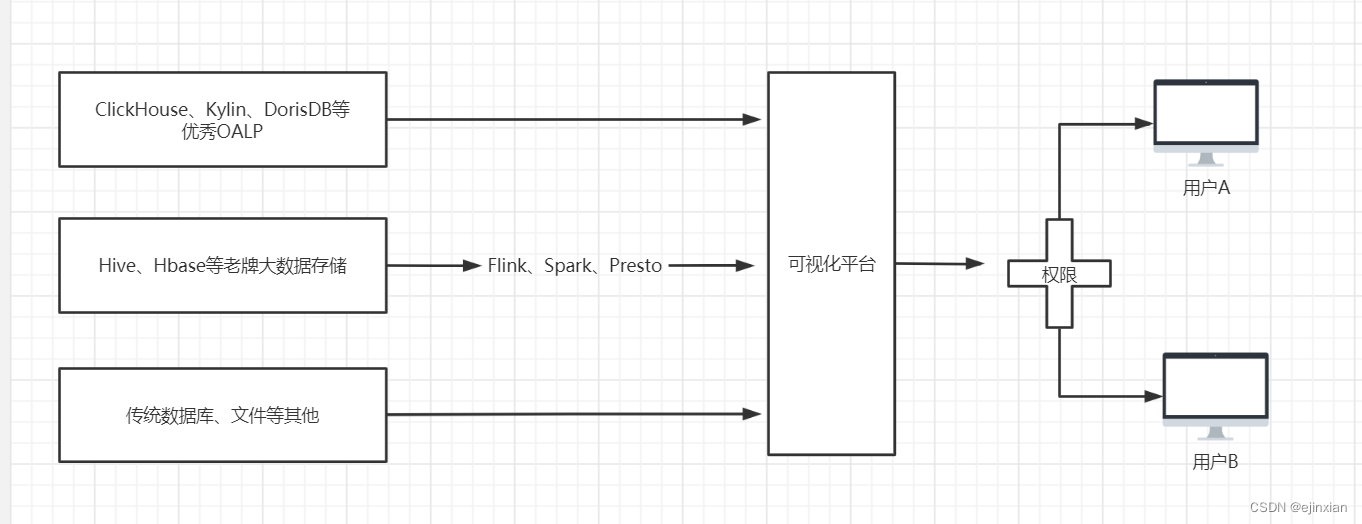
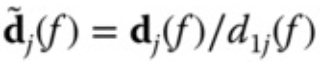一、朴素贝叶斯法原理
1.基本原理
朴素贝叶斯法(Naive Bayes)是一种基础分类算法,它的核心是贝叶斯定理+条件独立性假设。贝叶斯定理描述的是两个条件概率之间的关系,对两个事件A和B,由乘法法则易知
(
A
∩
B
)
=
P
(
A
)
P
(
B
│
A
)
=
P
(
B
)
P
(
A
│
B
)
(A∩B)=P(A)P(B│A)=P(B)P(A│B)
(A∩B)=P(A)P(B│A)=P(B)P(A│B)
贝叶斯定理就是对这个关系式的变形,即
P
(
B
│
A
)
=
P
(
B
)
P
(
A
∣
B
)
P
(
A
)
P(B│A)=\frac{P(B)P(A|B)}{P(A)}
P(B│A)=P(A)P(B)P(A∣B)
若把样本特征和类别作为对应的条件和条件概率,则贝叶斯定理可以用来解决分类问题。如对样本
x
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x=\left( x_1,x_2,...,x_n \right)
x=(x1,x2,...,xn),所属类别为
y
y
y,那么该特征下对应该类别的概率代入贝叶斯公式就是
P
(
y
∣
x
1
,
x
2
,
.
.
.
,
x
n
)
=
P
(
y
)
P
(
x
1
,
x
2
,
.
.
.
,
x
n
∣
y
)
P
(
x
1
,
x
2
,
.
.
.
,
x
n
)
P(y|x_1,x_2,...,x_n)=\frac{P(y)P(x_1,x_2,...,x_n|y)}{P(x_1,x_2,...,x_n)}
P(y∣x1,x2,...,xn)=P(x1,x2,...,xn)P(y)P(x1,x2,...,xn∣y)
贝叶斯分类法的思想就是计算样本特征对应于各类别的概率,以概率最大的作为分类输出。分母部分是特征的联合概率,可以进一步由全概率公式展开;分子部分由于含复杂的条件概率,使得直接的计算较复杂,因此这里做一个条件独立性假设,即认为样本的各维特征间是相互独立的,这是一个较强的假设,朴素贝叶斯也由此得名。在该条件之下,分子便可化为
P
(
y
)
∏
i
=
1
n
P
(
x
i
∣
y
)
P(y)\prod_{i=1}^{n}P(x_i|y)
P(y)i=1∏nP(xi∣y)
注意到,在用于分类决策时,分母部分的值对于所有的类别都是相同的,要找出最大概率对应的类别,只考察分子即可。因此,朴素贝叶斯分类器表示为
y
^
=
arg
m
a
x
y
k
P
(
y
k
)
∏
i
=
1
n
P
(
x
i
∣
y
k
)
\hat{y}=\arg max_{y_k}{P(y_k)\prod_{i=1}^{n}P(x_i|y_k)}
y^=argmaxykP(yk)i=1∏nP(xi∣yk)
2.平滑处理
在离散特征的情形之下进行分类输出的概率计算,可能会出现概率为0的情况,如随机变量观测值的某一维并未在训练集中出现,那么它所属的条件概率为0,致使对应类别的后验概率为0,从而使分类产生偏差,这是不合理的,因此需进行一定的平滑处理。具体,就是在频率计算时,对每组统计的频数加上一个常数。
先验概率:
P
(
y
k
)
=
∑
i
=
1
N
I
(
y
i
=
y
k
)
+
λ
N
+
K
λ
P(y_k)=\frac{\sum_{i=1}^{N}{I(y_i=y_k)+\lambda}}{N+K\lambda}
P(yk)=N+Kλ∑i=1NI(yi=yk)+λ
条件概率:
P
(
x
i
∣
y
k
)
=
∑
i
=
1
N
I
(
x
i
,
y
i
=
y
k
)
+
λ
∑
i
=
1
N
I
(
y
i
=
y
k
)
+
S
λ
P(x_i|y_k)=\frac{\sum_{i=1}^{N}{I(x_i,y_i=y_k)+\lambda}}{\sum_{i=1}^{N}{I(y_i=y_k)+S\lambda}}
P(xi∣yk)=∑i=1NI(yi=yk)+Sλ∑i=1NI(xi,yi=yk)+λ
当
λ
=
1
\lambda=1
λ=1时,称为拉普拉斯平滑(Laplace smoothing)。
3.三个基本模型
根据特征随机变量的类型,分为伯努利朴素贝叶斯、多项式朴素贝叶斯、高斯朴素贝叶斯三种基本模型。
(1) 伯努利朴素贝叶斯
若特征随机变量符合的是离散型的二项分布,也就是仅布尔值,那么此时的模型称为伯努利朴素贝叶斯。从统计的角度,分类器表达式分子中的连乘运算对应于n次独立试验。
(2) 多项式朴素贝叶斯
若特征随机变量符合的是离散型的多项分布,那么此时的模型称为多项式朴素贝叶斯。同样地,分类器表达式分子中的连乘运算对应于n次独立试验。
(3) 高斯朴素贝叶斯
若特征随机变量是连续型的(如身高、体重),即假定它是符合高斯分布的(正态分布),概率的计算就是由已知的数据计算出高斯分布的两个参数(均值、标准差),进而由密度函数确定对应的取值,代入公式计算。同样地,分类器表达式分子中的连乘运算对应于n次独立试验。
二、示例
这里对多项式朴素贝叶斯分类模型举例。
训练集:
| 样本特征向量X | 类别Y |
|---|---|
| [1, 1, 2, 3] | 1 |
| [1, 2, 2, 4] | 2 |
| [1, 2, 3, 3] | 2 |
| [1, 2, 4, 4] | 3 |
| [1, 3, 3, 4] | 3 |
| [2, 2, 3, 4] | 1 |
| [2, 1, 3, 3] | 3 |
测试样本:[1, 2, 3, 4]
则类别集合为
Y
∈
{
1
,
2
,
3
}
Y\in\left\{ 1,2,3 \right\}
Y∈{1,2,3} ,
P
(
Y
=
1
)
=
2
7
P(Y=1)=\frac{2}{7}
P(Y=1)=72,
P
(
Y
=
2
)
=
2
7
P(Y=2)=\frac{2}{7}
P(Y=2)=72,
P
(
Y
=
3
)
=
3
7
P(Y=3)=\frac{3}{7}
P(Y=3)=73,
P
(
X
1
=
1
∣
Y
=
1
)
=
1
2
P\left( X_1=1|Y=1 \right)=\frac{1}{2}
P(X1=1∣Y=1)=21,
P
(
X
2
=
2
∣
Y
=
1
)
=
1
2
P\left( X_2=2|Y=1 \right)=\frac{1}{2}
P(X2=2∣Y=1)=21,
P
(
X
3
=
3
∣
Y
=
1
)
=
1
2
P\left( X_3=3|Y=1 \right)=\frac{1}{2}
P(X3=3∣Y=1)=21,
P
(
X
4
=
4
∣
Y
=
1
)
=
1
2
P\left( X_4=4|Y=1 \right)=\frac{1}{2}
P(X4=4∣Y=1)=21,
P
(
X
1
=
1
∣
Y
=
2
)
=
1
P\left( X_1=1|Y=2 \right)=1
P(X1=1∣Y=2)=1,
P
(
X
2
=
2
∣
Y
=
2
)
=
1
P\left( X_2=2|Y=2 \right)=1
P(X2=2∣Y=2)=1,
P
(
X
3
=
3
∣
Y
=
2
)
=
1
2
P\left( X_3=3|Y=2 \right)=\frac{1}{2}
P(X3=3∣Y=2)=21,
P
(
X
4
=
4
∣
Y
=
2
)
=
1
2
P\left( X_4=4|Y=2 \right)=\frac{1}{2}
P(X4=4∣Y=2)=21,
P
(
X
1
=
1
∣
Y
=
3
)
=
2
3
P\left( X_1=1|Y=3 \right)=\frac{2}{3}
P(X1=1∣Y=3)=32,
P
(
X
2
=
2
∣
Y
=
3
)
=
1
3
P\left( X_2=2|Y=3 \right)=\frac{1}{3}
P(X2=2∣Y=3)=31,
P
(
X
3
=
3
∣
Y
=
3
)
=
2
3
P\left( X_3=3|Y=3 \right)=\frac{2}{3}
P(X3=3∣Y=3)=32,
P
(
X
4
=
4
∣
Y
=
3
)
=
2
3
P\left( X_4=4|Y=3 \right)=\frac{2}{3}
P(X4=4∣Y=3)=32,
归属于类别1的概率:
P
(
Y
=
1
)
P
(
X
1
=
1
∣
Y
=
1
)
P
(
X
2
=
2
∣
Y
=
1
)
P
(
X
3
=
3
∣
Y
=
1
)
P
(
X
4
=
4
∣
Y
=
1
)
=
2
7
⋅
1
2
⋅
1
2
⋅
1
2
⋅
1
2
=
1
56
\begin{equation*} \begin{aligned} &P(Y=1)P(X_1=1|Y=1)P(X_2=2|Y=1)P(X_3=3|Y=1)P(X_4=4|Y=1)\\ &=\frac{2}{7}\cdot\frac{1}{2}\cdot\frac{1}{2}\cdot\frac{1}{2}\cdot\frac{1}{2}\\ &=\frac{1}{56} \end{aligned} \end{equation*}
P(Y=1)P(X1=1∣Y=1)P(X2=2∣Y=1)P(X3=3∣Y=1)P(X4=4∣Y=1)=72⋅21⋅21⋅21⋅21=561
归属于类别2的概率:
P
(
Y
=
2
)
P
(
X
1
=
1
∣
Y
=
2
)
P
(
X
2
=
2
∣
Y
=
2
)
P
(
X
3
=
3
∣
Y
=
2
)
P
(
X
4
=
4
∣
Y
=
2
)
=
2
7
⋅
1
⋅
1
⋅
1
2
⋅
1
2
=
1
14
\begin{equation*} \begin{aligned} &P(Y=2)P(X_1=1|Y=2)P(X_2=2|Y=2)P(X_3=3|Y=2)P(X_4=4|Y=2)\\ &=\frac{2}{7}\cdot1\cdot1\cdot\frac{1}{2}\cdot\frac{1}{2}\\ &=\frac{1}{14} \end{aligned} \end{equation*}
P(Y=2)P(X1=1∣Y=2)P(X2=2∣Y=2)P(X3=3∣Y=2)P(X4=4∣Y=2)=72⋅1⋅1⋅21⋅21=141
归属于类别3的概率:
P
(
Y
=
3
)
P
(
X
1
=
1
∣
Y
=
3
)
P
(
X
2
=
2
∣
Y
=
3
)
P
(
X
3
=
3
∣
Y
=
3
)
P
(
X
4
=
4
∣
Y
=
3
)
=
3
7
⋅
2
3
⋅
1
3
⋅
2
3
⋅
2
3
=
8
189
\begin{equation*} \begin{aligned} &P(Y=3)P(X_1=1|Y=3)P(X_2=2|Y=3)P(X_3=3|Y=3)P(X_4=4|Y=3)\\ &=\frac{3}{7}\cdot\frac{2}{3}\cdot\frac{1}{3}\cdot\frac{2}{3}\cdot\frac{2}{3}\\ &=\frac{8}{189} \end{aligned} \end{equation*}
P(Y=3)P(X1=1∣Y=3)P(X2=2∣Y=3)P(X3=3∣Y=3)P(X4=4∣Y=3)=73⋅32⋅31⋅32⋅32=1898
归属于类别2的概率最大,因此分类输出为2。
三、Python实现
(1) 伯努利朴素贝叶斯
'''
sklearn实现伯努利朴素贝叶斯分类。
'''
import numpy as np
from sklearn.naive_bayes import BernoulliNB
## 1.构造训练集和待测样本
#训练集数据
train_x=[
[1, 1, 1, 1],
[1, 1, 1, 1],
[1, 1, 1, 0],
[1, 1, 0, 0],
[1, 0, 0, 0],
[0, 0, 0, 0]
]
#训练集数据标签
train_y=[
1,
2,
2,
3,
3,
1
]
#待测样本
test_x = [
[1, 2, 1, 2],
[1, 1, 2, 2]
]
#转为array形式
train_x = np.array(train_x)
train_y = np.array(train_y)
test_x = np.array(test_x)
## 2.定义分类器
bnbClf = BernoulliNB()
## 3.训练
Fit_bnbClf = bnbClf.fit(train_x,train_y)
## 4.预测
pre_y = Fit_bnbClf.predict(test_x)
print('预测类别:')
print(pre_y)

(2) 多项式朴素贝叶斯
'''
sklearn实现多项式朴素贝叶斯分类。
'''
import numpy as np
from sklearn.naive_bayes import ComplementNB
## 1.构造训练集和待测样本
#训练集数据
train_x=[
[1, 1, 2, 3],
[1, 2, 2, 4],
[1, 2, 3, 3],
[1, 2, 4, 4],
[1, 3, 3, 4],
[2, 2, 3, 4],
[2, 1, 3, 3]
]
#训练集数据标签
train_y=[
1,
2,
2,
3,
3,
1,
3
]
#待测样本
test_x = [
[1, 2, 3, 4],
[1, 1, 1, 4]
]
#转为array形式
train_x = np.array(train_x)
train_y = np.array(train_y)
test_x = np.array(test_x)
## 2.定义分类器
cnbClf = ComplementNB()
## 3.训练
Fit_cnbClf = cnbClf.fit(train_x,train_y)
## 4.预测
pre_y = Fit_cnbClf.predict(test_x)
print('预测类别:')
print(pre_y)

(3) 高斯朴素贝叶斯
'''
sklearn实现高斯朴素贝叶斯分类。
'''
import numpy as np
from sklearn.naive_bayes import GaussianNB
#训练集数据
train_x=[
[1.1, 2, 3, 4],
[1, 2.2, 3, 4],
[1, 2, 3.3, 4],
[1, 2, 3, 4.4],
[1.1, 2.2, 3, 4],
[1, 2, 3.3, 4.4]
]
#训练集数据标签
train_y=[
1,
2,
2,
3,
3,
1
]
#待测样本
test_x = [
[1.2, 2, 3, 4],
[1, 2.3, 3, 4]
]
#转为array形式
train_x = np.array(train_x)
train_y = np.array(train_y)
test_x = np.array(test_x)
## 2.定义分类器
gnbClf = GaussianNB()
## 3.训练
Fit_gnbClf = gnbClf.fit(train_x,train_y)
## 4.预测
pre_y = Fit_gnbClf.predict(test_x)
print('预测类别:')
print(pre_y)

End.
pdf下载
![[WUSTCTF2020]颜值成绩查询(布尔注入)](https://img-blog.csdnimg.cn/f3db04f98a9f4fdebdf0c3d8e7cd800f.png)