目录
一、set
1.set的介绍
2.set的使用
2.1 set的模板参数列表
2.2 set的构造
2.3 set的迭代器
2.4 set的容量
2.5 set的修改操作
2.6 set的使用举例
二、map
1.map的介绍
2.map的使用
2.1 map的模板参数说明
2.2 map的构造
2.3 map的迭代器
2.4 map的容量与元素访问
2.5 map中元素的修改
2.6 map的使用举例
三、multiset
1.multiset的介绍
2.multiset的使用
四、multimap
1.multimap的介绍
2.multimap的使用
五、OJ题练习使用
1.前K个高频单词
2.两个数组的交集
六、完结撒❀
一、set
1.set的介绍
set文档介绍
翻译:
1. set是按照一定次序存储元素的容器。2. 在 set 中,元素的 value 也标识它 (value 就是 key ,类型为 T) ,并且每个 value 必须是唯一的。set中的元素不能在容器中修改( 元素总是 const) ,但是可以从容器中插入或删除它们。3.在内部, set 中的元素总是按照其内部比较对象 ( 类型比较 ) 所指示的特定严格弱排序准则进行 排序。4. set容器通过 key 访问单个元素的速度通常比 unordered_set 容器慢,但它们允许根据顺序对子集进行直接迭代。5. set在底层是用二叉搜索树 ( 红黑树 ) 实现的。
注意:
1. 与 map/multimap 不同, map/multimap 中存储的是真正的键值对 <key, value> , set 中只放value ,但在底层实际存放的是由 <value, value> 构成的键值对。2. set 中插入元素时,只需要插入 value 即可,不需要构造键值对。3. set 中的元素不可以重复 ( 因此可以使用 set 进行去重 ) 。4. 使用 set 的迭代器遍历 set 中的元素,可以得到有序序列5. set 中的元素默认按照小于来比较6. set 中查找某个元素,时间复杂度为: log2 n7. set 中的元素不允许修改 ( 为什么 ? --- 麻烦 排序的维护,唯一性的维护,时间复杂度的维护)8. set 中的底层使用二叉搜索树 ( 红黑树 ) 来实现。
2.set的使用
2.1 set的模板参数列表

T: set
中存放元素的类型,实际在底层存储
<value, value>
的键值对。
Compare
:
set
中元素默认按照小于来比较
Alloc
:
set
中元素空间的管理方式,使用
STL
提供的空间配置器管理
2.2 set的构造
| 函数声明 | 功能介绍 |
| set(const Compare& comp = Compare(),const Allocstor& = Allocator()); | 构造空的set |
| set(InputIterator first,InputIterator last,const Compare& comp = Compare(),const Allocator& = Allocator()); | 用[first,last)区间中的元素构造set |
| set(const set<Key,Compare,Allocator>& x); | set的拷贝构造 |
2.3 set的迭代器
| 函数声明 | 功能介绍 |
| iterator begin() | 返回set中起始位置元素的迭代器 |
| iterator end() |
返回
set
中最后一个元素后面的迭代器
|
|
const_iterator cbegin()
const
|
返回
set
中起始位置元素的
const
迭代器
|
|
const_iterator cend() const
|
返回
set
中最后一个元素后面的
const
迭代器
|
|
reverse_iterator rbegin()
|
返回
set
第一个元素的反向迭代器,即
end
|
|
reverse_iterator rend()
|
返回
set
最后一个元素下一个位置的反向迭代器,
即
rbegin
|
|
const_reverse_iterator
crbegin() const
|
返回
set
第一个元素的反向
const
迭代器,即
cend
|
|
const_reverse_iterator
crend() const
|
返回
set
最后一个元素下一个位置的反向
const
迭
代器,即
crbegin
|
2.4 set的容量
| 函数声明 | 功能介绍 |
| bool empty() const | 检测set是否为空,空返回true,否则返回false |
| size_type size() const | 返回set中有效元素个数 |
2.5 set的修改操作
| 函数声明 | 功能介绍 |
|
pair<iterator,bool> insert (const value_type& x )
|
在
set
中插入元素
x
,实际插入的是
<x, x>
构成的
键值对,如果插入成功,返回
<
该元素在
set
中的
位置,
true>,
如果插入失败,说明
x
在
set
中已经
存在,返回
<x
在
set
中的位置,
false>
|
|
void erase ( iterator position )
|
删除
set
中
position
位置上的元素
|
|
size_type erase ( const
key_type& x )
|
删除
set
中值为
x
的元素,返回删除的元素的个数
|
|
void erase ( iterator first,
iterator last )
|
删除
set
中
[first, last)
区间中的元素
|
|
void swap (
set<Key,Compare,Allocator>&
st);
|
交换
set
中的元素
|
|
void clear ( )
|
将
set
中的元素清空
|
|
iterator find ( const
key_type& x ) const
|
返回
set
中值为
x
的元素的位置,没有找到返回end()
|
|
size_type count ( const
key_type& x ) const
|
返回
set
中值为
x
的元素的个数
|
2.6 set的使用举例
#include <set>
void TestSet()
{
// 用数组array中的元素构造set
int array[] = { 1, 3, 5, 7, 9, 2, 4, 6, 8, 0, 1, 3, 5, 7, 9, 2, 4,
6, 8, 0 };
set<int> s(array, array + sizeof(array) / sizeof(array[0]));
cout << s.size() << endl;
// 正向打印set中的元素,从打印结果中可以看出:set可去重
for (auto& e : s)
cout << e << " ";
cout << endl;
// 使用迭代器逆向打印set中的元素
for (auto it = s.rbegin(); it != s.rend(); ++it)
cout << *it << " ";
cout << endl;
// set中值为3的元素出现了几次
cout << s.count(3) << endl;
}二、map
1.map的介绍
map的文档介绍
翻译:
1.map是关联容器,它按照特定的次序 ( 按照 key 来比较 ) 存储由键值 key 和值 value 组合而成的元 素。2. 在 map 中,键值 key 通常用于排序和唯一的标识元素,而值 value 中存储与此键值 key 关联的内容。键值 key 和值 value 的类型可能不同,并且在 map 的内部, key 与 value 通过成员类型value_type 绑定在一起,为其取别名称为 pair: typedef pair<const key, T> value_type;3. 在内部, map 中的元素总是按照键值 key 进行比较排序的。4.map 中通过键值访问单个元素的速度通常比 unordered_map 容器慢,但 map 允许根据顺序对元素进行直接迭代 ( 即对 map 中的元素进行迭代时,可以得到一个有序的序列 ) 。5.map 支持下标访问符,即在 [ ] 中放入 key ,就可以找到与 key 对应的 value 。6.map 通常被实现为二叉搜索树 ( 更准确的说:平衡二叉搜索树 ( 红黑树 ))
2.map的使用
2.1 map的模板参数说明
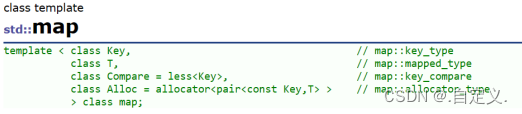
key:
键值对中
key
的类型
T
: 键值对中
value
的类型
Compare:
比较器的类型,
map
中的元素是按照
key
来比较的,缺省情况下按照小于来比
较,一般情况下
(
内置类型元素
)
该参数不需要传递,如果无法比较时
(
自定义类型
)
,需要用户
自己显式传递比较规则
(
一般情况下按照函数指针或者仿函数来传递
)
Alloc
:通过空间配置器来申请底层空间,不需要用户传递,除非用户不想使用标准库提供的
空间配置器
注意:在使用
map
时,需要包含头文件。
2.2 map的构造
| 函数声明 | 功能介绍 |
| map() | 构造一个空的map |
2.3 map的迭代器
| 函数声明 | 功能介绍 |
| begin()和end() |
begin:
首元素的位置,
end
最后一个元素的下一个位置
|
| cbegin()和cend() |
与
begin
和
end
意义相同,但
cbegin
和
cend
所指向的元素不
能修改
|
| rbegin()和rend() |
反向迭代器,
rbegin
在
end
位置,
rend
在
begin
位置,其
++
和
--
操作与
begin
和
end
操作移动相反
|
| crbegin()和crend() |
与
rbegin
和
rend
位置相同,操作相同,但
crbegin
和
crend
所
指向的元素不能修改
|
2.4 map的容量与元素访问
| 函数声明 | 功能介绍 |
|
bool empty ( ) const
|
检测
map
中的元素是否为空,是返回
true
,否则返回
false
|
|
size_type size() const
|
返回
map
中有效元素的个数
|
|
mapped_type& operator[] (const
key_type& k)
|
返回
key
对应的
value
|
问题:当
key
不在
map
中时,通过
operator
获取对应
value
时会发生什么问题?
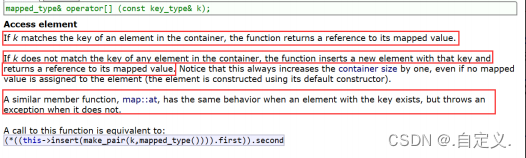
注意:在元素访问时,有一个与
operator[]
类似的操作
at()(
该函数不常用
)
函数,都是通过
key
找到与
key
对应的
value
然后返回其引用,不同的是:
当
key
不存在时,
operator[]
用默认
value
与
key
构造键值对然后插入,返回该默认
value
,
at()
函数直接抛异常
。
2.5 map中元素的修改
| 函数声明 | 功能简介 |
|
pair<iterator,bool> insert (const value_type& x)
|
在
map
中插入键值对
x
,注意
x
是一个键值
对,返回值也是键值对:
iterator
代表新插入
元素的位置,
bool
代表释放插入成功
|
|
void erase ( iterator position )
|
删除
position
位置上的元素
|
|
size_type erase ( const key_type& x )
|
删除键值为
x
的元素
|
|
void erase ( iterator first,
iterator last )
|
删除
[first, last)
区间中的元素
|
|
void swap (
map<Key,T,Compare,Allocator>&
mp)
|
交换两个
map
中的元素
|
|
void clear ( )
|
将
map
中的元素清空
|
|
iterator find ( const key_type& x
)
|
在
map
中插入
key
为
x
的元素,找到返回该元
素的位置的迭代器,否则返回
end
|
|
const_iterator find ( const key_type& x ) const
|
在
map
中插入
key
为
x
的元素,找到返回该元
素的位置的
const
迭代器,否则返回
cend
|
|
size_type count ( const
key_type& x ) const
|
返回
key
为
x
的键值在
map
中的个数,注意
map
中
key
是唯一的,因此该函数的返回值
要么为
0
,要么为
1
,因此也可以用该函数来
检测一个
key
是否在
map
中
|
2.6 map的使用举例
#include <string>
#include <map>
void TestMap()
{
map<string, string> m;
// 向map中插入元素的方式:
// 将键值对<"peach","桃子">插入map中,用pair直接来构造键值对
m.insert(pair<string, string>("peach", "桃子"));
// 将键值对<"peach","桃子">插入map中,用make_pair函数来构造键值对
m.insert(make_pair("banan", "香蕉"));
// 借用operator[]向map中插入元素
/*
operator[]的原理是:
用<key, T()>构造一个键值对,然后调用insert()函数将该键值对插入到map中
如果key已经存在,插入失败,insert函数返回该key所在位置的迭代器
如果key不存在,插入成功,insert函数返回新插入元素所在位置的迭代器
operator[]函数最后将insert返回值键值对中的value返回
*/
// 将<"apple", "">插入map中,插入成功,返回value的引用,将“苹果”赋值给该引
用结果,
m["apple"] = "苹果";
// key不存在时抛异常
//m.at("waterme") = "水蜜桃";
cout << m.size() << endl;
// 用迭代器去遍历map中的元素,可以得到一个按照key排序的序列
for (auto& e : m)
cout << e.first << "--->" << e.second << endl;
cout << endl;
// map中的键值对key一定是唯一的,如果key存在将插入失败
auto ret = m.insert(make_pair("peach", "桃色"));
if (ret.second)
cout << "<peach, 桃色>不在map中, 已经插入" << endl;
else
cout << "键值为peach的元素已经存在:" << ret.first->first << "--->"
<< ret.first->second << " 插入失败" << endl;
// 删除key为"apple"的元素
m.erase("apple");
if (1 == m.count("apple"))
cout << "apple还在" << endl;
else
cout << "apple被吃了" << endl;
}
【总结】
1. map 中的的元素是键值对2. map 中的 key 是唯一的,并且不能修改3. 默认按照小于的方式对 key 进行比较4. map 中的元素如果用迭代器去遍历,可以得到一个有序的序列5. map 的底层为平衡搜索树 ( 红黑树 ) ,查找效率比较高 O(log_2 N)6. 支持 [] 操作符, operator[] 中实际进行插入查找。
三、multiset
1.multiset的介绍
multiset文档介绍
[
翻译
]
:
1. multiset 是按照特定顺序存储元素的容器,其中元素是可以重复的。2. 在 multiset 中,元素的 value 也会识别它 ( 因为 multiset 中本身存储的就是 <value, value> 组成的键值对,因此 value 本身就是 key , key 就是 value ,类型为 T). multiset 元素的值不能在容器中进行修改 ( 因为元素总是 const 的 ) ,但可以从容器中插入或删除。3. 在内部, multiset 中的元素总是按照其内部比较规则 ( 类型比较 ) 所指示的特定严格弱排序准则进行排序。4. multiset 容器通过 key 访问单个元素的速度通常比 unordered_multiset 容器慢,但当使用迭代器遍历时会得到一个有序序列。5. multiset 底层结构为二叉搜索树 ( 红黑树 )。
注意:
1. multiset 中在底层中存储的是 <value, value> 的键值对2. multiset 的插入接口中只需要插入即可3. 与 set 的区别是, multiset 中的元素可以重复, set 是中 value 是唯一的4. 使用迭代器对 multiset 中的元素进行遍历,可以得到有序的序列5. multiset 中的元素不能修改6. 在 multiset 中找某个元素,时间复杂度为 O(log_2 N)7. multiset 的作用:可以对元素进行排序
2.multiset的使用
此处只简单演示
set
与
multiset
的不同,其他接口与
set
相同,可参考
set
。
#include <set>
void TestSet()
{
int array[] = { 2, 1, 3, 9, 6, 0, 5, 8, 4, 7 };
// 注意:multiset在底层实际存储的是<int, int>的键值对
multiset<int> s(array, array + sizeof(array) / sizeof(array[0]));
for (auto& e : s)
cout << e << " ";
cout << endl;
return 0;
}四、multimap
1.multimap的介绍
multimap文档链接
翻译:
1. Multimaps 是关联式容器,它按照特定的顺序,存储由 key 和 value 映射成的键值对 <key,value> ,其中多个键值对之间的 key 是可以重复的。2. 在 multimap 中,通常按照 key 排序和唯一地标识元素,而映射的 value 存储与 key 关联的内容。 key 和 value 的类型可能不同,通过 multimap 内部的成员类型 value_type 组合在一起,value_type 是组合 key 和 value 的键值对 :typedef pair<const Key, T> value_type;3. 在内部, multimap 中的元素总是通过其内部比较对象,按照指定的特定严格弱排序标准对key 进行排序的。4. multimap 通过 key 访问单个元素的速度通常比 unordered_multimap 容器慢,但是使用迭代器直接遍历 multimap 中的元素可以得到关于 key 有序的序列。5. multimap 在底层用二叉搜索树 ( 红黑树 ) 来实现。
注意:
multimap
和
map
的唯一不同就是:
map
中的
key
是唯一的,而
multimap
中
key
是可以
重复的
。
2.multimap的使用
multimap
中的接口可以参考
map
,功能都是类似的。
注意:
1. multimap 中的 key 是可以重复的。2. multimap 中的元素默认将 key 按照小于来比较3. multimap 中没有重载 operator[] 操作 ( 可思考下为什么 ?) 。(多个key与value没有形成映射关系)4. 使用时与 map 包含的头文件相同。
五、OJ题练习使用
1.前K个高频单词
题目:

基本思路:
使用map将所有单词出现的次数进行存储,在使用vector进行排序,再将前K个push_back到新的vector里面进行返回。
解题代码:
class Solution {
public:
struct kvCom
{
bool operator()(const pair<string,int> V1,const pair<string,int> V2)
{
return (V1.second > V2.second) || (V1.second == V2.second && V1.first < V2.first);
}
};
vector<string> topKFrequent(vector<string>& words, int k) {
map<string,int> CountMap;
for(auto& e : words)
{
CountMap[e]++;
}
//按照int排序
vector<pair<string,int>> v(CountMap.begin(),CountMap.end());
//stable_sort(v.begin(),v.end(),kvCom());
sort(v.begin(),v.end(),kvCom());
vector<string> vs;
for(size_t i=0; i<k;i++)
{
//cout<<v[i].first<<":"<<v[i].second<<endl;
vs.push_back(v[i].first);
}
return vs;
}
};2.两个数组的交集
题目:

基本思路:
通过将两个数组分别存进两个set里面(这一步也完成了去重,防止出现多个交集),再用一个vector进行存储返回,之后在其中一个set中查找是否存在另一个set中的值,若存在则push_back到vector中,循环操作,最后将vector进行返回。
解题代码:
class Solution {
public:
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> s1(nums1.begin(),nums1.end());//已经完成去重工作
set<int> s2(nums2.begin(),nums2.end());
vector<int> v;
for(auto e : s1)
{
auto ret = s2.find(e);
if(ret != s2.end())
{
v.push_back(*ret);
}
}
return v;
}
};六、完结撒❀
如果以上内容对你有帮助不妨点赞支持一下,以后还会分享更多编程知识,我们一起进步。
最后我想讲的是,据说点赞的都能找到漂亮女朋友❤