一个人的免疫组库由某一时间点的大量适应性免疫受体组成,代表了该个体的适应性免疫状态。免疫组库分类和相关受体识别有可能为新型疫苗的开发做出贡献。大量的实例对免疫组库分类提出了挑战,这可以表述为大规模多实例学习 (MMIL,Massive Multiple Instance Learning) 问题。传统的 MIL 方法(无论是在bag级还是instance级)在处理大量实例时都面临着巨大的计算负担或监督模糊的问题。为了解决这些问题,作者提出了一种基于标签消歧的多模态大规模多实例学习方法 (LaDM³IL) 用于免疫组库分类。LaDM³IL 采用实例级 MIL 范式来处理高计算成本的问题,并使用专门设计的标签消歧模块进行标签校正,减轻误导性监督的影响。为了更全面地表示每个受体,LaDM³IL 利用多模态融合模块来整合每个免疫受体的基因片段-gene segments和氨基酸 (AA,amino acid) 序列的信息。在巨细胞病毒 (CMV,Cytomegalovirus) 和Cancer数据集上进行的大量实验证明了所提出的 LaDM³IL 在免疫组分类和相关受体识别任务方面均具有出色的性能。
来自:A Label Disambiguation-Based Multimodal Massive Multiple Instance Learning Approach for Immune Repertoire Classification
工程:https://github.com/Josie-xufan/LaDM3IL
目录
- 背景概述
- 相关工作:标签消歧
- 方法
- 问题定义
- 模型架构-特征提取
- 标签消歧
- 聚合
- 数据集
背景概述
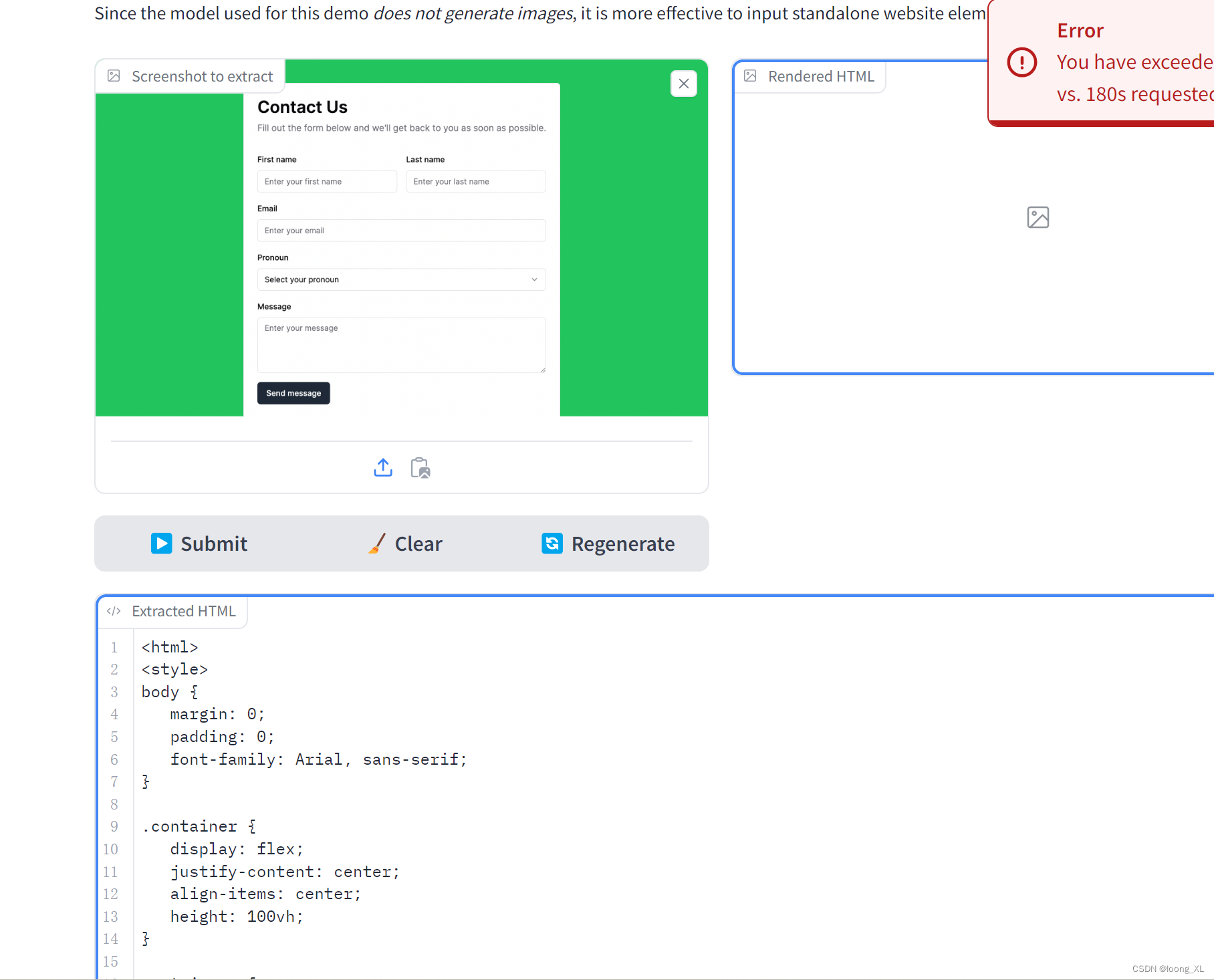
适应性免疫受体库 (AIRR,adaptive immune receptor repertoires) 由 T 细胞受体 (TCR,T-cell receptors) 和 B 细胞受体 (BCR,B-cell receptors) 组成,负责识别致病病原体(如细菌、病毒以及癌细胞)并记录过去和正在进行的免疫反应信息。图 1 显示了典型的适应性免疫过程,其中以 TCR 为例。TCR 位于 T 细胞表面,首先识别主要组织相容性复合体(肽-MHC 复合物,peptide-MHC complexes)上呈递的病原体抗原肽(antigen peptides),然后适应性免疫系统保存和扩增这些免疫受体(immune receptors)以激活免疫反应并保护人体免受疾病侵害。BCR 的病原体识别机制与 TCR 相似,主要区别在于 BCR 直接结合抗原表面,无需 MHC 呈递。

- 图1:适应性免疫受体库和免疫过程的说明。a) 适应性免疫受体库 (AIRR) 包括个体的 T 细胞受体 (TCR) 和 B 细胞受体 (BCR),它们是适应性免疫反应中不可或缺的分子。b) 免疫过程:适应性免疫受体 (AIR,adaptive immune receptor) 位于 T 细胞和 B 细胞的表面,其功能是识别抗原肽(antigenic peptides),对于 TCR,该抗原肽由主要组织相容性复合体 (MHC,major histocompatibility complex) 呈递,对于 BCR,该抗原肽直接与抗原(antigen)本身结合。
- antigen presenting cell:抗原呈递细胞
作为个体TCR和BCR的集合,AIRR记录了过去和正在进行的适应性免疫反应,其状态反映了免疫状态和个体对传染病、自身免疫性疾病和肿瘤相关病原体的反应。因此,AIRRs中的编码信息对于感染、疾病和癌症诊断具有高度的信息性和价值。这可以被概念化为一个免疫库分类问题。我们希望开发一种准确有效的方法来解决免疫系统分类和相关受体识别问题,因为它能加速疫苗的开发。
最近,基于高通量测序的免疫测序技术的进步促进了AIRRs的分析,其提供了一个组库中TCRs和BCRs的计数和受体序列的数据。这一进展为数据驱动方法铺平了道路。然而,由于以下因素,这仍然是一个具有挑战性的问题:
- 高度多样性-High diversity:适应性免疫受体(AIRs)具有高度多样性,使适应性免疫系统能够识别大量抗原。据估计,自然界中至少有 1 0 16 10^{16} 1016种不同的AIRs。
- 大容量-Large capacity:每个人都有大量不同的免疫受体( 1 0 7 − 1 0 8 10^{7}-10^{8} 107−108)。
- 低见证率-Low witness rate(WR):个体对特定疾病的免疫状态通常由基因库中极少数特定受体的存在决定。
在实践中,免疫组库分类可以被形式化为大规模多实例学习(MMIL)问题,其中AIR repertoires被视为bags,并且组库中的单个AIR被视为instance。AIRs的生物学功能由其氨基酸(AA)序列和相应的基因片段(V、D和J基因片段)决定。感兴趣的免疫状态(例如感染、疾病和癌症)是我们旨在预测的免疫库分类问题中的库级标签(repertoire-level label)。考虑到个体的特定免疫状态通常仅与库中一小部分特定受体相关,库中AIRs的准确实例水平标签是不可用的。这种弱监督的学习场景是多实例学习(MIL)的特点,在这种场景中,只有bag级标签是可用的。
现有的MIL算法可分为两种主要类型,即bag级和instance级MIL。在bag级MIL中,实例被编码为低维嵌入,然后将其聚合为bag级表示。聚合模块可以采用各种架构,包括固定的或参数化的pooling模块、注意力机制、RNN或Transformer方法,以及图神经网络。这种处理需要大量的计算资源,特别是在处理大规模数据集时,这阻碍了bag级MIL在免疫库分类(大容量)中的实践。相反,实例级MIL专注于实例级学习,并通过聚合每个实例的预测来生成bag级预测。这种方法提供了较低计算资源需求的优点。然而,实例级MIL面临着标签监督不准确的挑战,这源于广泛采用的将bag级标签分配给其中的每个instance的策略。鉴于低WR和高度多样性,这种标签分配策略在免疫库分类的背景下是有害的。
LaDM3IL是一种基于标签消歧的多模态大规模多实例学习方法,用于免疫库分类和相关受体识别。LaDM3IL利用instance级MIL框架来控制计算负载并应对高容量挑战。同时,为了应对高多样性挑战,LaDM3IL利用具有基于gating的注意力的多模态融合模块和张量融合来整合来自每个immune receptor的基因片段和氨基酸(AA)序列信息,从而生成每个受体的判别表示。其中,名为SC-AIR-BERT的预训练模型用于生成AA序列的嵌入。此外,LaDM3 IL结合了一个标签消歧模块(label disambiguation module),专门设计用于减轻错误监督的影响,以应对低WR的挑战。最后,在巨细胞病毒(CMV)和癌症数据集上对LaDM3 IL进行了广泛评估。
相关工作:标签消歧
标签消歧是部分标签学习(PLL,partial label learning)中的一个关键挑战,其目的是从候选标签集中找到正确的标签。与监督学习任务相比,PLL中的标签往往是模糊的,并且在模型学习过程中需要去噪以确保准确的分类。Pico是一种PLL方法(ICLR2021),以在统一的框架中处理表示学习和标签消歧问题,他们使用对比学习生成输入的embedding,然后,他们基于生成的embedding设计了一种基于prototype的标签消歧策略。在训练过程中,将基于prototype中最接近的类同时更新用于分类的pseudo target,以消除标签的歧义。
方法
问题定义
一个AIRR包含大量AIRs。给定 N N N个AIRRs { I R 1 , . . . , I R N } \left\{IR_{1},..., IR_{N} \right\} {IR1,...,IRN},每个AIRR包含 M M M个AIRs { I R i 1 , . . . , I R i M } \left\{IR_{i}^{1},..., IR_{i}^{M} \right\} {IRi1,...,IRiM}。注意, M M M在不同的组库中差异很大。同时,将 N N N个组库的标签定义为 { Y 1 , . . . , Y N } \left\{Y_{1},...,Y_{N}\right\} {Y1,...,YN},类别总数为 C C C。此外,AIRs与表示为 { f r e i 1 , . . . , f r e i M } \left\{fre_{i}^{1},...,fre_{i}^{M}\right\} {frei1,...,freiM}的频率值配对,指示对某些抗原(certain antigens)的免疫反应强度。模型试图建立一个函数 Y i = F ( I R i ) Y_{i}=F(IR_{i}) Yi=F(IRi),与传统instance级MIL方法类似,最初将bag标签 Y i Y_{i} Yi分配给 { I R i 1 , . . . , I R i M } \left\{IR_{i}^{1},..., IR_{i}^{M} \right\} {IRi1,...,IRiM}作为pseudo标签。随着训练更新这些标签。
模型架构-特征提取
图2说明了LaDM3IL的框架。为了获得每个AIR的全面表示,作者基于多模态融合模块,将AA序列和V(D)J基因片段的信息与基于门控的注意力机制相结合,然后进行张量融合。具体而言,基因编码器利用可训练embedding层将token化的V(D)J基因名称转换为数字表示,表示为 h g h_{g} hg。 h g h_{g} hg是将V基因片段和J基因片段的单独embedding连接起来的结果,每个片段的尺寸分别为16和8。
值得注意的是,D基因信息被排除在外,因为它在很大一部分AIRs中不存在。同时,使用预训练的序列编码器SC-AIR-BERT来生成AIRs的AA序列的表示,称为嵌入维度为512的
h
s
h_s
hs。SCAIR-BERT是一个类似BERT的模型,包括6个标准Transformer层,每层包含4个注意力头。然后,通过基于门控的注意力机制,计算出两种模态的输出,记为
o
g
o_{g}
og和
o
s
o_{s}
os。张量融合模块对
o
g
o_{g}
og和
o
s
o_{s}
os进行整合:
h
=
R
e
L
U
(
W
f
u
s
i
o
n
⋅
(
o
g
⊕
o
s
)
+
b
f
u
s
i
o
n
)
h=ReLU(W_{fusion}\cdot(o_{g}\oplus o_{s})+b_{fusion})
h=ReLU(Wfusion⋅(og⊕os)+bfusion)其中,
⊕
\oplus
⊕表示Kronecker Production。

- 图2:模型架构
标签消歧
以实例级MIL为基础框架来解决免疫库分类问题,该问题聚合了所有实例级预测以及bag级预测。为了解决监督不准确的问题,作者设计了一个标签消歧模块。该模块的关键设计是表示为 E p r o t o t y p e E_{prototype} Eprototype的原型,该原型保留了每个类别的典型嵌入以及调整每个受体标签的机制。具体步骤如下。
首先,在获得如特征提取器中所述的受体的表示后,将通过以下方式计算每个受体的预测: p i j = s o f t m a x ( F C r e c e p t o r ( h i j ) ) p_{i}^{j}=softmax(FC_{receptor}(h_{i}^{j})) pij=softmax(FCreceptor(hij))其中, F C r e c e p t o r FC_{receptor} FCreceptor是一个可学习分类器, p i j p_{i}^{j} pij是基于多模态特征embedding h i j h_{i}^{j} hij(来自第 i i i个免疫库的第 j j j个免疫受体)的预测概率。
然后,从每一类 c ∈ { 1 , . . . , C } c\in\left\{1,...,C\right\} c∈{1,...,C}中选出在epoch e e e时, p i k p_{i}^{k} pik超过阈值 θ \theta θ的 K K K个免疫受体,记为 k e c − r e c e p t o r kec-receptor kec−receptor。然后,原型将使用基于动量的方法更新,在epoch e + 1 e+1 e+1 处原型中 c c c类的嵌入通过在epoch e e e 处符合 c c c的所选 K K K受体的嵌入来更新。每个免疫受体的标签 Y i j Y_{i}^{j} Yij基于epoch e e e的原型和免疫受体之间的相似性进行调整。
聚合
为了生成免疫库的预测 p i p_{i} pi,作者将相应的免疫受体 p i j p_{i}^{j} pij的预测与相应频率 f r e i j fre_{i}^{j} freij组合如下: p i = ∑ j = 1 M ( p i j ⋅ f r e i j ) p_{i}=\sum_{j=1}^{M}(p_{i}^{j}\cdot fre_{i}^{j}) pi=j=1∑M(pij⋅freij)
数据集
CMV数据集由785个组库构成,每个组库平均有243,960个受体。作者排除了信息缺失的组库,684个组库被纳入实验,具有完整的CMV状态(阳性:312,阴性:372)和序列丰度。
癌症数据集包括训练集中的30,000个肿瘤相关受体和40,000个对照受体,以及测试集中10,000个肿瘤相关受体和19,851个对照受体。在CMV数据集上,作者评估方法在免疫库分类和相关受体鉴定方面的性能。在癌症数据集上,更多地关注癌症相关受体识别的性能。