Tip: 如果你在进行深度学习、自动驾驶、模型推理、微调或AI绘画出图等任务,并且需要GPU资源,可以考虑使用UCloud云计算旗下的Compshare的GPU算力云平台。他们提供高性价比的4090 GPU,按时收费每卡2.6元,月卡只需要1.7元每小时,并附带200G的免费磁盘空间。通过链接注册并联系客服,可以获得20元代金券(相当于6-7H的免费GPU资源)。欢迎大家体验一下~
0. 简介
自从发现可以利用自有数据来增强大语言模型(LLM)的能力以来,如何将 LLM 的通用知识与个人数据有效结合一直是热门话题。关于使用微调(fine-tuning)还是检索增强生成(RAG)来实现这一目标的讨论持续不断。检索增强生成 (RAG) 是一种使用来自私有或专有数据源的信息来辅助文本生成的技术。它将检索模型(设计用于搜索大型数据集或知识库)和生成模型(例如大型语言模型 (LLM),此类模型会使用检索到的信息生成可供阅读的文本回复)结合在一起。
用一个简单的比喻来说, RAG 对大语言模型(Large Language Model,LLM)的作用,就像开卷考试对学生一样。在开卷考试中,学生可以带着参考资料进场,比如教科书或笔记,用来查找解答问题所需的相关信息。开卷考试的核心在于考察学生的推理能力,而非对具体信息的记忆能力。同样地,在 RAG 中,事实性知识与 LLM 的推理能力相分离,被存储在容易访问和及时更新的外部知识源中,具体分为两种:
- 参数化知识(Parametric knowledge): 模型在训练过程中学习得到的,隐式地储存在神经网络的权重中。
- 非参数化知识(Non-parametric knowledge): 存储在外部知识源,例如向量数据库中。
1. 了解LangChain
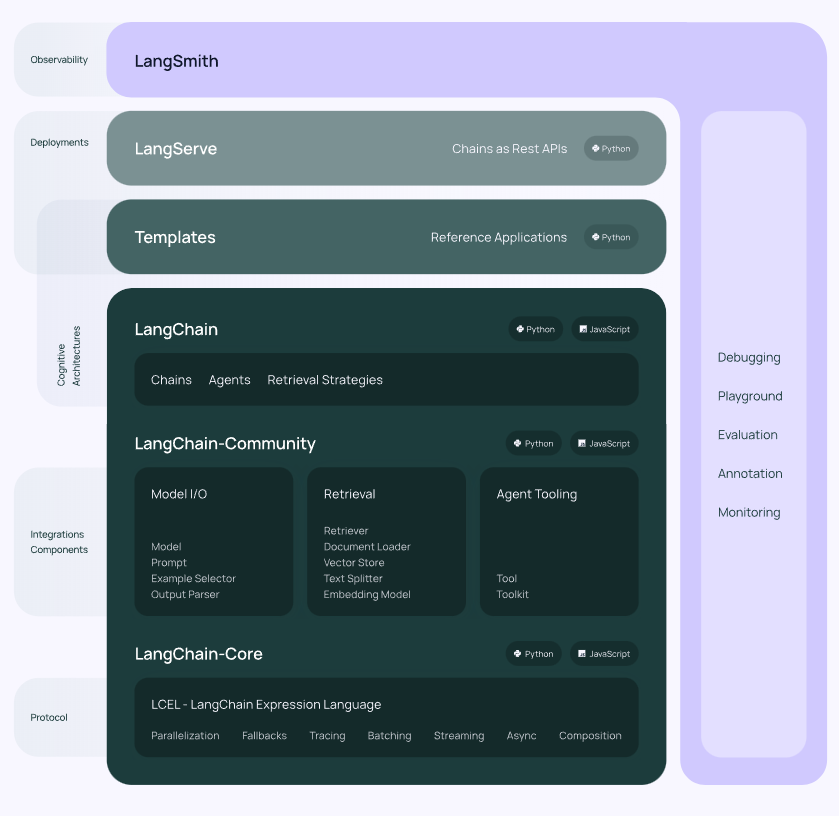
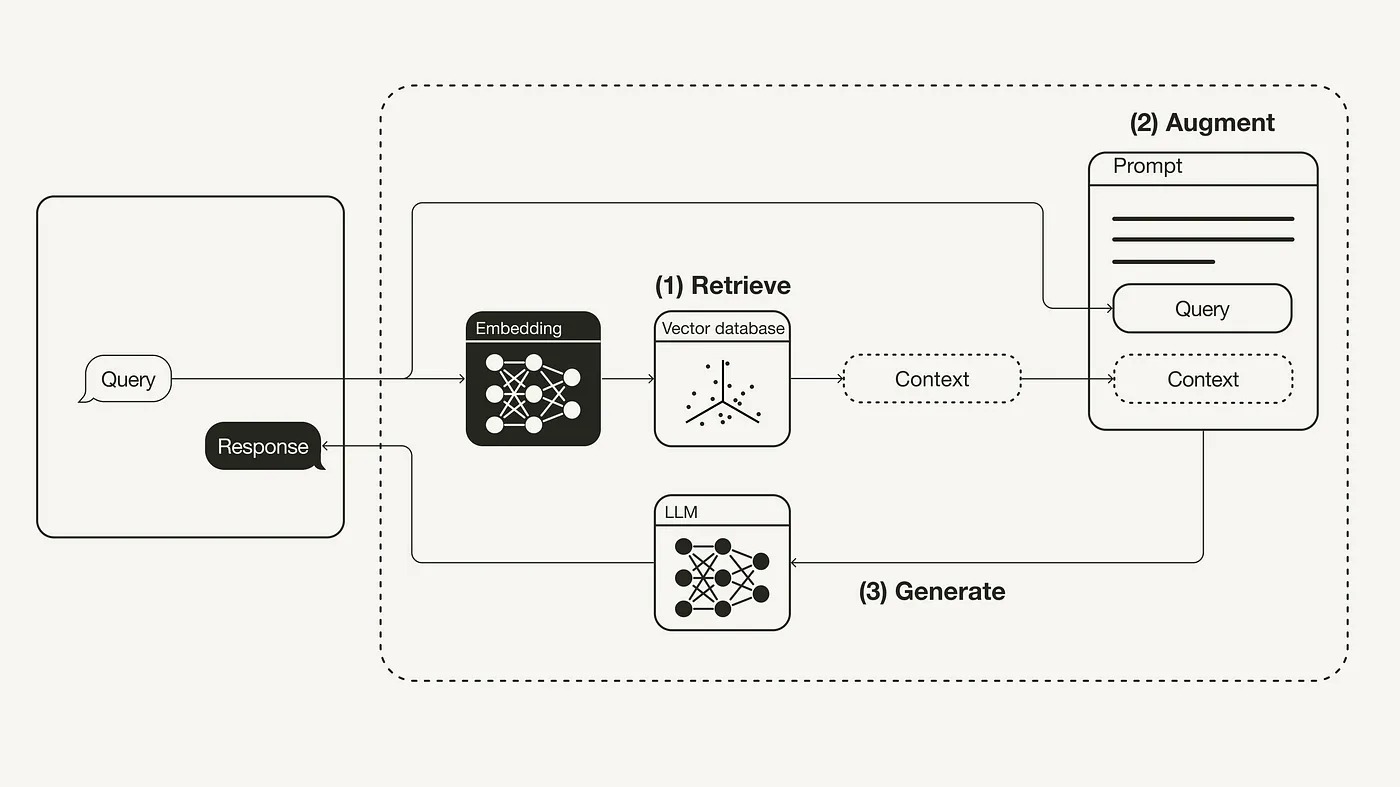
从上图可以看到,LangChain 目前有四层框架:
- 最下层深色部分:LangChain的Python和JavaScript库。包含无数组件的接口和集成,以及将这些组件组合到一起的链(chain)和代理(agent)封装,还有链和代理的具体实现。
- Templates:一组易于部署的参考体系结构,用于各种各样的任务。
- LangServe:用于将LangChain链部署为REST API的库。
- LangSmith:一个开发人员平台,允许您调试、测试、评估和监控基于任何LLM框架构建的链,并与LangChain无缝集成。
2. RAG基础使用
首先,你需要建立一个向量数据库,这个数据库作为一个外部知识源,包含了所有必要的额外信息。填充这个数据库需要遵循以下步骤:
- 收集数据并将其加载进系统
- 将你的文档进行分块处理
- 对分块内容进行嵌入,并存储这些块
首先,你需要收集并加载数据。为了加载数据,你可以利用 LangChain 提供的众多 DocumentLoader 之一。Document 是一个包含文本和元数据的字典。为了加载文本,你会使用 LangChain 的 TextLoader。
import requests
from langchain.document_loaders import TextLoader
url = "https://raw.githubusercontent.com/langchain-ai/langchain/master/docs/docs/modules/state_of_the_union.txt"
res = requests.get(url)
with open("state_of_the_union.txt", "w") as f:
f.write(res.text)
loader = TextLoader('./state_of_the_union.txt')
documents = loader.load()
其次,需要对文档进行分块 — 由于 Document 的原始大小超出了 LLM 处理窗口的限制,因此需要将其切割成更小的片段。LangChain 提供了许多文本分割工具,对于这个简单的示例,你可以使用 CharacterTextSplitter,设置 chunk_size 大约为 500,并且设置 chunk_overlap 为 50,以确保文本块之间的连贯性。
from langchain.text_splitter import CharacterTextSplitter
text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=50)
chunks = text_splitter.split_documents(documents)
最后一步是嵌入并存储这些文本块 — 为了实现对文本块的语义搜索,你需要为每个块生成向量嵌入,并将它们存储起来。生成向量嵌入时,你可以使用 OpenAI 的嵌入模型;而存储它们,则可以使用 Weaviate 向量数据库。通过执行 .from_documents() 操作,就可以自动将这些块填充进向量数据库中。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Weaviate
import weaviate
from weaviate.embedded import EmbeddedOptions
client = weaviate.Client(
embedded_options = EmbeddedOptions()
)
vectorstore = Weaviate.from_documents(
client = client,
documents = chunks,
embedding = OpenAIEmbeddings(),
by_text = False
)
一旦向量数据库准备好,你就可以将它设定为检索组件,这个组件能够根据用户查询与已嵌入的文本块之间的语义相似度,来检索出额外的上下文信息
retriever = vectorstore.as_retriever()
接下来,你需要准备一个提示模板,以便用额外的上下文信息来增强原始的提示。你可以根据下面显示的示例,轻松地定制这样一个提示模板。
from langchain.prompts import ChatPromptTemplate
template = """You are an assistant for question-answering tasks.
Use the following pieces of retrieved context to answer the question.
If you don't know the answer, just say that you don't know.
Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:
"""
prompt = ChatPromptTemplate.from_template(template)
print(prompt)
在 RAG (检索增强生成) 管道的构建过程中,可以通过将检索器、提示模板与大语言模型 (LLM) 相结合来形成一个序列。定义好 RAG 序列之后,就可以开始执行它。
from langchain.chat_models import ChatOpenAI
from langchain.schema.runnable import RunnablePassthrough
from langchain.schema.output_parser import StrOutputParser
llm = ChatOpenAI(model_name="gpt-3.5-turbo", temperature=0)
rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
query = "What did the president say about Justice Breyer"
rag_chain.invoke(query)
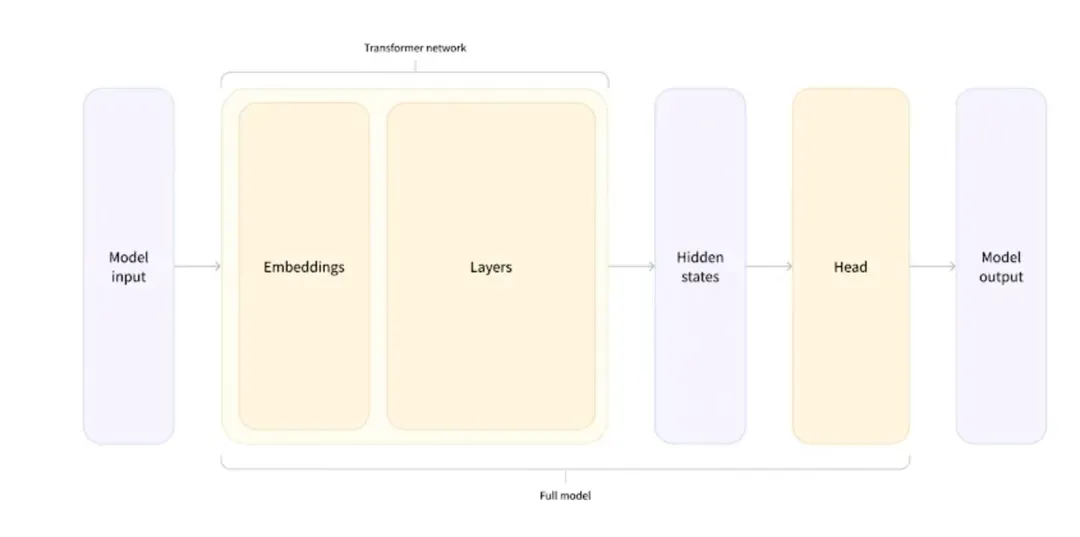
3. ollama替换chatgpt完成联网搜索拆分
此外可以通过ollama检索完成Embedding,给他资料,让他从这些资料从中找到答案来回答问题,就是构建知识库,回答问题
urls = [
"https://ollama.com/",
"https://ollama.com/blog/windows-preview",
"https://ollama.com/blog/openai-compatibility",
]
docs = [WebBaseLoader(url).load() for url in urls]
docs_list = [ item for sublist in docs for item in sublist]
#text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500,chunk_overlap=100)
text_splitter = CharacterTextSplitter.from_tiktoken_encoder(chunk_size=7500, chunk_overlap=100)
docs_splits = text_splitter.split_documents(docs_list)
# 2 convert documents to Embeddings and store them
vectorstore = Chroma.from_documents(
documents=docs_splits,
collection_name="rag-chroma",
embedding=embeddings.ollama.OllamaEmbeddings(model='nomic-embed-text'),
)
retriever =vectorstore.as_retriever()
# 4 after RAG
print("\n######\nAfter RAG\n")
after_rag_template ="""Answer the question based only the following context:
{context}
Question:{question}
"""
after_rag_prompt = ChatPromptTemplate.from_template(after_rag_template)
after_rag_chain = (
{"context": retriever, "question": RunnablePassthrough()}
| after_rag_prompt
| model_local
| StrOutputParser()
)
print(after_rag_chain.invoke("What is Ollama?"))
通过三个网址,获取数据,将其转化为embedding,存储在向量库中,我们提问时,就能得到我们想要的一个初步答案,比未给语料时效果要好。
使用nomic-embed-text进行嵌入,nomic-embed-text具有更高的上下文长度8k,该模型在短文本和长文本任务上均优于 OpenAI Ada-002 和text-embedding-3-small。
4. 多模态RAG
为了帮助模型识别出"猫"的图像和"猫"这个词是相似的,我们依赖于多模态嵌入。为了简化一下,想象有一个魔盒,能够处理各种输入——图像、音频、文本等。现在,当我们用一张"猫"的图像和文本"猫"来喂养这个盒子时,它施展魔法,生成两个数值向量。当这两个向量被输入机器时,机器会想:"根据这些数值,看起来它们都与’猫’有关。"这正是我们的目标!我们的目标是帮助机器识别"猫"的图像和文本"猫"之间的密切联系。然而,为了验证这个概念,当我们在向量空间中绘制这两个数值向量时,结果发现它们非常接近。这个结果与我们之前观察到的两个文本词"猫"和"狗"在向量空间中的接近度完全一致。这就是多模态的本质。
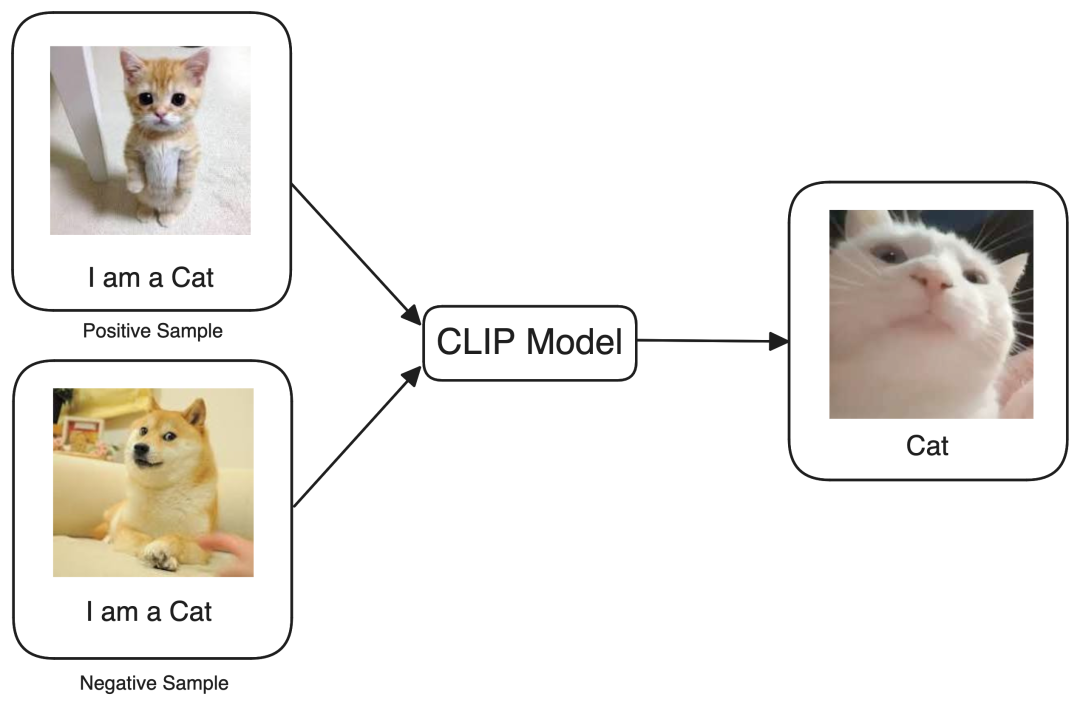
现在我们训练文本-图像模型识别出正样本提供了准确的解释,而负样本具有误导性,应该在训练过程中被忽略。正式来说,这种技术被OpenAI引入的 CLIP[2] (对比语言-图像预训练)所称,作者在大约4亿对从互联网上获取的图像标题对上训练了一个图像-文本模型,每当模型犯错误时,对比损失函数就会增加并惩罚它,以确保模型训练良好。同样的原则也适用于其他模态组合,例如猫的声音与猫这个词是语音-文本模型的正样本,一段猫的视频与描述性文本"这是一只猫"是视频-文本模型的正样本。