什么?
func main() {
p := Person{Name: "hedon"}
p.SetName("new_name")
fmt.Println("person name after set:", p.Name)
pt := reflect.TypeOf(p)
fmt.Println("the number of person's method: ", pt.NumMethod())
p2 := &Person{}
pt = reflect.TypeOf(p2)
fmt.Println("the number of &person's method: ", pt.NumMethod())
}
func (p *Person) SetName(name string) {
p.Name = name
}
func main() {
p := Person{Name: "hedon"}
p.SetName("new_name")
fmt.Println("person name after set:", p.Name)
pt := reflect.TypeOf(p)
fmt.Println("the number of person's method: ", pt.NumMethod())
p2 := &Person{}
pt = reflect.TypeOf(p2)
fmt.Println("the number of &person's method: ", pt.NumMethod())
}
func (p Person) SetName(name string) {
p.Name = name
}
很明显这两段代码的唯一区别就是,第一段代码我们是为 *Person 实现了 SetName 方法,而第二段代码我们是为 Person 实现了 SetName 方法。两段代码我们都打印了调用 SetName 后 p.name 的值,以及利用方式分别获取 Person 和 *Person 实现的方法个数。
第一段代码的输出如下:
person name after set: new_name
the number of person's method: 0
the number of &person's method: 1
第二段代码的输出如下:
person name after set: hedon
the number of person's method: 1
the number of &person's method: 1
这里我们可以得出 2 个结论:
① 结构体的修改依赖于方法接收器的类型:
- 当方法的接收器为值类型(
Person)时,对结构体的修改不会影响原始结构体实例,因为方法作用于结构体的副本上。 - 当方法的接收器为指针类型(
*Person)时,对结构体的修改会影响原始结构体实例,因为方法作用于结构体的引用上。
② 方法集依赖于接收器的类型:
- 为值类型(
Person)实现的方法,既属于值类型也属于指针类型(*Person)的方法集。 - 为指针类型(
*Person)实现的方法,只属于指针类型的方法集。
对于 ②,我们可以通过 Plan9 汇编代码一探究竟。
我们为第一段代码执行以下命令:
go build -gcflags -S main.go
在输出的最上面,可以看到只有 main.(*Person).GetName。
# command-line-arguments
main.main STEXT size=128 args=0x0 locals=0x48 funcid=0x0 align=0x0
...
main.(*Person).GetName STEXT size=16 args=0x8 locals=0x0 funcid=0x0 align=0x0 leaf
...
我们再来为第二段代码执行相同的命令。可以在输出的最上面,看到不仅有 main.Person.GetName,还可以发现编译器自动帮我们生成了 main.(*Person).GetName。
# command-line-arguments
main.main STEXT size=480 args=0x0 locals=0xe8 funcid=0x0 align=0x0
...
main.Person.SetName STEXT size=16 args=0x28 locals=0x0 funcid=0x0 align=0x0 leaf
...
main.(*Person).SetName STEXT dupok size=128 args=0x18 locals=0x8 funcid=0x16 align=0x0
...
对于 ②,笔者其实有一个不太理解的地方,比如下面这段代码:
func main() {
p := &Person{Name: "hedon"}
p.SetName("new_name")
fmt.Println("person name after set:", p.Name) // hedon
}
func (p Person) SetName(name string) {
p.Name = name
}
这里 p 是引用类型,下面实现的是 Person.SetName,按照我们上面的结论,编译器会自动帮我们实现 (*Person).SetName。按照这种思路,输出 new_name 也是解释得通的。因为既然我们声明的是一个引用类型,那么 p 完全可以去调用自动生成的 (*Person).SetName。但是最终的结果还是输出 hedon,所以这里编译器自动帮我们将 p 进行解引用,然后调用了 Person.SetName。
这是比较困扰笔者的一个地方,欢迎评论区讨论~
可能编译器还是更希望对于开发者来说“所见即所得”,既然开发者实现的是 Person.SetName,那么对于开发者来说,应该就是希望不影响原始结构体的值,所以编译器还是选择遵循这种“意愿”,不乱操作。
2.3 结构体比较
Go 允许直接比较两个结构体实例,但有一定的限制:
- 可比较性:只有当结构体中的所有字段都是可比较的时,结构体才是可比较的。基本数据类型(如 int、string 等)是可比较的,但切片、映射、函数等类型不可比较。
- 相等性检测:当两个结构体的对应字段都相等时,这两个结构体被认为是相等的。可以使用
==和!=操作符来进行比较。
下面这段示例,p3==p4 返回了 true,这符合我们上面总结的结论。p1==p2 返回了 false,因为这其实不是结构体之间的比较了,这是指针的比较了。
p1 := &Person{Name: "hedon", Age: 18}
p2 := &Person{Name: "hedon", Age: 18}
fmt.Println(p1 == p2) // false
p3 := Person{Name: "hedon", Age: 18}
p4 := Person{Name: "hedon", Age: 18}
fmt.Println(p3 == p4) // true
结构体的比较只支持 == 和 !=,不支持 < 和 > 等其他运算符的比较。而 Go 语言又不支持比较符重载。所以如果你要比较两个结构体的大小,那么只能自行封装类型 compare 的函数。在这我们排序结构体数组或切片的时候,经常使用到,比如我们希望按 Age 字段从小到大排序:
sort.Slice(persons, func(i, j int) bool {
return persons[i].Age < persons[j].Age
})
2.4 结构体复制
在 Go 中,结构体也是值类型,这意味着当它们被赋值给新的变量或作为函数参数传递时,实际上是进行了一次深拷贝:
- 值复制:当将一个结构体赋值给一个新变量时,新变量会获得原始结构体的一个副本,它们在内存中占有不同的位置。
- 独立性:因为是深拷贝,所以原始结构体和副本结构体是完全独立的;修改其中一个不会影响另一个。
type Point struct {
X, Y int
}
original := Point{1, 2}
copy := original
copy.X = 3
fmt.Println(original) // {1, 2}
fmt.Println(copy) // {3, 2}
3. 结构体与接口
在 Go 语言中,如果一个类型实现了接口中所有的方法,则这个类型就实现了该接口。关于接口部分的知识点,比如接口定义、多态和断言等,本文就不赘述了。
在这里我主要想从另外一个角度继续来验证前面我们总结的:为值类型(Person)实现的方法,既属于值类型也属于指针类型(*Person)的方法集。
请看这段代码:
package main
import "fmt"
type Person interface {
GetName() string
}
type Man struct {
Name string
}
func (m Man) GetName() string {
return m.Name
}
func PrintPersonName(p Person) {
fmt.Println(p.GetName())
}
func main() {
m1 := Man{Name: "hedon1"}
PrintPersonName(m1)
m2 := &Man{Name: "hedon2"}
PrintPersonName(m2)
}
这段代码我们定义了 Person 接口,它只有一个方法 GetName。然后我们定义了一个结构体 Man,并为它的值类型实现了 Person 接口。通过我们上面的结论,这里 Man 和 *Man 其实都实现了 Person 接口,所以上面的代码是可以编译通过的。
如果改成为指针类型实现接口呢?你可以试一下~
func (m *Man) GetName() string {
return m.Name
}
4. 泛型结构体
Go 语言在其 1.18 版本中引入了泛型支持,这包括了对泛型结构体的支持。通过使用泛型,你可以创建更灵活和可重用的数据结构和函数。
type Container[T any] struct {
items []T
}
可以看到 Go 语言用 [] 来实现泛型,而不像其他语言一样用 <>,真是喜欢搞特殊啊 🤡,又丑又容易跟 map 和 slice 混淆。
5. 结构体的标签(Tag)
在结构体字段后面,我们可以用 `` 来指定标签,这允许我们对结构体定制化一些常用操作,最经典的就是序列化与反序列化。
5.1 序列化与反序列化
对于常见的数据结构,如 json、yaml、xml 或 toml,我们都可以通过在结构体中指定标签,然后使用对应解析库进行序列化和反序列化。比如:
package main
import (
"encoding/json"
"fmt"
)
type Person struct {
Name string `json:"name"`
Age int `json:"age"`
}
func main() {
p := Person{Name: "hedon", Age: 18}
bs, _ := json.Marshal(p) // 序列化
fmt.Println(string(bs)) // {"name":"hedon","age":18}
newP := Person{}
_ = json.Unmarshal(bs, &newP) // 反序列化
fmt.Println(newP) // {hedon 18}
}
在笔者的实践过程中,在结构体组合的场景下,不同数据格式的解析会有一些小差别,这在实战过程中你需要重点关注和验证。比如 json 和 yaml 就会有一些不同。
比如说我这里定义了下面 2 个结构体,其中 Person 组合了 School:
type Person struct {
Name string `json:"name" yaml:"name"`
Age int `json:"age" yaml:"age"`
School
}
type School struct {
SchoolName string `json:"school_name" yaml:"school_name"`
SchoolAddress string `json:"school_address" json:"school_address"`
}
它们都加上了 json 和 yaml 标签,对于 json 类型,你可以用标准库的 encoding/json 来进行序列化和反序列化,而 yaml 你可以使用第三方库:go-yaml。
先来看系列化结果:
func main() {
p := Person{Name: "hedon", Age: 18, School: School{SchoolName: "nb_school", SchoolAddress: "a_good_school_place"}}
bs, _ := json.Marshal(p)
fmt.Println("json:\n", string(bs))
bs, _ = yaml.Marshal(p)
fmt.Println("yaml:\n", string(bs))
}
输出如下:
json:
{"name":"hedon","age":18,"school_name":"nb_school","school_address":"a_good_school_place"}
yaml:
name: hedon
age: 18
school:
school_name: nb_school
school_address: a_good_school_place
通过观察你可以发现哈,在 json 中,组合的时候(没有给 School 加标签)直接将 School 平铺在 Person 中,所以在序列化的结果中,找不到 "school": {}。而在 yaml 中,并不是直接平铺的。
这个区别在你解析配置文件的时候尤其重要,如果不注意,那么可能会导致配置解析失败。
我准备了 4 个配置文件,分别是:
// person1.json
{
"name": "hedon_json",
"age": 18,
"school": {
"school_name": "nb_json_school",
"school_address": "a_good_place_in_json"
}
}
# person1.yaml
name: "hedon_yaml"
age: 18
school:
school_name: "nb_yaml_school"
school_address: "a_good_price_in_yaml"
// person2.json
{
"name": "hedon_json",
"age": 18,
"school_name": "nb_json_school",
"school_address": "a_good_place_in_json"
}
# person2.yaml
name: "hedon_yaml"
age: 18
school_name: "nb_yaml_school"
school_address: "a_good_price_in_yaml"
解析代码如下:
func main() {
filenames := []string{"person1.json", "person1.yaml", "person2.json", "person2.yaml"}
for i, fn := range filenames {
bs := readFileIntoBytes(fn)
p := Person{}
if i%2 == 0 {
_ = json.Unmarshal(bs, &p)
} else {
_ = yaml.Unmarshal(bs, &p)
}
fmt.Printf("%s -> %v\n", fn, p)
}
}
func readFileIntoBytes(filename string) []byte {
f, err := os.Open(filename)
if err != nil {
panic(err)
}
bs, _ := io.ReadAll(f)
return bs
}
输出:
person1.json -> {hedon_json 18 { }}
person1.yaml -> {hedon_yaml 18 {nb_yaml_school a_good_price_in_yaml}}
person2.json -> {hedon_json 18 {nb_json_school a_good_place_in_json}}
person2.yaml -> {hedon_yaml 18 { }}
如果给 School 字段加上 json tag 的话,结果又是不同:
type Person struct {
Name string `json:"name" yaml:"name"`
Age int `json:"age" yaml:"age"`
School `json:"school" yaml:"school"`
}
输出:
person1.json -> {hedon_json 18 {nb_json_school a_good_place_in_json}}
person1.yaml -> {hedon_yaml 18 {nb_yaml_school a_good_price_in_yaml}}
person2.json -> {hedon_json 18 { }}
person2.yaml -> {hedon_yaml 18 { }}
可以看到受影响的只有 json。
到这里我们可以总结:在组合场景下,如果不明确指定 tag,yaml 解析期望字段是嵌套的,而 json 解析期望字段是平铺的。
5.2 自定义 Tag
在 Go 中,你可以为结构体字段定义任意的标签。这些标签在编译时会被存储,并且可以在运行时通过反射(reflection)来访问。
假设我们定义一个名为 check 的标签,它用于我们对结构体字段的检查,假设我们这个标签支持以下功能:
check:"strnoempty": 字符串不可以为空。
假如加入 check 标签的 Person 结构体如下:
type Person struct {
Name string `check:"strnoempty"`
}
我们来为 check 实现解析函数:
func CheckPerson(p Person) error {
pt := reflect.TypeOf(p)
pv := reflect.ValueOf(p)
for i := 0; i < pt.NumField(); i++ {
field := pt.Field(i)
tagValue := field.Tag.Get("check")
if tagValue == "" {
continue
}
if field.Type.Kind() == reflect.String && tagValue == "strnoempty" {
if err := checkStrNoEmpty(field.Name, pv.Field(i).Interface()); err != nil {
return err
}
}
}
return nil
}
func checkStrNoEmpty(fieldName string, v any) error {
s, ok := v.(string)
if !ok {
return fmt.Errorf("%v is not string", v)
}
if s == "" {
return fmt.Errorf("[check] %s should not be empty", fieldName)
}
return nil
}
测试如下:
func main() {
p1 := Person{}
p2 := Person{Name: "hedon"}
fmt.Println(CheckPerson(p1)) // [check] Name should not be empty
fmt.Println(CheckPerson(p2)) // <nil>
}
6. 结构体内存对齐
在本小节中,我们将探讨 Go 语言结构体的内存结构和对齐策略。
6.1 问题引出
思考下面这段代码的输出:
type S1 struct {
num2 int8
num1 int16
flag bool
}
type S2 struct {
num1 int8
flag bool
num2 int16
}
func main() {
fmt.Println(unsafe.Sizeof(S1{}))
fmt.Println(unsafe.Sizeof(S2{}))
}
为什么仅是字段顺序不同,S1{} 和 S2{} 的大小就不一样了?
我们可以写个简单的程序来输出 S1 和 S2 的内存结构:
func main() {
s1 := S1{}
s2 := S2{}
fmt.Print("s1: ")
printMemory(s1)
fmt.Print("s2: ")
printMemory(s2)
}
func printMemory(a any) {
t := reflect.TypeOf(a)
mem := make([]int, int(t.Size()))
for i := 0; i < t.NumField(); i++ {
field := t.Field(i)
offset := int(field.Offset)
size := int(field.Type.Size())
for j := 0; j < size; j++ {
mem[j+offset] = i + 1
}
}
fmt.Println(mem)
}
输出:
s1: [1 0 2 2 3 0]
s2: [1 2 3 3]
其中 1、2、3 分别替代结构体中的第 1/2/3 个字段所占用的内存。这里可以看到 s1 的长度是 6 字节,而 s2 是 4 字节。这里 s1 比 s2 多出的 2 个字节就是这两个填充的 0。这而 2 个字节的填充,就是为了内存对齐。
6.2 内存对齐
如上分析,s1 的内存结构如下:

如果没有内存对齐呢?s1 的结构可能如下:
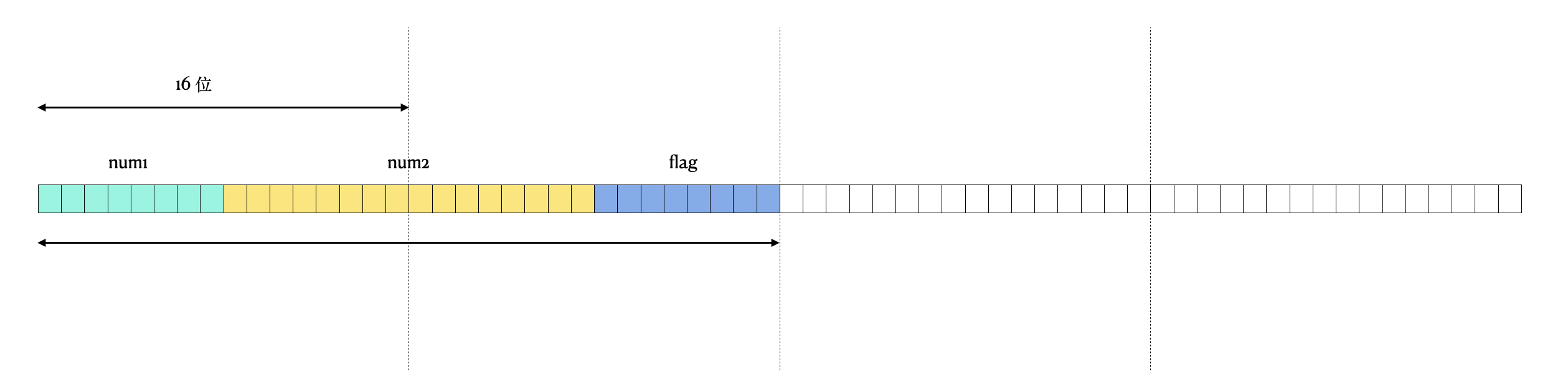
如果是 16 位系统的话,那么没有内存对齐的情况下,要访问 s1.num2 字段,就需要跨过 2 个系统字长的内存,效率就低了。具体来说,内存对齐是计算机内存分配的一种优化方式,用于确保数据结构的存储按照特定的字节边界对齐。这种对齐是为了提高计算机处理数据的效率。
6.3 对齐系数
- 对齐系数:变量的内存地址必须被对齐系数整除。
unsafe.Alignof(): 可以查看值在内存中的对齐系数。
6.4 基本类型对齐
fmt.Printf("bool size: %d, align: %d\n", unsafe.Sizeof(bool(true)), unsafe.Alignof(bool(true)))
fmt.Printf("byte size: %d, align: %d\n", unsafe.Sizeof(byte(0)), unsafe.Alignof(byte(0)))
fmt.Printf("int8 size: %d, align: %d\n", unsafe.Sizeof(int8(0)), unsafe.Alignof(int8(0)))
fmt.Printf("int16 size: %d, align: %d\n", unsafe.Sizeof(int16(0)), unsafe.Alignof(int16(0)))
fmt.Printf("int32 size: %d, align: %d\n", unsafe.Sizeof(int32(0)), unsafe.Alignof(int32(0)))
fmt.Printf("int64 size: %d, align: %d\n", unsafe.Sizeof(int64(0)), unsafe.Alignof(int64(0)))
输出:
bool size: 1, align: 1
byte size: 1, align: 1
int8 size: 1, align: 1
int16 size: 2, align: 2
int32 size: 4, align: 4
int64 size: 8, align: 8
结论:基本类型的对齐系数跟它的长度一致。

6.5 结构体内部对齐
结构体内存对齐分为内部对齐和结构体之间对齐。
我们先来看结构体内部对齐:
- 指的是结构体内部成员的相对位置(偏移量);
- 每个成员的偏移量是 自身大小 和 对齐系数 的较小值的倍数
type Demo struct {
a bool
b string
c int16
}
假如我们定义了上面的结构体 Demo,如果在 64 位系统上(字长为 8 字节)通过上面的规则,可以判断出:(单位为字节)
- a: size=1, align=1
- b: size=16, align=8
- c: size=2, align=2

当然我们也可以通过程序输出来验证:
type Demo struct {
a bool // size=1, align=1
b string // size=16, align=8
c int16 // size=2, align=2
}
func main() {
d := Demo{}
fmt.Printf("a: size=%d, align=%d\n", unsafe.Sizeof(d.a), unsafe.Alignof(d.a))
fmt.Printf("b: size=%d, align=%d\n", unsafe.Sizeof(d.b), unsafe.Alignof(d.b))
fmt.Printf("c: size=%d, align=%d\n", unsafe.Sizeof(d.c), unsafe.Alignof(d.c))
printMemory(d)
}
func printMemory(a any) {
t := reflect.TypeOf(a)
mem := make([]int, int(t.Size()))
for i := 0; i < t.NumField(); i++ {
field := t.Field(i)
offset := int(field.Offset)
size := int(field.Type.Size())
for j := 0; j < size; j++ {
mem[j+offset] = i + 1
}
}
fmt.Println(mem)
}
输出:
a: size=1, align=1
b: size=16, align=8
c: size=2, align=2
[1 0 0 0 0 0 0 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 3 3 0 0 0 0 0 0]
6.6 结构体长度填充
上面 Demo 结构体最后还填了 6 个字节的 0,这就是结构体长度填充:
- 结构体通过填充长度,来对齐系统字长。
- 结构体长度是 最大成员长度 和 系统字长 较小值的整数倍。
我的系统环境是 m2max,系统字长是 8 字节,Demo 最大成员长度是 b string,即 16 个字节,所以 Demo 的长度应该是 8 的倍数,所以最后填充了 6 个字节的 0。
6.7 结构体之间对齐
- 结构体之间对齐,是为了确定结构体的第一个成员变量的内存地址,以让后面的成员地址都合法。
- 结构体的对齐系数是 其成员的最大对齐系数;
6.8 空结构体对齐
前面我们专门讨论了空结构体 struct{},它们的内存地址统一指向 zerobase,而且内存长度为 0。这也导致了它的内存对齐规则,有一些不同。具体可以分为以下 4 个情况。
6.8.1 空结构体单独存在
空结构体单独存在时,其内存地址为 zerobase,不额外分配内存。
6.8.2 空结构体在结构体最前
空结构体是结构体第一个字段时,它的地址跟结构体本身及结构体第 2 个字段一样,不占据内存空间。
type TestEmpty struct {
empty struct{}
a bool
b string
}
func main() {
te := TestEmpty{}
fmt.Printf("address of te: %p\n", &te)
fmt.Printf("address of te.empty: %p\n", &(te.empty))
fmt.Printf("address of te.a: %p\n", &(te.a))
fmt.Printf("empty: size=%d, align=%d\n", unsafe.Sizeof(te.empty), unsafe.Alignof(te.empty))
fmt.Printf("a: size=%d, align=%d\n", unsafe.Sizeof(te.a), unsafe.Alignof(te.a))
fmt.Printf("b: size=%d, align=%d\n", unsafe.Sizeof(te.b), unsafe.Alignof(te.b))
printMemory(te)
}
输出:
address of te: 0x140000ba000
address of te.empty: 0x140000ba000
address of te.a: 0x140000ba000
empty: size=0, align=1
a: size=1, align=1
b: size=16, align=8
[2 0 0 0 0 0 0 0 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3]
6.8.3 空结构体在结构体中间
空结构体出现在结构体中时,地址跟随前一个变量。
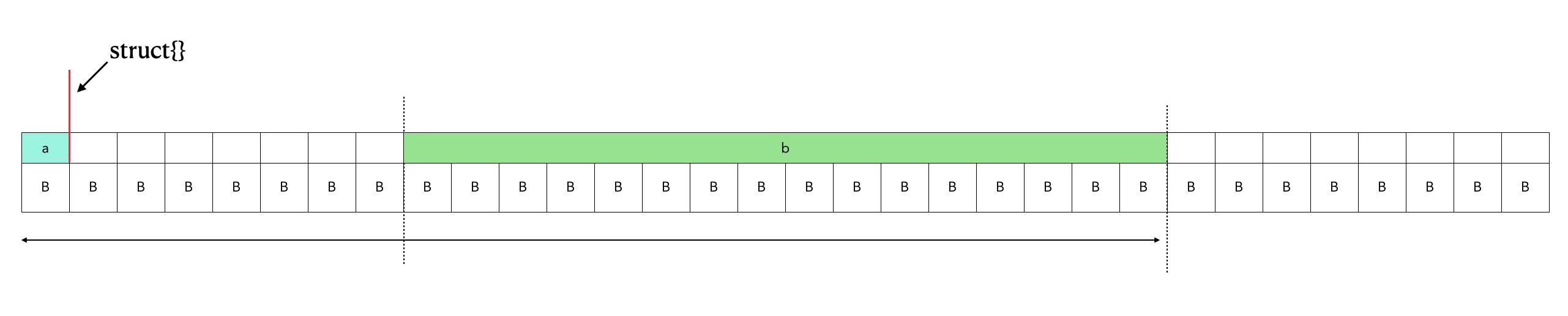
type TestEmpty struct {
a bool
empty struct{}
b string
}
func main() {
te := TestEmpty{}
fmt.Printf("address of te: %p\n", &te)
fmt.Printf("address of te.a: %p\n", &(te.a))
fmt.Printf("address of te.empty: %p\n", &(te.empty))
fmt.Printf("a: size=%d, align=%d\n", unsafe.Sizeof(te.a), unsafe.Alignof(te.a))
fmt.Printf("empty: size=%d, align=%d\n", unsafe.Sizeof(te.empty), unsafe.Alignof(te.empty))
fmt.Printf("b: size=%d, align=%d\n", unsafe.Sizeof(te.b), unsafe.Alignof(te.b))
printMemory(te)
}
输出:
address of te: 0x14000128000
address of te.a: 0x14000128000
address of te.empty: 0x14000128001
a: size=1, align=1
empty: size=0, align=1
b: size=16, align=8
[1 0 0 0 0 0 0 0 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3 3]
6.8.4 空结构体在结构体最后
空结构体出现在结构体最后,如果开启了一个新的系统字长,则需要补零,防止与其他结构体混用地址。

type TestEmpty struct {
a bool
b string
empty struct{}
}
func main() {
te := TestEmpty{}
fmt.Printf("address of te: %p\n", &te)
fmt.Printf("address of te.a: %p\n", &(te.a))
fmt.Printf("address of te.empty: %p\n", &(te.empty))
fmt.Printf("a: size=%d, align=%d\n", unsafe.Sizeof(te.a), unsafe.Alignof(te.a))
fmt.Printf("b: size=%d, align=%d\n", unsafe.Sizeof(te.b), unsafe.Alignof(te.b))
fmt.Printf("empty: size=%d, align=%d\n", unsafe.Sizeof(te.empty), unsafe.Alignof(te.empty))
printMemory(te)
}
输出:
address of te: 0x1400006a020
address of te.a: 0x1400006a020
address of te.empty: 0x1400006a038
a: size=1, align=1
b: size=16, align=8
empty: size=0, align=1
[1 0 0 0 0 0 0 0 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 0 0 0 0 0 0 0 0]
6.9 使用 fieldalignment -fix 工具优化结构体内存对齐
还记得我们最开始提出的问题吗?
type S1 struct {
num2 int8
num1 int16
flag bool
}
type S2 struct {
num1 int8
flag bool
num2 int16
}
func main() {
fmt.Println(unsafe.Sizeof(S1{}))
fmt.Println(unsafe.Sizeof(S2{}))
}
S1 和 S2 提供的程序功能是一样的,但是 S1 却比 S2 花费了更多的内存空间。所以有时候我们可以通过仅仅调整结构体内部字段的顺序就减少不少的内存空间消耗。在这个时候 fieldalignment 可以帮助我们自动检测并优化。
你可以运行下面命令安装 fieldalignment 命令:
go install golang.org/x/tools/go/analysis/passes/fieldalignment/cmd/fieldalignment@latest
然后在项目根目录下运行下面命令,对我们的代码进行检查:
go vet -vettool=$(which fieldalignment) ./...
这里会输出:
./main.go:9:9: struct of size 6 could be 4
这个时候可以执行 fieldalignment -fix 目录|文件 ,它会自动帮我们的代码进行修复,但是强烈建议你在运行之前,备份你的代码,因为注释会被删除!
fieldalignment -fix ./...
输出:
/Users/hedon/GolandProjects/learn-go-struct/main.go:9:9: struct of size 6 could be 4
这个时候 S1 已经被优化好了:
type S1 struct {
num1 int16
num2 int8
flag bool
}