本专栏将介绍基于Scikit-learn(简称sklearn)的机器学习入门知识。包括但不一定限于,机器学习基本知识、sklearn库简介,基于Sklearn库的机器学习实践。
这是本专栏的第000篇,将介绍如何安装和配置sklearn环境,不仅包括Sklearn库的安装和配置,还包括本教程所用的Python开发环境——Jupyterlab软件的安装配置。
目录
0.1 sklearn简介
0.2 sklearn 的安装与配置
0.3 其他工具安装与配置
0.3.1 Jupyterlab的安装与配置
(1)安装Jupyterlab
(2)配置Jupyterlab
0.1 sklearn简介
sklearn (全称 scikit-Learn) 是一个基于 Python 语言的机器学习工具,更准确的说,它是一个专用于机器学习的Python扩展库。它建立在 NumPy, SciPy, Pandas 和 Matplotlib 之上,里面的 API 的设计非常好,所有对象的接口简单,很适合新手上路。
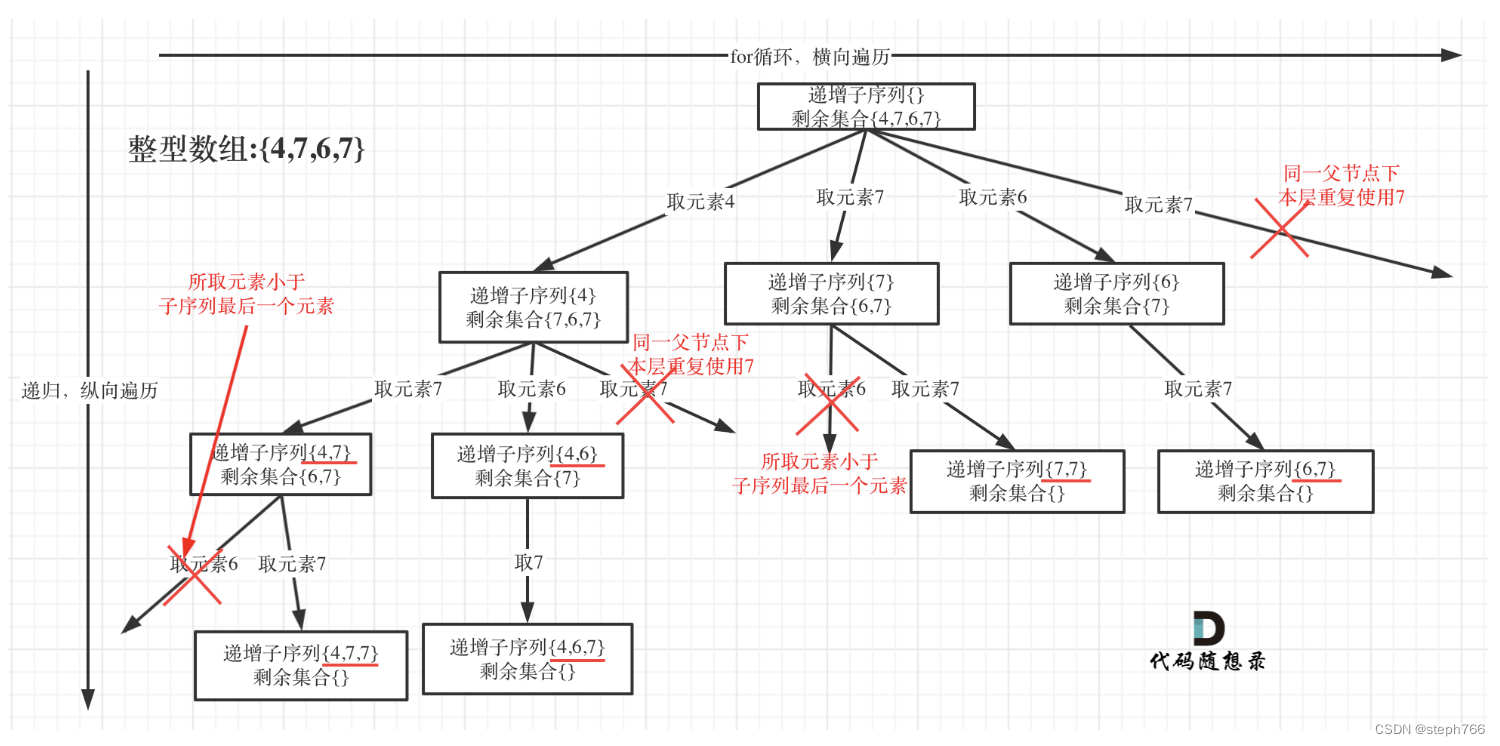
在sklearn 里面有六大任务模块:分别是分类(Classification)、回归(Regression)、聚类(Clustering)、降维(Dimensionality reduction)、模型选择(Model selection)和预处理(Preprocessing),如下图从其官网的截屏。目前最新版本为1.15(update to 2024-06)
下面从功能、应用及主要方法等方面,对这六个模块简要说明:
(1)各模块功能说明
预处理
功能:特征提取和归一化。
应用:将输入数据转换为机器学习算法适用的格式
算法:预处理、特征提取等
模型选择
功能:比较、验证和选择参数和模型。
应用:通过参数调整提高精度。
算法:网格搜索、交叉验证、度量等
分类
功能:识别对象属于哪一类(对应离散量)。
应用:垃圾邮件检测,图像识别。
算法:梯度增强、最近邻、随机森林、逻辑回归等
回归
功能:预测与对象关联的连续值属性。
应用:药物反应,股票价格。
算法:梯度增强、最近邻居、随机森林、山脊(ridge)等等
聚类
功能:无监督方法,将相似的对象自动分组到集合中。
应用:客户细分,分组实验结果。
算法:k-Means、HDBSCAN、层次聚类等
降维
功能:减少要考虑的随机变量的数量。
应用:可视化,提高效率。
算法:主成分分析(PCA)、特征选择、非负矩阵分解(NMF)等。
0.2 sklearn 的安装与配置
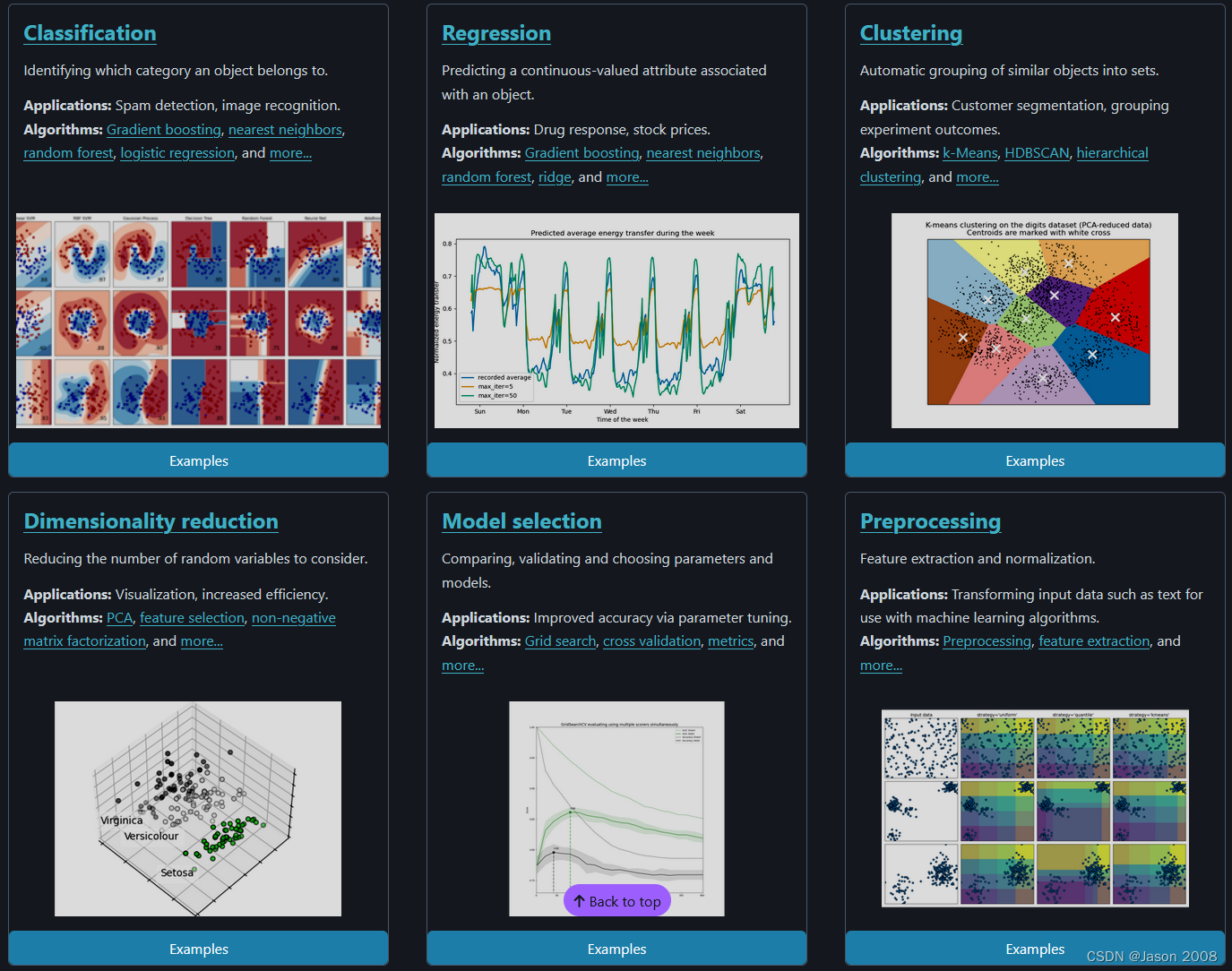
前面提到,sklearn库是scipy的一个扩展库,即sklearn会大量调用scipy库中的函数直接使用,因此,如果想正常使用sklearn,则scipy是必需提前安装的。
另外scipy库调用了numpy中的函数完成基本的数值计算,又调用了matplotlib中的函数完成绘图功能,因此,numpy和matplotlib也是必需提前安装的。
以下是这三个库功能的简要介绍:
- Numpy(Numerical Python的缩写)是一个开源的Python科学计算库。在Python中虽然提供了list容器和array模块,但这些结构并不适合于进行数值计算,因此需要借助于Numpy库创建常用的数据结构(如:多维数组,矩阵等)以及进行常用的科学计算(如:矩阵运算)。
- Scipy库是sklearn库的基础,它是基于Numpy的一个集成了多种数学算法和函数的Python模块。它的不同子模块有不同的应用,如:积分、插值、优化和信号处理等。
- matplotlib是基于Numpy的一套Python工具包,它提供了大量的数据绘图工具,主要用于绘制一些统计图形,将大量的数据转换成更加容易被接受的图表。
下图可以形象地说明以上各库的调用关系:
幸运的是,如果我们通过安装Anaconda来搭建Python运行环境时,上述各库是自动安装好的。简直不要太方便了。
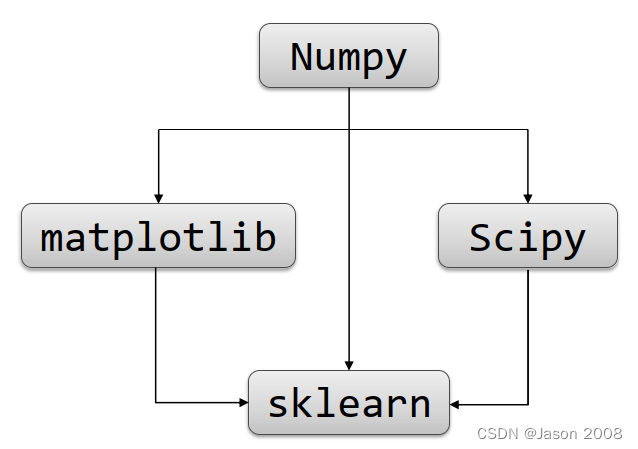
如果不放心,可以打开Anaconda Navigator,找到环境配置选项,选中“Installed”,然后在搜索框中键入“learn”,即可查询到已安装的sklearn库的信息,如下图所示:
大家有没有注意到一个细节,除了提示安装了“scikit-learn”库之外,Anaconda内还预先安装了另外一个库“scikit-learn-intelex”,看说明应该是一个专门为Intel CPU设计的用于sklearn加速的扩展库。实际应用中,并没有专门测试是否使用该库对处理速度的影响,但既然有这个库,还是建议大家优先考虑使用Intel的平台。
当然,如果确实想从纯净的Python环境下从头安装和配置sklearn环境,则建议搜索相关技术帖子。安装步骤一般是:
- 1Numpy库
- Scipy库
- matplotlib库
- sklearn库
安装方式也有两种,一种是在线的pip安装,第二种是离线的pip安装,两者的区别在于,后者先将对应版本的whl文件下载到本机指定的路径下再安装。在不能保证外网一直能够保持畅通的情况下,建议采用第二种本地安装方式。在此给出一个常用的用于下载Python扩展库对应的whl文件的下载链接:https://pypi.python.org/pypi。
相关的资料,在网上能够很方便地搜索到,在此不再赘述。
最后再啰嗦几句,如果确实想确认是否已经成功安装sklearn库,则打开Python命令行运行环境,键入以下四行命令:
import numpy
import matplotlib
import scipy
import sklcarn如果没有任何错误提示,即表示可以正常使用上述各库了。
0.3 其他工具安装与配置
由于本教程专注与机器学习基本理论和方法的sklearn实现,而不是应用,因此不是用任何IDE工具用于代码编辑和调试。在此选用了Jupyter系列中的Notebook和lab作为各类算法的开发和验证。
notebook和lab是Jupyter提供的两种功能强大的工具,两者相比,lab可以看作是notebook的增强版,因此我们最终选用Jupyter lab作为本教程主要的代码编辑工具。
当然,为了学习方便,我会讲文本、公式、图表和代码,都在本教程中一一呈现。大家可将本教程中的资料很方便地转换成Jupyter lab进行发布。
有关Jupyter lab的安装和配置文件,网上教程也很多。为了便于大家查阅,我讲自己在另外一个专栏中有关内容直接复制粘贴过来。
0.3.1 Jupyterlab的安装与配置
(1)安装Jupyterlab
首先安装某些依赖,至于这些依赖不安装有什么影响,说实话,我目前也不清楚。
sudo apt install nodejs npm接下来,安装libffi-dev,
sudo apt install libffi-dev接下来,就是本节的主角了,使用pip3安装Jupyterlab,
pip3 install jupyter jupyterlab整个过程较长,经过几分钟的等待,以及终端窗口大段的warning提醒,终于完成了Jupyterlab的安装。一定要先重启机器,目的是让系统自动改写默写Path变量。然后在命令窗口键入jupyter lab,系统会正常启动浏览器,然后就会在默认的路径下创建一个未命名的ipynb文件,并等待编辑。
看到熟悉的notebook的编辑窗口,真是感觉亲切至极。到此算是完成Jupyterlab的基本设置,但这才刚刚开始,还有更多内容等待设置,当然这些设置并不都是必需的,大家可根据个人的编程习惯,自行浏览。
(2)配置Jupyterlab
下面介绍生成Jupyterlab的配置文件,并完成修改的流程。
首先使用以下命令,生成Jupyterlab的配置文件:
jupyter lab --generate-config可使用编辑命令,修改配置文件:
nano /home/jetson/.jupyter/jupyter_lab_config.py至于设置内容,可根据个人需要自行确定,不再单独说明。
使用一下语句,添加界面对中文的支持。
pip3 install jupyterlab-language-pack-zh-CN完成中文包的安装后,即可将Jupyterlab的界面设置为中文。