目录
- 基本组成部分:
- 工作原理:
- 特点:
- 一个简单的示例
- 应用场景:
布隆过滤器(Bloom Filter)是一种空间效率极高且查询速度很快的概率型数据结构,用于测试一个元素是否属于一个集合。布隆过滤器的基本思想是在一个固定大小的位数组上使用多个哈希函数进行映射。
基本组成部分:
-
位数组(Bit Array):布隆过滤器的核心是一个大型的二进制位数组,初始化时所有位都设置为0。
-
哈希函数(Hash Functions):使用多个不同的哈希函数,当一个元素被加入布隆过滤器时,这个元素会被这k个哈希函数分别映射到位数组的不同位置,并将这些位置的比特位设为1。
工作原理:
-
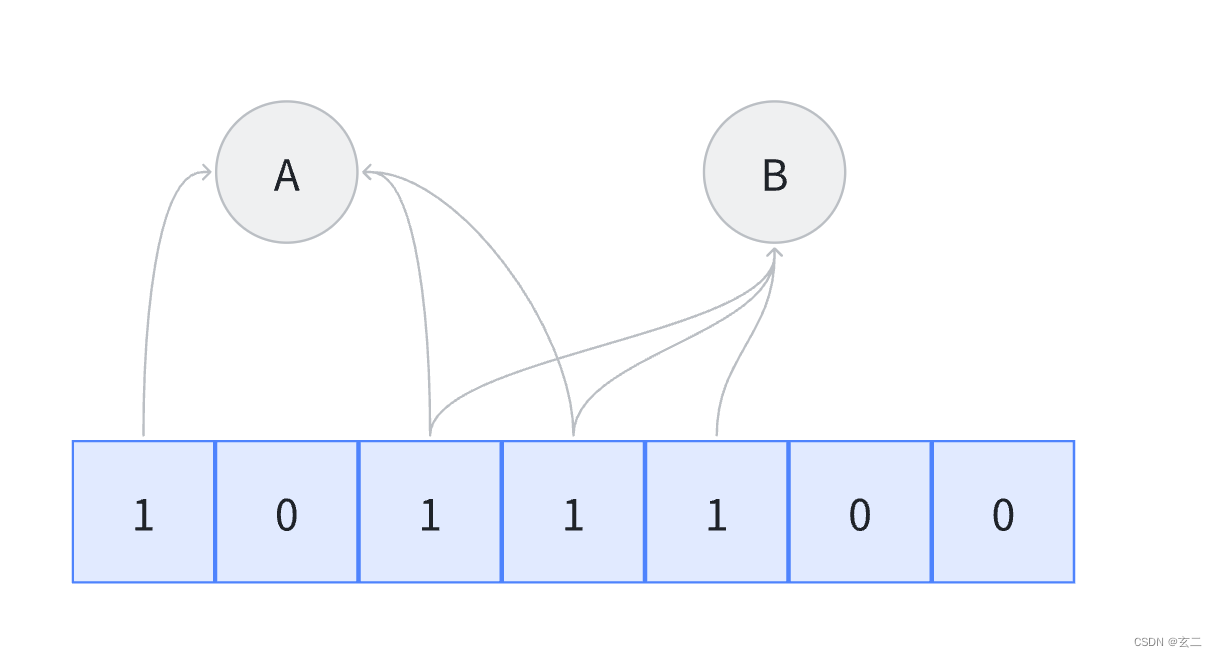
添加元素:要将一个元素添加到布隆过滤器中,先用k个哈希函数分别计算出k个位置,然后将这些位置的位设为1。
-
由于使用了多个哈希函数,一个元素通常会导致位数组中的多个位置被置为1。但也因此节省很多空间。
-
-
查询元素:要检查一个元素是否在集合中,同样使用这k个哈希函数计算k个位置,如果所有这些位置的位都是1,则算法判断元素“可能”在集合中。但存在一定的误报率,即元素实际上并不在集合中,但由于哈希碰撞,计算出的位置也都是1。

特点:
-
空间效率高:相比直接存储元素或使用传统的数据结构,布隆过滤器使用更少的内存表示集合。
-
查询速度快:查询过程只需要对k个位置进行访问,时间复杂度接近O(1)。
-
误报率:布隆过滤器可能会报告元素在集合中,即使它实际上不在(假阳性)。但它绝不会报告元素不在集合中,如果元素确实存在(无假阴性)。
-
不可删除性:一旦一个位被设置为1,就不能再回退,因此从布隆过滤器中删除元素比较困难,虽然有一些方法可以部分解决这个问题,但通常是以牺牲其他性能为代价的。
一个简单的示例
以下是一个布隆过滤器的简单代码。
java和redis都提供了好用的布隆过滤器第三方库,直接使用即可。
import java.util.BitSet;
public class BloomFilter {
private static final int DEFAULT_SIZE = 2 << 24; // 默认位数组大小,可根据需要调整
private static final int[] seeds = new int[]{7, 11, 13, 31, 37, 61}; // 哈希种子,可以增加以减少误报率
private BitSet bitSet = new BitSet(DEFAULT_SIZE);
private SimpleHash[] func;
public BloomFilter() {
func = new SimpleHash[seeds.length];
for (int i = 0; i < seeds.length; i++) {
func[i] = new SimpleHash(DEFAULT_SIZE, seeds[i]);
}
}
// 添加元素
public void add(Object value) {
for (SimpleHash f : func) {
bitSet.set(f.hash(value), true);
}
}
// 查询元素是否存在
public boolean contains(Object value) {
if (value == null) {
return false;
}
boolean ret = true;
for (SimpleHash f : func) {
ret = ret && bitSet.get(f.hash(value));
}
return ret;
}
// 简单的哈希函数实现
private static class SimpleHash {
private int cap;
private int seed;
public SimpleHash(int cap, int seed) {
this.cap = cap;
this.seed = seed;
}
// 使用哈希函数计算位置
public int hash(Object value) {
int h;
return (value == null) ? 0 : Math.abs(seed * (cap - 1) & ((h = value.hashCode()) ^ (h >>> 16)));
}
}
}
// 使用示例
public class Main {
public static void main(String[] args) {
BloomFilter filter = new BloomFilter();
filter.add("test");
filter.add("example");
System.out.println(filter.contains("test")); // 应返回 true
System.out.println(filter.contains("absent")); // 可能返回 false 或者由于误报返回 true
}
}
应用场景:
-
缓存系统(重点):判断一个键值是否可能在缓存中,减少不必要的缓存查找或数据库查询。避免缓存穿透。
-
网页爬虫去重:避免重新抓取已经访问过的URL。
-
数据库查询优化:作为初步筛选,减少对主数据库的查询次数。
-
垃圾邮件过滤:快速排除已知的非垃圾邮件地址。