介绍
构建系统长期以来一直是计算机编程中的标准工具。
标准 make 构建系统由其作者获得 ACM 软件系统奖,于 1976 年首次开发。它不仅允许您声明一个输出文件依赖于一个(或多个)输入文件,而且可以递归地执行此操作。例如,一个程序可能依赖于一个又依赖于相应源代码的对象文件:
prog: main.o
cc -o prog main.o
main.o: main.c
cc -C -o main.o main.c
如果在下一次调用make时发现,源代码文件main.c的修改时间比 main.o 更近,那么它不仅会重新构建 main.o 对象文件,还会重新构建 prog 本身。
构建系统是分配给本科计算机科学学生的常见学期项目,不仅因为构建系统在几乎所有软件项目中都有用,而且因为其构建涉及基本数据结构和涉及有向图的算法(本章将在更多细节上讨论)。
几十年来对构建系统的使用和实践,人们可能会期望它们已经变得完全通用且能够满足最奢华的需求。但事实上,在构建制品之间的一种常见相互作用——动态交叉引用的问题——由于大多数构建系统处理得很差,以至于在本章中,我们不仅要重温解决 make 问题所使用的经典解决方案和数据结构,而且还要将那个解决方案显著扩展到一个要求远远更高的领域。
交叉引用上也有该问题。交叉引用往往出现在文本文档、文档和印刷书籍中!
问题: 构建文件系统
重建格式化文档的系统似乎总是做得太多或太少。他们在回应小修改时做了太多额外工作,让您等待与之无关的章节重新解析和重新格式化。但他们也可能重建得太少,导致最终产品不一致。
考虑一下 Sphinx,这是一个用于 Python 官方语言文档以及 Python 社区中许多其他项目的文档构建工具。Sphinx 项目的 index.rst 通常会包括一个目录:
Table of Contents
=================
.. toctree::
install.rst
tutorial.rst
api.rst
这个章节文件名列表告诉 Sphinx 在构建 index.html时包含到每个三个命名章节的链接。它也将包含每个章节内的任何部分的链接。从上面的标题和 toctree 命令产生的文本去掉其标记后可能是:
Table of Contents
• Installation
• Newcomers Tutorial
• Hello, World
• Adding Logging
• API Reference
• Handy Functions
• Obscure Classes
这个目录涵盖了来自四个不同文件的信息。虽然它的基本顺序和结构来自 index.rst ,但每个章节和部分的实际标题都来自三个章节源文件。
如果您稍后重新考虑教程的章节标题——毕竟,“newcomer”这个词听起来很古老,好像您的用户是刚到了先驱州怀俄明的移民——那么您可以编辑 tutorial.rst 的第一行,写点更好的内容:
-Newcomers Tutorial
+Beginners Tutorial
==================
Welcome to the tutorial!
This text will take you through the basics of...
当你准备重建时,Sphinx 将会做正确的事情!它会重新构建教程章节本身和索引。(将输出导入 cat ,让 Sphinx 在每个重建的文件上分别显示,而不是使用简单的回车键重复覆盖一个单行,以显示这些进度更新。)
$ make html | cat
writing output... [ 50%] index
writing output... [100%] tutorial
因为 Sphinx 选择重建这两个文档,所以 tutorial.html 现在顶部显示新标题,输出 index.html 将在目录中显示更新的章节标题。Sphinx 已经重建了所有内容,使输出保持一致。
如果您对 tutorial.rst 的编辑改动很小,那该怎么办?
Beginners Tutorial
==================
-Welcome to the tutorial!
+Welcome to our project tutorial!
This text will take you through the basics of...
在这种情况下,不需要重建 index.html ,因为段落内的这个小修改不会改变目录中的任何信息。但事实证明,Sphinx 并不像最初看起来那样聪明!尽管生成的内容将完全相同,但它还是会继续执行重建 index.html 的多余工作。
writing output... [ 50%] index
writing output... [100%] tutorial
您可以在 index.html 的“之前”和“之后”版本上运行 diff ,以确认您的小编辑对首页没有产生任何影响——但 Sphinx 仍然让您在重新构建时等待。
您可能甚至都没有注意到那些容易编译的小文件的额外重建工作。但当您频繁对长篇、复杂或涉及生成图表或动画等多媒体的文件进行微调和编辑时,工作流程的延迟就可能显得重要。尽管 Sphinx 至少尽量不会在您进行单个更改时重建每个章节 — 比方说,它没有重新构建 install.html 或 api.html 以响应您的 tutorial.rst 编辑 — 但它确实做得比必要更多。
但事实证明, Sphinx 做得更糟糕: 有时会做得太少,导致输出不一致,容易被用户注意到。
要看到最简单的故障之一,首先在 API 文档的顶部添加一个交叉引用
API Reference
=============
+Before reading this, try reading our :doc:`tutorial`!
+
The sections below list every function
and every single class and method offered...
凭恪守惯例,Sphinx 将会认真重建该 API 参考文档以及您项目的主页 index.html
writing output... [ 50%] api
writing output... [100%] index
在 api.html 的输出文件中,您可以确认 Sphinx 已经将教程章节的标题包含在交叉引用的锚点标签中:
<p>Before reading this, try reading our
<a class="reference internal" href="tutorial.html">
<em>Beginners Tutorial</em>
</a>!</p>
如果您现在对 tutorial.rst 文件顶部的标题进行另一个编辑怎么办?您将使三个输出文件失效:
- tutorial.html 顶端的标题现在已经过时,所以需要重新构建文件。
- index.html 中的目录仍然具有旧标题,因此需要重建该文档。
- 第 api.html 段落中嵌入的交叉引用仍然具有旧的章标题,并且需要重新构建。
Sphinx做了什么?
writing output... [ 50%] index
writing output... [100%] tutorial
糟糕。只重新生成了两个文件,而不是三个。Sphinx 未能正确重新生成您的文档。如果您现在将 HTML 推送到网络上,用户将在 api.html 顶部的交叉引用中看到旧标题,但一旦链接将他们带到 tutorial.html 本身,就会看到不同的标题 - 新标题。这对于 Sphinx 支持的许多种类的交叉引用都可能发生:章节标题、部分标题、段落、类、方法和函数。
构建系统和一致性
由于这个问题是古老和普遍的,因此它的解决方案也有同样悠久的历史:
$ rm -r _build/
$ make html
如果您删除所有输出,您将确保进行完整重建! 一些项目甚至将 rm -r 别名更改为 clean ,因此只需快速 make clean 即可擦除一切。
通过删除每个中间或输出资产的每一份副本,一个庞大的 rm -r 可以强制重新开始构建,没有任何缓存 — 没有可能导致过时产品的早期状态记忆。但是我们能开发出更好的方法吗?
如果你的构建系统是一个持久的过程,当它从一个文档的源代码传递到另一个文档的文本时,它会注意到每个章节标题、每个章节标题和每个交叉引用的短语,那会怎么样?它关于在更改单个源文件后是否重建其他文档的决定可能是精确的,而不仅仅是猜测,并且是正确的,而不是使输出处于不一致的状态。结果将是一个类似于旧的静态 make 工具的系统,但它在构建文件时会学习文件之间的依赖关系——在添加、更新和删除交叉引用时动态添加和删除依赖关系。
在接下来的章节中,我们将用 Python 构建一个名为 Contingent 的工具。Contingent 保证在存在动态依赖关系时的正确性,同时执行尽可能少的重建步骤。虽然它可以应用于任何问题域,但我们将针对上述问题的一个小版本运行它。
Contingent
链接任务构建图
任何构建系统都需要一种链接输入和输出的方法。例如,我们上面讨论的三个标记文本都会生成相应的 HTML 输出文件。表达这些关系的最自然方式是作为方框和箭头的集合——或者用数学术语来说,是节点和边——形成一个图。
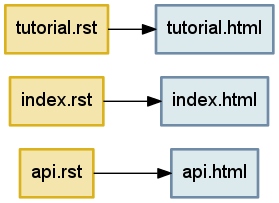
我们该如何在Python中表示图这种数据结构?
(当然,我们有一些库可以实现,但我们先考虑内置的数据结构)
尝试使用元组、列表、集合、字典,你会发现字典是最合适用来表示图的。
我们使用字典来表示节点的边。
一个表示传出边tutorial.rst → tutorial.html ,一个表示传入边tutorial.html ← tutorial.rst 。
incoming = {
'tutorial.html': {'tutorial.rst'},
'index.html': {'index.rst'},
'api.html': {'api.rst'},
}
outgoing = {
'tutorial.rst': {'tutorial.html'},
'index.rst': {'index.html'},
'api.rst': {'api.html'},
}
正确使用类
你可能对上面没有任何关于类的讨论感到惊讶,毕竟,类是许多编程语言流行的常见机制,也是经常被讨论的话题。但事实上,类通常和数据结构设计问题“正交“,类没有替代数据建模范式,而是重复已有的数据结构。
- 类的实例通过字典是实现
- 类实例的使用方式类似可变元组
当然,类提供了更好的接口,你可以用graph.incoming 而不是 graph["incoming"]。
因此,类的真正价值不在于它们改变了数据设计的科学。类的价值在于,它们可以让你隐藏你的数据设计,不让程序的其余部分看到!
设计一个类,我们可以减少需要记住的细节,只记住一组接口。
>>> from contingent import graphlib
>>> g = graphlib.Graph()
>>> g.add_edge('index.rst', 'index.html')
>>> g.add_edge('tutorial.rst', 'tutorial.html')
>>> g.add_edge('api.rst', 'api.html')
细心的读者会注意到,我们在图中添加了边,而没有显式创建“节点”和“边”对象,而且这些早期示例中的节点本身只是字符串。来自其他语言和传统,人们可能希望看到系统中所有内容的用户定义类和接口:
Graph g = new ConcreteGraph();
Node indexRstNode = new StringNode("index.rst");
Node indexHtmlNode = new StringNode("index.html");
Edge indexEdge = new DirectedEdge(indexRstNode, indexHtmlNode);
g.addEdge(indexEdge);
Python 语言和社区明确而有意地强调使用简单、通用的数据结构来解决问题,而不是为我们想要解决的问题的每个微小细节创建自定义类。这是“Pythonic”解决方案概念的一个方面:Pythonic 解决方案试图最大限度地减少语法开销,并利用 Python 强大的内置工具和广泛的标准库。
考虑到这些因素,让我们回到 Graph 类,检查它的设计和实现,看看数据结构和类接口之间的相互作用。在构造新 Graph 实例时,已经构建了一对字典来使用我们在上一节中概述的逻辑来存储边缘:
class Graph:
"""A directed graph of the relationships among build tasks."""
def __init__(self):
self._inputs_of = defaultdict(set)
self._consequences_of = defaultdict(set)
使用defaultdict方便处理缺少的键。
让我们来研究一下 add_edge 的实现,我们之前用它来构建图 4.1 的图。
def add_edge(self, input_task, consequence_task):
"""Add an edge: `consequence_task` uses the output of `input_task`."""
self._consequences_of[input_task].add(consequence_task)
self._inputs_of[consequence_task].add(input_task)
该方法隐藏了这样一个事实,即每个新边都需要两个而不是一个存储步骤,以便我们在两个方向上访问它。
还应该有一种简单的方法来访问每个边,而无需学习如何遍历我们的数据结构:
def edges(self):
"""Return all edges as ``(input_task, consequence_task)`` tuples."""
return [(a, b) for a in self.sorted(self._consequences_of)
for b in self.sorted(self._consequences_of[a])]
Graph.sorted() 方法尝试按自然排序顺序(如字母顺序)对节点进行排序,以便为用户提供稳定的输出顺序。
>>> from pprint import pprint
>>> pprint(g.edges())
[('api.rst', 'api.html'),
('index.rst', 'index.html'),
('tutorial.rst', 'tutorial.html')]
由于我们现在有一个真实的实时 Python 对象,而不仅仅是一个图,我们可以问它有趣的问题!例如,当 Contingent 从源文件构建博客时,当内容 api.rst 发生变化时,它需要知道诸如“什么取决于 api.rst ?
>>> g.immediate_consequences_of('api.rst')
['api.html']
这个 Graph 告诉构建系统,当api.rst变化时 , api.html已经过时了,必须重建。
index.html呢?
>>> g.immediate_consequences_of('index.html')
[]
返回了一个空列表,表示 index.html 该列表位于图的右边缘,因此如果它发生更改,则无需进一步重建。这个查询可以非常简单地表达出来,这要归功于已经为我们的数据进行布局的工作:
def immediate_consequences_of(self, task):
"""Return the tasks that use `task` as an input."""
return self.sorted(self._consequences_of[task])
>>> from contingent.rendering import as_graphviz
>>> open('figure1.dot', 'w').write(as_graphviz(g)) and None
图 4.1 忽略了我们在本章开头部分发现的最重要的关系之一:文档标题在目录中的显示方式。让我们填写这个细节。我们将为每个标题字符串创建一个节点,该节点需要通过解析输入文件来生成,然后传递给我们的其他例程之一:
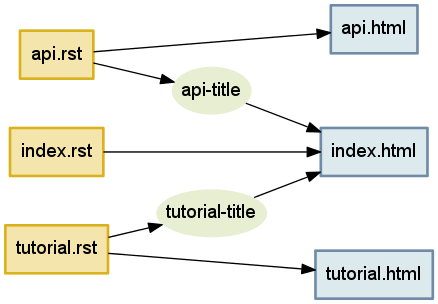
学习联系
现在,我们有一种方法可以让 Contingent 跟踪任务以及它们之间的关系。然而,如果我们更仔细地观察图 4.2,我们会发现它实际上有点模糊不清:如何从 api.rst得到 api.html ?我们怎么知道 index.html 需要教程中的标题?如何解决这种依赖关系?
当我们手工构建结果图时,我们对这些想法的直观概念很有帮助,但不幸的是,计算机并不是非常直观,因此我们需要更精确地了解我们想要什么。
从源生成输出需要哪些步骤?如何定义和执行这些步骤?系统如何知道它们之间的联系?
在 Contingent 中,构建任务被建模为函数(及参数)。函数定义特定项目了解如何执行的操作,参数提供了细节:应该阅读哪个源文档,需要哪个博客标题。当它们运行时,这些函数可能会依次调用其他任务函数,传递它们需要答案的任何参数。
为了了解它是如何工作的,我们现在实际上将实现本章开头描述的文档构建器。为了防止自己陷入细节的泥潭,在本图中,我们将使用简化的输入和输出文档格式。我们的输入文件将包含第一行的标题,其余文本构成正文。交叉引用将只是用反引号括起来的源文件名,在输出时,这些文件名将替换为输出中相应文档的标题。
以下是我们的示例 index.txt 、 api.txt 和 tutorial.txt 的内容,说明了标题、文档正文和来自我们小文档格式的交叉引用:
>>> index = """
... Table of Contents
... -----------------
... * `tutorial.txt`
... * `api.txt`
... """
>>> tutorial = """
... Beginners Tutorial
... ------------------
... Welcome to the tutorial!
... We hope you enjoy it.
... """
>>> api = """
... API Reference
... -------------
... You might want to read
... the `tutorial.txt` first.
... """
现在我们有一些源文件可用,但是怎么构建出HTML文件呢?
在实际系统中,将源代码转换为标记涉及几个步骤:从磁盘读取原始文本,将文本解析为方便的内部表示形式,处理作者可能指定的任何指令,解析交叉引用或其他外部依赖关系(例如包含文件), 并应用一个或多个视图转换以将内部表示转换为其输出形式。
Contingent 通过将任务分组到一个 Project 中来管理任务。Project 作为构建系统的管理者,它将自己注入构建过程中,每次一个任务与另一个任务交谈都会被记录,以构建所有任务之间的关系图。
>>> from contingent.projectlib import Project, Task
>>> project = Project()
>>> task = project.task
我们 read()的任务将假装从磁盘读取文件。由于我们已经在变量中定义了文本,因此它需要做的就是从文件名转换为相应的文本。
>>> filesystem = {'index.txt': index,
... 'tutorial.txt': tutorial,
... 'api.txt': api}
...
>>> @task
... def read(filename):
... return filesystem[filename]
parse() 任务根据文档格式的规范解释文件内容的原始文本。我们的格式非常简单:文档的标题出现在第一行,其余内容被视为文档的正文。
>>> @task
... def parse(filename):
... lines = read(filename).strip().splitlines()
... title = lines[0]
... body = '\n'.join(lines[2:])
... return title, body
因为格式太简单了,所以解析器有点傻,但它说明了解析器需要执行的解释性职责。(一般来说,解析是一个非常有趣的主题,许多书籍都部分或全部地写了关于它。)在像 Sphinx 这样的系统中,解析器必须理解系统定义的许多标记标记、指令和命令,将输入文本转换为系统其余部分可以使用的内容。
注意 parse() 和 read() 之间的 连接点 — 解析的第一个任务是传递文件名到read,read将查找并返回该文件的内容。
给定源文件名,title_of() 将返回文档的标题:
>>> @task
... def title_of(filename):
... title, body = parse(filename)
... return title
此任务很好地说明了文档处理系统各部分之间的责任分离。title_of() 函数直接从文档的内存表示(在本例中为元组)工作,而不是为了找到标题而自行重新解析整个文档。根据系统规范的约定,parse() 函数单独生成内存中的表示,而博客构建器的其余部分则处理函数,例如 title_of() 简单地使用其输出。
如果你来自正统的面向对象传统,这种面向函数的设计可能看起来有点奇怪。在 OO 解决方案中, parse() 将返回某种具有 title_of() 方法或属性的 Document 对象。事实上,Sphinx正是以这种方式工作的:它的 Parser 子系统生成一个“Docutils 文档树”对象,供系统的其他部分使用。
最后一项任务, render() ,将文档的内存表示转换为输出表单。实际上,它是 parse() 的逆过程。 parse() 获取符合规范的输入文档并将其转换为内存中的表示, render() 获取内存中的表示并生成符合某些规范的输出文档。
>>> import re
>>>
>>> LINK = '<a href="{}">{}</a>'
>>> PAGE = '<h1>{}</h1>\n<p>\n{}\n<p>'
>>>
>>> def make_link(match):
... filename = match.group(1)
... return LINK.format(filename, title_of(filename))
...
>>> @task
... def render(filename):
... title, body = parse(filename)
... body = re.sub(r'`([^`]+)`', make_link, body)
... return PAGE.format(title, body)
下面是一个示例,它将调用上述逻辑的每个阶段 - 渲染 tutorial.txt 以生成其输出:
>>> print(render('tutorial.txt'))
<h1>Beginners Tutorial</h1>
<p>
Welcome to the tutorial!
We hope you enjoy it.
<p>
图 4.3 说明了任务图,该图以传递方式连接生成输出所需的所有任务,从读取输入文件到解析和转换文档,再到呈现文档:

图 4.3 不是为本章手绘的,而是直接从 Contingent生成的!对于 Project 对象来说,构建此图是可能的,因为它维护自己的调用堆栈,类似于 Python 维护的实时执行帧堆栈,以记住当前函数返回时要继续运行的函数。
注:程序会产生一个.dot文本文件,可以用graphvis渲染出图片。
每次调用新任务时,Contingent 都可以假设它已被当前位于堆栈顶部的任务调用,并且其输出将被使用。维护堆栈将需要围绕任务 T 的调用执行几个额外的步骤:
- Push T
- 执行T,执行过程中可能调用其他任务
- Pop T
- 返回结果
为了拦截任务调用,Project 利用 了一个关键的 Python 功能:函数装饰器。装饰器允许在定义函数时处理或转换函数。 Project.task 装饰器利用这个机会将每个任务打包到另一个函数(包装器)中,这允许在包装器(它将代表项目管理图和堆栈)和我们的任务函数(专注于文档处理)之间明确分离。下面是 task 装饰器模板的样子:
from functools import wraps
def task(function):
@wraps(function)
def wrapper(*args):
# wrapper body, that will call function()
return wrapper
这是一个完全典型的 Python 装饰器声明。然后,可以通过在定义函数的上方通过@task应用装饰器:
@task
def title_of(filename):
title, body = parse(filename)
return title
此定义完成后, title_of 将引用函数的包装版本。装饰器可以通过function 访问函数的原始版本,在适当的时间调用它。task装饰器具体内容如下:
def task(function):
@wraps(function)
def wrapper(*args):
task = Task(wrapper, args)
if self.task_stack:
self._graph.add_edge(task, self.task_stack[-1])
self._graph.clear_inputs_of(task)
self._task_stack.append(task)
try:
value = function(*args)
finally:
self._task_stack.pop()
return value
return wrapper
此包装器执行几个关键的维护步骤:
- 打包任务。 将任务打包到一个对象中,wrapper此处命名任务函数的包装版本。
- 如果此任务已被正在进行的当前任务调用,则添加一条边,以捕获此任务是已运行任务的输入这一事实。
- 忘记我们上次可能学到的关于任务的任何内容,因为这次它可能会做出新的决定——例如,如果 API guide的源文本不再提及tutorial,那么它的 render() 不再要求提供 title_of() Tutorial。
- 将此任务Push到任务堆栈的顶部,以防它决定在执行其工作的过程中调用其他任务。
- 调用 try…finally 块内的任务,确保我们正确地从堆栈中删除已完成的任务,即使它因引发异常而死亡。
- 返回任务的返回值
步骤 4 和 5 维护任务堆栈本身,步骤 2 使用堆栈来执行跟踪后续,这是我们首先构建任务堆栈的全部原因。
由于每个任务都被自己的包装函数副本包围,因此仅调用和执行常规任务堆栈就会产生关系图,这是一种不可见的副作用。这就是为什么我们小心翼翼地在我们定义的每个处理步骤使用包装器的原因:
@task
def read(filename):
# body of read
@task
def parse(filename):
# body of parse
@task
def title_of(filename):
# body of title_of
@task
def render(filename):
# body of render
多亏了这些装饰器,当我们调用 parse('tutorial.txt') 装饰器时,它才知道 parse 和 read 之间的联系。我们可以通过构建另一个 Task 元组并询问如果它的输出值发生变化会有什么后果来询问这种关系:
>>> task = Task(read, ('tutorial.txt',))
>>> print(task)
read('tutorial.txt')
>>> project._graph.immediate_consequences_of(task)
[parse('tutorial.txt')]
重新read tutorial.txt 文件并发现其内容已更改的后果是我们需要重新执行该文档的 parse() 函数。如果我们渲染整套文档会发生什么?Contingent 是否能够学习整个构建过程?
>>> for filename in 'index.txt', 'tutorial.txt', 'api.txt':
... print(render(filename))
... print('=' * 30)
...
<h1>Table of Contents</h1>
<p>
* <a href="tutorial.txt">Beginners Tutorial</a>
* <a href="api.txt">API Reference</a>
<p>
==============================
<h1>Beginners Tutorial</h1>
<p>
Welcome to the tutorial!
We hope you enjoy it.
<p>
==============================
<h1>API Reference</h1>
<p>
You might want to read
the <a href="tutorial.txt">Beginners Tutorial</a> first.
<p>
==============================
成功了!从输出中,我们可以看到,我们的转换用文档标题代替了源文档中的指令,这表明 Contingent 能够发现构建文档所需的各种任务之间的联系。

通过 task 包装机制观察一个任务调用另一个任务, Project 自动学习了输入和结果的图。由于它有一个完整的后果图可供使用,因此 Contingent 知道如果任何任务的输入发生变化,需要重建的所有内容。
追逐后续
初始生成运行完成后,Contingent 需要监视输入文件的更改。当用户完成新的编辑并运行“保存”时,需要调用该 read() 方法及其结果。
这将要求我们以与创建图时相反的顺序遍历图。你会记得,它是通过调用 render() API 参考并调用 parse() 最终调用 read() 任务来构建的。现在我们走向另一个方向:我们知道现在 read() 将返回新内容,我们需要弄清楚下游的后果。
编译结果的过程是一个递归的过程,因为每个结果本身都可以有依赖于它的进一步任务。我们可以通过重复调用图来手动执行此递归。(请注意,我们在这里利用了这样一个事实,即 Python 提示保存名称 _ 下显示的最后一个值,以便在后续表达式中使用。)
>>> task = Task(read, ('api.txt',))
>>> project._graph.immediate_consequences_of(task)
[parse('api.txt')]
>>> t1, = _
>>> project._graph.immediate_consequences_of(t1)
[render('api.txt'), title_of('api.txt')]
>>> t2, t3 = _
>>> project._graph.immediate_consequences_of(t2)
[]
>>> project._graph.immediate_consequences_of(t3)
[render('index.txt')]
>>> t4, = _
>>> project._graph.immediate_consequences_of(t4)
[]
这种反复寻找直接后果的递归任务,只有在我们到达没有进一步后果的任务时才停止,这是一个足够基本的图操作,它直接由 Graph 类上的方法支持:
>>> # Secretly adjust pprint to a narrower-than-usual width:
>>> _pprint = pprint
>>> pprint = lambda x: _pprint(x, width=40)
>>> pprint(project._graph.recursive_consequences_of([task]))
[parse('api.txt'),
render('api.txt'),
title_of('api.txt'),
render('index.txt')]
事实上, recursive_consequences_of() 试图变得有点聪明。如果某个特定任务作为其他几个任务的下游结果重复出现,则应小心地在输出列表中仅提及一次,并将其移到末尾,以便仅出现在作为其输入的任务之后。这种智能由拓扑排序的经典深度优先实现提供支持,该算法最终通过隐藏的递归帮助程序函数在 Python 中编写相当容易。详细信息请查看graphlib.py 源代码。
如果在检测到更改后,我们小心翼翼地在递归结果中重新运行每个任务,那么 Contingent 将能够避免重建得太少。然而,我们的第二个挑战是避免过多的重建。再次参见图 4.4。我们希望避免在每次更改时 tutorial.txt 都重新构建所有三个文档,因为大多数编辑可能不会影响其标题,而只会影响其正文。如何做到这一点?
解决方案是使图形重新计算依赖于缓存(cache)。在逐步完成更改的递归结果时,我们只会调用输入与上次不同的任务。
此优化将涉及最终的数据结构。我们将给出 Project 一个 _todo 集合,用于记住至少一个输入值已更改并因此需要重新执行的每个任务。由于只有在_todo 中的任务已过期,因此生成过程可以跳过运行其他任务。
同样,Python 方便和统一的设计使这些功能非常容易编码。由于任务对象是可散列的, 因此_todo可以是一个按标识记住任务项的集合(保证任务永远不会出现两次),并且以前运行的 _cache 返回值可以是将任务作为键的字典。
更准确地说,只要 _todo 非空,重建步骤就必须保持循环。在每个循环中,它应该:
- 调用
recursive_consequences_of()并传入 _todo 中列出的每个任务。返回值不仅是 _todo 任务本身的列表,还包括任务下游的每个任务的列表——换句话说,如果这次输出不同,则可能需要重新执行的每个任务。 - 对于列表中的每个任务,检查它是否列在
_todo中。如果没有,那么我们可以跳过运行它,因为我们在它的上游重新调用的所有任务都没有产生需要重新计算任务的新返回值。 - 但是,对于在我们到达它时确实列出
_todo的任何任务,我们需要要求它重新运行并重新计算其返回值。如果任务包装器函数检测到此返回值与旧的缓存值不匹配,则在递归结果列表中到达它们_todo之前,其下游任务将被自动添加到这些任务中。
当我们到达列表的末尾时,可能需要重新运行的每个任务实际上都应该已经重新运行。但以防万一,如果它还没有空,我们将检查 _todo 并重试。即使对于变化非常快的依赖关系树,这也应该很快解决。只有循环依赖(例如,任务 A 需要任务 B 的输出,而任务 B 本身需要任务 A 的输出)才能使构建器处于无限循环中,并且只有当它们的返回值永远不会稳定时。幸运的是,实际构建任务通常没有循环依赖。
让我们通过一个例子来跟踪这个系统的行为。
假设您同时编辑 tutorial.txt 和更改了标题和正文内容。我们可以通过修改字典filesystem中的值来模拟这一点:
>>> filesystem['tutorial.txt'] = """
... The Coder Tutorial
... ------------------
... This is a new and improved
... introductory paragraph.
... """
现在内容已经改变,我们可以要求项目使用其 cache_off() 上下文管理器重新运行 read() 任务,该管理器暂时禁用缓存:
>>> with project.cache_off():
... text = read('tutorial.txt')
新的tutorial文本现已读入缓存。需要重新执行多少个下游任务?
为了帮助我们回答这个问题,该 Project 类支持一个简单的跟踪工具,它将告诉我们在重建过程中执行了哪些任务。由于上述更改 tutorial.txt 会影响其正文和标题,因此需要重新计算下游的所有内容:
>>> project.start_tracing()
>>> project.rebuild()
>>> print(project.stop_tracing())
calling parse('tutorial.txt')
calling render('tutorial.txt')
calling title_of('tutorial.txt')
calling render('api.txt')
calling render('index.txt')
回顾图 4.4,您可以看到,正如预期的那样,这是 read(‘tutorial.txt’) 的直接或下游结果的每个任务。
但是,如果我们再次编辑它,但这次保持标题不变呢?
>>> filesystem['tutorial.txt'] = """
... The Coder Tutorial
... ------------------
... Welcome to the coder tutorial!
... It should be read top to bottom.
... """
>>> with project.cache_off():
... text = read('tutorial.txt')
这个小的、有限的更改应该不会对其他文档产生影响。
>>> project.start_tracing()
>>> project.rebuild()
>>> print(project.stop_tracing())
calling parse('tutorial.txt')
calling render('tutorial.txt')
calling title_of('tutorial.txt')
成功!只有一个文档被重建。给定一个新的输入文档,但仍然返回相同的值,这一事实 意味着所有进一步的下游任务都与更改隔离开来,并且不会被重新调用。
结论
在现有的语言和编程方法中,Contingent 将是一片令人窒息的小类森林,问题域中的每个概念都被赋予了冗长的名称。
然而,在用 Python 编写 Condition 时,我们跳过了十几个可能的类的创建,例如 TaskArgument ConsequenceList 和 CachedResult 和 。相反,我们借鉴了 Python 使用泛型数据结构解决泛型问题的强大传统,从而产生了重复使用核心数据结构元组、列表、集和字典中的一小部分思想的代码。
但这不会造成问题吗?
通用数据结构本质上也是匿名的。我们的 project._cache 是set。中 Graph 的每一个上游和下游节点集合也是set。我们是否面临看到通用 set 错误消息的危险,并且不知道是在项目还是图实现中查找错误?
事实上,我们没有危险!
由于封装的严格规则(只允许 Graph 代码接触图的set,而 Project 代码接触项目的set),如果集合操作在项目的后期阶段返回错误,则永远不会出现歧义。在错误发生时,最内层的执行方法的名称必然会将我们引导到错误中涉及的类和集合。没有必要为数据类型的每个可能的应用程序创建一个子 set 类,只要我们将传统的下划线放在数据结构属性的前面,然后注意不要从类之外的代码中触及它们。
Contingent 展示了划时代的 Design Patterns书中 的 Facade 模式对于设计良好的 Python 程序的重要性。并非 Python 程序中的每个数据结构和数据片段都可以成为自己的类。取而代之的是,类在代码中的概念枢轴处被谨慎使用,在这个枢轴中,一个大概念(如依赖关系图的概念)可以被包装到一个 Facade 中,该 Facade 隐藏了位于其下方的简单通用数据结构的细节。
Facade 外部的代码命名了它需要的大概念和它想要执行的操作。在 Facade 内部,程序员操纵 Python 编程语言中小而方便的移动部分,完成操作。
Facade(外观模式)属于结构型模式,是一种日常开发中经常被使用到的设计模式。
意图:为子系统中的一组接口提供一个一致的接口,Facade 模式定义了一个高层接口,这个接口使得这一子系统更加容易使用。 –设计模式 - Facade 外观模式