在讲父子进程之前,我们接着上面那篇继续讲
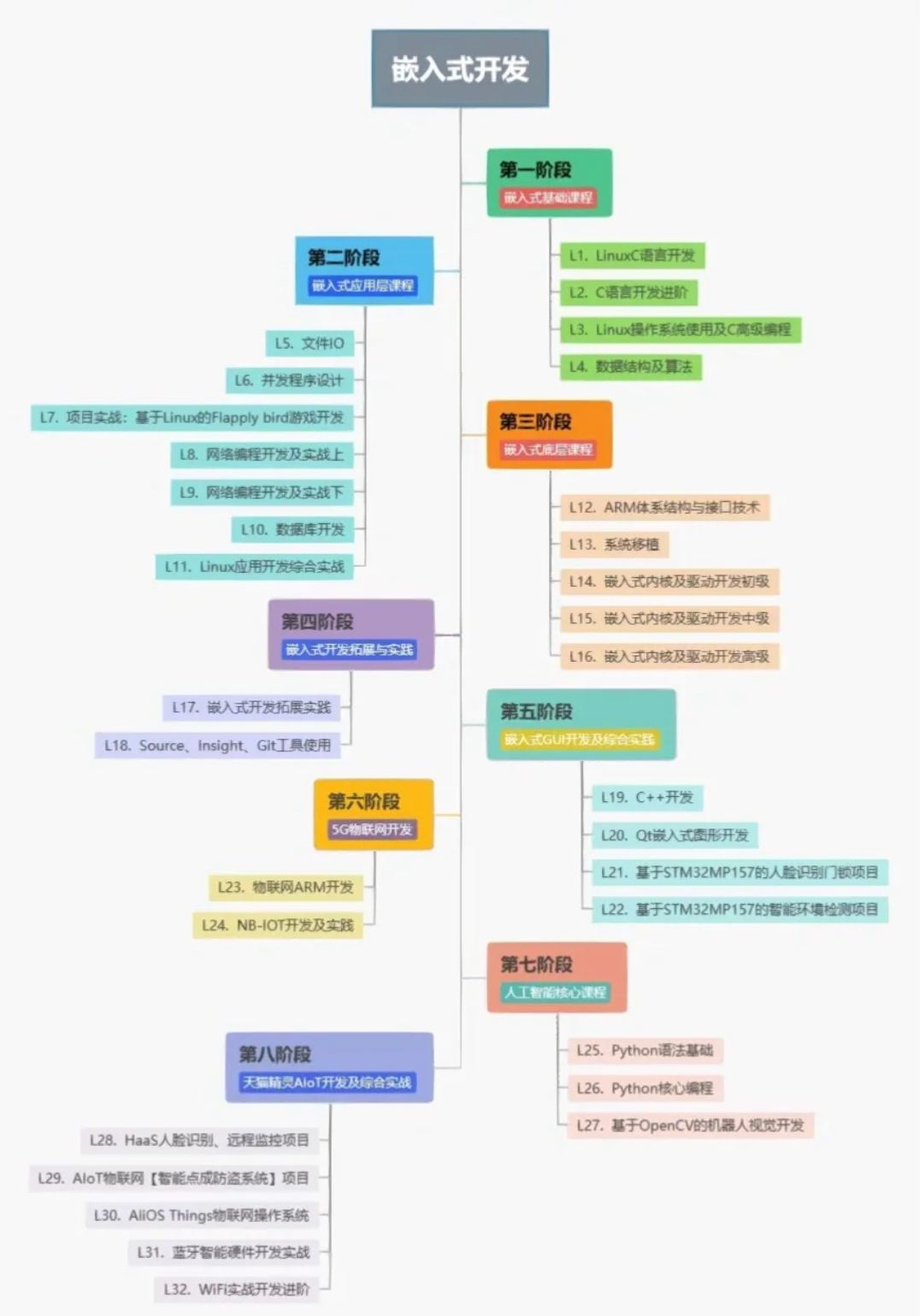
1.查看进程
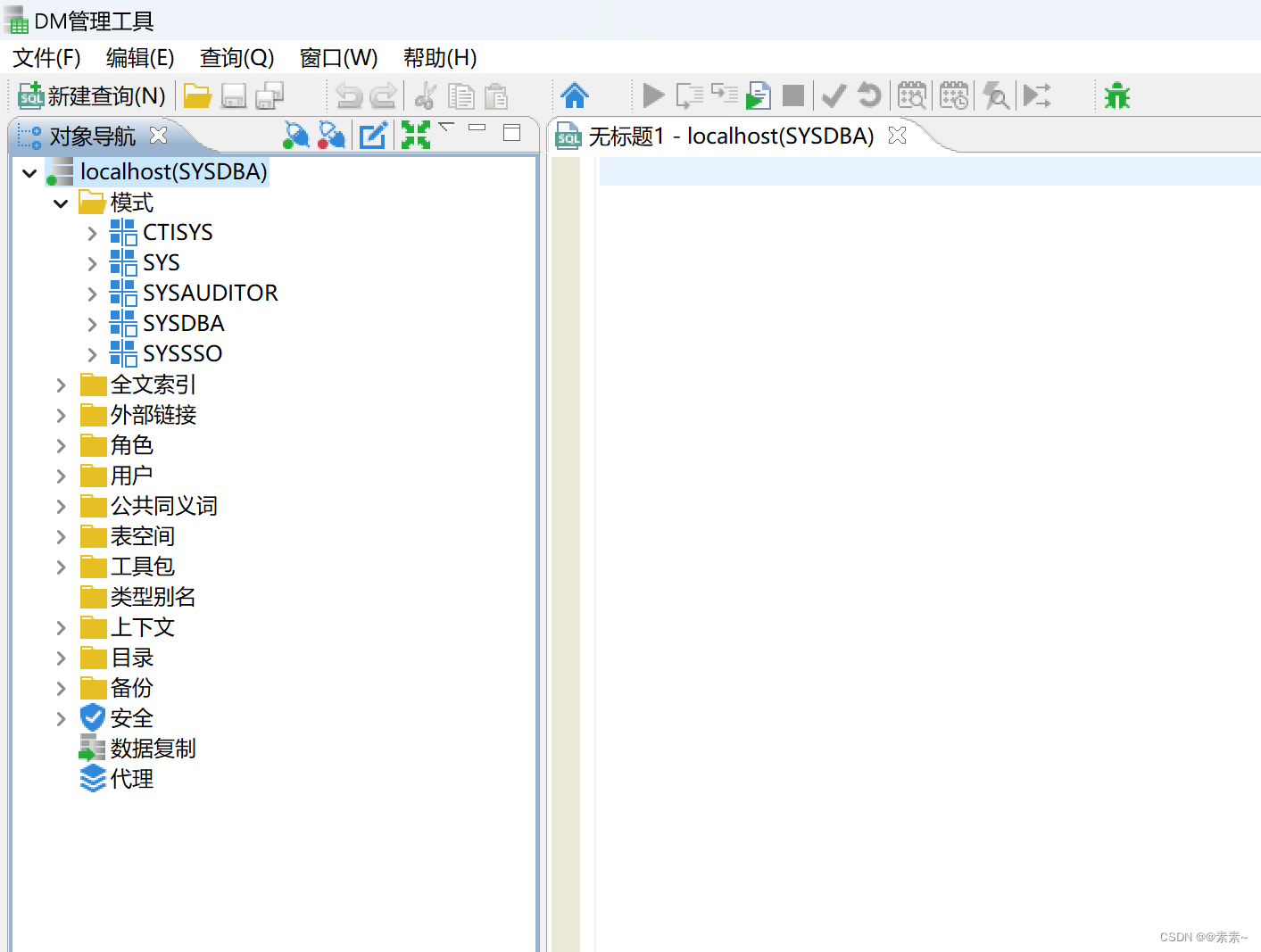
mycode.c
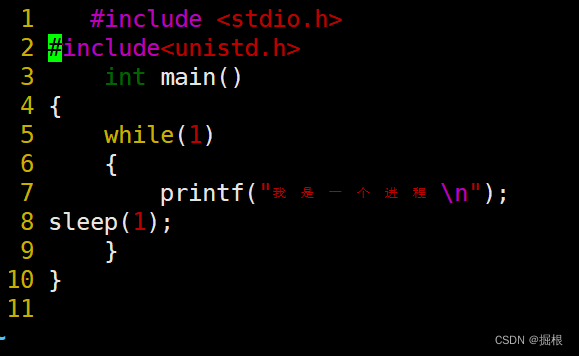
makefile
我们在zs_108直接编译mycode.c,直接运行,然后我们转换另一个账号来查看这个进程

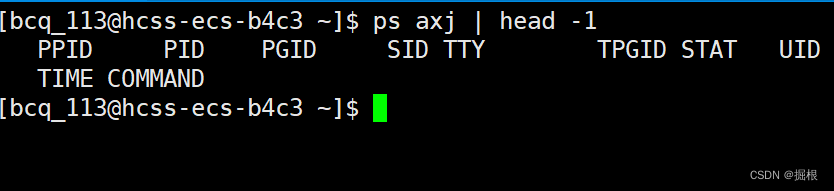
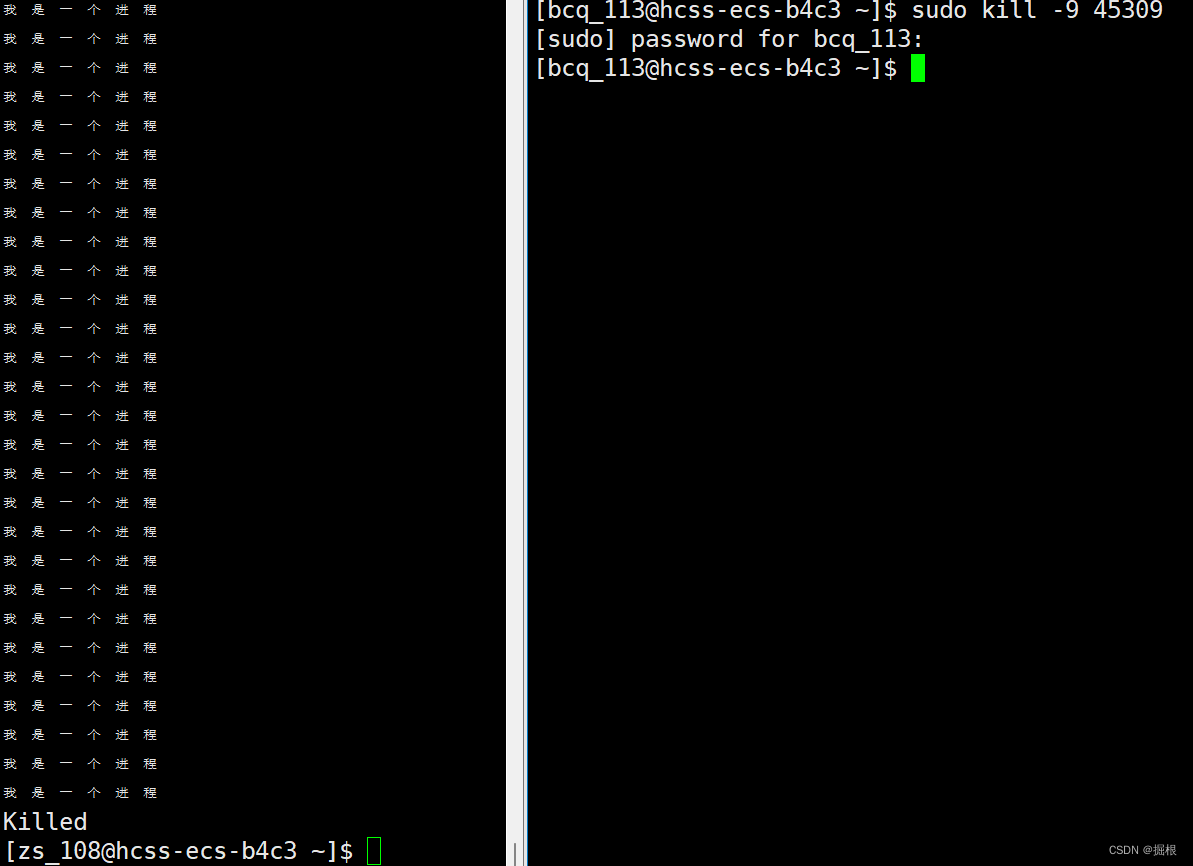
我们可以通过ps指令来查看进程
我们就会好奇了,第二行是什么?我们查的是第一行的啊
那个是指令的ps的进程
PID有什么用呢?
一个PID只对应一个进程
这个非常有用,比如说我们可以让一个进程强制停止下来
我们执行下面这个就能让这个进程停止
程序就被强制停止了

2.通过系统调用获取进程标示符
2.1.PID——子进程
我们怎么获得自己的PID呢?
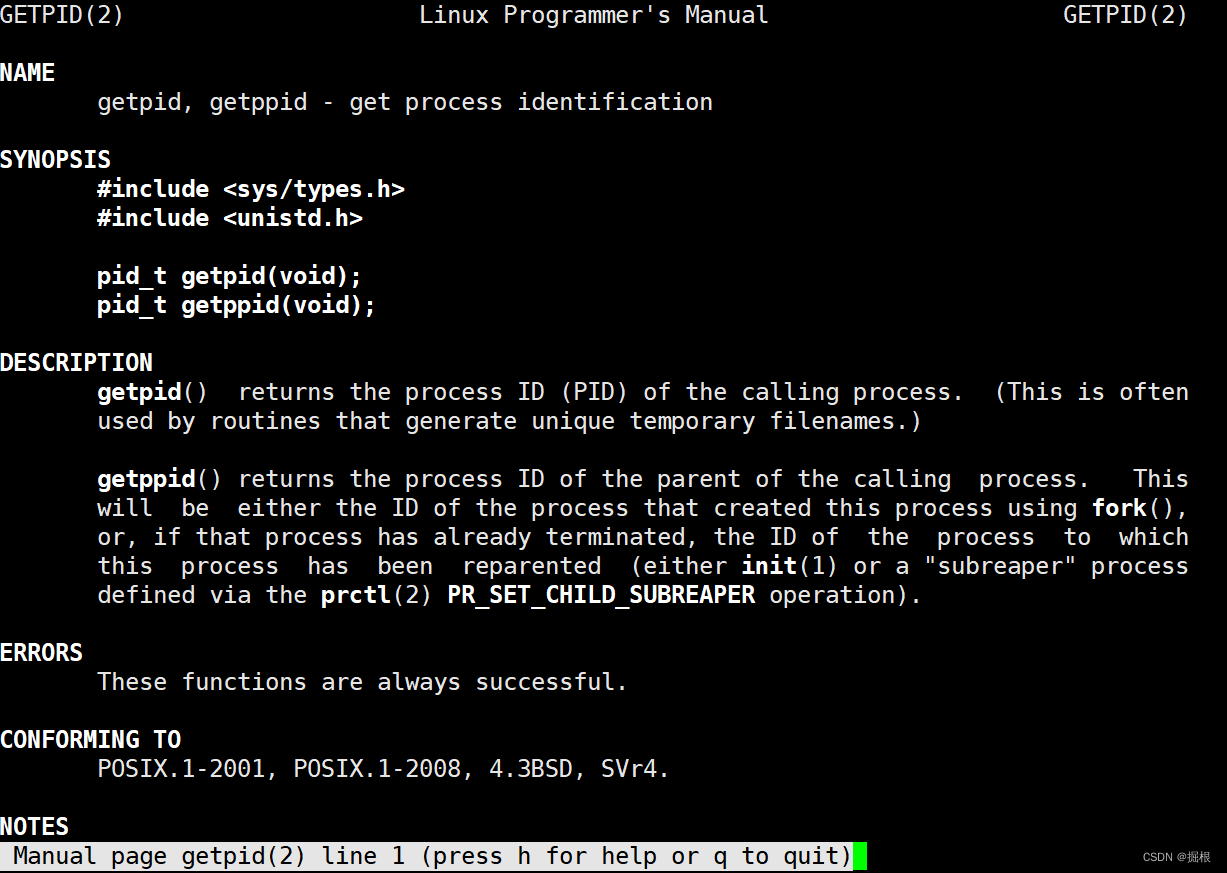
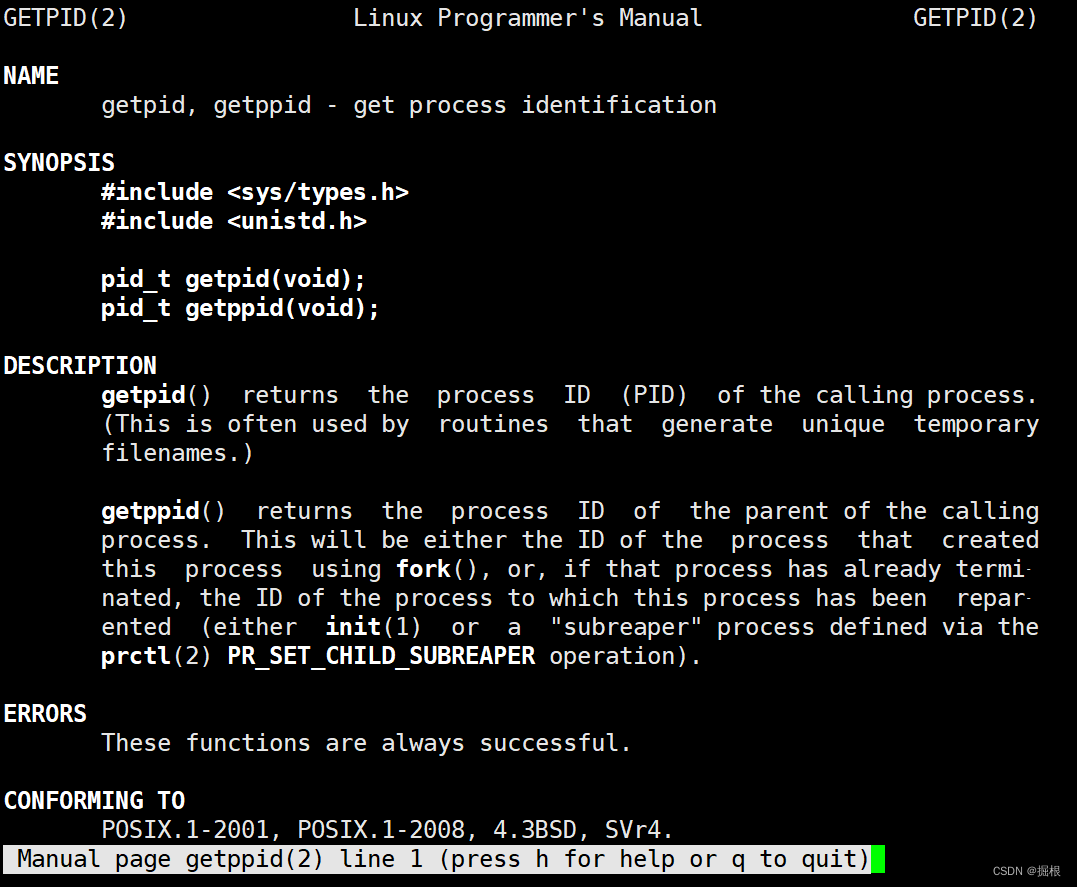
用系统调用——getpid函数
我们用man查一下
![]()
我们来使用一下就知道了
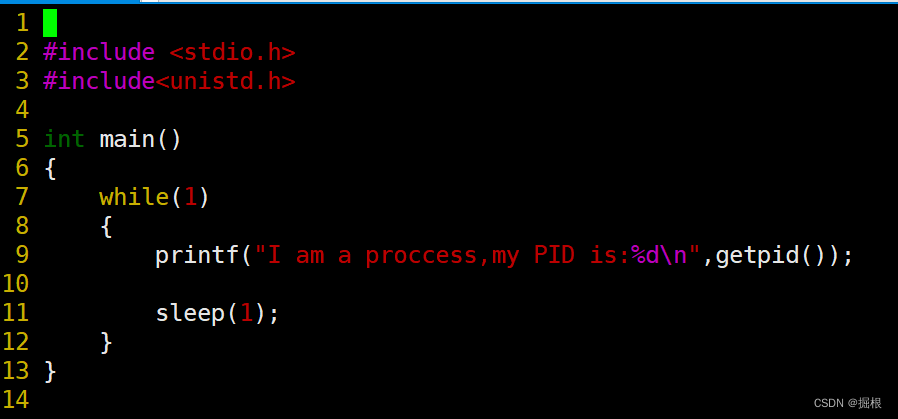
mycode.c
makefile
在执行之前我们先执行这个

注意test是我的可执行程序的名字
 我们再运行我们编译好的可执行程序
我们再运行我们编译好的可执行程序

发现右边的也开始出现数据了
发现跟我们查的PID是一样的啊
我们可以多跑几次,发现PID变了,但是两边的PID都是一样的
2.2.PPID——父进程
PPID是通过函数getppid来实现的
我们还是用man手册查询一下
![]()
我们去修改代码
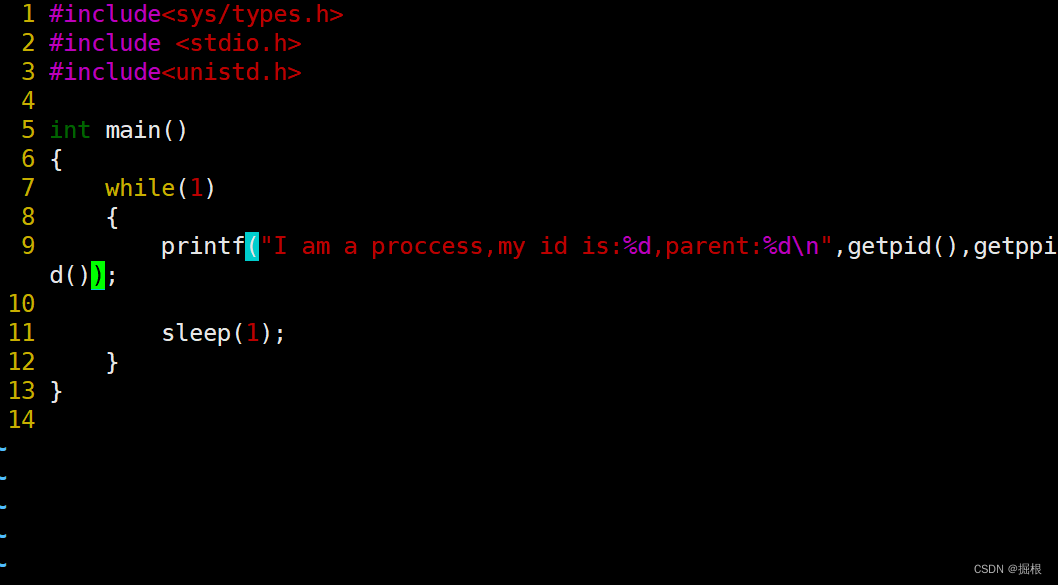
我们重复上面PID的步骤

我们再执行我们的test
 完全对的上
完全对的上
我们终止一下我们的程序,我们再打开试试看

我们发现我们的PID变化了,但是父进程PPID没变
那么这个PPID是谁啊

bash进程???
我们每次登录时,系统都会为我们创建一个bash进程
3.通过系统调用创建进程-fork初识
我们可以用man查看fork一下
![]()
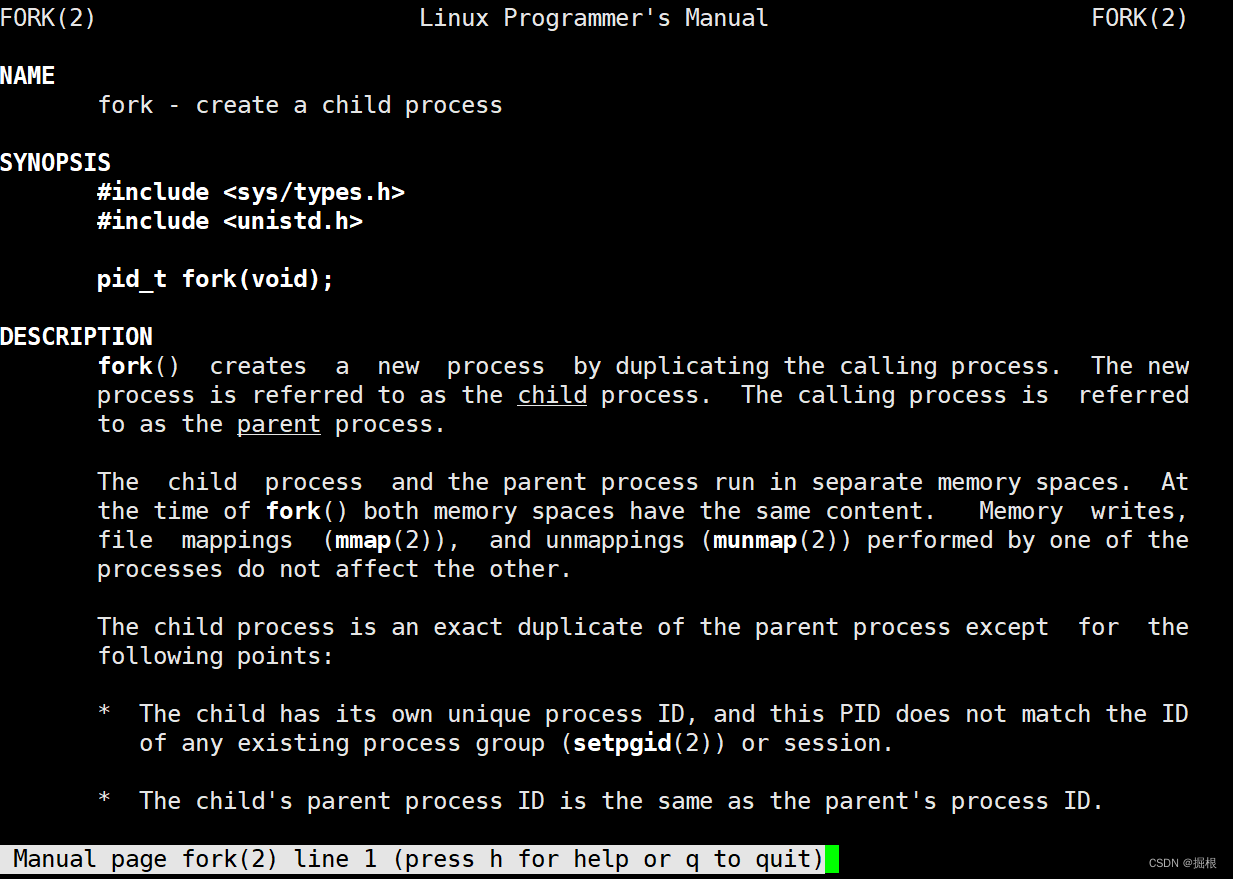
他的作用是创建一个子进程
它的用法有的奇怪,我来展示一下
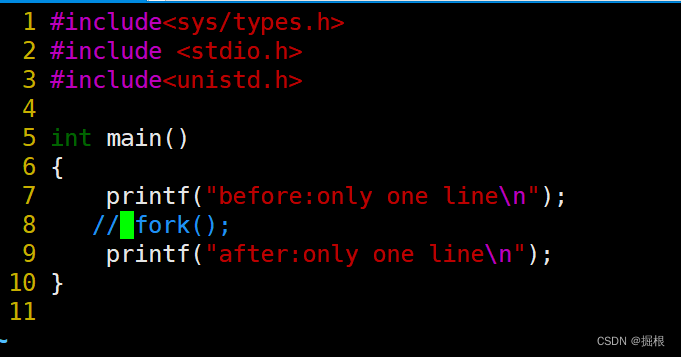
我们运行一下这段代码

我们再修改一下代码
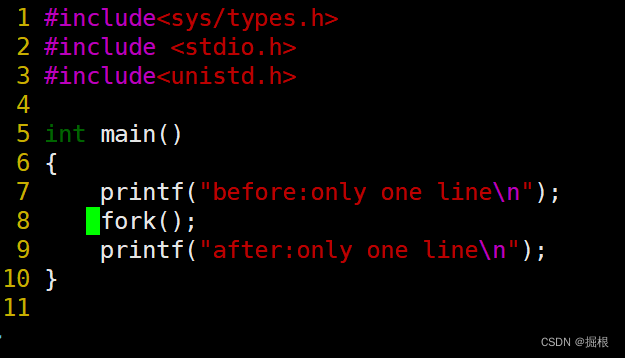
再执行一下

怎么还打印到命令行里面来了???
我们再修改一下代码
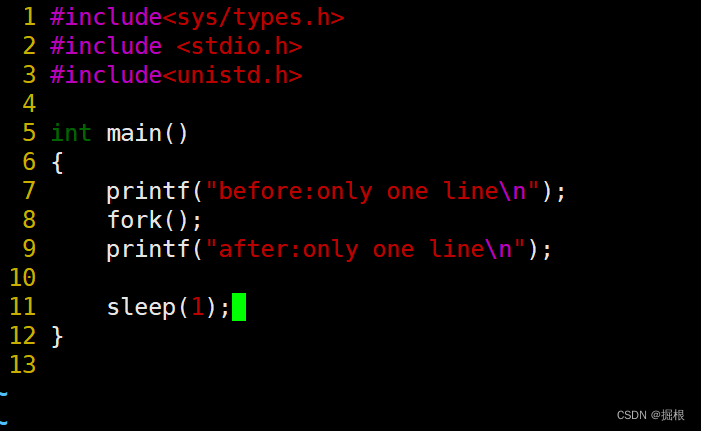
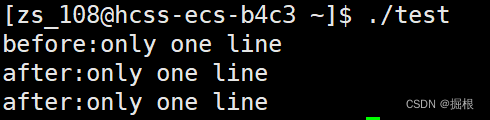
before是一条,after是两条,为什么呢?
这个是因为fork()的原因
按照手册的说法,fork的返回值既大于0又等于0,这可能吗?????
我们来验证一下

我们编译运行一下
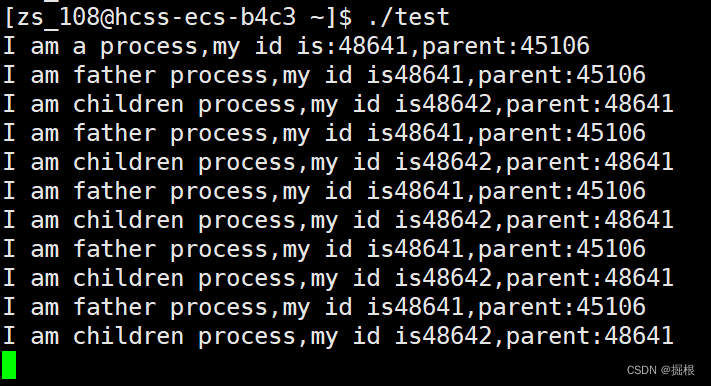
两个死循环在跑???
这个在c语言是基本不可能的,但是这个在操作系统是可以的
有没有发现children的PPID和parent的PID是一样的,所以他们是纯正的父子关系
在执行fork之前只有一个进程,执行到fork后就创建子进程,父进程就是原来的那个进程
创建进程的方式
- ./可执行程序
- fork()函数
接下来我们好好来好好研究一下fork函数
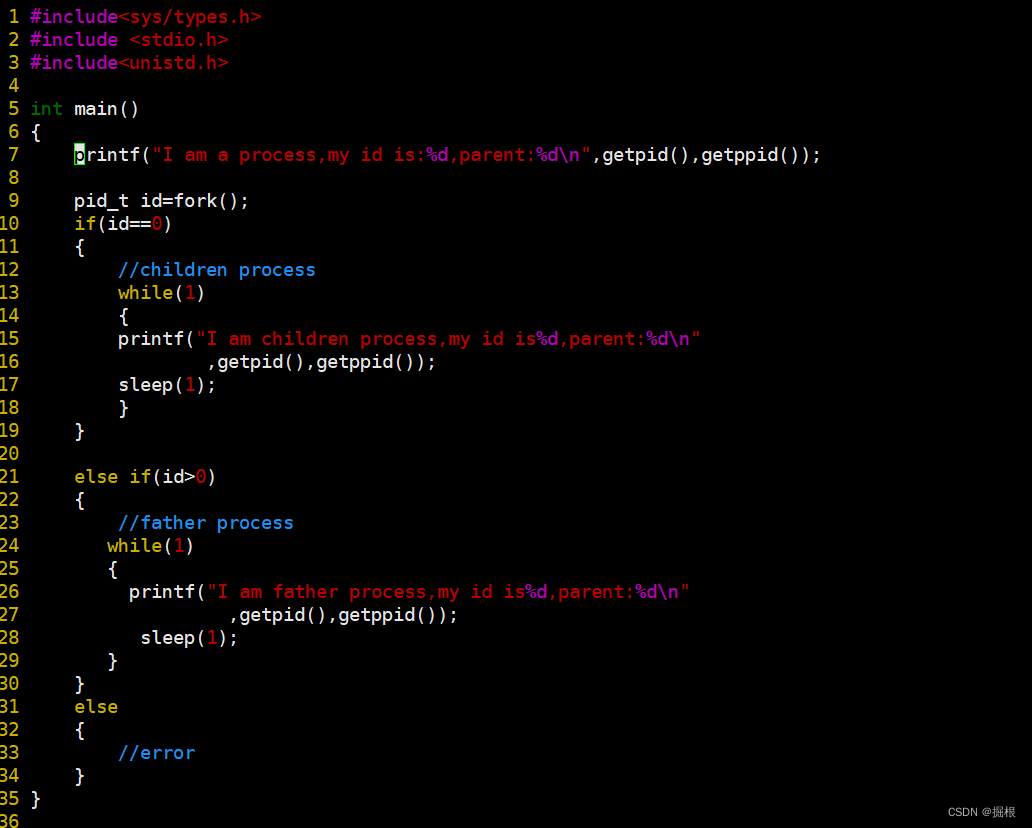
程序开始时按照从上往下的执行顺序创建一个执行流,执行到fork时创建子进程,子进程的返回值等于0,父进程的返回值大于0 ,就变成了两个执行流,父进程是旧的那个执行流,子进程是新创建的进程
3.1 为什么要创建子进程?
父进程创建子进程通常是希望子进程来协助父进程来完成一些工作,这些工作是单进程无法实现的。
例如:用户在下载某一款软件时,同时存在播放该款软件的官方宣传视频的需求。这就需要子进程来协助父进程来达到边下载边播放的目的。即通过一定手段(通常时fork()的返回值),让父子进程分别执行不同的代码!
3.2 fork()究竟干了些什么?
- fork()创建进程后,OS中会多一个进程(子进程)。
- 在创建过程中,Linux操作系统会为子进程创建对应的PCB,并用父进程的大部分属性来初始化子进程的相关属性(如子进程的pid、ppid、所在路径等属性信息则是单独实现)。
- 最后将该进程链入到运行队列中,等待CPU的调度!!
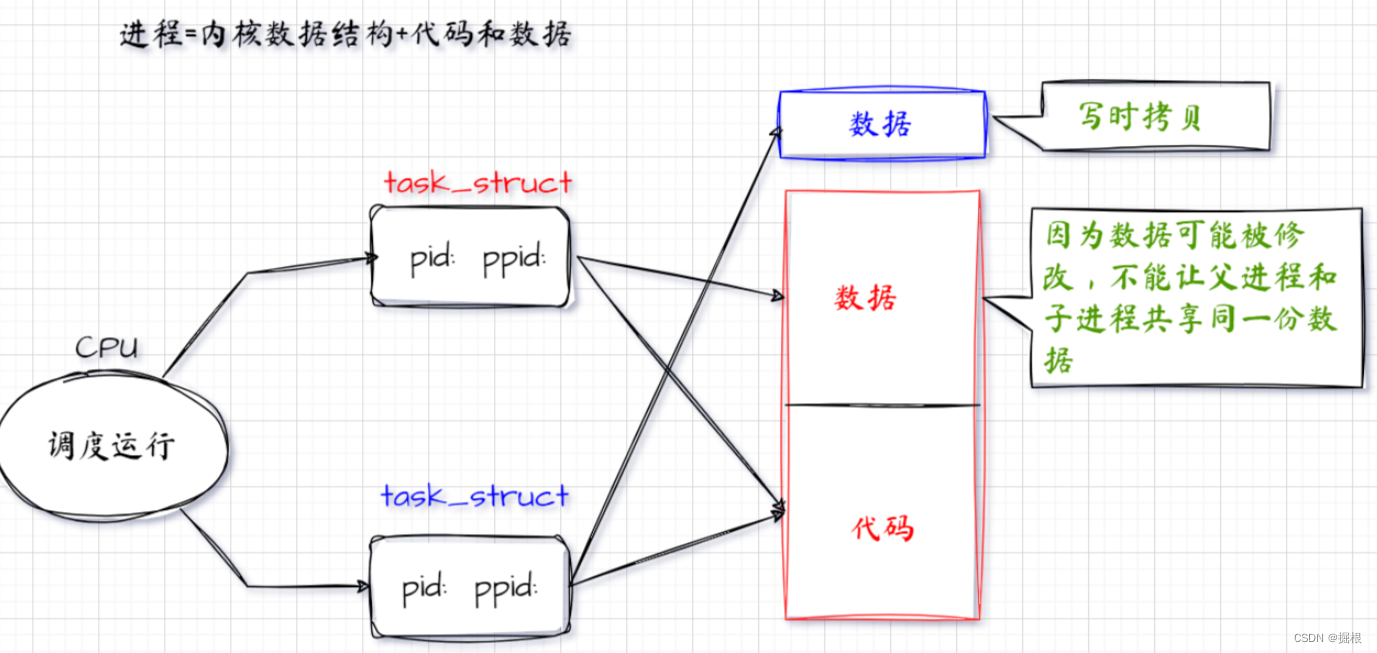
而进程 = 代码 + 内核数据结构和数据,并且进程间时是相互独立的。而进程中的代码和数据等是操作系统在创建该进程时,从磁盘上加载拷贝到内存中的。
但创建的子进程是直接在内存中创建的,子进程并没有相应的代码和数据,那要怎么解决这个问题呢?
- 实际上,代码只是用于读取的。
- 所以Linux中fork()创建的子进程和父进程共用同一段代码。
- 但对于数据来说,父/子进程间必然会存在差异(比如pid、ppid等)。
- 同时为了保证父/子进程间的独立性,必须在父/子进程中各自独立私有一份。
- 而在Linux中采用了写时拷贝的方式来解决这个问题。
下一个问题就是为啥我们在前面的展示中,fork()创建出的子进程只执行fork()后的代码?在fork()前的代码子进程能否“看见”呢?
- 答案是子进程能看见fork()前的所有代码!
- 至于为啥子进程只执行fork()后的代码,这是由于代码运行过程中,存在诸如epi、pc等寄存器。
- 这些寄存器中会保存当前指令要执行的下一条指令的地址。
- 而fork()创建子进程过程中,父进程中pc、epi等寄存器的结果也“继承”给了子进程。
- 所以才出现子进程只运行执行fork()函数后的代码!
3.3 fork为什么会存在两个返回值?
理解一个函数如何被返回两次,尤其是fork(),首先需要深入了解fork()的工作原理。
在没有调用fork()之前,系统中只有一个进程。进程由内核数据结构和与之关联的代码和数据组成。当创建一个新进程时,需要为它创建相应的进程控制块(PCB)以及与之关联的代码和数据。CPU随后会调度这个新进程,执行它的代码和数据。
调用fork()后,会创建一个新的子进程。创建子进程的本质是系统中多了一个新进程。由于进程由内核数据结构和代码及数据组成,因此新创建的子进程首先需要创建自己的task_struct(Linux内核中的进程描述符)。这个子进程的大部分属性是基于父进程的属性创建的,相当于复制了父进程的对象并对部分属性进行了修改。例如,子进程会有自己的PID,而其父进程ID(PPID)则设置为父进程的PID。这样,父子进程就有了自己的ID关系。
然而,子进程在刚创建时并没有自己的代码和数据,因此它只能访问父进程的代码和数据。这就是为什么fork()之后父子进程的代码是共享的。当CPU调度并运行父进程的代码时,它执行的是父进程的代码;当调度并运行子进程的代码时,它执行的仍然是父进程的代码
3.4 为何fork函数中父进程返回子进程的pid、子进程返回0?
一般而言啊,fork之后的代码父子共享啊,也就是说呢,其实当我们fork之后,后续的所有代码父子进父子进程他都能看到啊,只不过呢,我们是需要通过一定程度去区分,我们可以让父进程和子进程执行不同的代码块,那么当然应该这样,要不然我为什么创建子进程呢,我不就是想让你的子进程过来帮我忙嘛,把你创建出来,让你和我做不同的事情,所以我们的返回值一定是需要不同的,即便是返回值未来,如果假设系统设计者把它设成相同的了,未来我们一定也要有方法区分父子进程,这是这个,当然这不是这个问题的答案,问题是为什么要给子进程反回0给父进程反回pid,上面回答的是为什么父子进程返回值不同,我们现在知道了,因为父子进程,那么后续的代码是共享的,而我们可以通过不同的返回值来区分不同的执行流,让父子执行不同的代码块好也没有毛病,具体他执行的代码块要干啥我们后面来介绍啊 现在的问题是为什么要给子进程返回0给父进程返回pid。
给大家举一个生活当中的例子啊:
在现实生活中,一个父亲可以有多个子女,而每个子女只有一个父亲,这是容易理解的。在进程的世界中,一个父进程也可能有多个子进程。但有时,我们可能需要对特定的子进程进行控制。想象一下,如果一个家庭有10个孩子,当父亲喊“儿子,你过来”时,所有10个孩子都过来了,那么父亲到底是想叫哪个孩子呢?
因此,对于父进程来说,它必须有一种方法来区分每一个子进程。这就是为什么fork()在父进程中返回子进程的PID。这样,父进程就可以使用这个PID来标定和识别每一个子进程的唯一性。而对于子进程来说,情况就简单了。它只需要调用getppid()函数就可以直接获取其父进程的PID。所以,子进程要找到父进程并不需要花费太多成本,它只需要通过返回0来表示成功就可以了。这就是为什么我们在父进程中返回子进程的PID的原因,因为未来我们可能想通过父进程使用PID来明确控制我们要访问的是哪一个子进程。
3.5 父进程和子进程谁先运行?
我们已经看到了fork()函数会创建一个子进程。创建完子进程后,子进程会被加载链接到系统进程列表中等待CPU调度运行。
至于父进程和子进程谁先被CPU调度是不确定的。进程被调度的先后顺序由各自的PCB中的调度信息(时间片 + 优先级等)+ 调度器算法确定。换句话说,父进程和子进程谁先运行是由操作系统决定的!
3.6 为何同一个变量接收两个返回值
当使用fork()创建子进程时,系统中确实多了一个进程,这也意味着操作系统内必须为这个新进程创建一个对应的PCB(进程控制块)。这个子进程的PCB同样可以被CPU调度运行。与父进程不同,子进程在创建之初并没有自己的代码和数据。
需要明确的是,进程在运行时具有独立性。这意味着一个进程的崩溃或退出不会影响到其他进程。例如,如果在Windows上运行的QQ崩溃了,它不会影响到同时运行的画图软件或XShell等其他进程。每个进程都是独立的,它们的崩溃或退出不会影响其他进程。
为了保证进程的独立性,不能让父进程和子进程共享同一份数据,因为数据可能会被修改,修改后可能会影响其他进程。因此,虽然父子进程的代码是共享的,但数据不一定是共享的。理论上,子进程需要为自己拷贝一份父进程的数据。但实际上,数据的拷贝工作是由操作系统自动完成的。当子进程需要访问父进程的某部分数据时,操作系统会识别出这一需求,并在系统内存中为子进程重新开辟一段空间。子进程在新开辟的空间内进行数据的修改,这样就不会影响到父进程的数据。这种技术被称为写时拷贝(Copy-on-Write)。它确保了父子进程在数据层面的独立性,同时也避免了不必要的数据冗余。
总结来说,fork()创建的子进程具有独立的PCB,可以被CPU调度运行。虽然父子进程的代码是共享的,但数据不一定是共享的。操作系统通过写时拷贝技术确保父子进程在数据层面的独立性,同时也避免了数据冗余。
fork 函数在执行 return 返回的时候是往 id 变量里面写入嘛,父进程 return 一次,子进程 return 一次,子进程会执行写时拷贝,这就是为什么一个 id 变量有两个不同的数据,本质上是因为有两块空间。为什么同一个变量名可以有不同的内容,这个问题我们在后面介绍进程地址空间的时候为大家介绍。
我们来深入了解一下
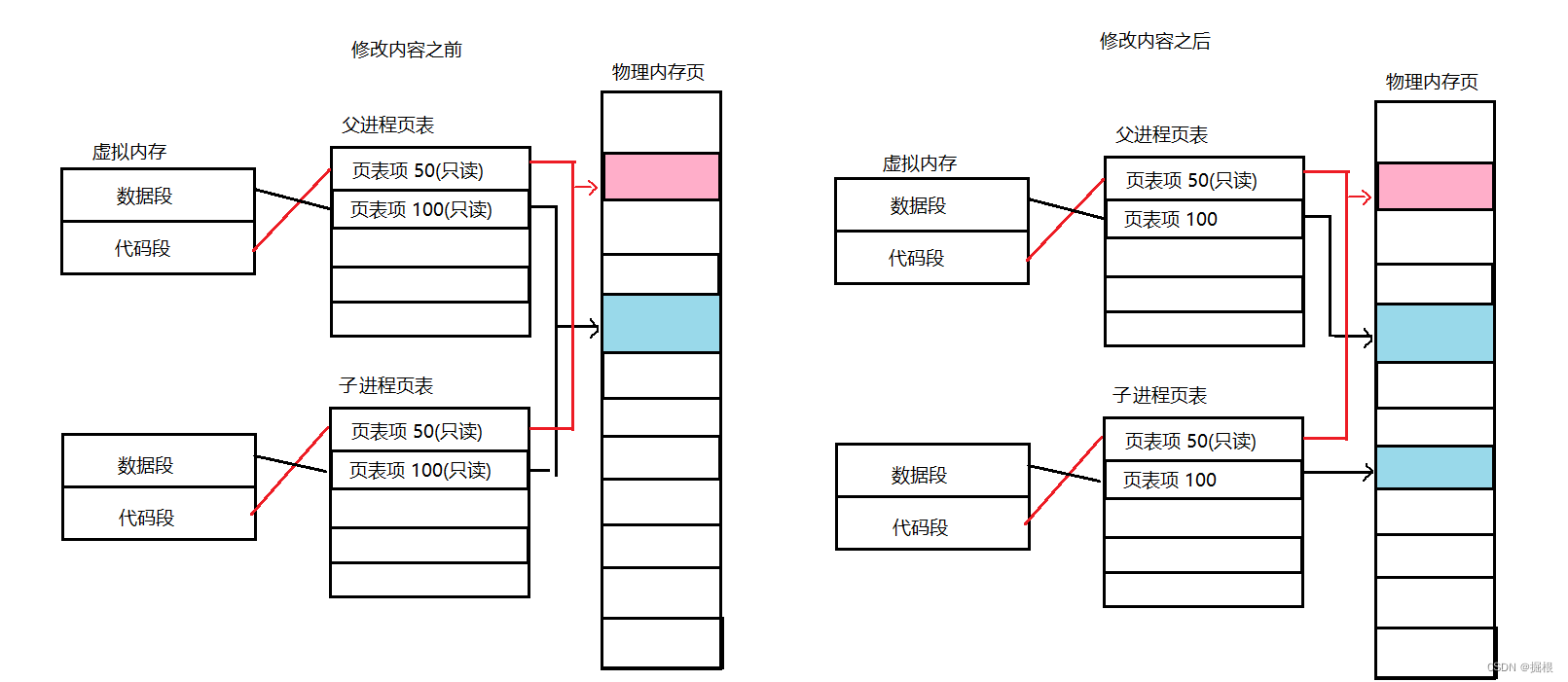
- 操作系统在创建子进程时,会先将父进程页表中的访问权限大部分改为只读权限。
- 然后以父进程为模板,将数据拷贝给子进程。
- 当子进程或父进程对数据试图修改数据,由于页表中的访问权限为只读。此时该行为会被操作系统识别到。并分为以下两种情况:
- 如果代码和数据所处区域本身就是只读的(如:代码区、字符常量区),此时OS认为该行为非法被拦截。
- 原本数据可读可写,但操作系统将对应页表中的访问权限设置为只读。当操作系统识别到该信息时,操作系统并不会将行为视为错误,而是作为重新申请内存拷贝内容的一种策略机制。此时操作系统会重新申请开辟空间,拷贝和修改数据,并修改页表中的映射关系。
3.7.fork创建子进程失败原因
在Linux中,fork()创建子进程失败通常由有以下两种原因:
- 系统中有太多的进程。操作系统内存不足。
- 实际上,用户使用fork()创建子进程是有次数限制的。当超过该范围时,fork创建子进程失败!
3.8.bash如何创建子进程?
我们看看程序最开始的那个printf,PPID是45106,那么45106是谁呢?
很明显了,就是我们自己的PID
这个bash创建子进程的过程肯定也调用了fork()
我们接着从这个故事说起:
“王婆为了保证自己在给别人说媒时,如果失败了,不会影响到自己,她是通过创建子进程来实现的。现在我的问题是,bash是如何创建子进程的?虽然我们还没有看或写bash的源代码,但我可以推断一下这个过程。
bash一定会调用fork来创建子进程,并让自己的代码继续执行命令行解释,而让子进程去执行解释新的命令。那么,bash自己就会继续接受用户的输入,并打印出提示符,等待用户输入新的命令。这就是为什么我们运行的所有命令都是在bash内部,因为所有的进程都是通过fork创建出来的。
当然,这只是问题的一半,后面还有更多内容需要探讨。但我们已经理解了创建子进程的过程,核心结论就是bash也是一个进程,当执行命令时,bash内部一定会为我们fork创建新的子进程,然后执行我们的代码。”