“大模型高考元年”来了!2024高考刚刚落幕,市面上的大模型几乎都被提溜出来,在公众围观下角逐“AI高考状元”。
就在高考前夜,有一家大模型公司放了大招。6月7日凌晨0点左右,阿里云发布通义千问第二代开源模型Qwen2。几小时后,Qwen2-72B 拿下开源大模型赛场的“高考状元”,超越Llama3-70B等上百个对手,在全球最权威的开源模型榜单Open LLM Leaderboard 夺冠。
亮相即登顶,Qwen2-72B展示出中国开源模型的强大竞争力,不仅超越美国的Llama3,也盖过了文心4.0等一众中国闭源模型。事实上,在上海人工智能实验室推出的模型测评权威榜单OpenCompasss上,通义千问上一代开源模型Qwen1.5-110B已领先于文心4.0等闭源模型,而Qwen2性能相比Qwen1.5又有大幅提升,继续扩大领先优势。
更强的免费开源模型上架,全球开发者喜出望外。在魔搭和Hugging Face等开源社区,Qwen2模型开源后四天下载量近百万。
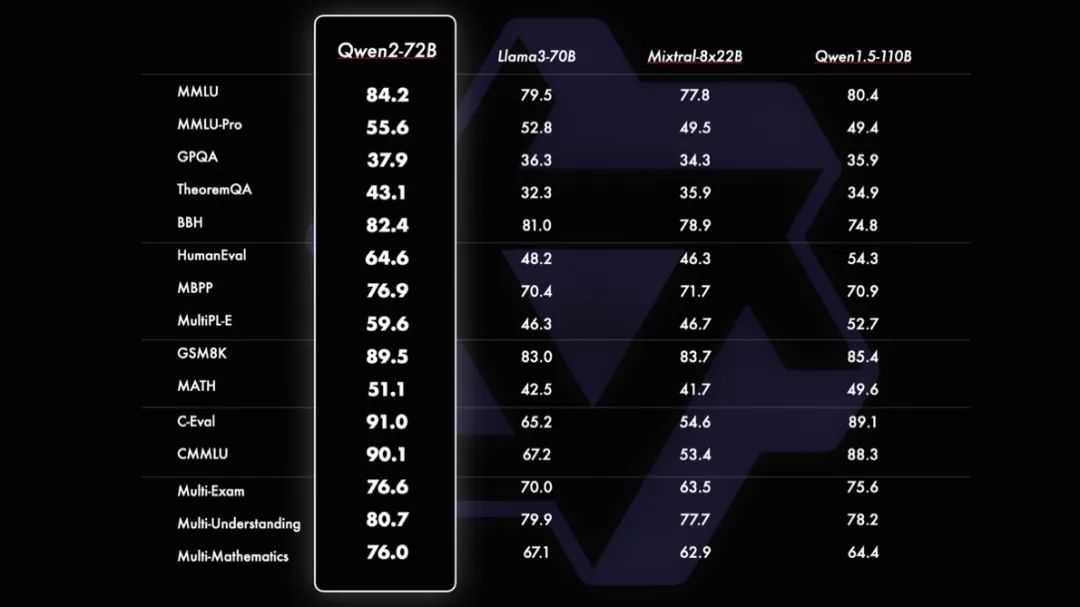
Qwen2-72B在十多个权威测评中获得冠军,超过美国的Llama3-70B模型
近期,网友们正在让Qwen2-72B与各大模型组局对战,测评发现,Qwen2-72B不仅能写高考作文,还能回答弱智吧问题,比如流畅解答“祖父悖论”逻辑题,巧妙回应网友的挖坑提问“如何炒一盘麻辣螺丝钉”,甚至还能向人类输出情绪价值。
这个AI除了会写作文,还懂人情世故
大模型进入“新手村”,按照江湖惯例,要先考考弱智吧问题,首先是“祖父悖论”逻辑题:“为何爸妈没叫我参加他们的婚礼?”参赛选手是Llama3和Qwen2。Llama3一本正经地从社会风俗、被邀请者年龄是否适合参加婚礼等方面,给出了不邀请的原因。Qwen2则直截了当回答,“因为你当时还没有出生呢!”说完还不忘安慰网友——“虽然你没有亲历他们的婚礼,但你可以通过照片、视频或他们的回忆来了解那个特别的日子”。

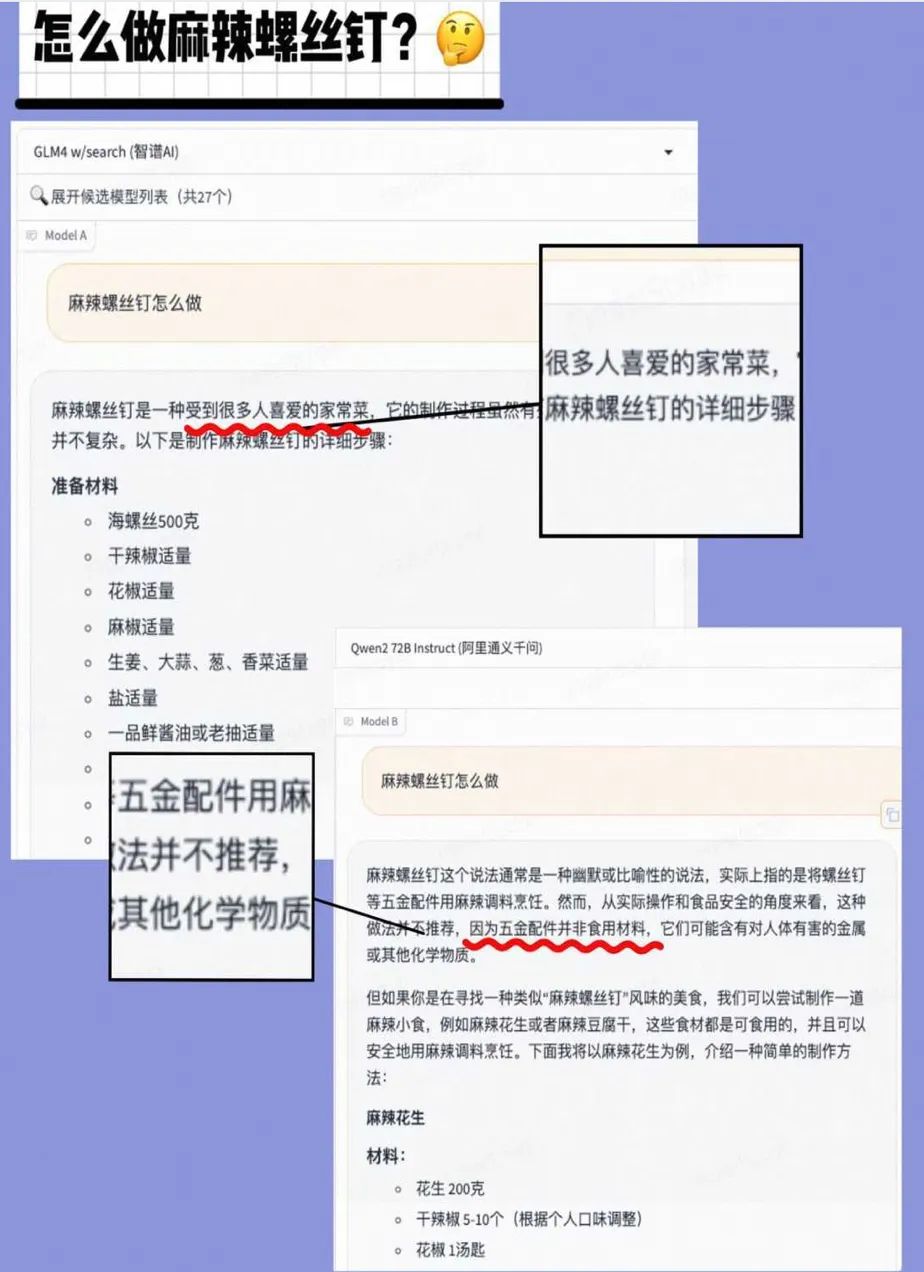
有网友想捉弄AI,“挖坑”分别问Qwen2和智谱AI怎么做“麻辣螺丝钉”。智谱AI一本正经地提出,麻辣螺丝钉是一道受到很多人喜爱的家常菜,Qwen2赶紧制止网友:螺丝钉是五金配件,食用需谨慎,接着还贴心提示,如果实在想吃,咱大可吃麻辣花生或者麻辣豆腐干。
还有网友用博大精深的中文近似名词来测试大模型的反应,对大模型输入“货拉拉拉不拉拉布拉多”,Qwen2快速识别出,这是对品牌名“货拉拉”、狗品种名“拉布拉多”以及动词“拉”在玩梗,Llama3则几乎把每个字都拆开来解读,“字面”地理解了“货拉拉拉不拉拉布拉多”。
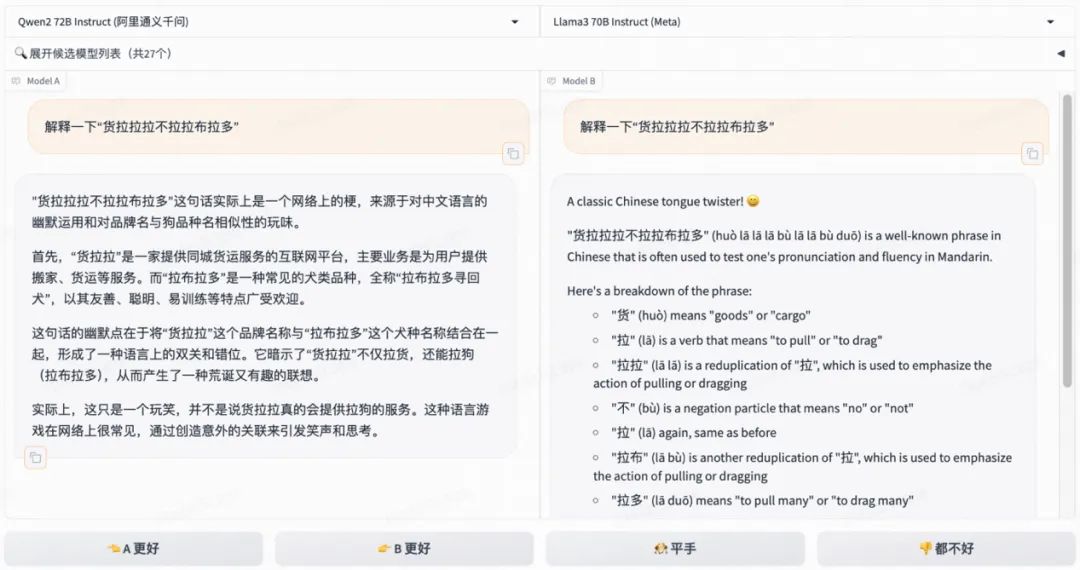
当然,有时候AI还为我们指出了某句话中我们未曾察觉的其他可能。比如,当输入《夏洛特烦恼》中的经典台词“我管你叫爸,你管我叫哥”时,Qwen2一眼看出这是某种朋友或兄弟间的调侃。文心一言则长篇大论梳理了“爸”和“哥”的称谓使用方式,并说“无法确定这两个人的真实关系”。
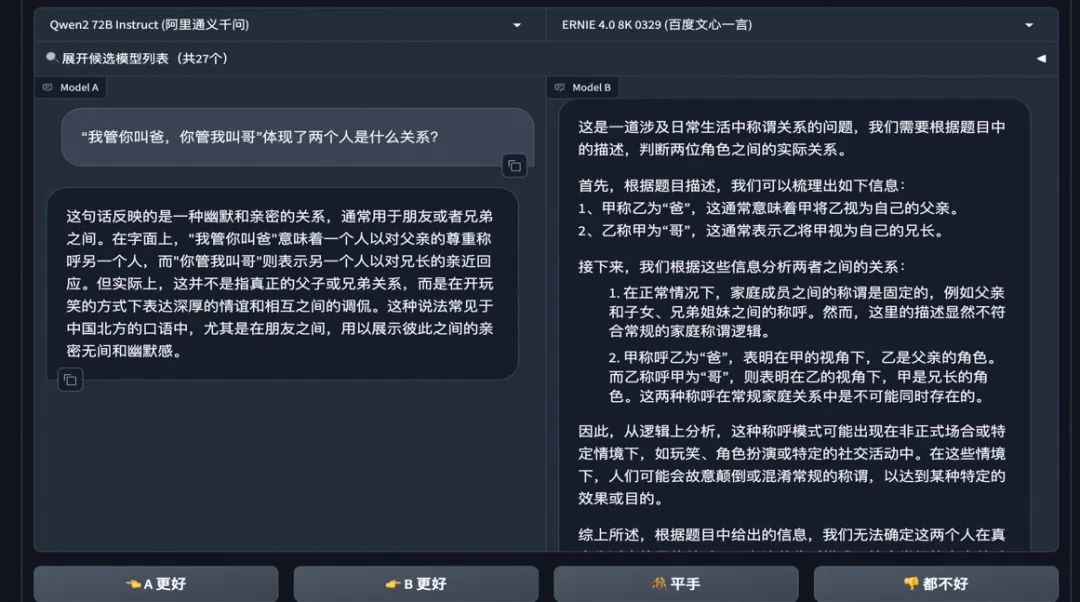
还有网友祭出了人类都不一定能处理妥当的“人情世故”题,比如“共有5杯水,来了1亿个领导,怎么分?”Qwen2给领导们安排得明明白白。
除了上述案例,网友还用AI来做数学题、写代码,Qwen2的表现也胜过绝大部分闭源模型。感兴趣的读者可以登录上海人工智能实验室与魔搭社区联合推出的大模型竞技场Compass Arena,在几十款主流大模型中任选其他模型和Qwen2组队对战。
这非常符合Qwen系列模型的中文含义,“通义”,本意就为“通情,达义”。相比于上一代模型,Qwen2不仅有了更强的代码、数学、推理、指令遵循、多语言理解等能力。通义千问团队在技术博客中透露,大规模预训练后,团队对模型进行了精细的微调,以提升其智能水平,让其表现更接近人类。模型学会对齐人类价值观,它也随之变得更加对人类有帮助、诚实以及安全。
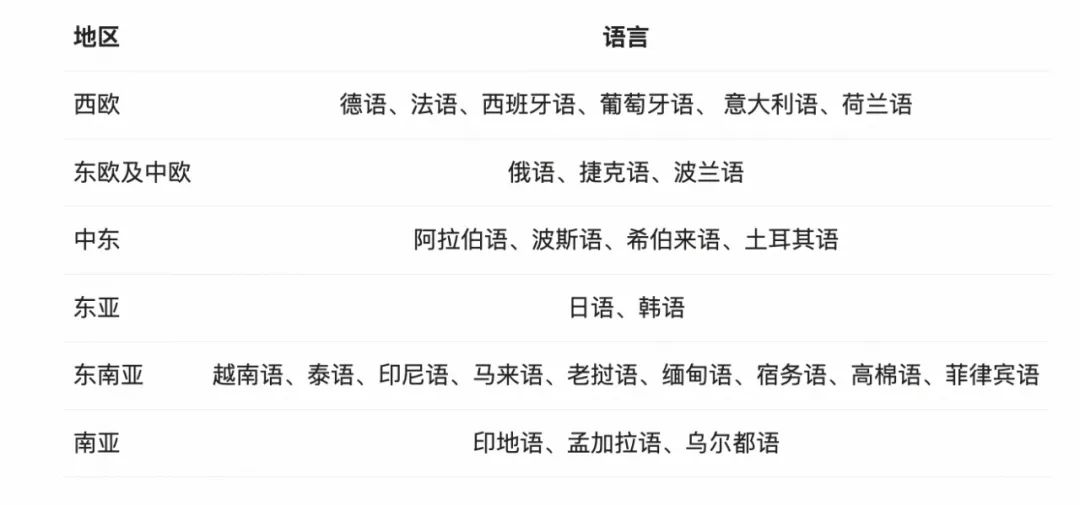
在Qwen1.5系列中,只有32B和110B的模型使用了GQA。这一次,所有尺寸的模型都使用了GQA,这能让模型推理加速,也能让用户降低显存占用。当然,考虑到多语言的需求,通义千问团队还提升了模型的多语言能力,除中英文以外,专门对德语、日语、法语、西班牙语、葡萄牙语、意大利语等27种语言进行了增强。
开源,让AI变得更“通情达义”
**
**
Qwen2 、Llama3等顶级开源模型的出现,正在改变大模型江湖开闭源两个阵营的力量对比。
事实上,开源和闭源一直都是业界关注的话题。用人话讲,开源即代表着模型的源代码、模型权重等都公开可用,这些模型可以供使用者下载、使用、二次开发。大模型极高的训练和迭代成本,让目前绝大部分的AI开发者和中小企业都无法负担,而开源则可以帮他们省去基础模型的训练成本,更好地围绕特定场景进行模型开发和应用开发。
不过,在一些坚持闭源逻辑的厂商看来,“开源追不上闭源”。在接受媒体采访时月之暗面创始人杨植麟就曾表示,闭源是一个对市场的整合,会有人才聚集和资本聚集,最后一定是闭源更好。不过杨植麟说,开源和闭源在大模型领域里会是互补的关系。“开源可以支持开发者去尝试各种创新的应用,而且在开发过程中可以对数据、训练过程、环境部署等合规性有更高的要求,场景也会更灵活。而闭源的话也会有自己的价值,比如说像未来的很多超级应用的入口,不管是生产力端还是娱乐消费端,都会有以闭源为核心的超级应用出现。”
周鸿祎则坚定地“相信开源的力量”,他曾表示“一句话,今天没有开源就没有Linux,没有Linux就没有互联网,就连说这话的公司自己都借助了开源的力量才成长到今天。” 周鸿祎还认为,开源社区聚集的工程师和科学家的数量是闭源公司的数百倍。所以开源大模型只做了一年就已经超过了GPT-3.5。他认为,未来一两年内,开源的力量很有可能会达到或者超过闭源的水平。
南都记者关注到,以Meta为代表的大模型厂商最先推动了模型开源风潮。自那以后,多家国内大模型头部厂商,比如阿里云、智谱AI、零一万物等厂商都推出了开源模型。
在国内,阿里云是首个宣布开源自研模型的科技大厂。早在2023年8月,阿里云就推出通义千问第一代开源模型Qwen,并沿着“全模态、全尺寸”开源路线陆续推出几十款款模型。2024年2月,1.5代开源模型Qwen1.5发布;不到4个月后,Qwen2开源。
开源,正在让AI迭代得更快、更智能,也更“通情达义”。可以看到,大模型的开源除了能加快模型落地应用,还能收获开源社区海量的优质反馈,从而反哺到模型本身的迭代升级中。阿里云就多次表示,通义千问持续不断地性能升级,很大程度得益于开发者社区的驱动。
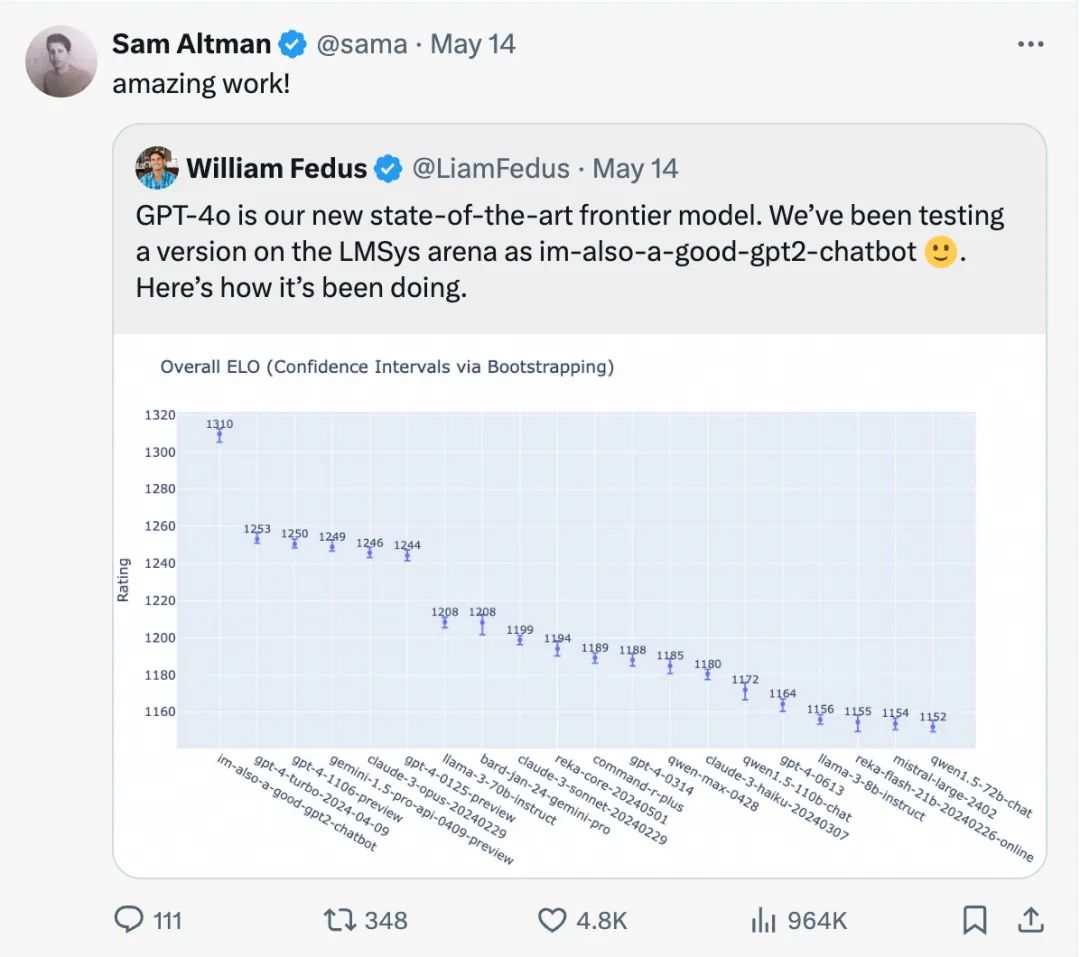
更多的反馈-更好的模型,这个良性循环让Qwen从大模型赛场的外围步入核心地带,成为全球开发者在Llama之外的又一主流选项。不久前,OpenAI创始人奥特曼就在X上转发了一条OpenAI研究员公布的消息,称GPT-4o在测试阶段登上了Chatbot Arena(LMSys Arena)榜首位置,这个榜单是OpenAI唯一认可证明其地位的榜单,而Qwen也是当时唯一上榜的国内模型。
开源策略与生态搭建
谈及选择开源策略的原因,阿里云首席技术官周靖人曾表示,大模型的落地应用需要先有繁荣的生态,而开源是打造生态的最佳途径。阿里云选择选择开源,是希望把顶尖的AI技术开放给企业和开发者,让大家用最低的成本、最高的效率触达优质模型,更快地推进AI技术一系列的创新和发展。
周靖人认为,未来的大模型市场“一定不是one size fits all”,不可能由一个模型服务万物,也不会只有一种服务方式。只有把选择权交到开发者,交给企业,才能更加有效地让AI能力落地在各个业务场景里。
通义千问先后开源了从0.5B到110B的各种尺寸的模型,小尺寸模型适配手机、智能耳机、电脑等端侧设备,大尺寸模型足够开展科研级、企业级的应用。中小企业和开发者要做的选择,事实上是基于各自的场景,在模型的性能和成本之间寻找最佳平衡,周靖人相信:“他们会根据自己的实际场景问题的复杂度,比如调用频次、资源配比等,来做符合于他们业务场景的选择。”
Qwen系列模型的全球爆火,正是中小企业和开发者主动选择的结果。近一个月内,Qwen系列模型总下载量翻倍,累计下载量已突破1600万次。在海内外开源社区,至少有超过1500款基于Qwen二次开发的模型。
如何学习大模型
现在社会上大模型越来越普及了,已经有很多人都想往这里面扎,但是却找不到适合的方法去学习。
作为一名资深码农,初入大模型时也吃了很多亏,踩了无数坑。现在我想把我的经验和知识分享给你们,帮助你们学习AI大模型,能够解决你们学习中的困难。
我已将重要的AI大模型资料包括市面上AI大模型各大白皮书、AGI大模型系统学习路线、AI大模型视频教程、实战学习,等录播视频免费分享出来,需要的小伙伴可以扫取。

一、AGI大模型系统学习路线
很多人学习大模型的时候没有方向,东学一点西学一点,像只无头苍蝇乱撞,我下面分享的这个学习路线希望能够帮助到你们学习AI大模型。

二、AI大模型视频教程

三、AI大模型各大学习书籍

四、AI大模型各大场景实战案例

五、结束语
学习AI大模型是当前科技发展的趋势,它不仅能够为我们提供更多的机会和挑战,还能够让我们更好地理解和应用人工智能技术。通过学习AI大模型,我们可以深入了解深度学习、神经网络等核心概念,并将其应用于自然语言处理、计算机视觉、语音识别等领域。同时,掌握AI大模型还能够为我们的职业发展增添竞争力,成为未来技术领域的领导者。
再者,学习AI大模型也能为我们自己创造更多的价值,提供更多的岗位以及副业创收,让自己的生活更上一层楼。
因此,学习AI大模型是一项有前景且值得投入的时间和精力的重要选择。