💛前情提要💛
本文是传知代码平台中的相关前沿知识与技术的分享~
接下来我们即将进入一个全新的空间,对技术有一个全新的视角~
本文所涉及所有资源均在传知代码平台可获取
以下的内容一定会让你对AI 赋能时代有一个颠覆性的认识哦!!!
以下内容干货满满,跟上步伐吧~
📌导航小助手📌
- 💡本章重点
- 🍞一. 概述
- 🍞二. 论文方法
- 🍞三. 论文总结
- 🍞四. 代码复现
- 🍞五. 数据集划分
- 🍞六. 训练模型
- 🍞七. 模型推理与可视化结果
- 🫓总结
💡本章重点
- MonoCon解读与复现
🍞一. 概述
本文介绍了一种名为 MonoCon 的方法,用于单目深度目标检测任务中的辅助学习。该方法利用了训练数据中丰富的投影2D监督信号作为辅助任务,在训练过程中同时学习了目标3D边界框和辅助上下文信息。实验结果表明,该方法在KITTI基准测试中取得了优异的表现,并且具有较快的推理速度。
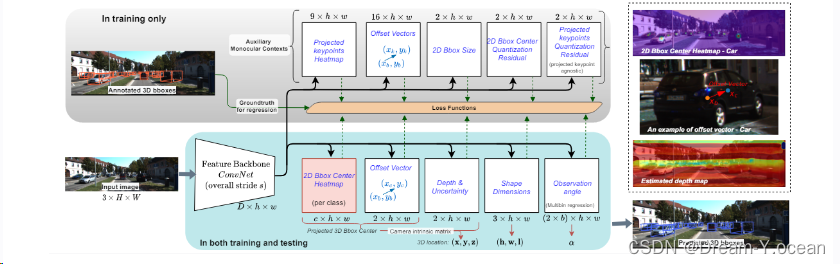
🍞二. 论文方法
方法描述
该论文提出了一种名为MonoCon的单目深度估计方法,用于预测3D物体的中心位置、形状尺寸和观察角度等参数。
论文实验
本文主要介绍了作者在Kitti 3D目标检测基准上进行的实验,并与现有的方法进行了比较。具体来说,作者首先对数据集和评估指标进行了介绍,然后针对MonoCon方法进行了训练和测试,并对其进行了详细的分析和解释。
在实验中,作者使用了Kitti 3D目标检测基准中的数据集,其中包括7481张图像用于训练和7518张图像用于测试。共有三个类别感兴趣:汽车、行人和自行车。作者采用了官方服务器提供的平均精度(AP)作为评估指标,包括AP3D|R40和APBEV|R40两个指标,均使用40个召回位置(R40),并在三种难度级别下进行评估。此外,作者还提供了训练和验证子集的划分方式。
在实验结果方面,作者首先将MonoCon与其他现有方法进行了比较。对于汽车类别,MonoCon在所有评估指标下都表现出了显著的优势,比第二名的方法GUPNet提高了1.44%的绝对增加率。同时,MonoCon也比其他方法运行得更快。然而,在行人和自行车类别上,MonoCon的表现不如一些现有方法。对于行人类别,MonoCon相对于最佳模型GUPNet有1.35%的AP3D|R40下降,但在所有方法中表现最好。对于自行车类别,MonoCon相对于最佳纯单目方法MonoDLE有1.29%的AP3D|R40下降,但仍然优于其他方法。作者认为,这可能是因为自行车类别的3D边界框比汽车类别的要小得多,投影到特征图上的辅助上下文往往非常接近,这可能会影响辅助上下文的学习效果。
最后,作者进行了多个Ablation Study来进一步分析MonoCon的效果。其中,作者发现学习辅助上下文是提高MonoCon性能的关键因素之一,而注意力归一化的作用相对较小。此外,作者还研究了回归头的类无关设置和训练设置的影响,发现在某些情况下可以提高性能。
总的来说,本文通过一系列实验和分析,证明了MonoCon在3D目标检测任务中的有效性,并提出了一些改进方向。

🍞三. 论文总结
文章优点
该论文提出了一种简单而有效的方法来进行单目3D目标检测,不需要利用任何额外的信息。作者提出的MonoCon方法学习了辅助单目上下文,这些上下文是从训练中的3D边界框投影而来。该方法采用了简单的实现设计,包括一个卷积神经网络特征背心和一组具有相同模块架构的回归头,用于必要的参数和辅助上下文。在实验中,MonoCon在Kitti 3D目标检测基准测试中表现出色,在汽车类别上优于最先进的方法,并在行人和骑自行车类别上获得与之相当的表现。此外,该方法还使用Cramer-Wold定理解释了其有效性,并进行了有效的实验验证。
方法创新点
该论文提出了MonoCon方法,这是一种基于单目上下文的学习方法,可以提高单目3D目标检测的性能。该方法通过利用3D边界框的投影来提取丰富的监督信号,从而有效地提高了模型的表达能力。此外,该方法采用了简单的实现设计,使得模型更加高效和易于理解。
未来展望
该论文提出的方法为单目3D目标检测提供了一个新的思路,但仍然存在一些挑战需要克服。例如,如何进一步提高模型的准确性和鲁棒性,以及如何将该方法扩展到其他应用场景中。因此,未来的研究方向可能包括改进模型的设计和优化算法,以提高模型的性能和效率。同时,还需要进一步探索单目上下文的潜力,以便更好地应用于实际场景中。
🍞四. 代码复现
这是不同于官方的基于pytorch的monocon复现
[Step 1]: 创建新的环境
Set [ENV_NAME] freely to any name you want. (Please exclude the brackets.)
conda create --name [ENV_NAME] python=3.8
conda activate [ENV_NAME]
[Step 2]: 下载新的代码
部分核心代码如下:
- monocon_detector.py
import os
import sys
import torch
import torch.nn as nn
from typing import Tuple, Dict, Any
sys.path.append(os.path.join(os.path.dirname(__file__), "..", ".."))
from model import DLA, DLAUp, MonoConDenseHeads
default_head_config = {
'num_classes': 3,
'num_kpts': 9,
'num_alpha_bins': 12,
'max_objs': 30,
}
default_test_config = {
'topk': 30,
'local_maximum_kernel': 3,
'max_per_img': 30,
'test_thres': 0.4,
}
class MonoConDetector(nn.Module):
def __init__(self,
num_dla_layers: int = 34,
pretrained_backbone: bool = True,
head_config: Dict[str, Any] = None,
test_config: Dict[str, Any] = None):
super().__init__()
self.backbone = DLA(num_dla_layers, pretrained=pretrained_backbone)
self.neck = DLAUp(self.backbone.get_out_channels(start_level=2), start_level=2)
if head_config is None:
head_config = default_head_config
if test_config is None:
test_config = default_test_config
if num_dla_layers in [34, 46]:
head_in_ch = 64
else:
head_in_ch = 128
self.head = MonoConDenseHeads(in_ch=head_in_ch, test_config=test_config, **head_config)
def forward(self, data_dict: Dict[str, Any], return_loss: bool = True) -> Tuple[Dict[str, torch.Tensor]]:
feat = self._extract_feat_from_data_dict(data_dict)
if self.training:
pred_dict, loss_dict = self.head.forward_train(feat, data_dict)
if return_loss:
return pred_dict, loss_dict
return pred_dict
else:
pred_dict = self.head.forward_test(feat)
return pred_dict
def batch_eval(self,
data_dict: Dict[str, Any],
get_vis_format: bool = False) -> Dict[str, Any]:
if self.training:
raise Exception(f"Model is in training mode. Please use '.eval()' first.")
pred_dict = self.forward(data_dict, return_loss=False)
eval_format = self.head._get_eval_formats(data_dict, pred_dict, get_vis_format=get_vis_format)
return eval_format
def load_checkpoint(self, ckpt_file: str):
model_dict = torch.load(ckpt_file)['state_dict']['model']
self.load_state_dict(model_dict)
def _extract_feat_from_data_dict(self, data_dict: Dict[str, Any]) -> torch.Tensor:
img = data_dict['img']
return self.neck(self.backbone(img))[0]
[Step 3]: See https://pytorch.org/get-started/locally/ and install pytorch for your environment.
We have tested on version 1.10.0.
It is recommended to install version 1.7.0 or higher.
[Step 4]: Install some packages using ‘requirements.txt’ in the repository.
The version of numpy must be 1.22.4.
pip install -r requirements.txt
[Step 5]
conda install cudatoolkit
🍞五. 数据集划分
下载后的文件放在 dataset 目录中,存放的目录结构
dataset
│
├── training
│ ├── calib
│ │ ├── 000000.txt
│ │ ├── 000001.txt
│ │ └── …
│ ├── image_2
│ │ ├── 000000.png
│ │ ├── 000001.png
│ │ └── …
│ └── label_2
│ ├── 000000.txt
│ ├── 000001.txt
│ └── …
│
└── testing
├── calib
└── image_2
需要对数据集划分:train训练集、val验证集,在dataset目录下新建一个文件to_train_val.py
用于将training 带标签数据(7481帧),划分为train(3712帧)、val(3769帧),代码如下:
import os
import shutil
# 【一】、读取train.txt文件
with open('./ImageSets/train.txt', 'r') as file:
# 逐行读取train.txt文件中的文件名ID
file_ids = [line.strip() for line in file]
# 【1】calib
# 指定路径A和路径B
path_A = './training/calib'
path_B = './train/calib'
# 如果路径B不存在,创建它
if not os.path.exists(path_B):
os.makedirs(path_B)
# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:
source_file = os.path.join(path_A, f"{file_id}.txt")
destination_file = os.path.join(path_B, f"{file_id}.txt")
if os.path.exists(source_file):
shutil.copy(source_file, destination_file)
else:
print(f"文件未找到:{file_id}.txt")
# 【2】image_2
# 指定路径A和路径B
path_A = './training/image_2'
path_B = './train/image_2'
# 如果路径B不存在,创建它
if not os.path.exists(path_B):
os.makedirs(path_B)
# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:
source_file = os.path.join(path_A, f"{file_id}.png")
destination_file = os.path.join(path_B, f"{file_id}.png")
if os.path.exists(source_file):
shutil.copy(source_file, destination_file)
else:
print(f"文件未找到:{file_id}.txt")
# 【3】label_2
# 指定路径A和路径B
path_A = './training/label_2'
path_B = './train/label_2'
# 如果路径B不存在,创建它
if not os.path.exists(path_B):
os.makedirs(path_B)
# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:
source_file = os.path.join(path_A, f"{file_id}.txt")
destination_file = os.path.join(path_B, f"{file_id}.txt")
if os.path.exists(source_file):
shutil.copy(source_file, destination_file)
else:
print(f"文件未找到:{file_id}.txt")
# 【二】、读取valtxt文件
with open('./ImageSets/val.txt', 'r') as file:
# 逐行读取val.txt文件中的文件名ID
file_ids = [line.strip() for line in file]
# 【1】calib
# 指定路径A和路径B
path_A = './training/calib'
path_B = './val/calib'
# 如果路径B不存在,创建它
if not os.path.exists(path_B):
os.makedirs(path_B)
# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:
source_file = os.path.join(path_A, f"{file_id}.txt")
destination_file = os.path.join(path_B, f"{file_id}.txt")
if os.path.exists(source_file):
shutil.copy(source_file, destination_file)
else:
print(f"文件未找到:{file_id}.txt")
# 【2】image_2
# 指定路径A和路径B
path_A = './training/image_2'
path_B = './val/image_2'
# 如果路径B不存在,创建它
if not os.path.exists(path_B):
os.makedirs(path_B)
# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:
source_file = os.path.join(path_A, f"{file_id}.png")
destination_file = os.path.join(path_B, f"{file_id}.png")
if os.path.exists(source_file):
shutil.copy(source_file, destination_file)
else:
print(f"文件未找到:{file_id}.txt")
# 【3】label_2
# 指定路径A和路径B
path_A = './training/label_2'
path_B = './val/label_2'
# 如果路径B不存在,创建它
if not os.path.exists(path_B):
os.makedirs(path_B)
# 遍历文件名ID并复制文件到路径B
for file_id in file_ids:
source_file = os.path.join(path_A, f"{file_id}.txt")
destination_file = os.path.join(path_B, f"{file_id}.txt")
if os.path.exists(source_file):
shutil.copy(source_file, destination_file)
else:
print(f"文件未找到:{file_id}.txt")
🍞六. 训练模型
训练模型的配置在config/monocon_configs.py:
需要修改数据集的路径。
模型训练保存的路径,比如./checkpoints_train,新建一个checkpoints_train文件夹。
如果GPU显存小于16G,要将_C.USE_BENCHMARK 设置为False;如果大约16G,设置为True。
设置BATCH_SIZE的大小,默认 _C.DATA.BATCH_SIZE = 8
设置CPU线程数,默认 _C.DATA.NUM_WORKERS = 4
设置验证模型和保存模型的间隔轮数,默认_C.PERIOD.EVAL_PERIOD = 10
from yacs.config import CfgNode as CN
_C = CN()
_C.VERSION = 'v1.0.3'
_C.DESCRIPTION = "MonoCon Default Configuration"
_C.OUTPUT_DIR = "./checkpoints_train" # Output Directory
_C.SEED = -1 # -1: Random Seed Selection
_C.GPU_ID = 0 # Index of GPU to use
_C.USE_BENCHMARK = False # Value of 'torch.backends.cudnn.benchmark' and 'torch.backends.cudnn.enabled'
# Data
_C.DATA = CN()
_C.DATA.ROOT = r'./dataset' # KITTI Root
_C.DATA.BATCH_SIZE = 8
_C.DATA.NUM_WORKERS = 4
_C.DATA.TRAIN_SPLIT = 'train'
_C.DATA.TEST_SPLIT = 'val'
_C.DATA.FILTER = CN()
_C.DATA.FILTER.MIN_HEIGHT = 25
_C.DATA.FILTER.MIN_DEPTH = 2
_C.DATA.FILTER.MAX_DEPTH = 65
_C.DATA.FILTER.MAX_TRUNCATION = 0.5
_C.DATA.FILTER.MAX_OCCLUSION = 2
# Model
_C.MODEL = CN()
_C.MODEL.BACKBONE = CN()
_C.MODEL.BACKBONE.NUM_LAYERS = 34
_C.MODEL.BACKBONE.IMAGENET_PRETRAINED = True
_C.MODEL.HEAD = CN()
_C.MODEL.HEAD.NUM_CLASSES = 3
_C.MODEL.HEAD.MAX_OBJS = 30
# Optimization
_C.SOLVER = CN()
_C.SOLVER.OPTIM = CN()
_C.SOLVER.OPTIM.LR = 2.25E-04
_C.SOLVER.OPTIM.WEIGHT_DECAY = 1E-05
_C.SOLVER.OPTIM.NUM_EPOCHS = 20 # Max Training Epochs 200
_C.SOLVER.SCHEDULER = CN()
_C.SOLVER.SCHEDULER.ENABLE = True
_C.SOLVER.CLIP_GRAD = CN()
_C.SOLVER.CLIP_GRAD.ENABLE = True
_C.SOLVER.CLIP_GRAD.NORM_TYPE = 2.0
_C.SOLVER.CLIP_GRAD.MAX_NORM = 35
# Period
_C.PERIOD = CN()
_C.PERIOD.EVAL_PERIOD = 10 # In Epochs / Set -1 if you don't want validation 10
_C.PERIOD.LOG_PERIOD = 50 # In Steps 50
🍞七. 模型推理与可视化结果
模型推理的命令含义如下:
python test.py --config_file [FILL] # Config file (.yaml file)
–checkpoint_file [FILL] # Checkpoint file (.pth file)
–visualize # Perform visualization (Qualitative Results)
–gpu_id [Optional] # Index of GPU to use for testing (Default: 0)
–save_dir [FILL] # Path where visualization results will be saved to
- 使用刚才训练的权重,模型推理示例:
python test.py --config_file checkpoints_train/config.yaml --checkpoint_file checkpoints_train/checkpoints/epoch_010.pth --visualize --save_dir save_output --gpu_id 0
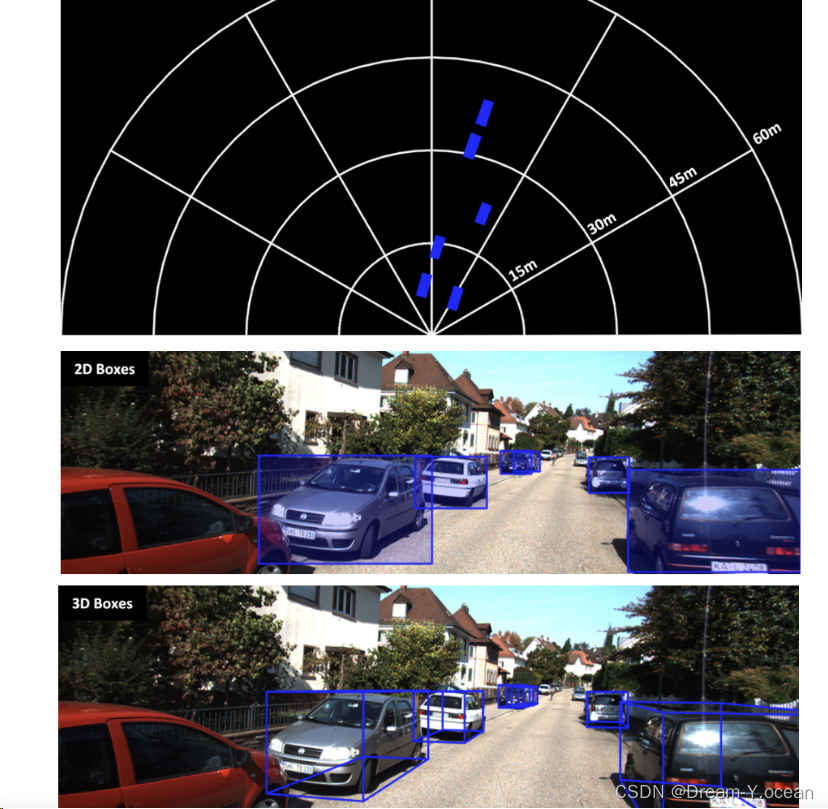
视频推理
python test_raw.py --data_dir [FILL] # Path where sequence images are saved
--calib_file [FILL] # Calibration file ("calib_cam_to_cam.txt")
--checkpoint_file [FILL] # Checkpoint file (.pth file)
--gpu_id [Optional] # Index of GPU to use for testing (Default: 0)
--fps [Optional] # FPS of the result video (Default: 25)
--save_dir [FILL] # Path of the directory to save the result video
参考材料
@InProceedings{liu2022monocon,
title={Learning Auxiliary Monocular Contexts Helps Monocular 3D Object Detection},
author={Xianpeng Liu, Nan Xue, Tianfu Wu},
booktitle = {36th AAAI Conference on Artifical Intelligence (AAAI)},
month = {Feburary},
year = {2022}
}
https://blog.csdn.net/qq_41204464/article/details/133824468
https://guo-pu.blog.csdn.net/article/details/133834915
🫓总结
综上,我们基本了解了“一项全新的技术啦” 🍭 ~~
恭喜你的内功又双叒叕得到了提高!!!
感谢你们的阅读😆
后续还会继续更新💓,欢迎持续关注📌哟~
💫如果有错误❌,欢迎指正呀💫
✨如果觉得收获满满,可以点点赞👍支持一下哟~✨
【传知科技 – 了解更多新知识】