1、概述
前面2篇博客给大家详细的介绍了PostgreSQL的安装和配置,本篇文章就带着大家一起学习一下PostgreSQL的用法,主要内容包括 基本的数据库操作、用户管理、数据备份、SCHEMA(模式)以及和MySQL的区别。
2、数据库基本操作
PostgreSQL是严格遵守SQL规范的,在SQL的标准实现上比MySQL更加完善,所以日常使用的语法基本上都是一样的,这里重点给大家介绍和MySQL不同的操作
2.1、登录数据库
## 默认用户登录
./psql
## 非默认用户
## psql -h ip地址 -U 用户名 -d 数据库 -p 端口
## 举例 jerry 用户 登录到 192.168.200.19 端口是 8800 数据库是 shop
psql -h 192.168.200.19 -U jerry -d shop -p 8800需要注意的是 psql指令不带参数的时候 默认的用户和数据库都是postgres
2.2、数据库操作
数据库相关操作如下
## 创建数据库
create database shop;
## 查看所有数据库
\l
## 切换当前数据库
\c shop
## 删除数据库
drop database shop 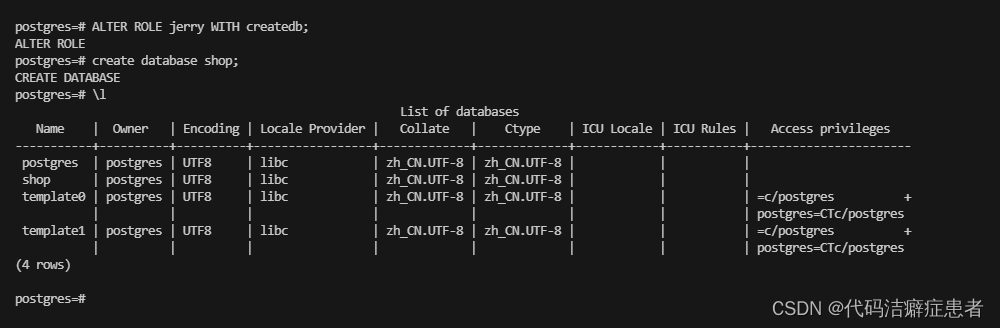
2.3、表操作
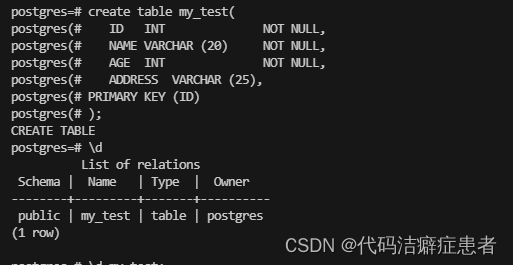
我们先准备以下脚本,然后在控制台执行
create table my_test(
ID INT NOT NULL,
NAME VARCHAR (20) NOT NULL,
AGE INT NOT NULL,
ADDRESS VARCHAR (25),
PRIMARY KEY (ID)
);
我们使用 \d 可以查看当前用户下所有的表信息,这里大家可以使用idea工具连接一下
我们可以看到这张表建到了 postgres 库的public 模式下了。
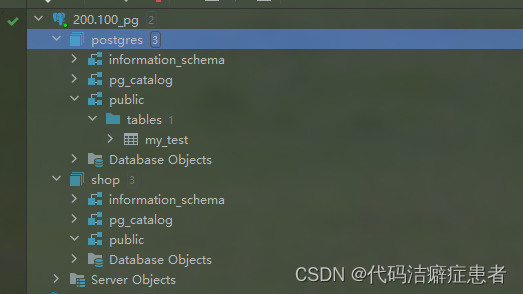
这里需要给大家说一下模式的概念,我们如果直接建表不指定Schema(模式名),就默认会在public模式下, 后续章节会给大家详细的介绍。
我们已经用postgres用户在postgres库下面新建了一张my_test 的表,这张表归属在public模式下。那么我们如果要在shop库新建表需要怎么操作呢,首先肯定需要切数据库,具体操作如下
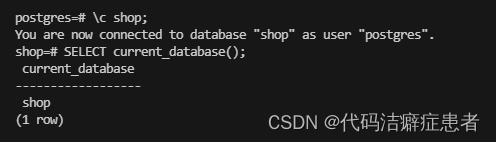
我们可以使用 \c 加数据库名 来切换数据库

这个时候我们就将这张表创建在了shop库的public模式下了。我们可以使用 \d + 表名 来查看表结构
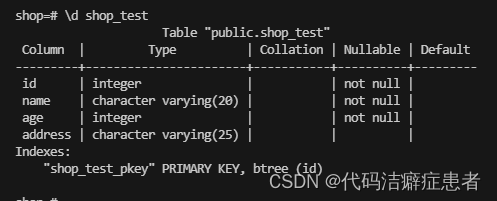
这里给大家分别介绍了数据库和表的几个基本的操作,其实 PostgreSQL大部分操作和 MySQL都是一样的,这里给大家介绍的都是和MySQL不同的几个操作,先来总结一下:
## 查看数据库
\l
## 切换数据库
\c dbName
## 查看表 和查看表结构
\d <tableName>
## 退出
\q3、用户管理
3.1、添加用户
我们先启动pg的服务,然后切换到postgres用户,使用该用户登录到pg的服务端,相关命令如下
###启动服务
./startup-pg start
## 进入bin目录
cd /usr/local/postgresql-16.3/bin
## 切换用户
su postgres
## 登录到pg
./psql
登陆成功后的界面如下所示:
下面我们来创建一个用户名叫tom的用户,并设置他的密码是tom123

返回了一个CREATE ROLE 说明这个用户创建成功了,其实我们也可以使用 CREATE ROLE指令来创建一个用户,比如我们接下来继续创建一个名为jerry的用户

也是可以的,在pg中这两条指令都可以用来创建用户,他们的区别是 CREATE USER 命令创建的用户默认带有LOGIN属性,也就是具备登录的权限
3.2、角色管理
我们上面创建了tom和jerry两个用户,我们可以使用 \du 指令来查看相关的用户信息
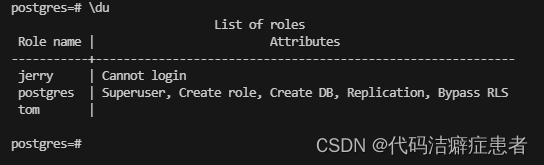
我们可以看到 jerry 这个用户后面有个属性说明 Cannot login。也就是说jerry这个用户不具备登陆的权限,我们必须要给 jerry 这个角色赋予登录的属性(权限),修改角色权限的指令我们可以使用ALTER ROLE
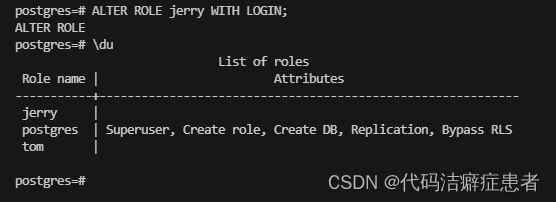
可以看到 tom和jerry两个角色都具备登录的权限了。其实在PG中用户就等价于角色加上属性(权限)。我们也可以使用ALTER ROLE去修改一个已经存在的角色的属性。我们给jerry用户添加一个创建数据的属性(权限)

下面我们登录一下 jerry 用户,相关命令如下
./psql -h 127.0.0.1 -U jerry -d shop -p 5432接着创建一个数据库 jerry_db
![]()
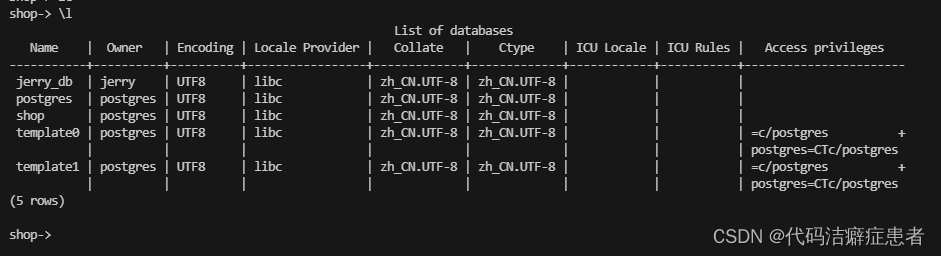
我们可以看到这个数据库的Owner 是jerry。
3.3、 对等认证
之前在使用postgres用户登录的时候我们发现直接可以使用psql 就可以了,这是因为postgreSQL有一种认证方式 peer,它允许操作系统的同名用户直接使用psql指令就能登录,但是仅限于postgreSQL安装的主机上使用,具体描述大家可参见官方文档的第21章节PostgreSQL: Documentation: 16: 21.9. Peer Authentication
我们可以在pg中创建一个 trump 的用户,不设置密码

接着我们退出psql,在主机上也创建一个trump 用户 也不设置密码
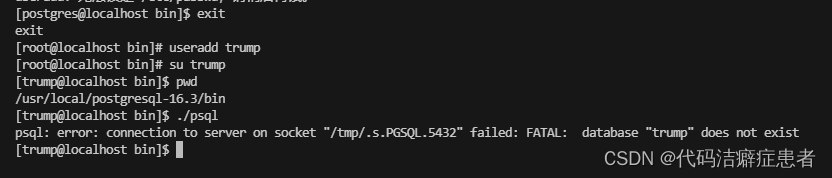
我们在切换到trump用户登录的时候发现报错了,报错信息提示 数据库 trump 不存在,好吧 这里我们需要指定具体的数据库。之所以postgres用户没报错 是因为默认有一个postgres的数据库。
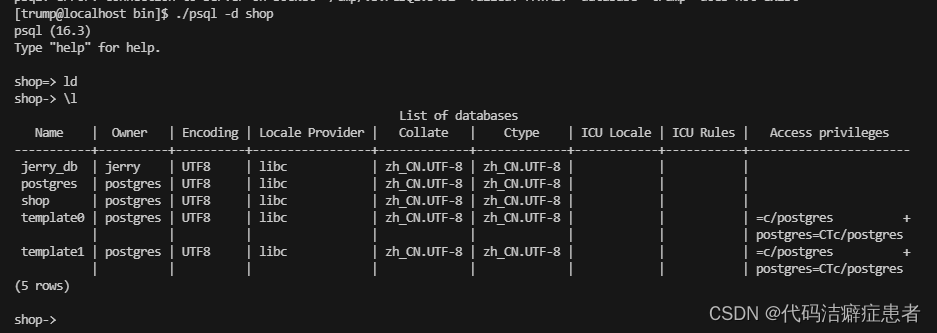
带上数据库,我们发现成功了,需要注意的是这种登录方式一般很少使用的,这里仅仅只是给大家介绍pg的一些特性,我们主要的登录方式还是通过用户名和密码登录的。
4、Schema(模式)
4.1、基本概念
在postgreSQL中有一个比较重要的概念叫 schema,官方文档中第5章节有关于模式的具体说明https://www.postgresql.org/docs/16/ddl-schemas.html
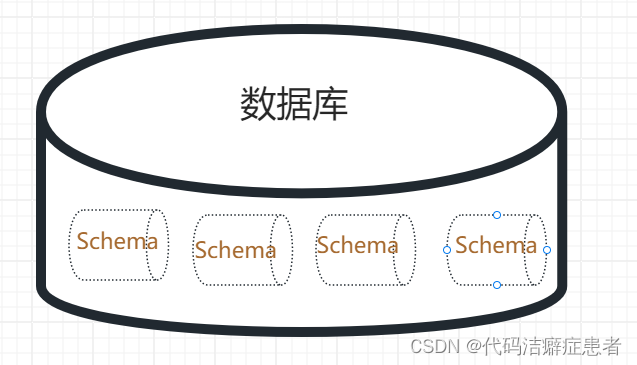
这里我个人的理解是 模式相当于数据库里面的一个逻辑上的"子数据库",我们来看官方文档上的示意,

我们从上述内容中可以知道以下几点内容
1、一个数据库可以有 一个或者多个模式
2、模式中包含了 表、数据类型、函数以及操作符
3、模式不是严格的隔离
4、一个用户可以访问它所连接的数据库下所有模式,但是需要具备对应的权限
关于这几点我们可以知道模式大概的样子应该是这样的
4.2、Schema相关操作
好了,相关的概念相信大家清楚了,下面我们来实操一下
## 创建数据库
create database tianlongbabu;
## 切换数据库
\c tianlongbabu;
## 创建模式
create schema gaibang;
create schema shaolin;
## 创建表
create table gaibang.user (
id INT NOT NULL,
user_name VARCHAR (20) NOT NULL,
age INT NOT NULL,
face_value VARCHAR (25),
PRIMARY KEY (id)
);
create table shaolin.user (
id INT NOT NULL,
user_name VARCHAR (20) NOT NULL,
age INT NOT NULL,
face_value VARCHAR (25),
PRIMARY KEY (id)
);上述命令我们新建了一个数据库 tianlongbabu 然后在这个数据库中新建了一个 gaibang 和shaolin的schema,并且分别在这两个schema里面创建了user 表。你可能会好奇同一个数据库里为什么可以创建同名表,到这里相信你也知道 肯定就是和 schema有关了。
好了 我们可以使用下面的语句查询一下schema信息
SELECT nspname AS schema_name
FROM pg_namespace
WHERE nspname !~ '^pg_' AND nspname <> 'information_schema';
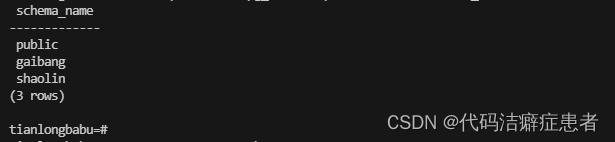
我们可以打开 idea 通过图形界面的方式查看一下
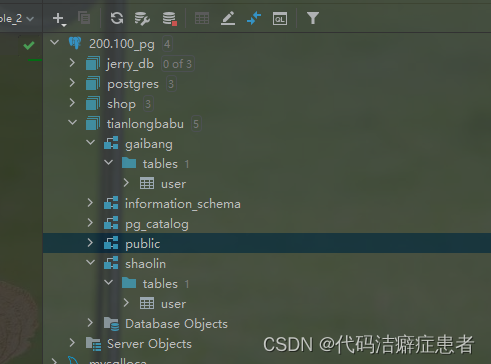
我们可以看到tianlongbabu库下面组织了4个schema,其中 shaolin和gaibang是我们自己创建的。
好了,关于schema 出现的原因 官方文档上给出了几点说明

1、允许多个用户使用一个数据库,各自使用单独的schema
2、将数据库对象组织成逻辑组,使其更易于管理。
3、第三方应用程序可以放在单独的模式中,这样它们就不会与其他对象的名称发生冲突
就类似上述案例中的gaibang和shaolin都有一个user表,我们可以创建2个用户 可以使用共同使用tianlongbabu这个数据库,两个用户使用各自的schema 这样就不回相互产生影响了。需要注意的是模式不能嵌套
4.3、相关命令总结
## 创建模式
create schema schema_name
## 删除模式
drop schema schema_name
## 删除模式并且删除该模式下的数据对象
drop schema schema_name cascade5、数据备份
数据备份是一个关系型数据库必不可少的一个功能,postgreSQL 同样也具备快速数据备份的能力。我们首先在前面创建的表中添加几条数据
INSERT INTO gaibang."user" (id, user_name, age, face_value) VALUES (1, '乔峰', 35, '100');
INSERT INTO gaibang."user" (id, user_name, age, face_value) VALUES (2, '白世镜', 45, '46');
INSERT INTO gaibang."user" (id, user_name, age, face_value) VALUES (3, '吴长青', 59, '45');
INSERT INTO gaibang."user" (id, user_name, age, face_value) VALUES (4, '康敏', 28, '50');
INSERT INTO gaibang."user" (id, user_name, age, face_value) VALUES (5, '马大元', 40, '50');
INSERT INTO gaibang."user" (id, user_name, age, face_value) VALUES (6, '宋长老', 60, '48');
INSERT INTO shaolin."user" (id, user_name, age, face_value) VALUES (1, '玄苦大师', 70, '80');
INSERT INTO shaolin."user" (id, user_name, age, face_value) VALUES (2, '虚竹', 23, '99');
INSERT INTO shaolin."user" (id, user_name, age, face_value) VALUES (3, '玄难大师', 72, '88');
INSERT INTO shaolin."user" (id, user_name, age, face_value) VALUES (4, '玄悲大师', 71, '90');
INSERT INTO shaolin."user" (id, user_name, age, face_value) VALUES (5, '扫地僧', 90, '101');
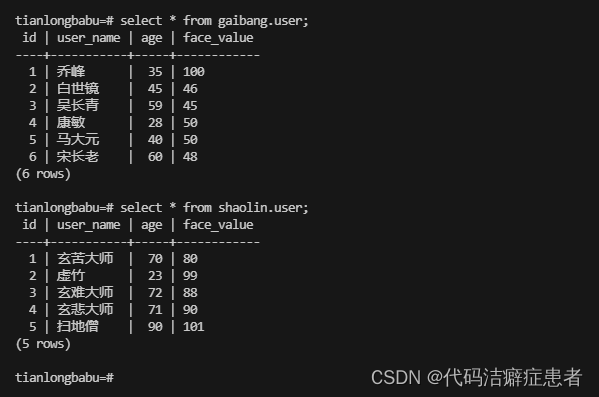
添加上述数据后 我们可以查看一下,确认无误后 我们回到主机上,我们先到安装目录的bin目录下
## 来到目录下
cd /usr/local/postgresql-16.3/bin
## 切换用户
su postgres
## 备份数据
./pg_dump tianlongbabu > tianlongbabu.sql
## 或者
./pg_dump tianlongbabu > tianlongbabu.bak这样 就可能将数据库tianlongbabu整库备份了,其中sql文件和bak文件的区别是 sql是明文,bak是压缩二进制格式的文件。备份好了之后我们就可以删掉数据库
我们删掉tianlongbabu之后 我们再来恢复
## 创建数据库
create database tianlongbabu;
## 恢复数据
./psql tianlongbabu < tianlongbabu.sql 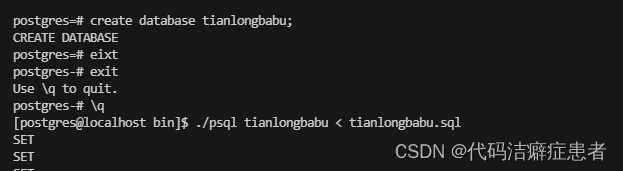
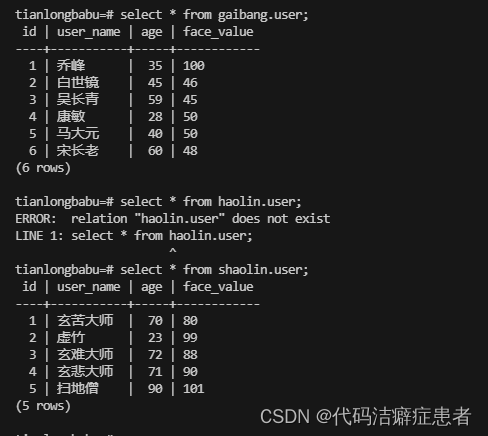
我们发现数据已经恢复了。需要注意的是命令一般只能单库备份,如果我们需要备份多个数据库我们可以使用 pg_dumpall 这个指令
6、PostgreSQL和MySQL
PostgreSQL和MySQL实现上存在很多差异,这里给大家介绍他们在组织表的方式上的差异。以下是关于这两种数据库管理系统组织表的方式的详细比对
1、PostgreSQL
- 堆表结构:
- PostgreSQL使用堆表结构来存储数据。这意味着数据按照其插入的顺序进行存储,并不按照任何特定的顺序(如主键顺序)进行排序。
- 每个文件由多个块组成,块是物理磁盘中的存储单位。块由四个主要部分组成:块头(PageHeaderData)、记录(包括Linp和Tuple)、空闲空间(Freespace)和特定数据(Special space)。
- Linp:是ItemIdData类型,长度固定,在块中从前向后分配。每个ItemIdData都记录了一个偏移,用于指向Tuple。
- Tuple:是记录的头信息,与记录本身一起构成完整的记录。记录本身长度不固定,在块中从后向前分配。
- Freespace:位于Linp和Tuple之间,用于存储未分配的空间(空闲空间)。新插入页面中的元组即对应的项标识符将从这部分空间中来分配。
- Special space:用于存放与索引方法相关的特定数据。但在普通表文件块中并没有使用,其内容被置为空。
- 表空间:
- PostgreSQL支持表空间的概念,可以将表、索引、物化视图等物理对象进行分组并存储到不同的物理位置,从而提升I/O能力。
2、MySQL(InnoDB存储引擎)
- 索引组织表:
- 在InnoDB存储引擎中,表都是根据主键顺序组织存放的,这种存储方式的表称为索引组织表。
- 如果在创建表时没有显式定义主键,InnoDB存储引擎会按照一定规则选择或创建主键。
- 逻辑存储结构:
- InnoDB存储引擎的逻辑存储结构包括表空间、段(segment)、区(extent)和页(page)。
- 表空间:所有数据都被逻辑地存放在一个表空间中。
- 段:表空间由各个段组成,常见的段有数据段、索引段、回滚段等。
- 区:在任何情况下每个区的大小都为1MB。InnoDB存储引擎一次从磁盘申请4-5个区,以保证区中页的连续性。
- 页:页是InnoDB磁盘管理的最小单位,默认每个页的大小为16KB。B+树索引本身并不能找到具体的一条记录,能找到的只是该记录所在的页。
- 存储引擎:
- MySQL支持多种存储引擎,每种存储引擎都有其独特的组织表的方式。InnoDB是其中最常用的存储引擎之一,它采用索引组织表的方式。
总结来说,PostgreSQL和MySQL在组织表的方式上存在明显的差异。PostgreSQL使用堆表结构,并通过表空间的概念提供了灵活的物理存储管理。而MySQL(InnoDB存储引擎)则采用索引组织表的方式,将数据按照主键顺序进行存储,并通过逻辑存储结构(表空间、段、区和页)来管理数据。
相信大家已经了解到了这两款数据库底层组织表的方式以及使用的数据结构了,至于具体的选型大家可以根据自己的业务场景进行综合评估。本次教程就先到这里了,希望对大家有所帮助



![[大模型]LLaMA3-8B-Instruct langchain 接入](https://img-blog.csdnimg.cn/direct/ab2289e479c24db7b3613655e9adb73d.png#pic_center)