文章目录
- 一、语言模型
- 1、概念
- 2、预训练语言模型
- 3、NLP
- 4、benchmark
- 1)概念
- 2)GLUE
- 5、TPU
- 6、语料
- 二、神经网络
- 1、概念
- 2、训练神经网络
- 3、案例:word2vec
- 3、RNN(循环神经网络)
- 4、GRU
- 5、LSTM(长短时记忆网络)
- 6、双向RNN
- 4、CNN(卷积神经网络)
- 三、迁移学习
一、语言模型
1、概念
- 语言模型是一种用来评估语句或文本出现概率的统计模型。
- 它通常用来预测给定一段文本中下一个词或字符是什么,或者评估一个句子的流畅度和合理性。
- 语言模型在自然语言处理领域被广泛应用,包括机器翻译、语音识别、文本生成等任务中。常见的语言模型包括基于规则的模型、n-gram模型、神经网络模型等。
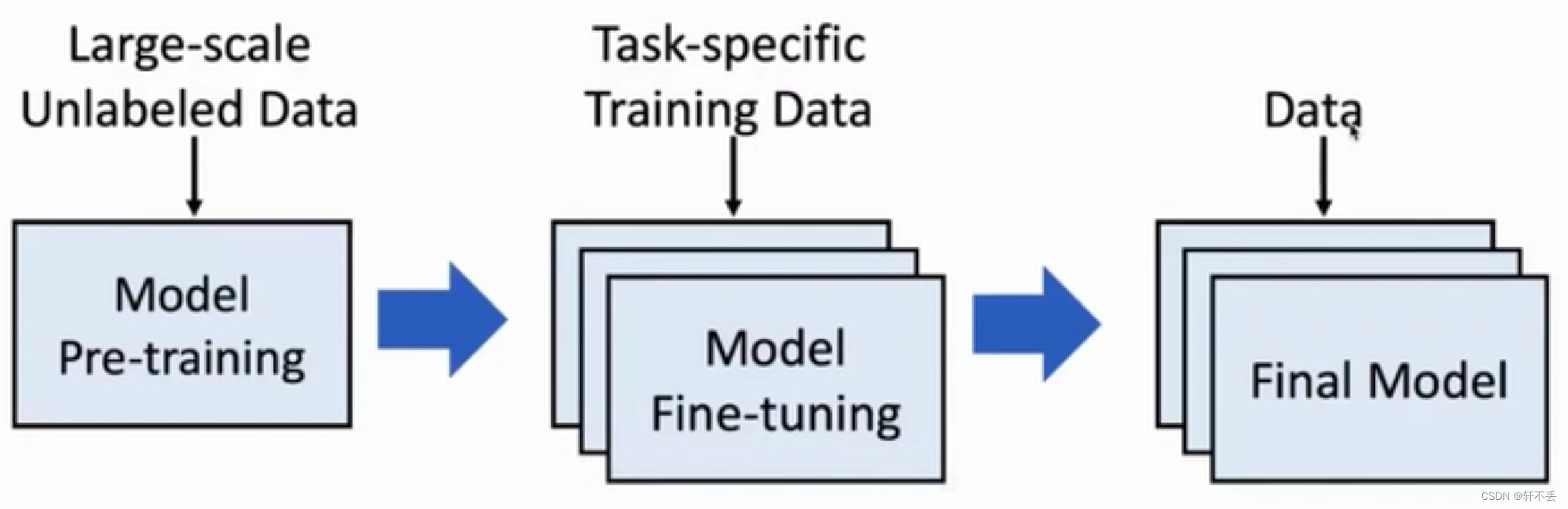
2、预训练语言模型
- 预训练语言模型是指在大规模文本数据集上进行预训练的神经网络模型,旨在通过学习文本数据中的语言规律和语义信息,从而获得对自然语言的深层理解和表示。
- 这些预训练语言模型可以用于各种自然语言处理任务,如文本分类、命名实体识别、情感分析等。
- 常见的预训练语言模型包括BERT、GPT、RoBERTa、XLNet等。这些模型的出现极大地推动了自然语言处理领域的发展,带来了许多突破性的成果。
- 大量无监督数据预训练——任务相关数据适配——得到最后模型
3、NLP
- NLP(Natural Language Processing,自然语言处理)是人工智能领域的一个重要分支,旨在使计算机能够理解、解释和生成人类语言。
- NLP技术涉及从文本数据中提取信息、理解语义、进行文本分类、情感分析、机器翻译、问答系统等任务。NLP技术的发展使得计算机可以更好地与人类进行交流和交互,例如智能语音助手、自然语言对话系统等应用。
- 预训练语言模型的出现进一步推动了NLP技术的发展,为实现更加智能和自然的语言处理应用提供了更为强大的基础。
4、benchmark
1)概念
- Benchmark(基准测试)通常用于评估和比较不同系统、算法或模型在特定任务上的性能。在机器学习和人工智能领域,benchmark通常用于衡量模型在各种任务上的表现,以便研究人员可以比较它们的性能,并确定最佳模型或方法。
- 常见的benchmark包括自然语言处理中的GLUE、SuperGLUE、图像识别中的ImageNet、语音识别中的LibriSpeech等。
- 通过参与benchmark测试,研究人员可以更好地了解他们的模型在现实任务中的表现,并推动领域内的进步和创新。
2)GLUE
- GLUE(General Language Understanding Evaluation)是一个用于评估自然语言处理模型在多个任务上表现的benchmark。
- 它由一系列针对语义理解和推理能力的任务组成,包括文本匹配、情感分类、自然语言推理等。
- GLUE的目标是提供一个统一的框架,使研究人员能够比较不同模型在各种自然语言理解任务上的性能。
- GLUE benchmark已经被广泛应用于评估各种预训练语言模型的性能,如BERT、RoBERTa、ALBERT等。
- 通过GLUE测试,研究人员可以更全面地了解模型在不同任务上的表现,为自然语言处理领域的发展提供重要参考。
5、TPU
- TPU(Tensor Processing Unit,张量处理单元)是由谷歌公司设计的专用于加速人工神经网络训练和推断的硬件加速器。
- TPU针对深度学习工作负载进行了优化,具有高效的矩阵乘法运算能力和低功耗特性,能够提供比传统CPU和GPU更高的性能。
- TPU通常用于加速谷歌的机器学习任务,如训练大规模的神经网络模型、进行推理和预测等
- 。谷歌还提供了云端TPU服务,使开发者能够在谷歌云平台上利用TPU来加速他们的深度学习任务。
- TPU的出现极大地推动了深度学习技术的发展,加速了人工智能应用的部署和发展。
6、语料
-
语料(corpus)是指用于语言研究、语言学习、自然语言处理等领域的大量文本数据集合。语料是研究语言现象和进行文本分析的基础,可以包括书籍、文章、对话、新闻、博客、社交媒体内容等各种形式的文本数据。
-
语料可以是标注的(annotated)或未标注的(unannotated),标注语料通常包含额外的语言信息,如词性标注、实体识别、句法分析等,以帮助进行语言学研究或训练机器学习模型。未标注语料则只包含原始文本数据,需要进行预处理和分析后才能应用于具体任务。
-
在自然语言处理领域,语料库是训练和评估文本处理模型的关键资源。通过对大规模语料进行处理和分析,可以帮助模型学习语言规律、建立词汇表征,并在各种文本相关任务中取得更好的性能。
-
语料的规模和质量对于自然语言处理任务的效果有重要影响。通常,更大规模、更多样化的语料库可以帮助模型更好地理解语言多样性和语境。因此,构建和维护高质量的语料库对于促进自然语言处理技术的发展至关重要。
二、神经网络
1、概念
-
一个神经元
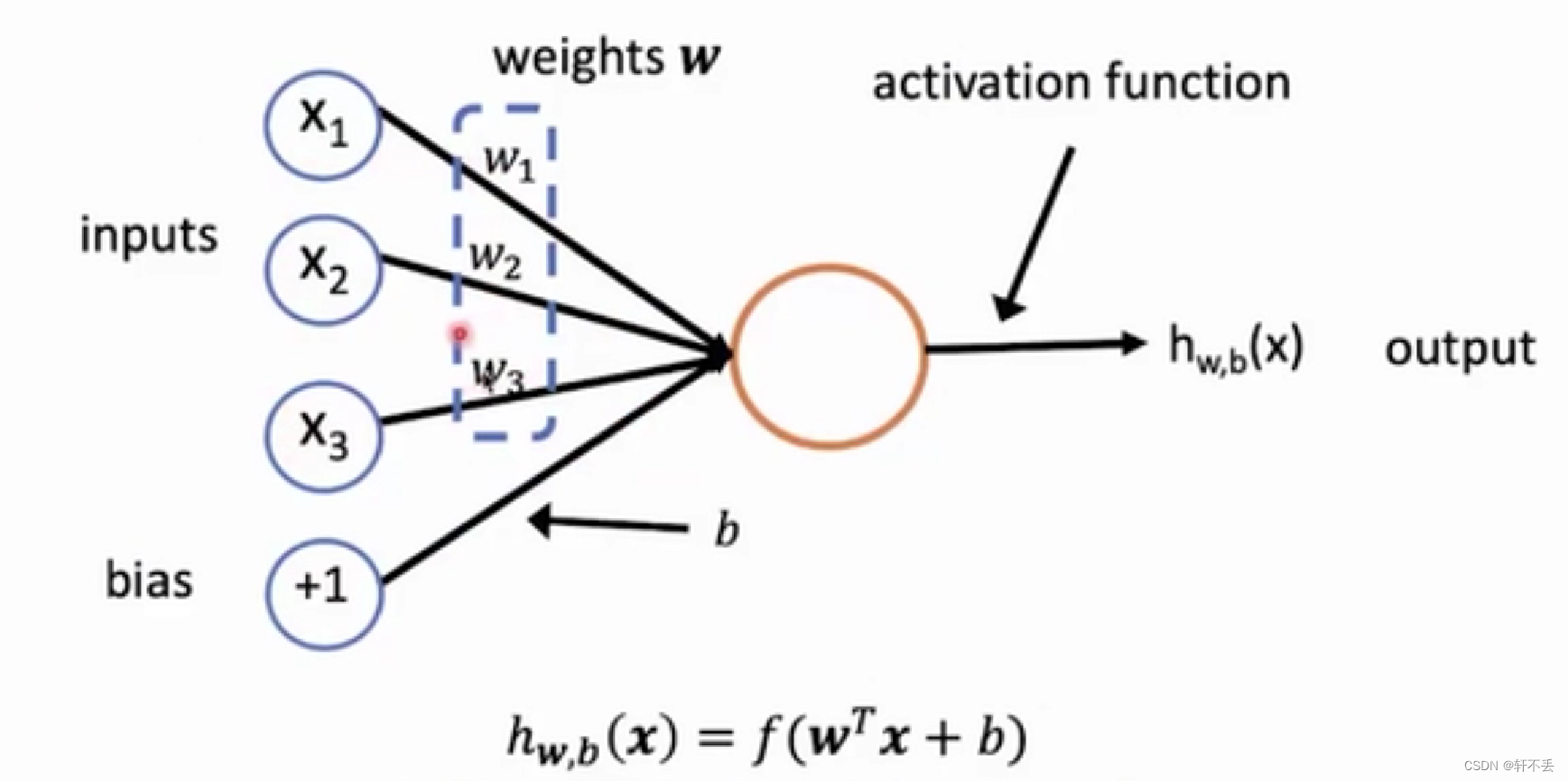
-
多个神经元(单层)

-
多层神经元
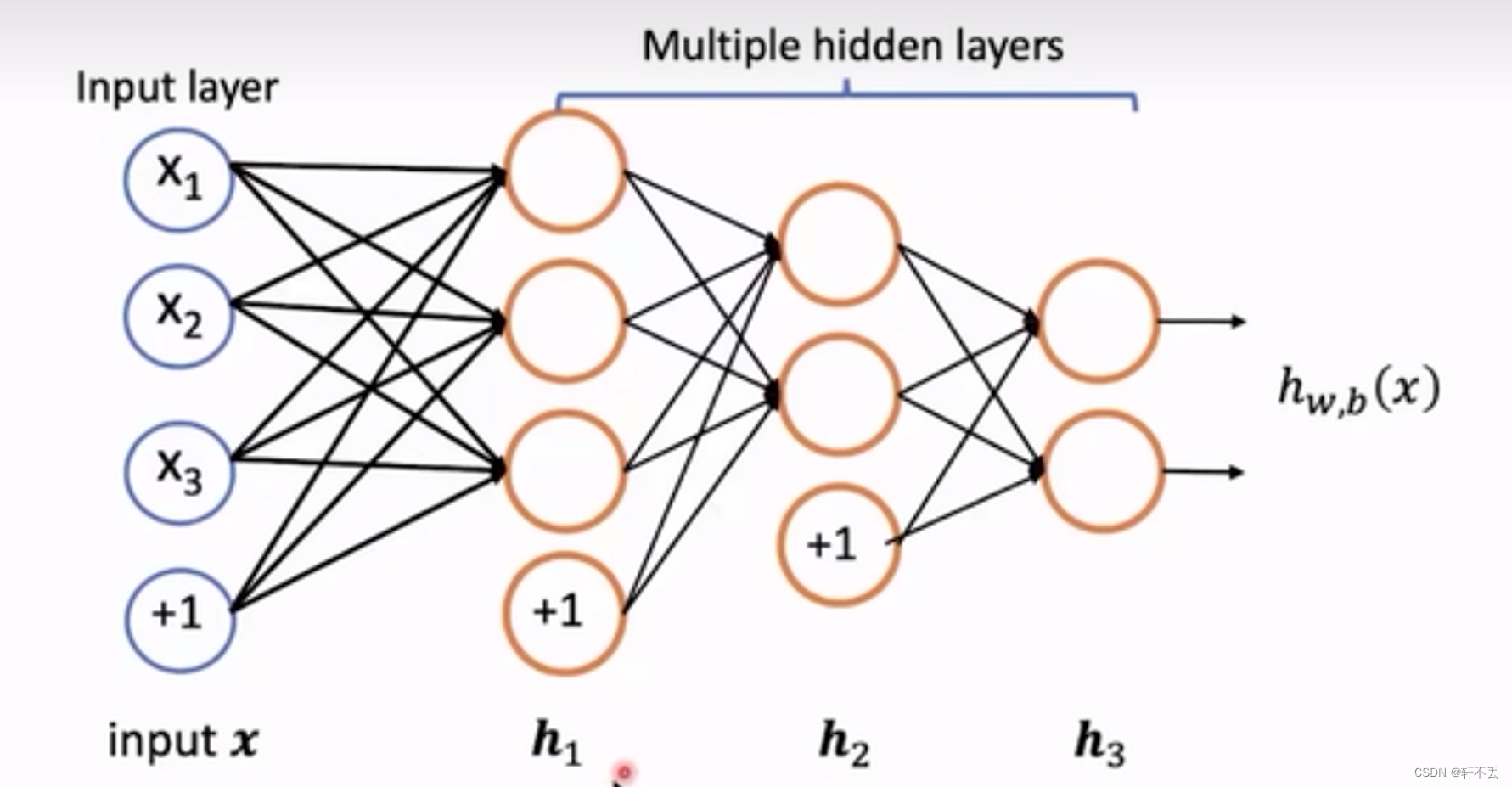
-
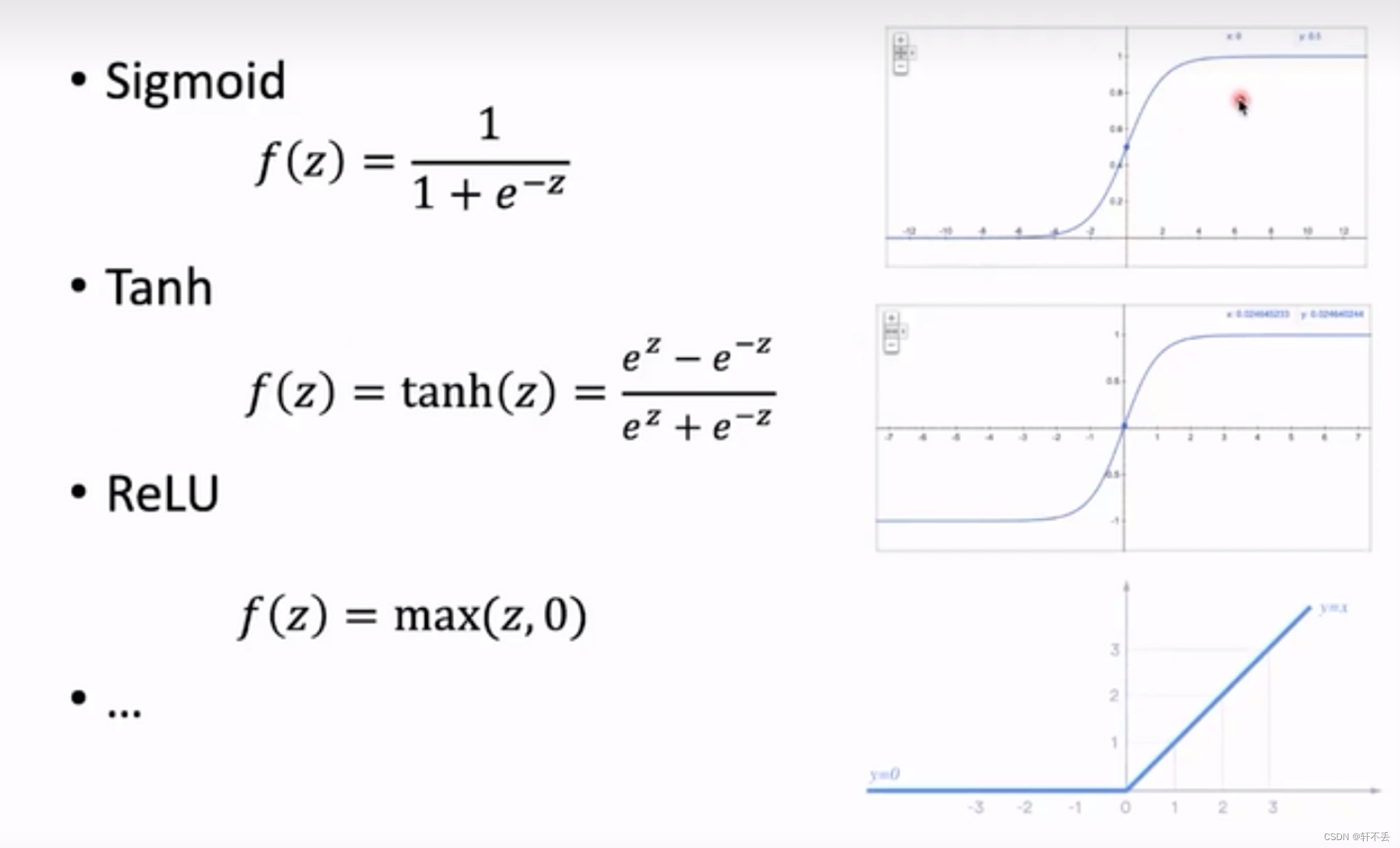
如果没有激活函数,则每一层的操作只是对上一层的输出进行一个线性变换,则本质上多层神经网络都用一层就可以表示,即多层神经网络和单层表达能力是一致的。
-
因此引入非线性的激活函数是为了防止多层神经网络塌缩成单一的神经网络。从而增加表达能力,拟合更复杂的函数

- 常见激活函数
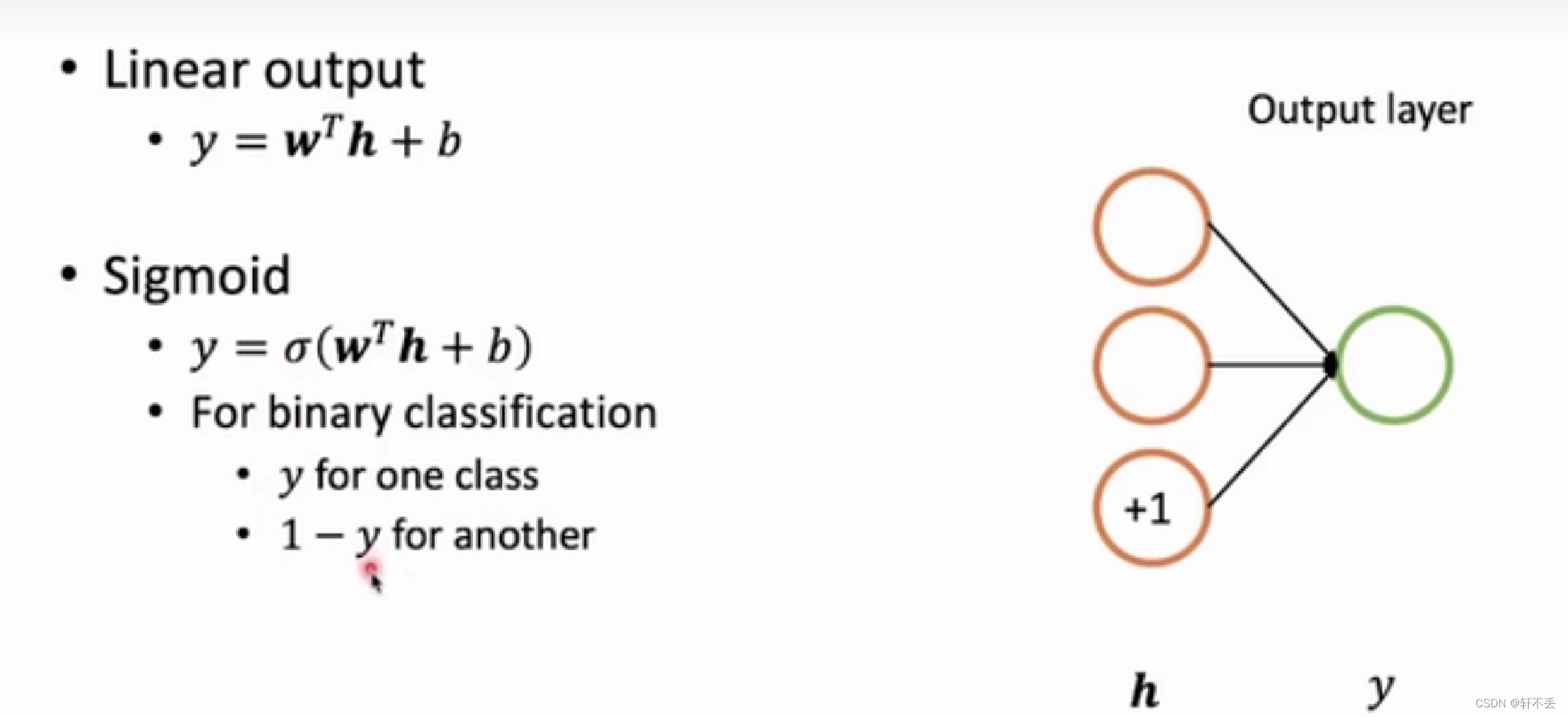
- 输出层的形态取决于想要什么数据:
- 回归问题:线性输出
- 二分类问题:sigmoid(输出在0-1之间)
- 多分类问题:softmax(如下图,一个分类在所有分类中占比)
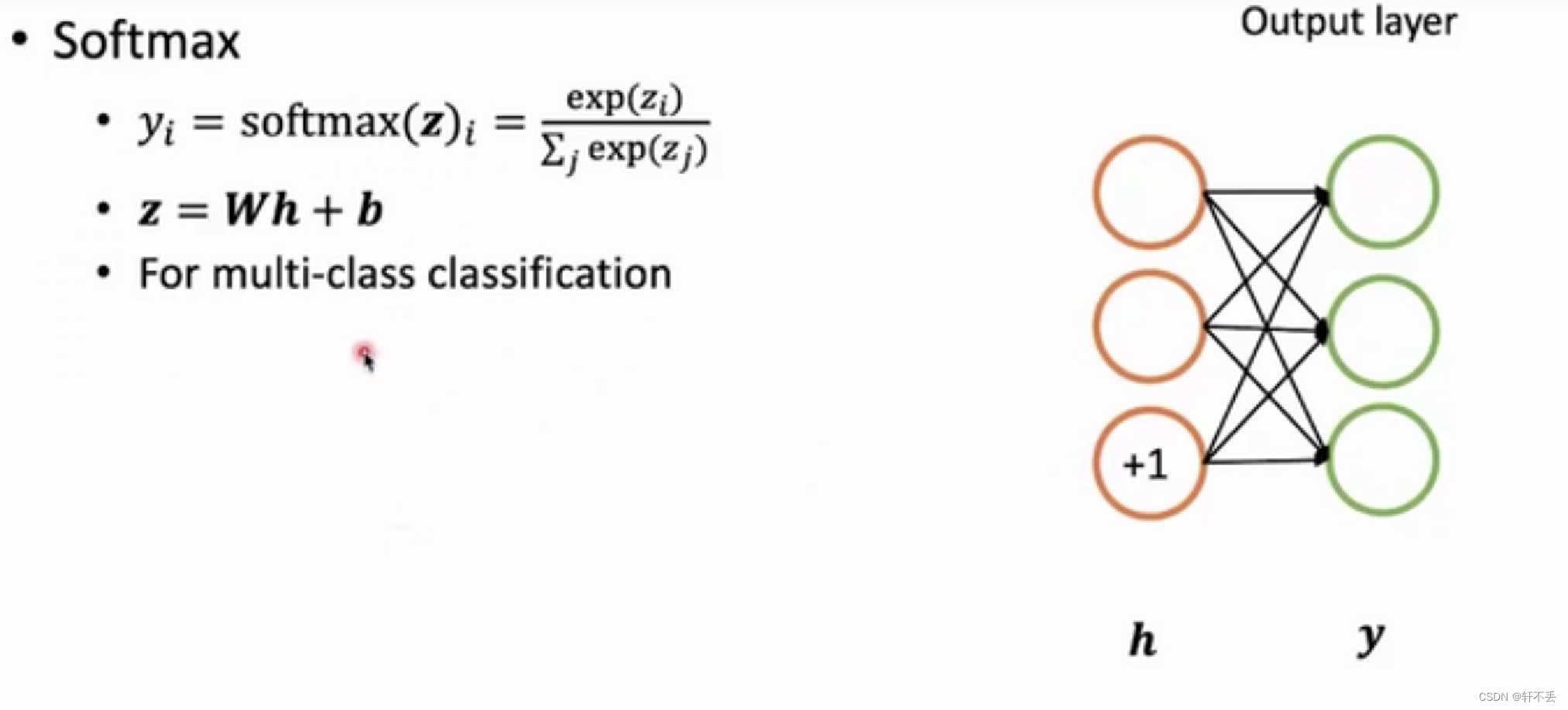
2、训练神经网络
- 首先需要设定目标(哪类问题),得到对应的损失函数,降低损失函数的值对目标不断进行调整。
- 回归问题:降低均方差
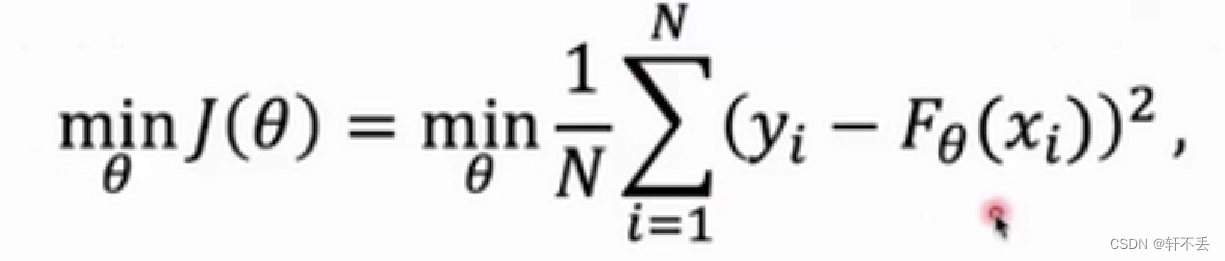
- 分类问题:最小化交叉熵

- 回归问题:降低均方差
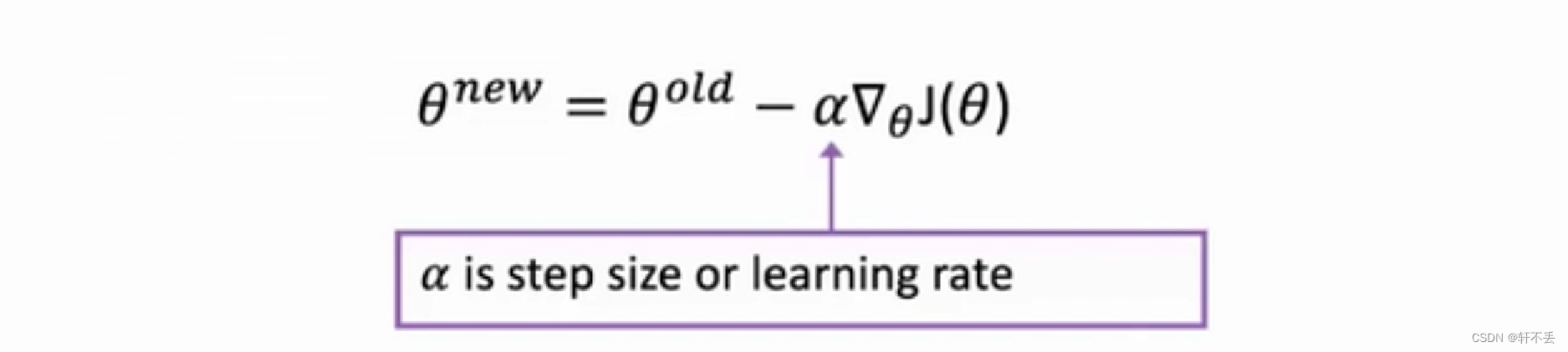
- 最小化损失函数:梯度下降
-
梯度即对损失函数进行单位大小改动时变化最快的一个方向( α \alpha α为学习率,即一次迈多大步长)
-
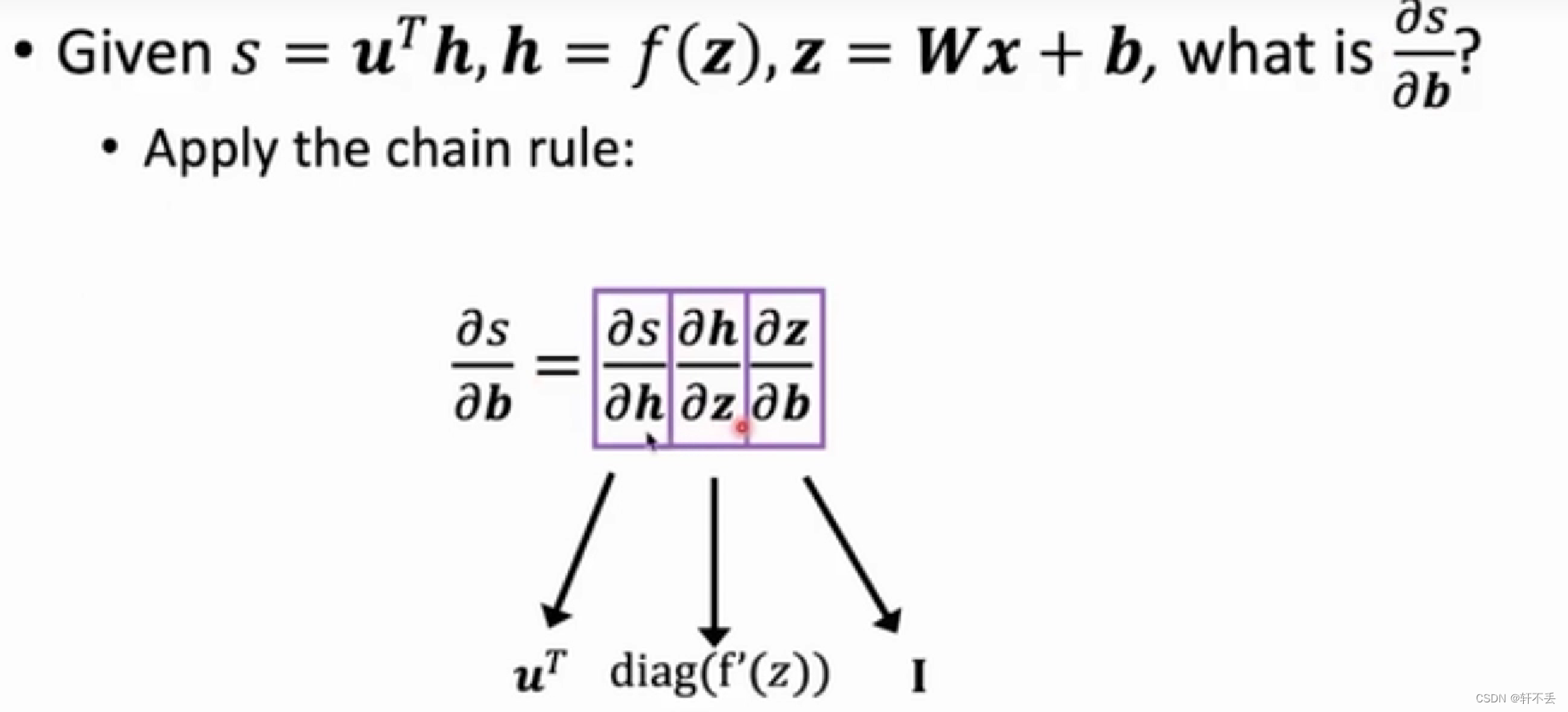
求每个参数对于损失函数的梯度


-
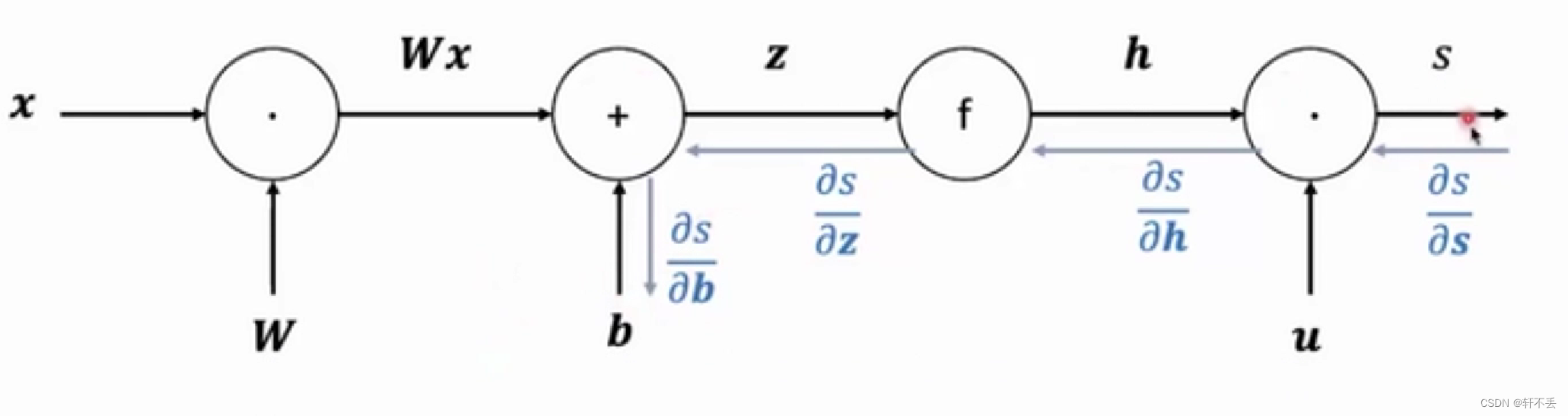
- 利用链式法则求解梯度
- 反向传播求解梯度
3、案例:word2vec
-
Word2Vec是一种用于自然语言处理的技术,它可以将单词映射到一个高维向量空间中。
-
Word2Vec模型的核心思想是通过训练神经网络,将单词表示为密集的向量,使得在向量空间中相似含义的单词在距离上更接近。这种表示方式有助于捕捉单词之间的语义和语法关系,可以用于词义相似度计算、文本分类、信息检索等任务。
-
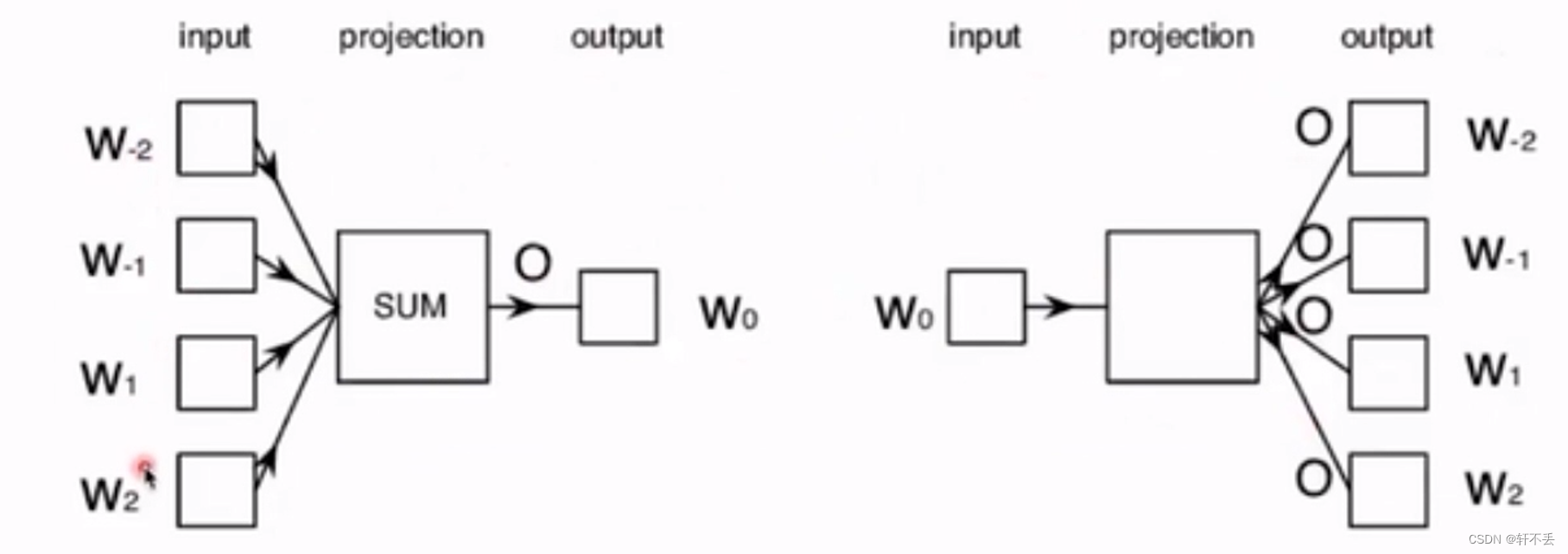
Word2Vec模型有两种经典的实现方式:Skip-gram和CBOW(Continuous Bag of Words)。
-
Word2Vec利用滑动窗口构造训练数据,一个滑动窗口是在一段文本中连续出现的几个单词,窗口中最中间的词是target,即目标词。其他词称为context,即上下文词。
-
Skip-gram模型通过目标词来预测其周围的上下文单词,而CBOW则是通过上下文单词来预测目标单词。这两种模型在训练过程中都可以学习到单词的向量表示。
-
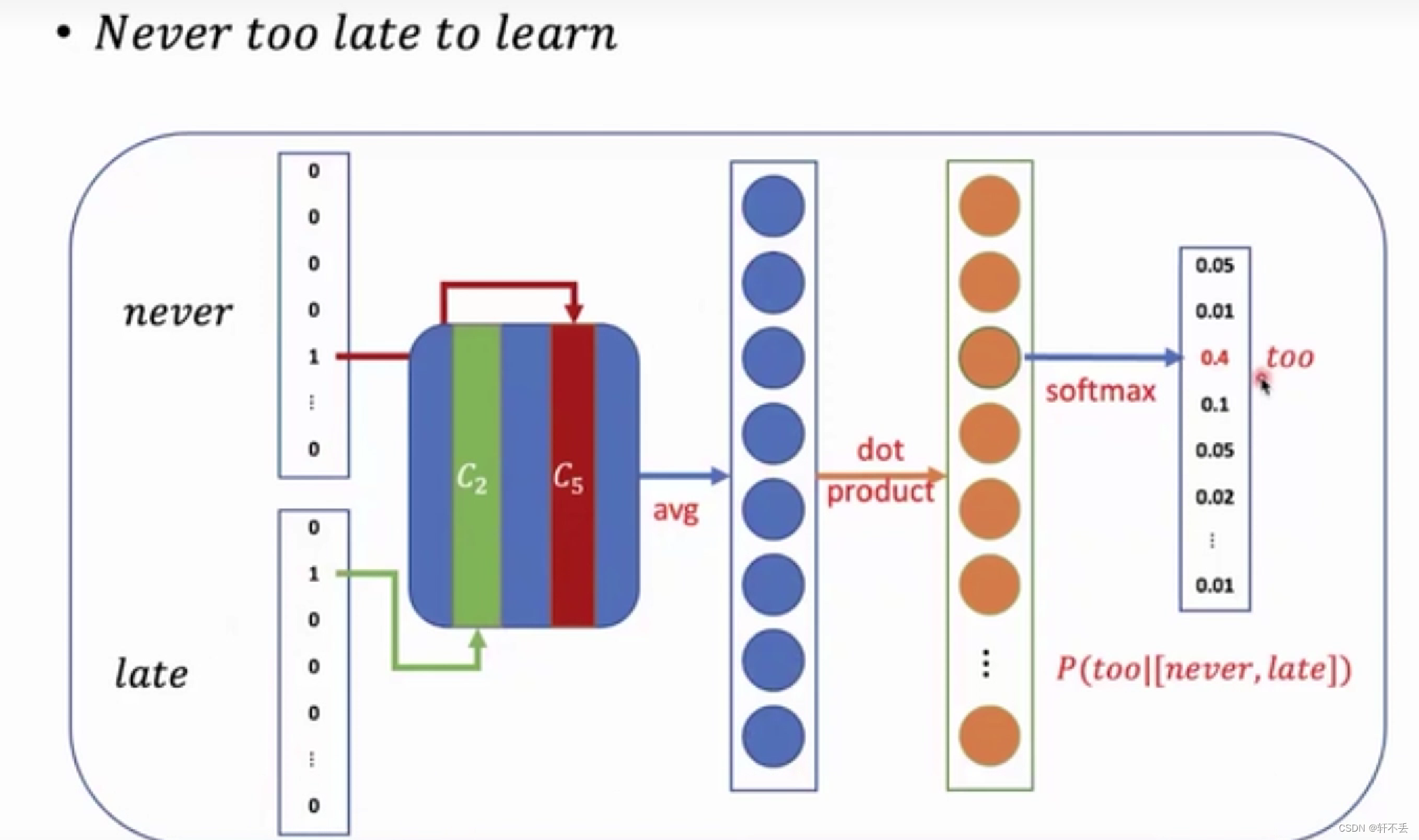
CBOW:输入采用one-hot模型(不同单词在向量只有一个维度有值且为1),输出采用n分类
-
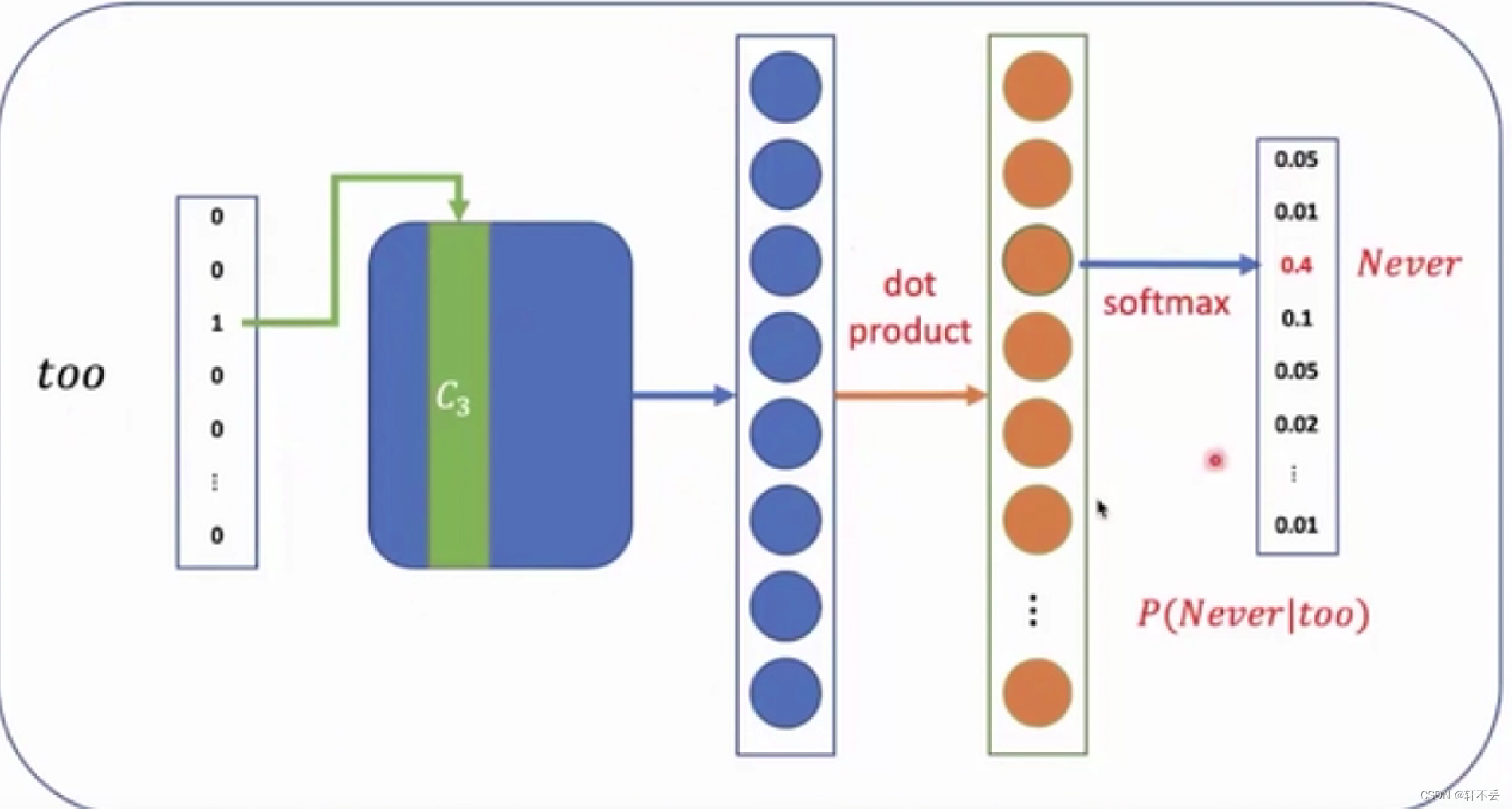
Skip-gram:输入即一个词,输出取前n个相关的词
-
问题,若词汇量过大,one-hot分维度会导致计算量过大,采用负采样或分层softmax进行优化。
-
类似还有其他优化,比如非固定滑动窗口(越靠近target的context应该是更相关的)
3、RNN(循环神经网络)
- 循环神经网络(Recurrent Neural Network,RNN)是一种专门用于处理序列数据的神经网络结构。
- 与传统的前馈神经网络不同,循环神经网络具有循环连接,可以在网络内部保持状态信息,从而能够更好地处理序列数据的特性,如自然语言、时间序列等。
- 在RNN中,每个时间步的输入不仅取决于当前时刻的输入,还取决于上一时刻的隐藏状态,这使得RNN可以对序列数据中的时间信息进行建模。通过不断更新隐藏状态,RNN可以在处理序列数据时保留之前的信息,并在后续时间步中利用这些信息。
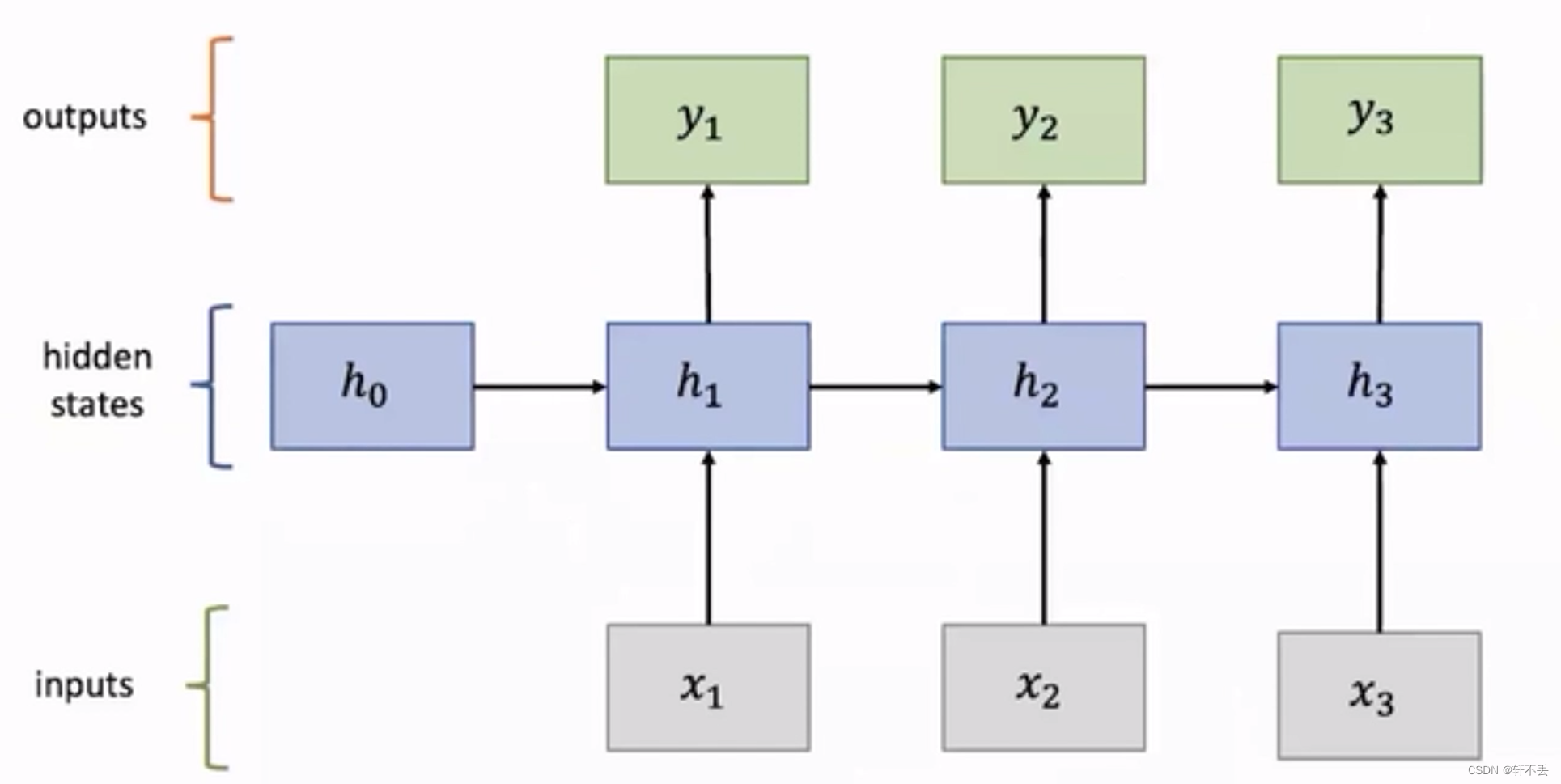
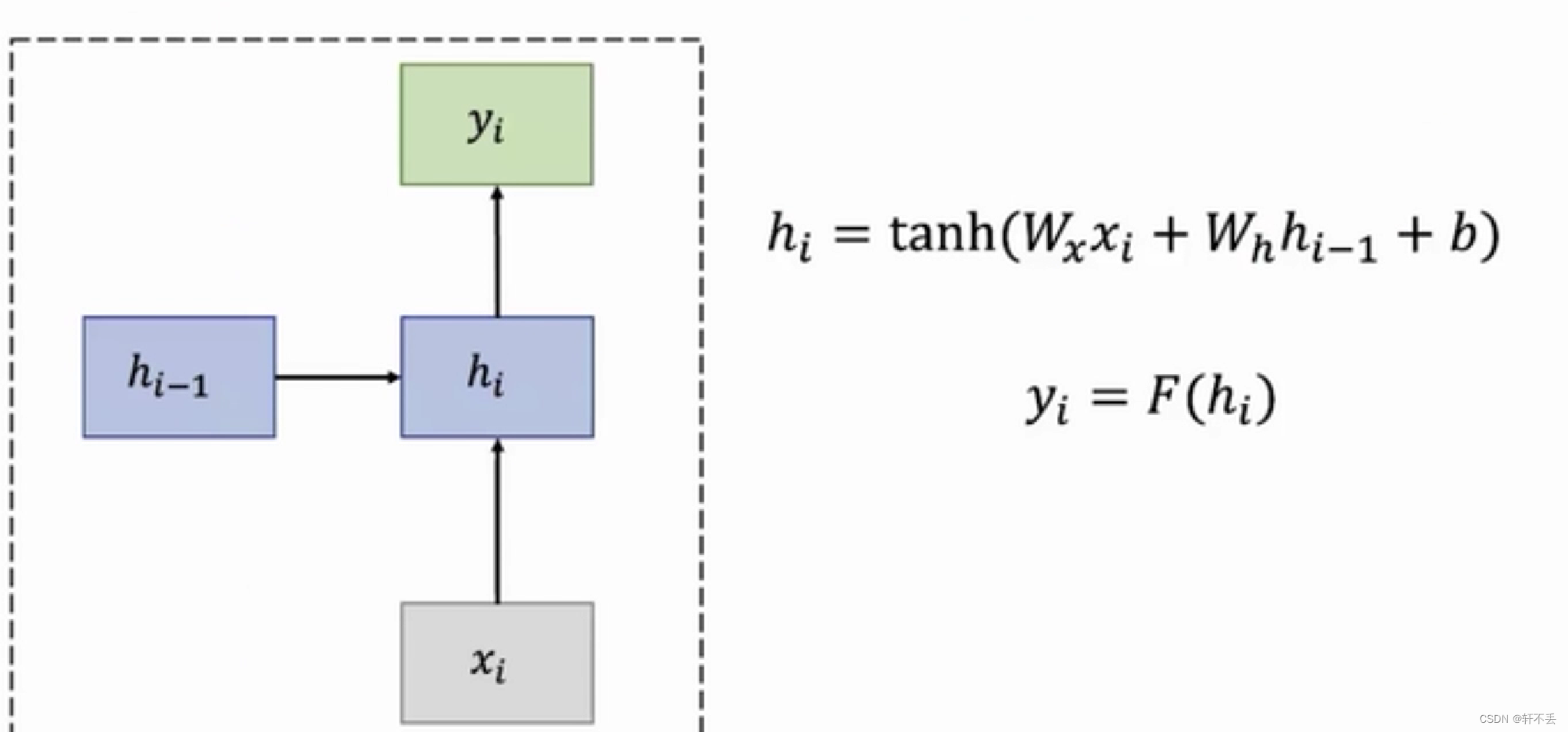
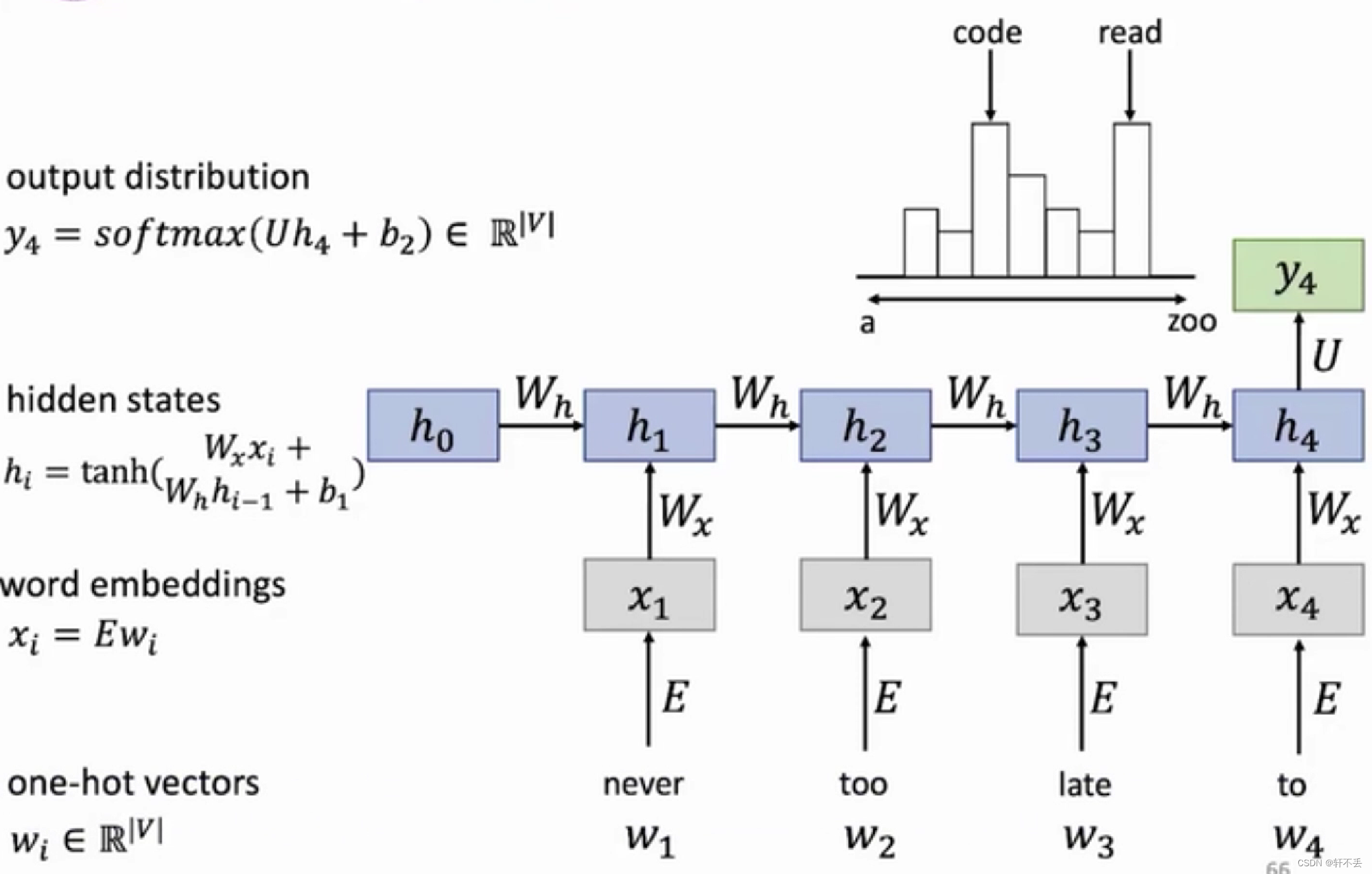
- RNN进行句子中下一个单词预测
可以看出,不论输入是什么,Wx和Wh都是一样的,因此RNN可以实现参数共享。
- 问题:梯度消失/梯度爆炸
因为RNN的输入需要用到前面的数据,因此在反向传播时链式会很长
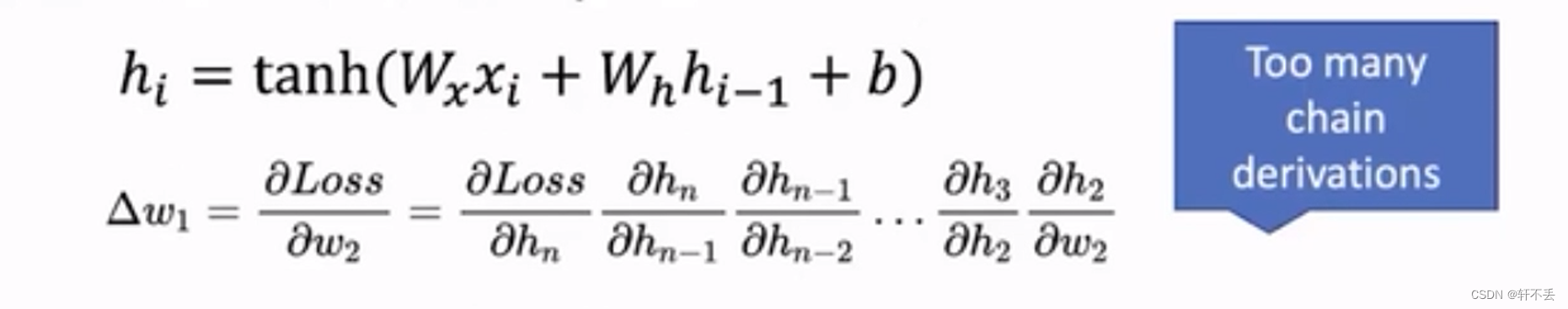
当每一层梯度都大于1,则梯度会指数倍上涨,即梯度爆炸。若小于1,则指数式衰减,即梯度消失。 - 传统的RNN存在梯度消失或梯度爆炸的问题,导致难以训练长序列数据(链越长越容易长生)。为了解决这一问题,出现了一些改进的RNN结构,如长短时记忆网络(LSTM)和门控循环单元(GRU)。这些改进的结构通过引入门控机制,可以更好地处理长序列数据,并更有效地捕捉序列数据中的长期依赖关系。
4、GRU
- GRU包含了更新门和重置门两个重要的门控机制,通过这两个门控单元来控制信息的流动,从而实现对序列数据的建模。
- 在GRU中,重置门决定了如何将过去的记忆与当前的输入相结合,而更新门则决定了如何将当前的记忆与上一时刻的记忆进行整合。通过这种门控机制,GRU可以有效地捕捉序列数据中的长期依赖关系,同时减少了参数数量,使得网络更易训练,同时具有较好的性能。
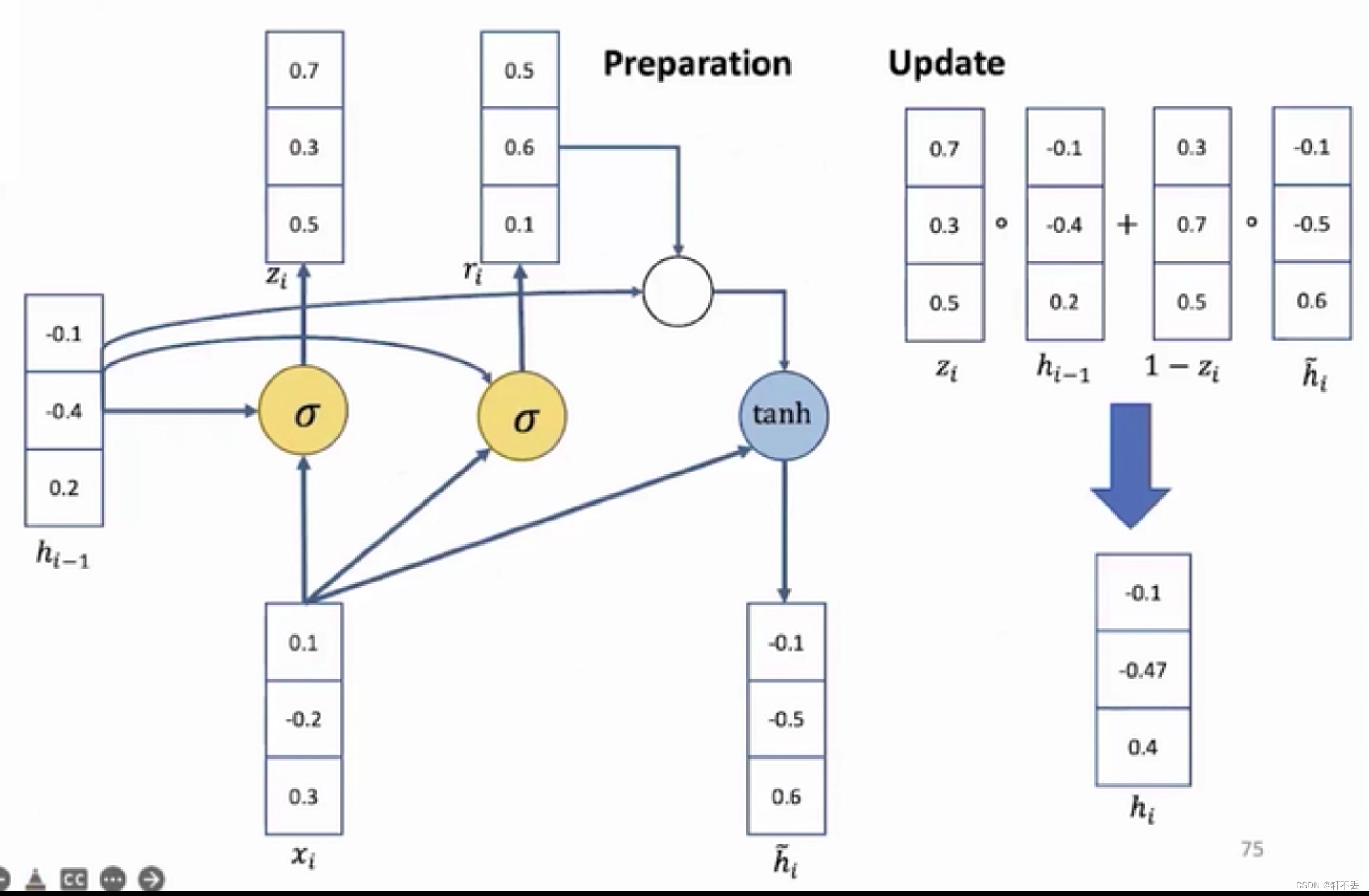
5、LSTM(长短时记忆网络)
- LSTM引入了三个门控单元:遗忘门(forget gate)、输入门(input gate)和输出门(output gate),以及一个细胞状态来控制信息流动。这些门控单元通过学习来决定哪些信息应该被记住、遗忘或更新,从而实现对序列数据的记忆和学习。
- 具体而言,遗忘门负责控制前一时刻的细胞状态中哪些信息需要被遗忘;输入门负责控制当前时刻的输入信息中哪些信息需要被更新到细胞状态中;输出门负责控制细胞状态的哪些信息被输出到下一时刻的隐藏状态中。通过这种门控机制,LSTM可以有效地处理长序列数据,并学习到长期依赖关系。
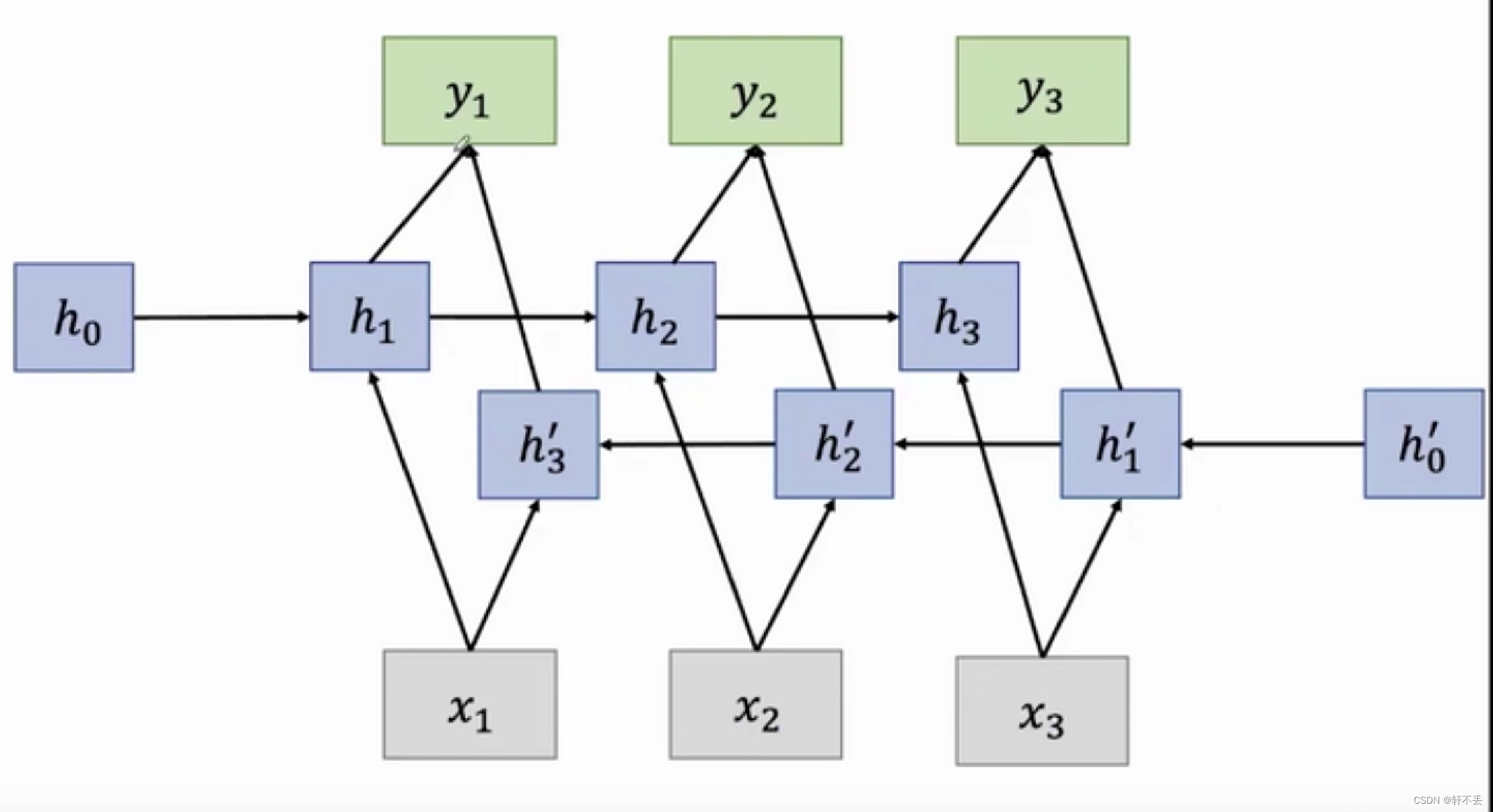
6、双向RNN
- 依靠过去和未来的输入
- 双向循环神经网络(Bidirectional Recurrent Neural Network,Bi-RNN)是一种结合了前向和后向信息的循环神经网络结构,用于处理序列数据。在双向RNN中,输入序列会同时经过一个前向RNN和一个后向RNN,从而能够捕捉到序列数据中前后两个方向的信息。
- 具体地,双向RNN包含两个独立的RNN结构:一个是正向RNN,负责处理输入序列的正向信息;另一个是反向RNN,负责处理输入序列的反向信息。这两个RNN结构可以独立地学习序列中的前向和后向关系,然后将它们的输出进行合并,从而综合考虑了整个序列中的信息。
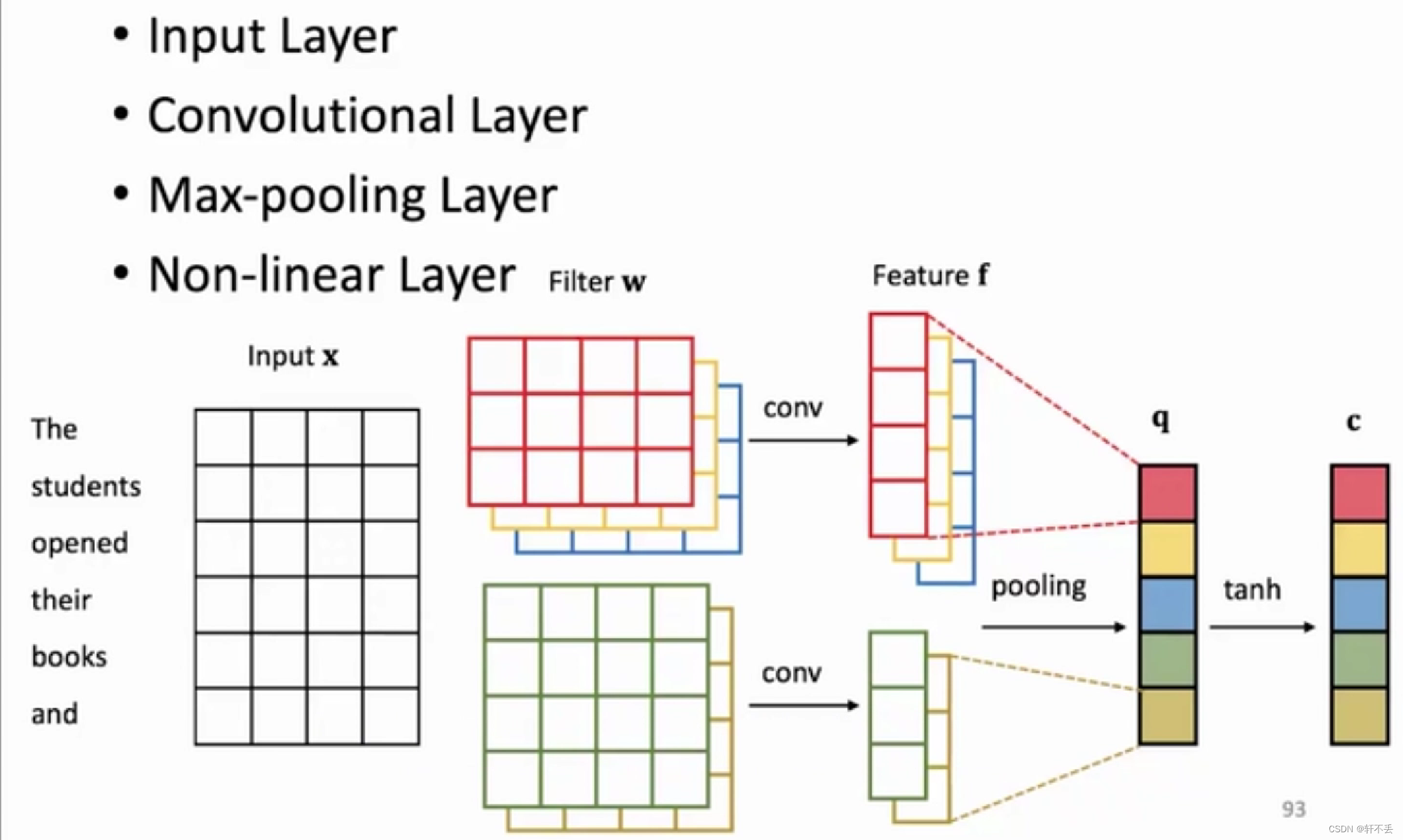
4、CNN(卷积神经网络)
- 卷积神经网络(Convolutional Neural Network,CNN)是一种专门用于处理结构化数据,尤其是二维图像和视频数据的深度学习模型。CNN的核心思想是通过卷积层、池化层和全连接层来提取和学习数据的特征,从而实现对图像等数据的高效分类和识别。
- CNN的主要组成部分包括:
-
卷积层(Convolutional Layer):卷积层通过卷积操作提取输入数据的特征,其中包括卷积核(filter)和步长(stride)。卷积操作可以有效地捕捉图像中的局部特征,同时通过共享权重可以减少参数数量。
-
池化层(Pooling Layer):池化层用于降采样,减少特征图的维度,同时保留主要特征。常见的池化操作包括最大池化和平均池化。
-
全连接层(Fully Connected Layer):全连接层负责将卷积层和池化层提取的特征进行分类或回归。全连接层通常在网络的最后几层出现。
通过堆叠多个卷积层、池化层和全连接层,CNN可以逐渐提取数据的高级特征,从而实现对复杂数据(如图像)的准确识别和分类。CNN在计算机视觉领域取得了巨大成功,被广泛应用于图像分类、目标检测、人脸识别等任务中,并且在自然语言处理等领域也有一定的应用。
三、迁移学习
迁移学习(Transfer Learning)是一种机器学习领域的技术,通过将在一个任务上学习到的知识和经验应用到另一个相关任务上,从而加速模型的训练过程、提高模型性能。迁移学习的核心思想是利用已经训练好的模型(通常是在大规模数据集上训练的模型)的特征表示来帮助解决新任务,而不是从零开始训练一个全新的模型。
迁移学习的优势包括:
- 加速训练过程:通过在预训练模型的基础上微调模型参数,可以显著减少训练时间和数据量,加快模型收敛速度。
- 提高模型性能:预训练模型已经学习到了大规模数据集的特征表示,可以提供更好的特征抽取能力,从而提高模型在新任务上的性能。
- 解决数据稀缺问题:当新任务的数据集较小或稀缺时,迁移学习可以通过利用在其他任务上学到的知识,提升模型的泛化能力。
迁移学习通常可以分为以下几种类型:
- 特征提取(Feature Extraction):冻结预训练模型的参数,只更新全连接层等分类器的参数。
- 微调(Fine-tuning):在预训练模型的基础上继续训练整个模型,更新所有参数。
- 领域自适应(Domain Adaptation):通过调整模型的表示使其适应不同的数据分布。
在深度学习领域,迁移学习经常应用于图像分类、目标检测、自然语言处理等任务中。常用的预训练模型包括ImageNet上预训练的模型(如ResNet、VGG、Inception等),BERT、GPT等自然语言处理预训练模型。
总之,迁移学习是一种利用已有知识来加速模型训练、提高性能的重要技术,可以在许多实际应用中发挥重要作用。