Imagic: Text-Based Real Image Editing with Diffusion Models
Bahjat Kawar, Google Research, CVPR23, Paper, Code
1. 前言
在本文中,我们首次展示了将复杂(例如,非刚性)基于文本的语义编辑应用于单个真实图像的能力。例如,我们可以改变图像中一个或多个对象的姿势和组成,同时保留其原始特征。我们的方法可以让站着的狗坐下,让鸟展开翅膀,等等——每一个都在用户提供的高分辨率自然图像中。与之前的工作相反,我们提出的方法只需要单个输入图像和目标文本(所需的编辑)。它对真实图像进行操作,并且不需要任何额外的输入(例如图像遮罩或对象的额外视图)。我们的方法称为Imagic,利用预先训练的文本到图像扩散模型来完成这项任务。它生成与输入图像和目标文本对齐的文本嵌入,同时微调扩散模型以捕捉图像特定的外观。我们在来自不同领域的大量输入上展示了Imagic的质量和多功能性,展示了大量高质量的复杂语义图像编辑,所有这些都在一个统一的框架内。为了更好地评估性能,我们引入了TEdBench,这是一个极具挑战性的图像编辑基准。我们进行了一项用户研究,其结果表明,与TEdBencch上以前的领先编辑方法相比,人类评分者更喜欢Imagic。

2. 整体思想
如下图,首先冻结扩散模型然后用目标Prompt优化出一个匹配Prompt,然后用这个Prompt微调扩散模型,最后在目标和匹配之间插值的Prompt生成图片。这里的关键在于第一步,第一步确保了优化的Prompt的语义和图片匹配,当然目标Prompt需要编辑的属性可以被区别出来,这对插值这步很重要。
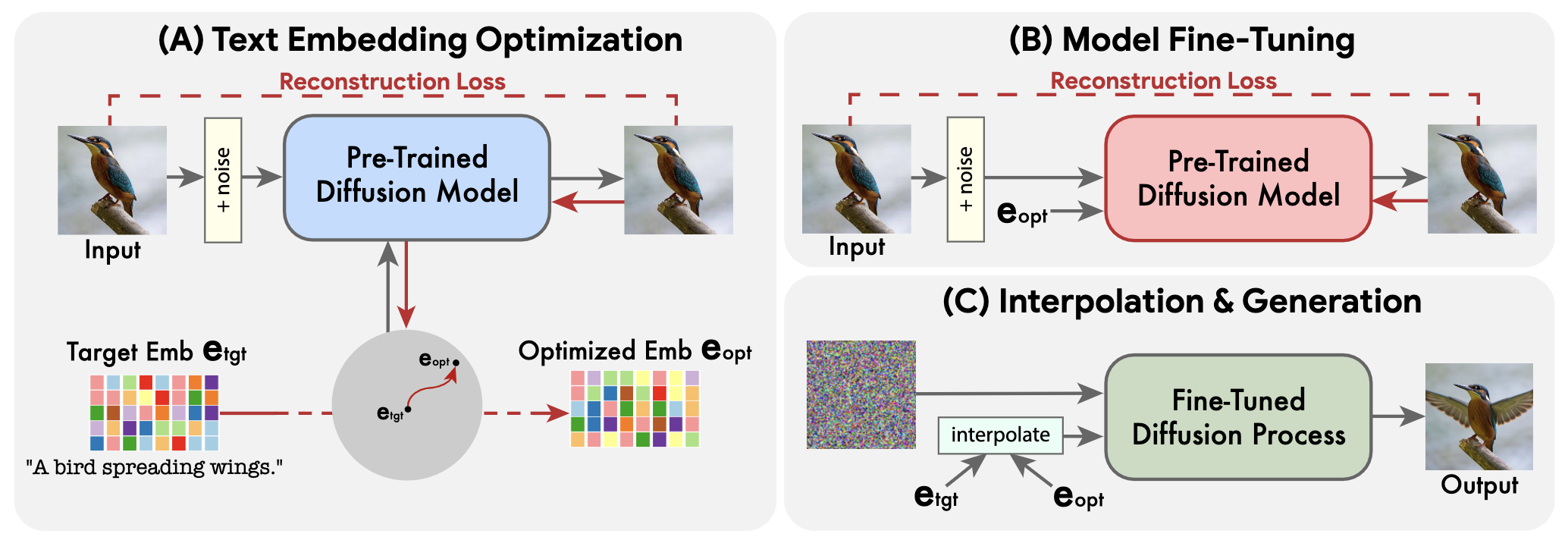
3. 方法
Text embedding optimization:目标文本首先通过文本编码器,该文本编码器输出其相应的文本嵌入 e t g t ∈ R T × d e_{t_{gt}} \in R^{T \times d} etgt∈RT×d,其中 T T T是给定目标文本中的标记数量, d d d是标记嵌入维度。然后,我们冻结生成扩散模型的参数,并使用去噪扩散目标优化目标文本嵌入。这导致文本嵌入尽可能与我们的输入图像匹配。我们运行这个过程的步骤相对较少,以便保持接近初始目标文本嵌入,获得 e o p t e_{opt} eopt。这种接近性使得能够在嵌入空间中进行有意义的线性插值,这对于遥远的嵌入来说不会表现出线性行为。
Model Fine-tuning: 请注意,当通过生成扩散过程时,所获得的优化嵌入 e o p t e_{opt} eopt并不一定会精确地导致输入图像,因为我们的优化只需少量步骤。因此,在我们方法的第二阶段,冻结优化的嵌入,微调模型。该过程移动模型以拟合点 e o p t e_{opt} eopt处的输入图像 x x x。同时,我们微调基础生成方法中存在的任何辅助扩散模型,如超分辨率模型。我们用相同的重建损失对它们进行微调,但以 e t g t e_{tgt} etgt为条件,因为它们将对编辑后的图像进行操作。这些辅助模型的优化确保了基本分辨率中不存在的 x x x的高频细节的保留。经验上,我们发现在推理时,将 e t g t e_{tgt} etgt输入到辅助模型比使用 e o p t e_{opt} eopt表现得更好。
Text embedding interpolation: 由于生成扩散模型被训练为在优化的嵌入 e o p t e_{opt} eopt处完全重新创建输入图像 x x x,我们使用它通过向目标文本嵌入 e t g t e_{tgt} etgt的方向前进来应用所需的编辑。更正式地说,我们的第三阶段是 e t g t e_{tgt} etgt和 e o p t e_{opt} eopt之间的简单线性插值。对于给定的超参数 η ∈ [ 0 , 1 ] η \in \left[ 0,1 \right] η∈[0,1],我们得到:
e ˉ = η ⋅ e t g t + ( 1 − η ) ⋅ e o p t \bar e = \eta ·e_{tgt} + (1-\eta) ·e_{opt} eˉ=η⋅etgt+(1−η)⋅eopt
其是表示期望的编辑图像的嵌入。然后,我们使用微调模型,以̄e为条件,应用基底生成扩散过程。这导致了低分辨率的编辑图像,然后使用微调的辅助模型对其进行超分辨率处理,以目标文本为条件。这个生成过程输出我们最终的高分辨率编辑图像 x x x.
4. 实验

上图是没有fine-tuned的,重建效果较差。可以看到上面无法保证背景一致性,下面可以非常好的保证。