前言
在上一篇文章《端午特别篇:你真的了解数据库索引吗?》中,纪宽针对一个业务SQL推荐索引优化问题提出了疑问。他发现DBdoctor推荐的索引组合(status, purchase_date,device_name, device_id)似乎与他作为DBA凭借多年经验推荐的索引方案大相径庭。DBdoctor与资深DBA之间究竟孰对孰错?我们将在本文中详细解密DBdoctor和资深DBA的PK结果,我将用实际的验证和剖析来狠狠地抽打他!
SELECT *FROMdeviceWHEREpurchase_date >= '2023-05-31'AND status = 'active' and device_id>=0AND device_name like '%162b%'
SQL分析
为了验证上述推荐索引的准确性,我们将DBA经验推荐的索引和DBdoctor推荐的索引都加上去,最终交给MySQL自己,看它究竟会选择哪个索引。
DBA推荐的:
KEY `dbdoctor_idx_status_purchase_date` (`status`,`purchase_date`)DBdoctor推荐的:
KEY `dbdoctor_idx_status_purchase_date_device_name_device_id` (`status`,`purchase_date`,`device_name`,`device_id)`DBA的结论:认为DBdoctor推荐的不准,完全不符合MySQL的原理规则,比如最左原则和模糊匹配等,那真实情况如何呢?
手动验证谁才是最优的索引
1)给device表增加上面三个索引,表结构如下:
CREATE TABLE `device` (`id` int NOT NULL AUTO_INCREMENT,`device_id` int DEFAULT NULL,`device_name` varchar(255) COLLATE utf8mb4_general_ci NOT NULL,`device_type` varchar(100) COLLATE utf8mb4_general_ci NOT NULL,`purchase_date` date DEFAULT NULL,`status` varchar(50) COLLATE utf8mb4_general_ci DEFAULT 'active',`created_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,`updated_at` timestamp NULL DEFAULT CURRENT_TIMESTAMP,PRIMARY KEY (`id`),KEY `dbdoctor_idx_status_purchase_date_device_name_device_id` (`status`,`purchase_date`,`device_name`,`device_id`),KEY `dbdoctor_idx_purchase_date_status` (`purchase_date`,`status`),KEY `dbdoctor_idx_status_purchase_date` (`status`,`purchase_date`)) ENGINE=InnoDB AUTO_INCREMENT=20446488 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci
索引采样page和采样记录数:

2)开启trace查看SQL实际三个索引的cost消耗,发现DBdoctor推荐最优。
set session optimizer_trace="enabled=on";得到以下trace cost消耗信息,我们发现确实是DBdoctor推荐的`dbdoctor_idx_status_purchase_date_device_name_device_id这个索引是最优的,cost消耗最小。
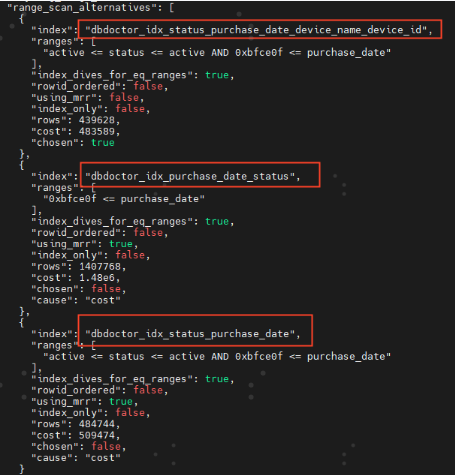
DBA们是不是开始怀疑人生了,为何会是这样?下面我们再进一步剖析。
进一步刨根问底
再回到这两个索引:
DBdoctor推荐:KEY `dbdoctor_idx_status_purchase_date_device_name_device_id` (`status`,`purchase_date`,`device_name`,`device_id`)DBA推荐:KEY `dbdoctor_idx_status_purchase_date` (`status`,`purchase_date`)
细心的你可以发现,上面两个索引trace中有两个怀疑点:
-
DBA推荐的索引开启了MRR算法
-
DBdoctor推荐的索引rows和DBA推荐的索引rows竟然结果不一样
下面我们来进一步分析这两个疑点:
1)我们仔细看下上面trace日志,发现DBA推荐的索引里还走了MRR优化算法,这个相当于多做了一次排序,然后再回表查其他字段,可以将离散IO换成顺序IO,带来性能的提升。难道是这个MRR出了问题,推荐的算法不是最优的,导致整体cost开销变大了?
关闭MRR算法,验证MRR是否是它导致的COST消耗增加:
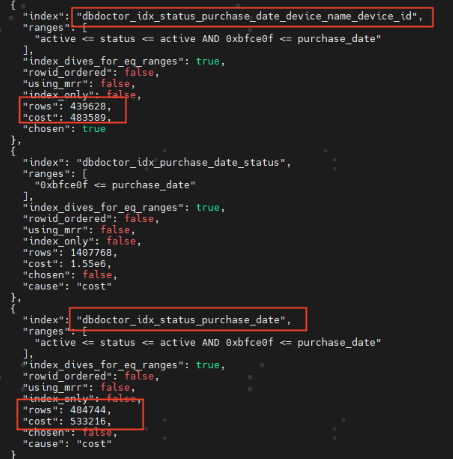
我们发现dbdoctor_idx_status_purchase_date开启mrr反而cost开销减少很多,带来优化,cost减少 533216-509474=23742
结论:MRR算法是带来了优化,MySQL推荐的算法没有问题,那剩下的那个疑点Rows为何不一样呢?
2)从上面排查的结论来看,问题出在预估的扫描行数上面,我们通过强制索引分别查看执行计划,看下扫描行。
-
DBdoctor推荐的索引的扫描行为439628

-
DBA推荐的索引:强制走dbdoctor_idx_purchase_date_status索引,扫描行为484744

DBA推荐的索引的扫描行偏大,多扫描了484744-439628=45116行记录,从MySQL源码Cost计算公式我们知道,每一条row的cost为Server层row_evalute_cost(默认为0.1),那么该索引偏大的一部分原因来自于这个扫描行。那为什么rows差异这么大呢?
我们来看下mysql源码,rows到底怎么得来的?
通过GDB我们快速找到了预估rows的函数,递归函数btr_estimate_n_rows_in_range_on_level 用于估计在 B-tree 某一级别上两个槽位(slot)之间的索引行数,其大致原理如下:
/* 4867 */static int64_t btr_estimate_n_rows_in_range_on_level(/* ... *//* 4876 */ bool *is_n_rows_exact) /*!< out: true if the returned/* 4877 */ value is exact i.e. not an/* 4878 */ estimation *//* 4879 */{/* 4880 */ int64_t n_rows;/* 4881 */ ulint n_pages_read;/* 4882 */ ulint level;/* 4883 *//* 4884 */ n_rows = 0;/* 4885 */ n_pages_read = 0;/* 4886 *//* 4887 */ /* Assume by default that we will scan all pages between/* 4888 */ slot1->page_no and slot2->page_no. *//* 4889 */ *is_n_rows_exact = true;/* ... *//* 4905 */ /* Count the records in the pages between slot1->page_no and/* 4906 */ slot2->page_no (non inclusive), if any. *//* 4907 *//* 4908 */ /* Do not read more than this number of pages in order not to hurt/* 4909 */ performance with this code which is just an estimation. If we read/* 4910 */ this many pages before reaching slot2->page_no then we estimate the/* 4911 */ average from the pages scanned so far. *//* 4912 *//* 4913 */ constexpr uint32_t N_PAGES_READ_LIMIT = 10;/* ... *//* 4940 */ /* It is possible that the tree has been reorganized in the/* 4941 */ meantime and this is a different page. If this happens the/* 4942 */ calculated estimate will be bogus, which is not fatal as/* 4943 */ this is only an estimate. We are sure that a page with/* 4944 */ page_no exists because InnoDB never frees pages, only/* 4945 */ reuses them. *//* 4946 */ if (!fil_page_index_page_check(page) ||/* 4947 */ btr_page_get_index_id(page) != index->id ||/* 4948 */ btr_page_get_level(page) != level) {/* 4949 */ /* The page got reused for something else *//* 4950 */ mtr_commit(&mtr);/* 4951 */ goto inexact;/* 4952 */ }/* ... *//* 4985 */inexact:/* 4986 *//* 4987 */ *is_n_rows_exact = false;/* 4988 *//* 4989 */ /* We did interrupt before reaching slot2->page *//* 4990 *//* 4991 */ if (n_pages_read > 0) {/* 4992 */ /* The number of pages on this level is/* 4993 */ n_rows_on_prev_level, multiply it by the/* 4994 */ average number of recs per page so far *//* 4995 */ n_rows = n_rows_on_prev_level * n_rows / n_pages_read;/* 4996 */ } else {/* 4997 */ /* The tree changed before we could even/* 4998 */ start with slot1->page_no *//* 4999 */ n_rows = 10;/* 5000 */ }/* 5001 *//* 5002 */ return (n_rows);/* 5003 */}
从起始槽位slot1 所在的页面开始,向右扫描几个页面。
如果在扫描过程中很快到达了目标槽位slot2所在的页面,则可以准确计算出 slot1 和 slot2 之间的记录数,并将 is_n_rows_exact 标志设置为 true。
返回估算的行数(不包括边界记录),并根据是否精确计算设置 is_n_rows_exact标志。
-
从起始页开始:
-
统计行数:
读取每个页面,统计其包含的记录数。
-
判断是否到达目标页面:
-
估算剩余页面的行数:
-
如果没有快速到达 slot2所在的页面,则计算已扫描页面中的平均记录数。
-
根据这个平均值,估算未扫描页面中的记录数。假设这些页面中的记录数与已扫描页面的记录数相同。
-
乘以 slot1 和 slot2之间的页面数,得出估算的总记录数。
-
-
返回结果:
该递归函数通过快速扫描初始几个页面来尝试精确计算行数,如无法精确计算,则基于平均值进行估算,以达到在性能和准确性之间的平衡。从trace中我们能看到,两个索引路径的sql拥有同样的range,但索引高度不一样,递归次数不同,页面平均记录数也不同,得出的预估rows不一样。
从上面的数据我们能看到,额外增加的Cost=DBA推荐的索引Cost-DBdoctor推荐的索引Cost=533216-483589=49627,DBA推荐的索引Cost增大主要有以下原因:
-
预估偏差Rows的Sever CPU Cost=45116*0.1=4511.6
-
预估偏差Rows涉及的Page IO Cost(单次io_read_block_cost默认为1)

综上所述:精确估算行数和平均值预估得出的行数是存在数据偏差的,从而也会影响到索引的最终选择,这一块由内核的固化代码逻辑来决定,DBA在做索引推荐的时候是无法感知到这一层的,通过规则方式不能覆盖到该场景。而通过DBdoctor的eBPF技术是可以感知到该层面数据,从而可以做出和MySQL选择一致的最优路径,从上面的执行结果可以看到DBdoctor推荐的索引比DBA推荐的索引执行耗时减少一倍。
总结
DBdoctor基于实际Cost的最优路径分析才是最准的,DBA的经验规则在一定场景下确实是可以带来优化,但在一些场景下是很难搞定的,比如上述场景,这里我初略的列了以下几点:
-
多种算法路径会导致Cost不一样
-
在不同版本中路径行为都不一样,导致cost不一样
-
索引的预估rows不一样,Cost不一样
-
额外的一些变量因子也会导致变化
综上所述,DBdoctor的旁路优化器才是终极杀器!不管何种场景,用SQL审核功能复制粘贴SQL,可一分钟快速得出最优索引结论。
-
端午特别篇:你真的了解数据库索引吗?
-
快薅羊毛,这款企业级数据库监控诊断平台终于免费啦
-
被锁住的大象(Postgres),如何跟MySQL赛跑

DBdoctor推出长久免费版
DBdoctor是一款企业级数据库全方位性能监控与诊断平台,致力于解决一切数据库性能问题。可以对商业数据库、开源数据库、国产数据库进行统一性能诊断。具备:SQL审核、巡检报表、监控告警、存储诊断、审计日志、权限管理等免费功能,不限实例个数,可基于长久免费版快速搭建企业级数据库监控诊断平台。同时拥有:性能洞察、锁分析、根因诊断、索引推荐、SQL发布前性能评估等高阶功能,官网可快速下载,零依赖,一分钟快速一键部署。如果您想要试用全部功能可添加公众号自助申请专业版license。成为企业用户可获得产品定制、OpenAPI集成、一对一专家等高阶服务。迎添加小助手微信了解详细信息!
1️⃣ 产品介绍:
内核级数据库性能诊断工具DBdoctor
2️⃣免费下载/在线试用:
https://dbdoctor.hisensecloud.com/col.jsp?id=126


![[Java基础揉碎]网络相关概念](https://img-blog.csdnimg.cn/direct/8a4fc8c807024b4f965d8af0c1ee6648.png)